지난 글에서는 Passive Marker 기반, 그중에서도 IR 카메라와 재귀반사 마커를 통한 방법을 알아보았다.
이번에는 IMU기반 방식과, RGB & Pose Estimation Algorithm을 활용한 방식을 알아보겠다.
IMU
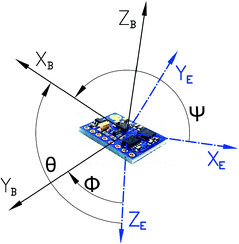
IMU는 단순히 말해서 가속도 센서다. 해당 센서의 frame으로 좌표계가 있고, 그 frame 기준으로 지금 센서의 물리적 가속도를 알려주는 센서다. 
이 가속도 센서는 싸면 3~6천원 정도에 구하고, 비싸면 개당 만원 단위의 단가가 나오기도 한다. 정확도와 축에 의해 가격이 결정되는데, 축은 3축 센서면 축을 기준으로 얼마다 이동하느냐만 알려준다면, 6축 센서는 , , 의 기저 벡터를 기준으로 얼마나 회전하는지도 알려준다.
일단 IMU센서는 우리 눈으로 보기에 정지된 상태이면 norm이 대략 인 가속도가 어떤 방향으로 항상 적용되고 있다. 지면에 고정된 frame을 기준으로 지면 아래 방향이지만, IMU 센서에 고정된 frame 기준으로 이 방향은 항상 변할 수 있다.
따라서 이 방향에 의한 영향을 제거해주고 오직 알고싶은 지면 frame에 대한 가속도만 구해야 한다.
그러면 이 센서를 가지고 어떻게 모션 캡쳐를 할 수 있을까?
기본적으로 사지 관절을 잇는 뼈를 하나의 직선으로 보고, 그 뼈에 센서를 부착하면 된다. 물리적으로 해당 뼈의 길이를 쟀다고 가정하면, 크기와 방향을 알 수 있게 되고, 이를 벡터화한 뒤 벡터들끼리 조합하면 사람의 스켈레톤 형태로 나타나는 것이다.
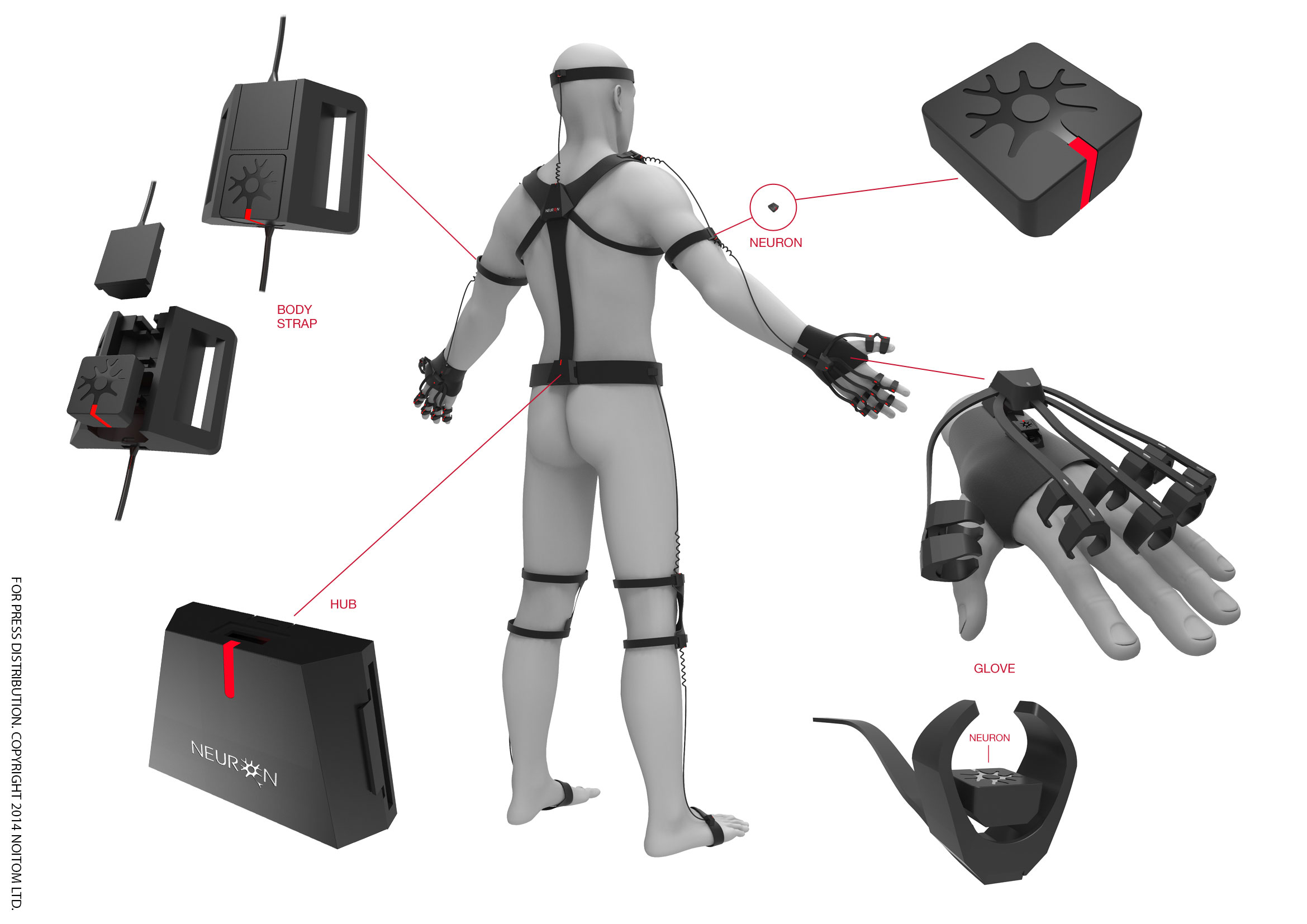
우리가 흔히 아는 VR Full Tracker가 이런 방식이다. 많은 저가형 모션 캡쳐 중 몸에 부착하는 장비가 있다면 대체로 이런 방식이다.
(아니면 장력 또는 flex를 측정하는 센서를 쓰거나..)
이 방식에서는 각 센서에서 얻는 신호값이 싱크가 중요한데, 가령 부터 까지 센서 A에서 얻은 신호가 부터 까지 센서 B에서 얻은 신호와 sync되어 나열되면 안된다는 것이다.
이 sync가 사실 우리에게는 체감이 되지 않는다. 가령 VR Full Tracker는 real-time play 용도라 적당한 action만 인식해주면 된다. 따라서 초저가 Full Tracker가 있다면 sync가 맞지 않을 수도 있다.
다만 특정한 이유로 측정 및 기록이 목적이라면 정말 중요하다. 가령 60Hz의 6축 센서 7개로부터 3초간 신호를 받았을 때, shape의 array를 얻을 수 있다.
이 때 에 대해 모두 동일한 시간에서 각 센서에서 발생한 값이냐가 중요하다. 그래야 정확한 기록이 가능해지기 때문이다.
IMU 센서 기반의 대표적인 모션캡쳐 솔루션은 Xsens이다.
IMU 기반으로 구성된 3D Human Dataset은 3DPW 등이 있다.

3DPW는 가속도 센서도 사용하지만 아마 Estimated 2DPose도 사용한 것으로 안다.
IMU 방식은 상당히 적은 비용으로 구현이 가능하지만, 정확도와 sync에 깊게 들어가면 상당히 어려우며, 그에 따라 가격도 상승한다.
RGB & Pose Estimation Algorithm (+ Depth)
이 방식은 Monocular, Stereo, Multi-View RGB camera가 있는 환경에 해당한다.
가장 좋지 못한 방식은 Monocular RGB 상황으로, 그냥 핸드폰 카메라 한 대만 있는 것과 같다. 이는 사실 Motion Capture보다는 Pose Estimation이라 부르는 게 맞고, 그 중에서도 3D Human Pose Estimation이다.
해보면 알겠지만, 정확도가 처참한 수준이다. jitter를 잡아내기는 커녕 근본적으로 예측 좌표와 실제 좌표와의 차이가 너무 크다. 꽤 잘 맞아봐야 1cm~5cm 정도의 오차라고 생각하면 편하다.
Stereo 환경은 좀 나으며, Epipolar Geometry 이론을 활용하여 Triangulation을 하는 등의 방법이 종종 쓰인다.(이론적으로는 stereo만으로도 정확한 measurement가 가능할 것이다.)
Multi-View는 말 그대로 RGB 카메라가 3개, 4개 이상 존재하는 상황을 말한다. 직관적으로 카메라 대수가 많을수록 정확도가 올라갈 것 이다.
이런 상황에서 모션캡쳐를 하게 해주는 소프트웨어는 iPi Software이다.

iPi Software는 단순히 N개의 웹캠만으로도 모션캡쳐를 하게 해주는데, 정확도가 생각보다 꽤 괜찮은 수준이다.
캘리브레이션 방식은 wand calibration과 유사한데, 마커가 1개인 방식이라 scale은 사람이 입력해야 한다.(예: 어떤 카메라가 지상으로부터 떨어져 있음)
이 방식은 정확도가 대체로 떨어지는데, 이를 보완해주는 방법은 Depth Camera를 같이 사용하는 것이다. MS Kinect, Intel RealSense와 같으 TOF 방식의 Depth 센서가 달려 있는 카메라를 사용하면 Pose Estimation 결과의 정확도가 매우 향상된다.
iPi Software의 경우에도, 사실 RGB 카메라의 대수가 많아지면 꽤 괜찮은 정확도가 나오며, Depth가 추가되면 상당히 괜찮은 수준의 정확도가 나온다. 애초에 저가 모션캡쳐를 목표로 나온 상품이라 준비할 도구들이 많지 않고 그 가격도 싼 편이다. 프리랜서 애니메이터들이 상당히 애용한다.
어느 방식이 좋을까?
필자의 경우 앞선 글의 패시브 마커 방식, 그리고 본 글의 두 가지 방식 모두 시도해보았다.
처음에는 제일 쉬워 보이는 RGB 기반으로 시도했고, 컬러 스티로폼 공 같은 걸 사서 인식해보려 했다. 이런저런 이유로 실패했다.
그 다음에는 IR 기반 방식을 시도했고, 이런저런 이유로 실패했다.
IMU 기반 방식으로 바꿨는데, 얘도 이런저런 이유로 실패했다.
돌고돌아 다시 IR Passive Marker 기반 방식을 시도하고 있다. 그 과정에서 많은 공부를 하고 있으며 현재까지 성공을 기대할 수 있을 정도로 많은 진척이 있었다.
결국 정석적(?)인 방식이 좋은 것일까..?
본업/학업과 병행하며 사이드&독학으로 모션캡쳐를 시도해왔더니 어느새 반년 정도가 지나 있더라...
이 시리즈에서 앞으로 이런 시행착오들, 어떤 제품을 사서 어떤 식으로 시도했고 왜 실패했는지, 그리고 그 과정에서 내가 공부했던 것들을 적어가려 한다. 아예 Manual을 만들까 싶기도 하고?
이왕이면 그 과정에서 사용한 소스코드도 공개하거나 tool화하는 것도 생각 중에 있다.
