Key Contribution
- Multi-modal self-supervised learning
- 1) Cross-modality Semantic Correspondence: Fine-grained Modeling(local) + Coarse-grained Modeling(global)- 2) Temporal Dependencies in Videos: Recovering masking frames
- Progressive Video Summarization: stage 사용해서 pinpointing important content, iteratively refine the video sequence by emphasizing the important content
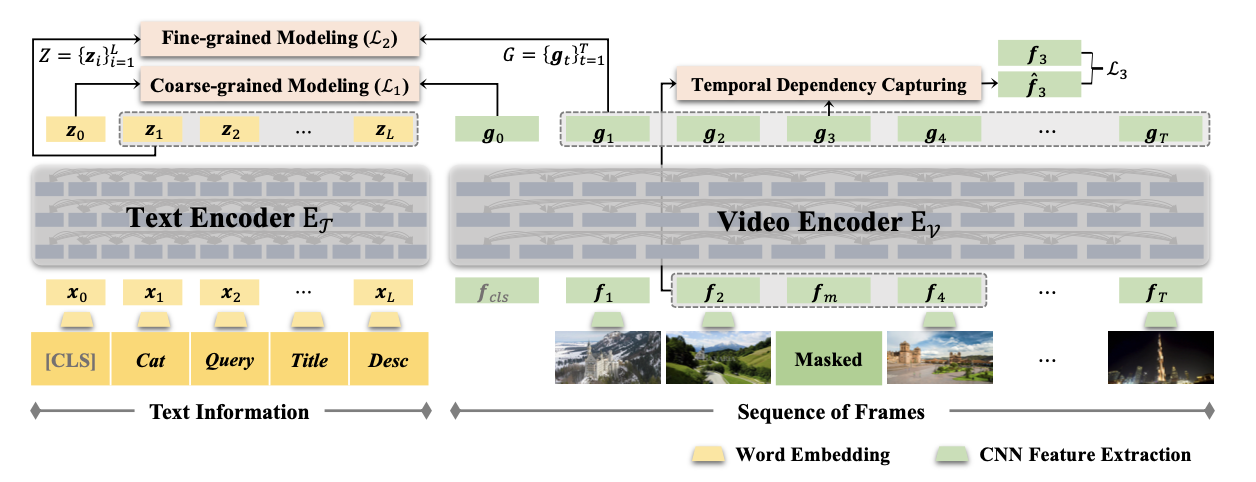
- text encoder: [CLS], category, search query, title, description
- video encoder: frame features (from GoogLeNet pool5 layer), 는 learnable feature -> 은 whole video에 대한 representation
objectives
Cross-modality Semantic Correspondence
- coarse-grained modeling: predict whether the video and the text are corresponding
- input:- BCE loss
- fine-grained modeling: measure the distance bet. frame sets & text sets
- contrastive loss
Temporal Dependencies in Videos
- replace a randomly selected frame with a learnable feature
- encoded masked feature를 가지고 mask frame을 예측하는 것이 아니라, recover the frame by considering the temporal dependencies between the masked frame and whole video
- MLP_s -> smooth transition인지 예측. , where is the encoded feature of .- 1) if smooth transition: recover it by using only its neighbors(local info) with one-layer Transformer and linear proj.
- 2) if abrupt transition: use to recover it, as contains global info
- the masked frame is recovered by combining 1) & 2)
Progressive Summarizer
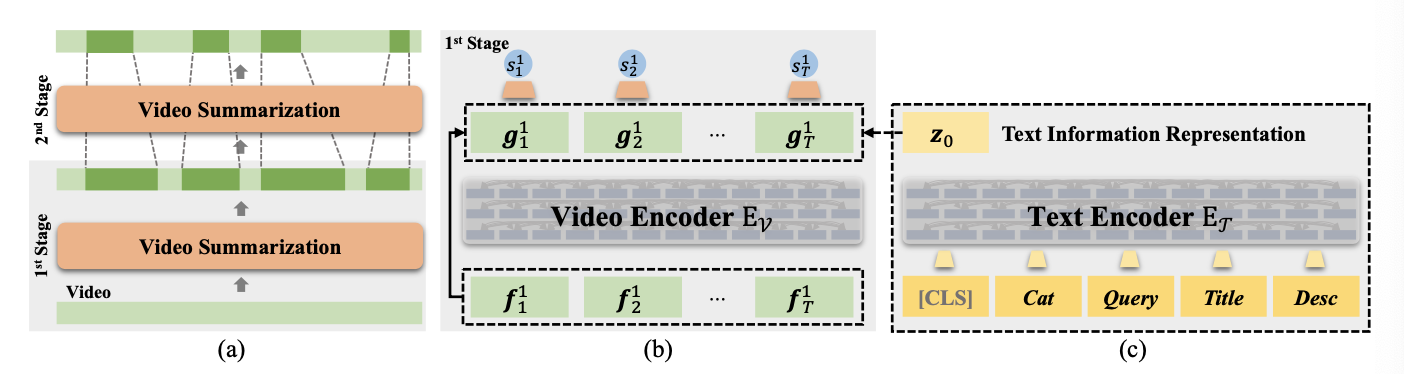
- frame score를 stage마다 곱해주는 식
- - with Text Info
- pretrained text encoder에 fed한 뒤 나온 을 visual modality와 합쳐서 scoring function에 넣음
Experiment
- SumMe: 비디오 이름을 search query로 사용, 나머지 3-types는 empty로
- TVSum: 비디오 이름을 search query로 사용, categories 데이터 있음. 나머지 empty

My goal is to found a company that can empower marginalized people and eventually better the world using AI.