
1. 개요
안녕하세요. 오랜만에, 블로그로 찾아뵙습니다😙
저는 4월에 IT기업 신입으로 입사하였고 벌써 4개월이 지났습니다. 시간이 정신없이 흘러갔네요...!
신입 개발자로 수습 프로젝트를 끝내고, 두 번째 프로젝트를 진행했습니다.
이 프로젝트에서 파일 다운로드 기능을 만들어야 했습니다.
예전에 토이 프로젝트로 간단히 구현한 경험은 있지만, 실무에서는 처음이었습니다.
추가적인 요구사항으로 대용량 파일일지라도 OOM(Out Of Memory) 발생하지 않도록 만들어야 했습니다.
코드로 구현하기 전에 이론과 예제코드를 찾아보면서 구현하려고 했지만
결국 마감에 쫓겨 주변에 선배 개발자님께 도움을 받아 기능을 구현했습니다.
선배님께 도움을 받아 구현하면서 알게된 키워드는 ServletResponse로 실시간 데이터 전송(스트리밍 방식)이 가능하다는 것이었습니다.
일단 문제없이 돌아가는 코드를 구현했지만, 어떤 원리로 기능이 작동하는지 궁금하기도 하고
이에 관해 잘 정리해둔다면, 개발자로써 살아가는데 좋은 밑거름이 될거란 생각이 들어 정리하고자 합니다.😌
2. 결론부터 먼저 말하면
결론부터 말하면, 어떠한 외부 라이브러리의 도움없이 자바와 스프링만으로 OOM 없이 대용량 파일을 스트리밍하여 다운로드 할 수 있습니다.
이는 InputStream과 OutputStream을 통해 가능합니다.
아래는 제가 테스트에 사용한 코드입니다.
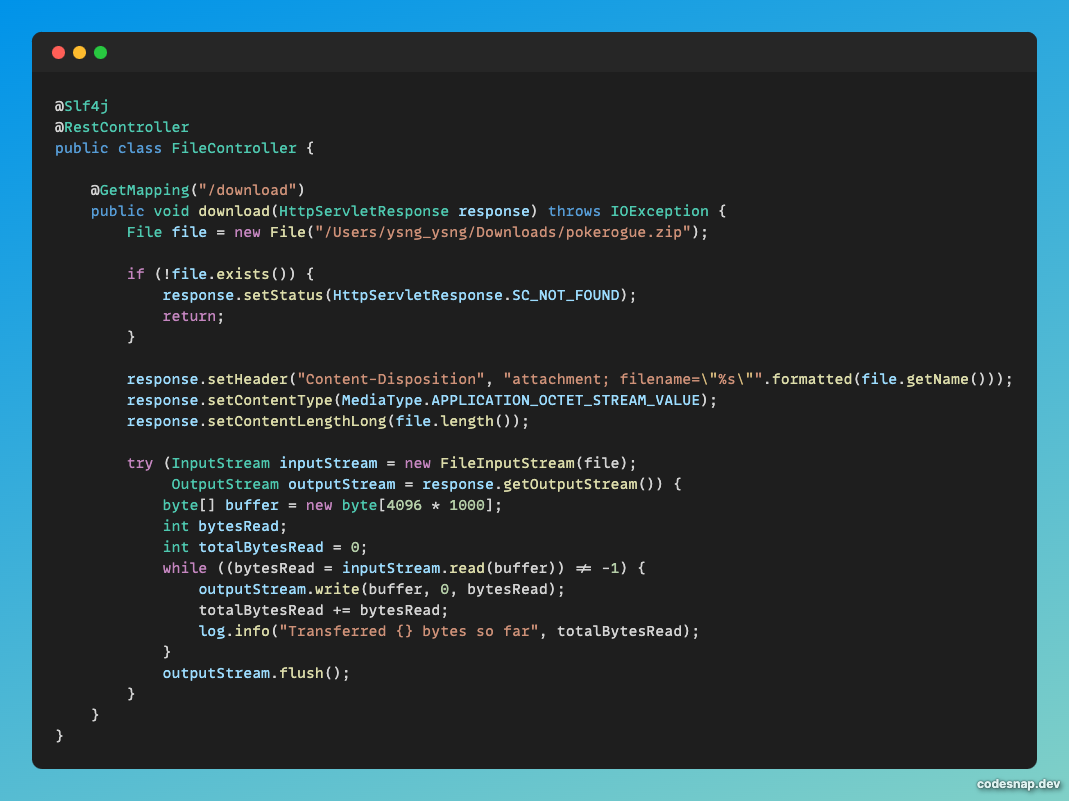
위의 코드를 디버그 모드로 실행하며 write한 파일 사이즈에 따라 브라우저에서의 파일 다운로드 진척도를 살펴보았습니다.
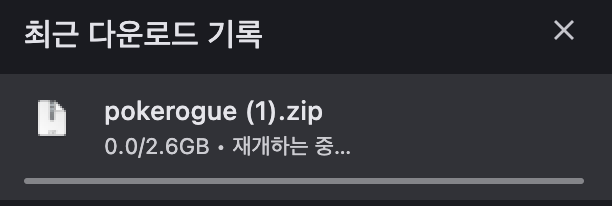
요청을 보내고 응답을 받으면 위와 같이 파일 다운로드를 시작합니다.
디버그 모드를 걸어놨기 때문에, 파일 다운로드가 지연되고 있는 것을 볼 수 있습니다.

위 로그에 찍힌 것처럼 70MB 정도를 write 해봤습니다.
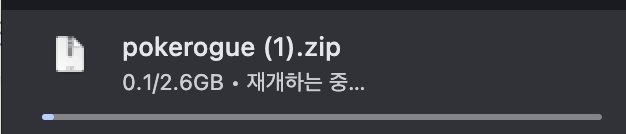
다운로드가 진행되고 멈춘 것을 볼 수 있습니다. 이것만 보더라도 스트리밍으로 파일을 다운로드 받는다는 것을 증명한 것입니다.

위와 같이 대략 300MB 정도 write를 진행하였습니다.
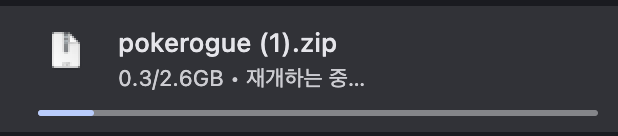
그 결과 거의 약 300MB만큼 데이터를 다운로드 받은 것을 확인할 수 있었습니다.
와이어샤크를 이용하여 확인
조금 더 나아가 와이어샤크를 이용해 들어오는 패킷 레벨에서 분석해보았습니다.
피드백 루프 탭에서 캡쳐해서 확인하였습니다.
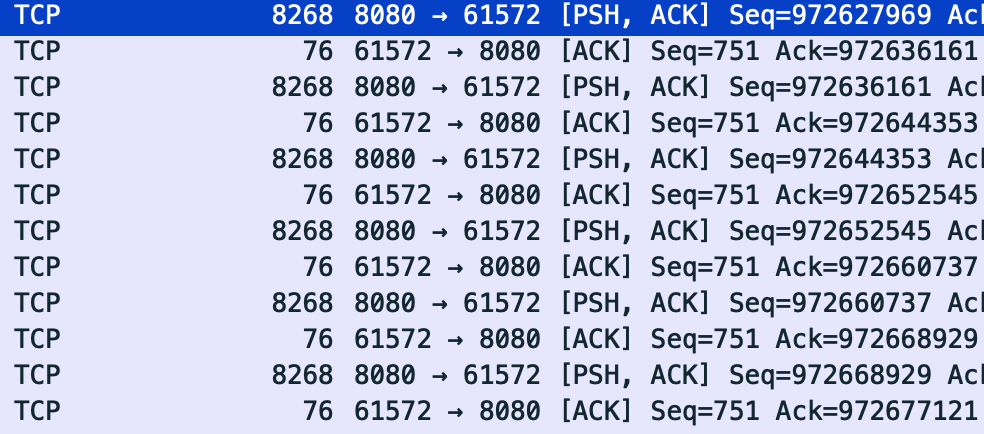
제 파일 다운로드 서버는 8080포트와 연결되어 있습니다.
위에서 보시는 것처럼 반복적으로 TCP 프로토콜로 Length가 8268인 패킷이 8080->61572로 향하는 것을 확인할 수 있습니다.
처음 패킷을 확인했을 때, 의문은 Length가 8268이라는 점입니다.
저는 분명 버퍼 사이즈가 저것 보다 큰 것으로 알고 있는데 패킷은 훨씬 작게 전송되었기 때문이죠.
근데, 조금만 생각해보면 당연합니다. 이는 OS 수준에서 관리되기 때문입니다.
패킷을 버퍼 사이즈만큼 크게 보내면 하나의 데이터를 전송하는데 오버헤드가 클 것입니다.
그래서 이를 OS 수준에서 잘게 나누는 것입니다.
그러면 왜 크기가 8268로 일정한 것일까요?
이는 MTU(Maximum Transmission Unit)에 의해 결정된 것이기 때문입니다.
즉, 패킷 하나당 최대 사이즈가 정의되어 있습니다.
전송하려는 데이터가 크기 때문에 MTU를 기준으로 데이터를 여러 패킷으로 자른 것입니다.
MTU에 관해서는 다음의 링크를 참고해주세요.
3. 조금만 더 깊게 분석해봅시다.
위에서 주목할 코드는 try-with-resources 안에 선언되어 있는 FileInputStream과OutputStream입니다.
FileInputStream은 데이터 저장장치(HDD 혹은 SSD)에 저장된 데이터와
InputStream을 열게 됩니다.
InputStream은 byte 배열로 선언된 buffer의 크기만큼 파일의 데이터를 읽어옵니다.
이에 해당하는 코드는 inputStream.read(buffer)입니다.
이 코드는 파일로부터 데이터를 읽어 buffer에 저장합니다. 그리고 읽은 데이터의 크기를 반환합니다.
다음으로 주목할 부분은 OutputStream입니다.
여기서 OutputStream은 HttpServletResponse가 반환한 스트림입니다.
즉, 이 스트림은 서버에 요청을 보낸 클라이언트와 연결된 통로인 것입니다.
while문의 선언부를 보시면 outputStream.write(buffer, 0, bytesRead)가 있습니다.
outputStream에 write를 함으로써 클라이언트에게 데이터를 전송하는 것입니다.
while문은 FileStream으로 열린 모든 데이터를 읽을 때까지 계속 반복합니다. 만일 모두 읽었다면(EOF) -1을 반환하여 반복문이 멈춥니다.
그렇다면 코드의 마지막에 outputStream.flush()는 무엇일까요?
이 메소드는 outputStream에 남아있는 버퍼의 데이터를 강제로 비우는 메소드입니다.
이러한 메소드를 호출하는 이유는 outputStream의 write메소드의 동작방식 때문입니다.
outputStream의 write메소드는 내부에 버퍼를 가지고 있습니다.
아래는 OutputStream의 구현체인 BufferedOutputStream의 write 메소드입니다.
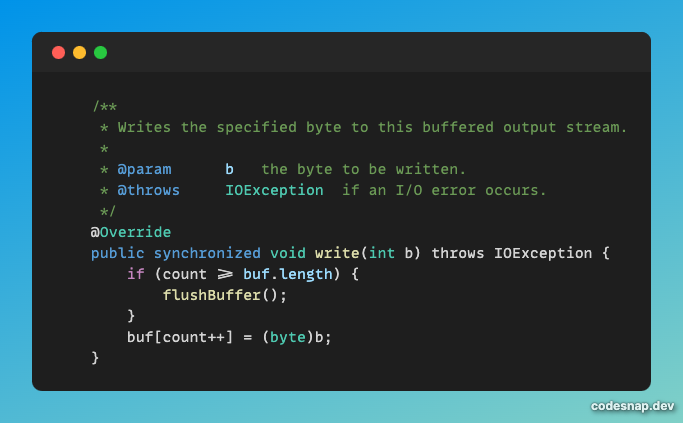
위에서 봤던 write 메소드는 래퍼 메소드로 내부에서 1byte씩 buf에 저장하는 write 메소드를 호출합니다.
OutputStream은 서블릿 컨테이너에 의해 자동으로 생성됩니다.
따라서 저의 경우 서블릿 컨테이너인 Tomcat이 OutputStream을 생성해주고,
Tomcat에 의해 OutputStream의 버퍼 사이즈도 결정됩니다.위에 코드에서 만일 buf.length를 count가 넘어버린다면,
flushBuffer() 메소드를 호출하여 데이터를 클라이언트에게 전달합니다.
만일, 파일 데이터를 OutputStream에 write하다가 buf의 사이즈를 넘지 않았다면
데이터가 OutputStream을 통해 전달되지 않을 것입니다.
즉, outputStream.flush()는 혹시나 버퍼에 남아있을 데이터를 클라이언트에게 완전히 전달하기 위해 호출하는 메소드인 것입니다.
4. 결론
이 방식을 활용하면 서버의 OOM을 신경쓰지 않고 클라이언트가
대용량 데이터를 다운로드 받을 수 있도록 만들 수 있습니다.
물론 모든 내용을 다 이해한 것은 아니지만, 블랙박스로 감춰져있던 비밀이
어느 정도 해결된거 같아 마음이 후련하네요.😌
더 깊은 이해를 위해 앞으로 서블릿과 스트림에 관해 더 공부해보려고 합니다.
그럼 다음에 뵙도록 하겠습니다!
참고자료
