DOM 이란?
문서 객체 모델(Document Object Model)
HTML, XML 문서에 접근하기 위한 일종의 interface 이다.
이 객체 모델은 문서 내의 모든 요소를 정의하고, 각각의 요소에 접근하는 방법을 제공합니다.
넓은 의미로 웹 브라우저가 HTML 페이지를 인식하는 방식을 의미합니다.
조금 좁은 의미로 본다면 document 객체와 관련된 객체의 집합을 의미할 수도 있습니다.
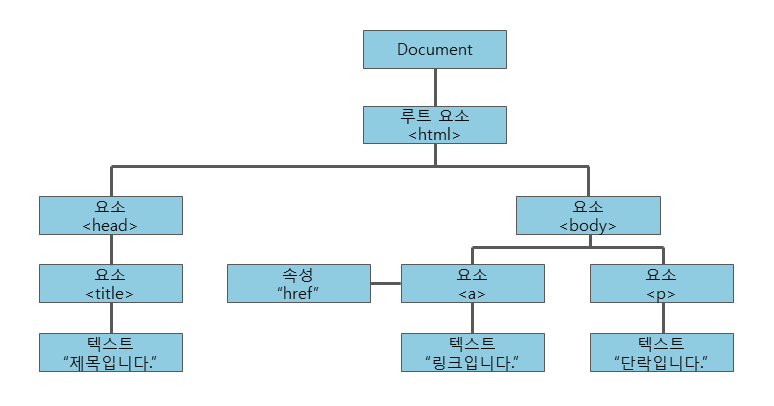
DOM은 문서의 구조화된 표현(structured representation)을 제공하며 프로그래밍 언어가 DOM 구조에 접근할 수 있는 방법을 제공하여 그들이 문서 구조, 스타일, 내용 등을 변경할 수 있게 돕는다.
DOM 은 구조화된 nodes와 property와 method를 갖고 있는 objects로 문서를 표현한다.
이들은 웹 페이지를 스크립트 또는 프로그래밍 언어들에서 사용될 수 있게 연결시켜주는 역할을 담당한다.
DOM 을 사용하기 위해 특별히 해야할 일은 없다.
각각의 브라우저는 자신만의 방법으로 DOM 구현하였으며, 이로 인해 실제 DOM 기준을 따르는지 확인해야 하는 번거로움이 발생하였다.
모든 웹 브라우저는 스크립트가 접근할 수 있는 웹 페이지를 만들기 위해 어느 정도의 DOM 을 항상 사용한다.
문서 객체 모델(DOM)은 메모리에 웹 페이지 문서 구조를 표현함으로써 스크립트 및 프로그래밍 언어와 페이지를 연결합니다. 이때 스크립트는 주로 JavaScript를 의미하나 HTML, SVG, XML 객체를 문서로 모델링 하는 것은 JavaScript 언어의 일부가 아닙니다.
DOM은 문서를 논리 트리로 표현합니다. 트리의 각 브랜치는 노드에서 끝나며, 각 노드는 객체를 갖습니다. DOM 메서드를 사용하면 프로그래밍적으로 트리에 접근할 수 있습니다. 이를 통해 문서의 구조, 스타일, 콘텐츠를 변경할 수 있습니다.
노드는 이벤트 처리기도 포함할 수 있습니다. 이벤트가 발생한 순간, 해당 이벤트와 연결한 처리기가 발동합니다.
HTML을 자바스크립트로 모델링한게 DOM(Document Object Model)이며
DOM을 잘게 쪼개면 node 단위이며 이 node는 트리 구조로 되어있다.
자바스크립트는 HTML 조작에 특화된 언어
그런데 자바스크립트가 어떻게 HTML을 조작할 수 있는지 원리를 생각해본 적이 있습니까.
생각해보면 HTML과 자바스크립트는 다른 언어입니다.
그래서 자바스크립트에선 <p></p> 이런 html을 직접 해석하고 조작할 수 없습니다.
자바스크립트는 <p> 이런건 못알아듣습니다.
그런데 어떻게 HTML 태그들을 알아보고 조작할 수 있는 것일까요?
자바스크립트가 HTML 조작을 하기 위해선 HTML을 자바스크립트가 해석할 수 있는 문법으로 변환해놓면 됩니다.
HTML을 자바스크립트가 좋아하는 array 혹은 object 자료형에 담아버리는게 좋지 않을까요?
그래서 실제로 브라우저는 HTML 페이지를 열어줄 때
HTML을 자바스크립트로 쉽게 찾고 바꾸기 위해 object와 비슷한 자료형에 담아줍니다.
예를 들어서
<div style="color : red">안녕하세요</div>
브라우저는 이런 HTML을 발견하면 object 자료로 바꿔서 보관해둡니다.
구체적으로는 var document = { } 이런 변수를 하나 만들어서 거기 넣어줍니다.
var document = {
div1 : {
style : {color : 'red'}
innerHTML : '안녕하세요'
}
}▲ 대충 이렇게 object 자료에 정리를 해놓는다는 소리입니다.
왜냐고요? 이래야 저렇게 점찍어서 원하는 자료를 출력하고 조작하고 할 수 있지 않겠습니까.
이제 document.div1.innerHTML = '안녕' 이렇게 자바스크립트를 짜면 HTML 조작이 가능할듯
그래서 저렇게 object에 담아두는 것입니다.
(물론 실제 DOM과 생김새는 좀 다르겠지만)
위 변수를 document object라고 부릅니다. 간지나게 + model이라고 붙여서 Document Object Model이라고 합니다.
요약하자면 자바스크립트가 HTML에 대한 정보들 (id, class, name, style, innerHTML 등)을
object 자료로 정리한걸 DOM이라고 부릅니다.
브라우저는 HTML 문서를 위에서 부터 읽으며 DOM을 생성합니다.
브라우저는 HTML문서를 위에서 부터 차례로 읽어내려갑니다.
읽을 때 마다 HTML을 발견하면 DOM에 추가해줍니다.
그래서 이걸 알면 왜 하단 코드가 에러가 나는지도 알 수 있겠군요.
(html 파일)
<script>
document.getElementById('test').innerHTML = '안녕'
</script>
<p id="test">임시글자</p>이렇게 코드짜면 에러가 납니다.
왜냐면 브라우저는 HTML을 위에서부터 한줄한줄 읽습니다.
그런데 갑자기 자바스크립트로 <p id="test">인 요소를 DOM에서 찾고 바꾸라고하는겁니다.
그래서 에러가 날 뿐입니다.
왜냐면 아직 <p id="test">를 읽기 전이라 p태그에 대한 DOM이 아직 생성되지 않았으니까요.
이렇듯 자바스크립트는 DOM이 생성된 경우에만 HTML을 변경할 수 있습니다.
혹은 자바스크립트 실행을 약간 나중으로 미루는 방법도 있음
"이 코드는 HTML 전부 다 읽고 실행해주세요" 라고 코드짜놓을 수 있습니다.
그러면 아까 예제같은 문제가 발생하지 않습니다.
$(document).ready(function(){ 실행할 코드 })
document.addEventListener('DOMContentLoaded', function() { 실행할 코드 }) 둘 중 마음에 드는거 쓰면 됩니다.
이 이벤트리스너들은 "HTML을 다 읽어들였는지"를 알려주는 이벤트리스너입니다.
(html 파일)
<script>
document.addEventListener('DOMContentLoaded', function() {
document.getElementById('test').innerHTML = '안녕'
})
</script>
<p id="test">임시글자</p>그래서 거기 안에 "저 밑에있는 <p id="test">변경해주세요~" 라고 코드 짜도 잘 동작함
그래서 예전스타일 강의들 보시면 ready 아니면 DOMContentLoaded 이벤트리스너를 꼭 쓰라고 가르칩니다.
안정적이니까요.
요즘은 그냥 자바스크립트를 <body>태그 끝나기 전에 전부 작성합니다
자바스크립트 위치를 내가 정할 수 없을 경우에만 유용한 방법이라고 보시면 됩니다.
4. load 이벤트리스너
load 라는 이벤트리스너를 사용하면 DOM 생성뿐만 아니라 이미지, css, js파일이 로드가 됐는지도 체크가능합니다.
이미지 같은게 로드되면 load라는 이벤트가 발생하기 때문입니다.
셀렉터로찾은이미지.addEventListener('load', function(){
//이미지 로드되면 실행할 코드
})이런 식으로 쓰면 됩니다.
근데 외부 자바스크립트 파일에 저걸 적어놓으면
그 js 파일보다 이미지가 더 먼저 로드되는 경우도 있으니 이벤트 발생체크를 못할 수도 있겠군요
$(window).on('load', function(){
//document 안의 이미지, js 파일 포함 전부 로드가 되었을 경우 실행할 코드
});
window.addEventListener('load', function(){
//document 안의 이미지, js 파일 포함 전부 로드가 되었을 경우 실행할 코드
})window에 붙이셔도 됩니다. document에 포함된 이미지, CSS파일 등 모든것이 로드가 되었는지 체크해줍니다.
ready 이런거랑 차이는 앞선 .ready()는 DOM 생성만 체크하는 함수인데,
이것보다 약간 더 나아가서 모든 파일과 이미지의 로드상태를 체크한다고 보시면 되겠습니다.
그래서 이거 써서 "이미지가 다 로드되면 사이트 보여주세요~" 이런 코드짜는 사람들이 있는데
한국인이라면 오히려 속터짐
디버깅
버그를 해결하는 행위.
초기 컴퓨터 개발자 중 한 명인 그레이스 하퍼가 컴퓨터 고장의 원인을 조사하던 중 회로 사이에 나방 한 마리가 끼어있는 것을 발견했다고 합니다. 이 나방 때문에 컴퓨터가 고장났던 것인데, 그때부터 컴퓨터에 어떤 문제가 생길 경우 버그라고 부르게 되었습니다. 그리고 디버깅(debugging)은 버그를 잡는다는 의미로서 잘못된 부분을 찾아 고치는 것을 뜻하게 되었지요.
Document.querySelector()
Document.querySelector()는 제공한 선택자 또는 선택자 뭉치와 일치하는 문서 내 첫 번째 Element를 반환합니다.
일치하는 요소가 없으면 null을 반환합니다.
하나 이상의 선택자를 포함한 DOMString. 유효한 CSS 선택자여야만 하며 아닐 경우 SYNTAX_ERR 예외가 발생합니다.
id, 클래스네임, 태그네임 사용 가능
Document.querySelectorAll()
지정된 셀렉터 그룹에 일치하는 다큐먼트의 엘리먼트 리스트를 나타내는 정적(살아 있지 않은) NodeList 를 반환합니다.
Document.getElementById()
주어진 문자열과 일치하는 id 속성을 가진 요소를 찾고, 이를 나타내는 Element 객체를 반환합니다.
ID는 문서 내에서 유일해야 하기 때문에 특정 요소를 빠르게 찾을 때 유용합니다.
ID가 없는 요소에 접근하려면 Document.querySelector()를 사용하세요.
모든 선택자를 사용할 수 있습니다.
Element.getElementsByClassName()
주어진 클래스를 가진 모든 자식 엘리먼트의 실시간 HTMLCollection 을 반환합니다.
Document의 getElementsByClassName() 메소드는 도큐먼트 루트로부터 도큐먼트 전체를 탐색한다는 점을 제외하고는 동일하게 작동합니다.
Document.getElementsByTagName()
엘리먼트의 HTMLCollection 과 주어진 태그명을 반환합니다.
루트 노드를 포함해 전체 다큐먼트를 대상으로 검색됩니다.
반환된 HTMLCollection 은 살아있는데, 이는 document.getElementsByTagName() 을 다시 호출하지 않아도 자동으로 업데이트하여 DOM 트리와 동기화된 상태를 유지함을 의미합니다.
클래스 이름 설정
element.className = '이름';
기존의 클래스 이름을 모두 삭제하고 새로 설정할 때는
예제 1과 같이 'className' 속성을 사용합니다.
'classList'는 readonly 속성이기 때문에, 직접 값을 지정할 수 없습니다.
클래스 추가
Element.classList.add
명시된 클래스를 추가하는 메서드입니다.
- 클래스 여러개 추가
element.classList.add('이름1', '이름2'...);
element.classList.add() 함수에 파라미터를 여러개 전달하여
한번에 여러개의 클래스를 추가할 수도 있습니다.
클래스 변경
element.classList.replace('변경전이름', '변경후이름');
기존의 class 속성에서 특정 class item을 찾아서, 해당 item의 이름을 변경할 수도 있습니다.
클래스 삭제
Element.classList.remove
명시된 클래스를 제거하는 메서드입니다.
innerText
innerText는 'Element'의 속성으로, 해당 Element 내에서 사용자에게 '보여지는' 텍스트 값을 읽어옵니다.
위 예제에서 'innerText' 버튼을 클릭하면,
아래와 같은 텍스트를 가져옵니다.
원래 div안에는
'안녕하세요? 만나서 반가워요'가 입력되어 있지만,
브라우저가 사용자에게 이 내용을 보여줄 때는, 연속되는 공백은 무시하고 하나의 공백만 처리하여
'안녕하세요? 만나서 반가워요.'라고 보여집니다.
또한, 위 예제의 div는 'display:none' 으로 정의된 텍스트를 포함하고 있습니다.
'display:none'으로 정의된 '숨겨진 텍스트'는 브라우저에서 사용자에게 보여지지 않습니다.
innerText는 이처럼 사용자에게 보여지는 텍스트를 가져옵니다.
사용자가 브라우저에서 div의 내용을 Ctrl+C하여 클립보드에 복사한 내용을 가져온다고 생각하면 이해하기 쉽습니다.
innerText, textContent 차이점
공통점 : 엘리먼트 및 노드에 텍스트를 추가하거나 값을 가져올 수 있는 방법
HTML
<div id='my_div'>
안녕하세요? 만나서 반가워요.
<span style='display:none'>숨겨진 텍스트</span>
</div>
<input type='button'
value='innerText'
onclick='getInnerText()'/>
<input type='button'
value='textContent'
onclick='getTextContent()'/>JS
function getInnerText() {
const element = document.getElementById('my_div');
alert(element.innerText);
}
function getTextContent() {
const element = document.getElementById('my_div');
alert(element.textContent);
} innerText
innerText는 'Element'의 속성으로, 해당 Element 내에서 사용자에게 '보여지는' 텍스트 값을 읽어옵니다.
원래 div안에는
'안녕하세요? 만나서 반가워요'가 입력되어 있지만,
브라우저가 사용자에게 이 내용을 보여줄 때는, 연속되는 공백은 무시하고 하나의 공백만 처리하여
'안녕하세요? 만나서 반가워요.'라고 보여집니다.
또한, 위 예제의 div는 'display:none' 으로 정의된 텍스트를 포함하고 있습니다.
'display:none'으로 정의된 '숨겨진 텍스트'는 브라우저에서 사용자에게 보여지지 않습니다.
innerText는 이처럼 사용자에게 보여지는 텍스트를 가져옵니다.
사용자가 브라우저에서 div의 내용을 Ctrl+C하여 클립보드에 복사한 내용을 가져온다고 생각하면 이해하기 쉽습니다.
textContent
textContent는 'Node'의 속성으로,
innetText와는 달리
위 예제에서 textContent 버튼을 클릭하면,
'안녕하세요? 만나서 반가워요.'의 연속된 공백이 그대로 표현된 것을 확인 할 수 있습니다.
또한, 'display:none' 스타일이 적용된 '숨겨진 텍스트' 문자열도 그대로 출력되는 것을 확인 할 수 있습니다.
