시작하기에 앞서...
네트워크에 대한 기본적인 지식을 정리하는 구간으로서 최대한 빨리 그리고 많이 알아가보고 싶다. 이미 AWS 자격증을 공부하면서 서버와 인터넷 통신간의 기본적인 지식은 얻은 상태지만 기본기 부터 탄탄히 잡을려고 한다.
인터넷 네트워크
인터넷 통신
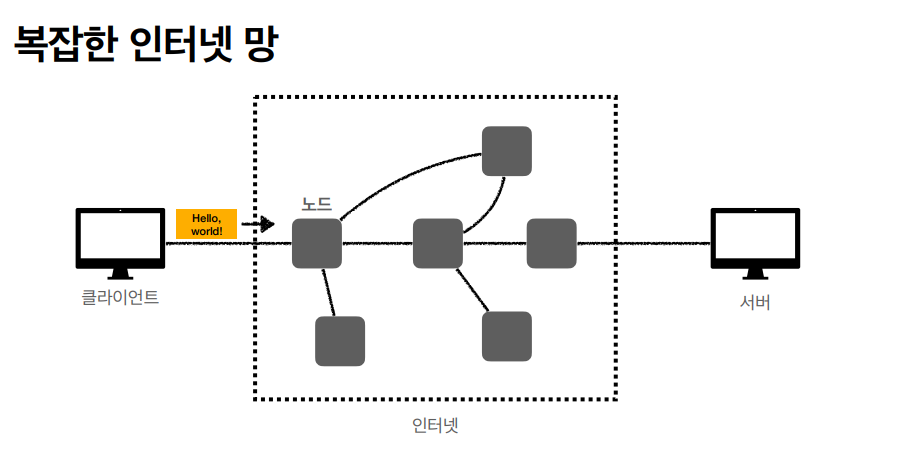
- 인터넷 통신은 기본적으로 복잡한 망을 통해서 이루어진다.
IP (Internet Protocol)
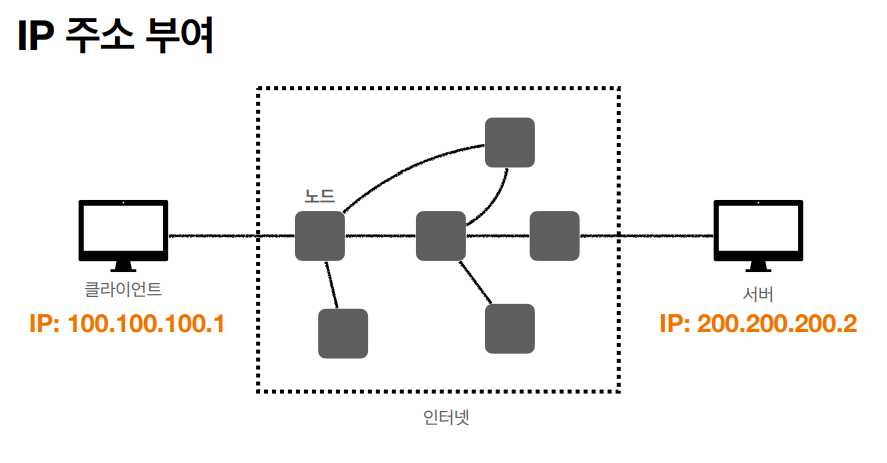
- IP 같은 경우 각 인터넷 (클라이언트, 서버) 에 특정 주소를 부여해주고 통신을 가능하게 만든다.
IP 프로토콜의 역활은 두가지로 나뉘는데,
1. 지정한 IP 주소 (IP Address) 에 데이터 전달
2. 패킷(Packet) 이라는 통신 단위로 데이터 전달
IP 패킷 정보로는,

이렇게 전송이 되는데 기본적인 구조는 이렇다.
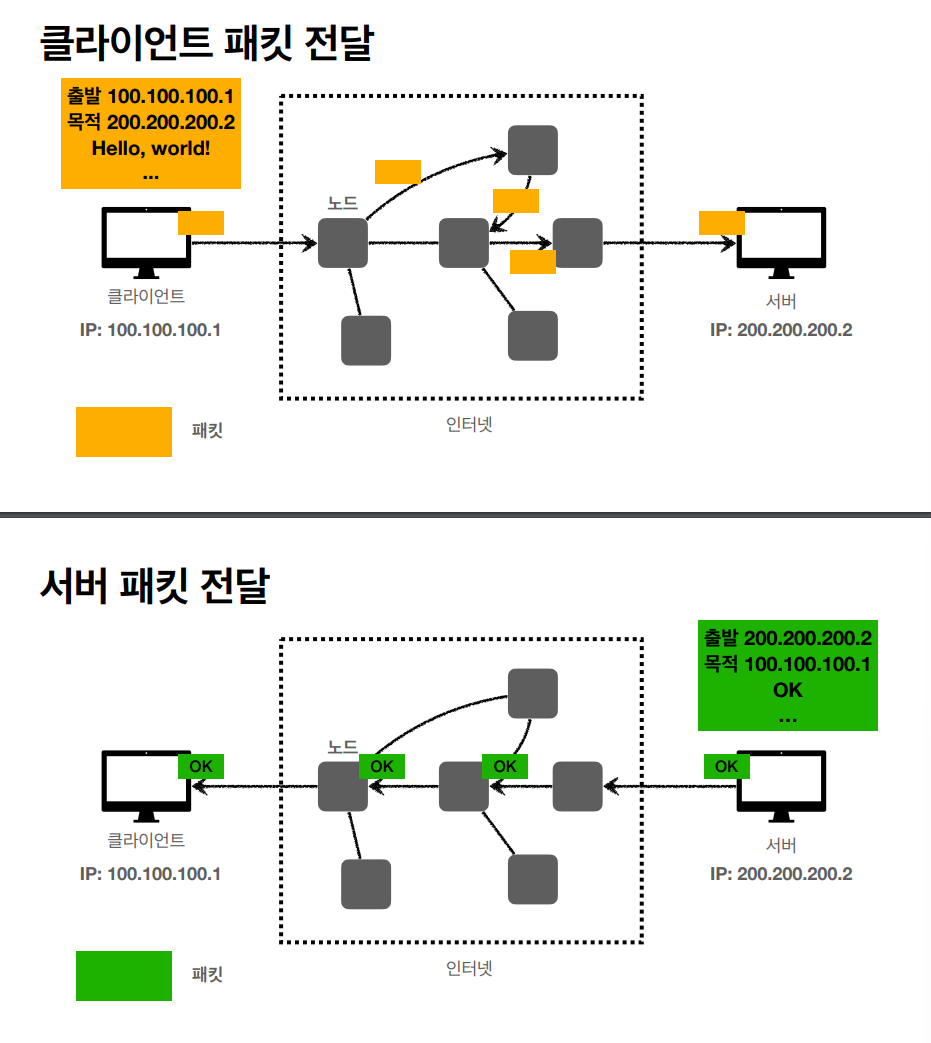
그러나, IP 프로토콜만을 활용하는거는 한계가 있는데
-
비연결성: 패킷을 받을 대상이 없거나 서비스 불능 상태여도 패킷은 그대로 전달이 된다
-
비신뢰성: 중간에 패킷이 사라질수도 있고, 패킷이 순서대로 오지 않을 수도 있다 -> Hello World -> World Hello 순으로 받을 수 있다.
-
프로그램 구분: 같은 IP를 사용하는 서버에서 통신하는 애플리케이션이 둘 이상이여도 문제가 발생한다 **
TCP, UDP
인터넷 프로토콜 스택에는 4개의 계층이 있다
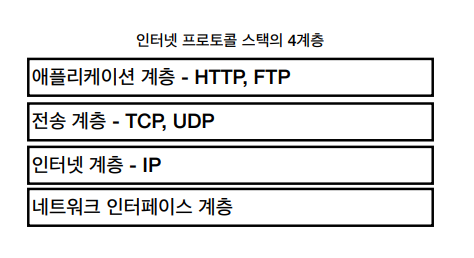
이 계층은 HTTP 아래 차례대로 이어져있는 계층이며 좀 더 구체적으로는 아래의 그림처럼 메세지나 채팅이 전달된다.
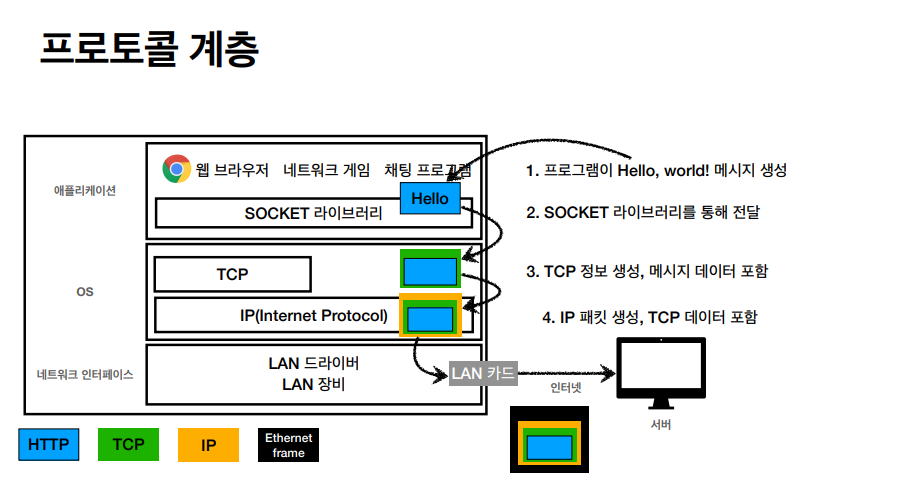
위에서 언급했던 IP 패킷 같은 경우는, 출발지 IP, 목적지 IP, 등등을 주황 태두리로 포함을 했지만 TCP/IP 패킷 같은 경우는 TCP 가 좀 더 디테일한 부분들을 IP 패킷안에 넣게 된다.

TCP 는 현재 대부분의 어플리케이션에서 사용중에 있으면서 가장 신뢰할 수 있는 프로토콜이라고 한다. 그리고 특징으로는 세가지가 있는데

이것을 가능하게 해준다.
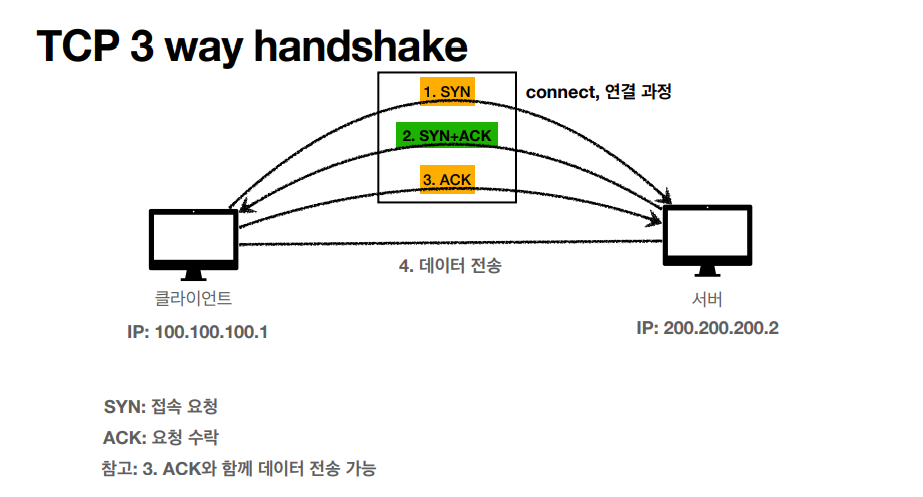
첫번째 가상 연결 같은 경우는, SYN, SYN + ACK, ACK 이 3가지 과정을 통해 IP 패킷만으로는 불가능했던 상대방 서버가 응답 가능한 상태인지를 먼저 확인해주고 데이터를 전송해준다.
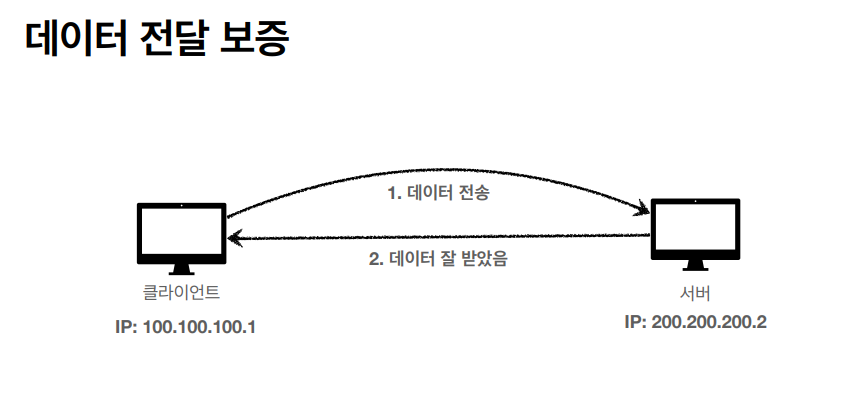
두번째는 데이터 전달 보증, 데이터를 받았을 경우에는 클라이언트가 알 수 있게 해준다.
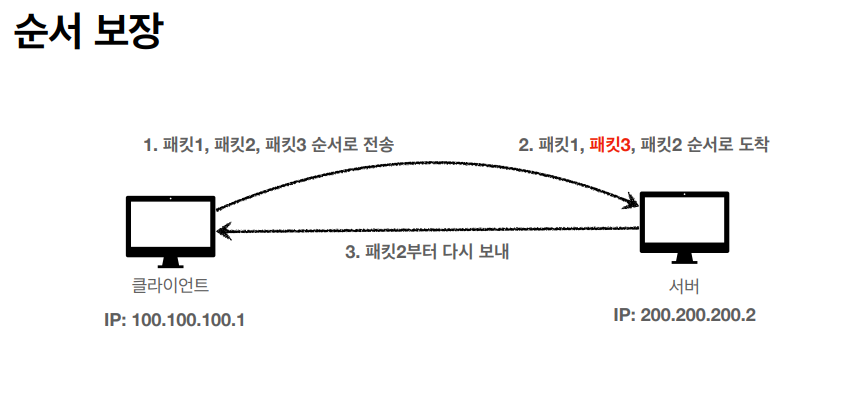
패킷이 혹여라도 잘못된 순서로 오게 될 경우에는, 잘 못 온 패킷에 순서부터 다시 요청을 하게되며 클라이언트가 보낸 순서를 유지 시켜준다.

UDP 같은 경우는 TCP 보다 단순하고 빠른 프로토콜이라고 생각하는게 편한거같다. IP 와 거의같지만 PORT 와 체크섬이 추가된 정도.
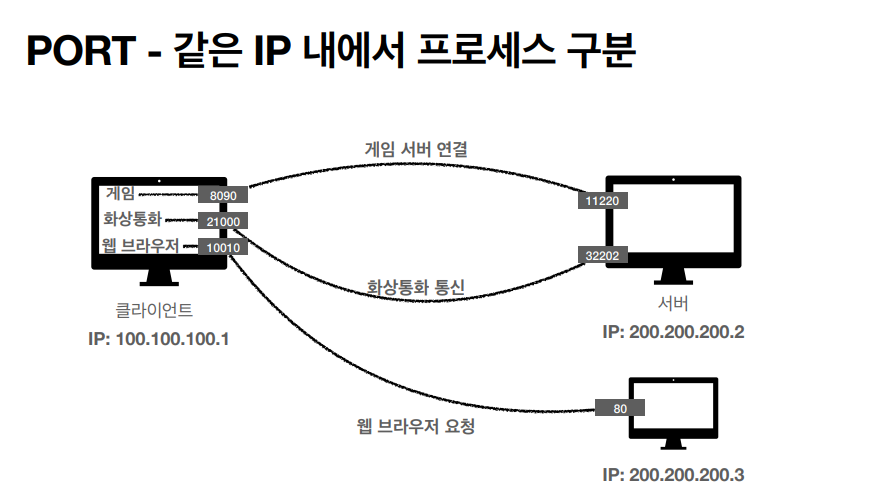
PORT
웹 브라우저에 요청을 할때 한번에 두개 이상 연결해야 하는 경우가 있을것이다. 이때는 두가지에 IP를 구분시켜줄 방법이 필요한데 이때는 위에서 언급한 TCP 정보와 IP 정보에서 보이듯이 PORT 정보로 구분을 가능하게 한다.
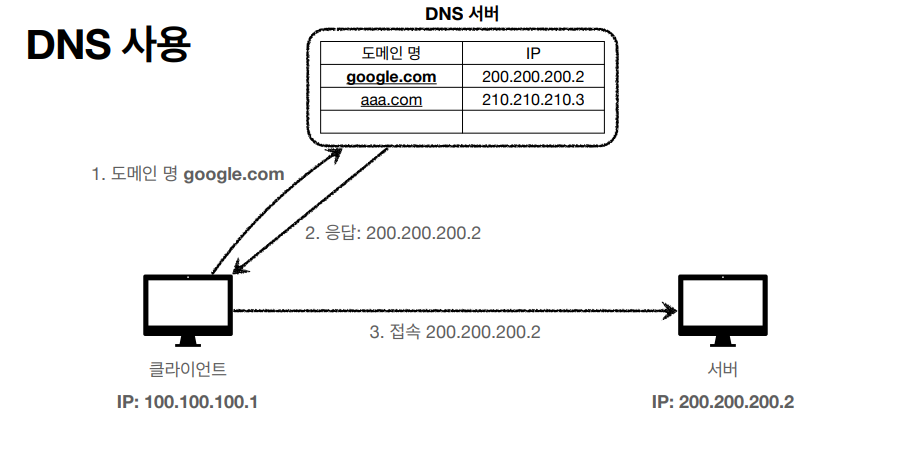
DNS
IP같은 경우는 숫자가 구분하기 상당히 힘들다. 그리고 서버 이전 등, 무슨 이유에서든 IP 주소가 변경이 될 수 있는데 이런 변경점을 클라이언트나 서버끼리 쉽게 알 수 있도록 도와주는게 바로 DNS (Domain Name System) 이다.
전화번호부와 비유하면은 가장 잘 맞는거같다.
URI와 웹 브라우저 요청 흐름
URI
URI 와 URL 은 같은 의미를 부여 할 수 있다. URL 같은 경우 Locator을 뜻하는 말로, 리소스가 있는 위치를 지정해주는 역활을 한다고 한다.

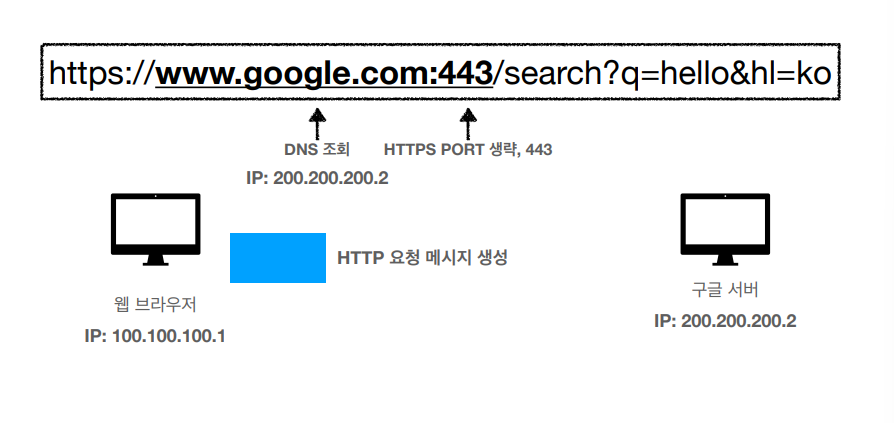
단순한 예로 이런 URL 이 주어졌을때 해석하는 문법은 고정되있다.

scheme 순서대로 읽어보자면은,
Scheme: 주로 http, https 같은 프로토콜을 사용하고 http는 80포트, https는 443 포트를 주로 사용한다
userinfo 는 거의 사용하지 않기때문에 생략
host: 호스트명, 도메인명 또는 IP 주소 입력가능하다
PORT: 접속포트, 일반적으로 생략, 생략시 http 는 80 그리고 https 는 443을 쓴다
/Path: 리소스 경로, 예시로는 /home/file1.jpg, /members, /members/100 등이 있다
query: key = value 의 형태, ?로 시작하고 & 로 추가 가능하다.
fragment, html 내부 북마크 등에 사용하고 서버에 전송하는 정보는 아니다
웹 브라우저 요청 흐름
위에서 언급했던 내용대로, 만약 웹 브라우저가 서버에 어떤 요청 메세지를 보낼때는 이런 과정이 나온다
DNS를 조회하고 포트넘버를 확인한 후에

GET 혹은 POST 등에 요청 메세지를 생성한다
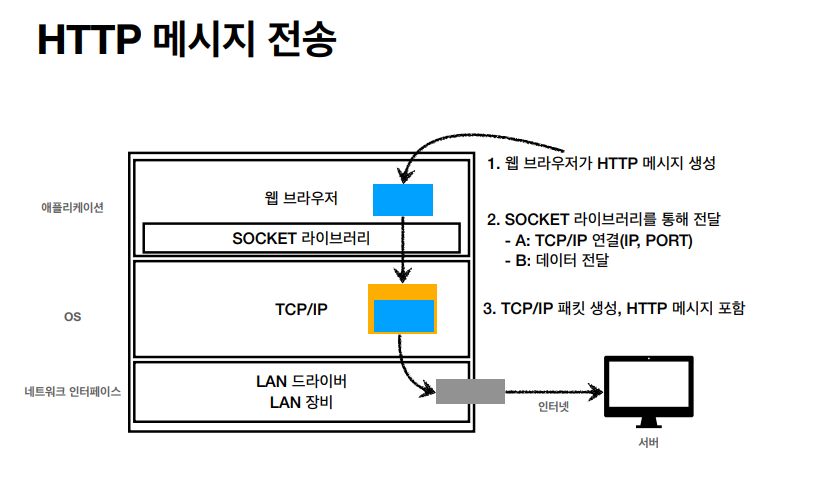
바로 위에 포스트에서도 언급했지만 이런 구조로 흘러서 내려온다. HTTP 메세지를 생성한 후에는 TCP 와 IP 패킷을 생성하고 인터넷으로 흘러서 간다

패킷이 상대 서버에 도달 헀을경우에는 응답 메세지를 또 한번 만들게 되는데

이런 식으로 만들어진 응답 메세지가 서버에서 내 웹 브라우저로 도착하게 되면은 HTML 렌더링 과정을 통해 원하는 정보가 나오게 되는것이다.
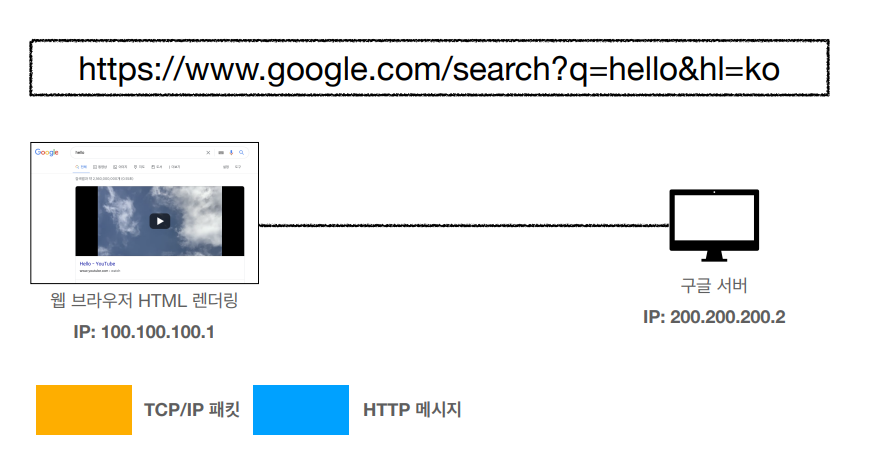
HTTP 기본

HTTP 는 해당 특징들을 가지고 있는데 각 특징 마다 가지고 있는 특색이 있다.
Stateful, Stateless
스테이트풀 상태와 스테이스리스 상태에는 차이점이 존재하는데 스테이트풀 상태같은 경우 이 전에 있었던 요청을 계속 유지 해야한다는 단점이 있다. 강의에서는 이 경우를 매장에 손님과 점원의 비유로 비교했는데

이 예시에서 볼 수 있듯이, 상태유지를 하게 되면 중간에 점원이 바뀔 경우 혼돈이 찾아온다. 여기서 손님과 점원의 관계는 클라이언트와 서버의 관계로도 표현을 할 수 있는데
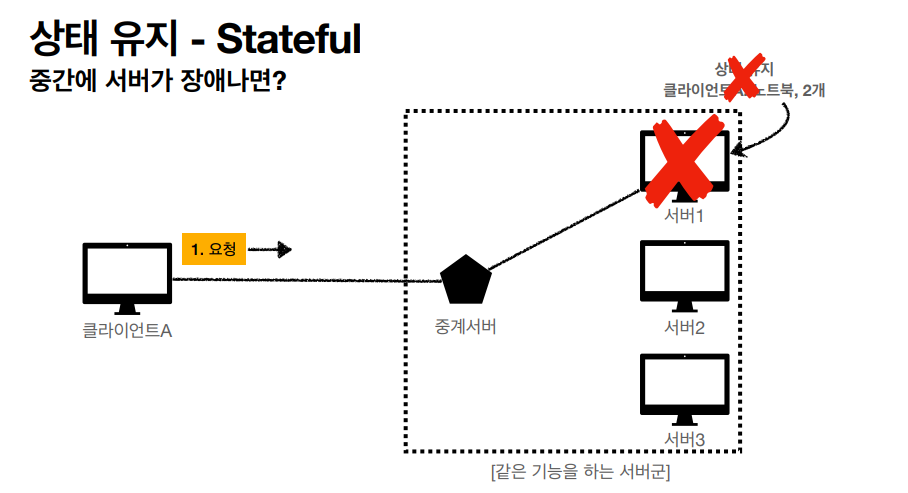
상태유지를 하는 Stateful 상태에서는 유지하고 있던 서버에 문제가 생길경우 다른 서버로의 이전이 힘들어진다
반대로, 스테이트리스 상태인 경우에는 요청하는 메세지가 길어지는 단점외에는 이 전에 있었던 상태가 어떤지 상관이 없다는 장점이 있다. 손님과 점원의 관계로 비교하면

이렇게도 표현을 할 수 있었다. 즉, 중간에 점원이 바뀌어도 문제가 없었단것이다. 이것을 클라이언트와 서버의 관계로 바꾼다면
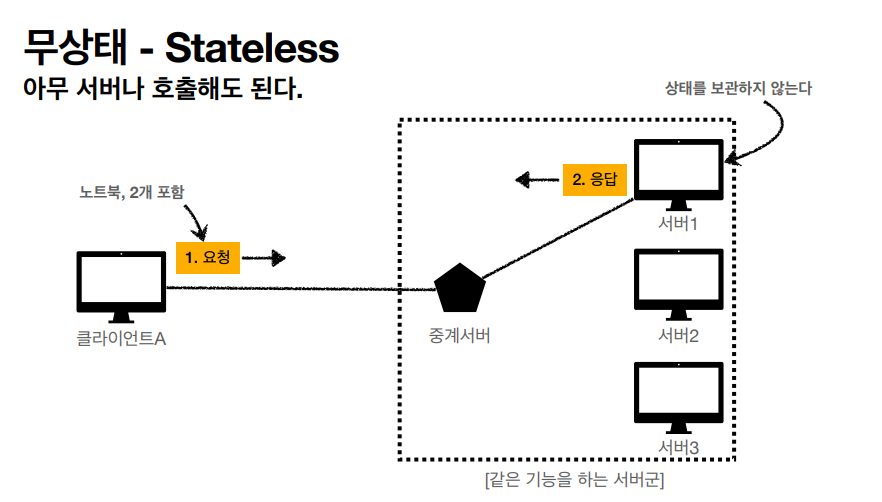
어떤 서버를 호출해도 마치 어느 점원이라도 요청을 처리할수 있는것처럼 가능하다는것이다.
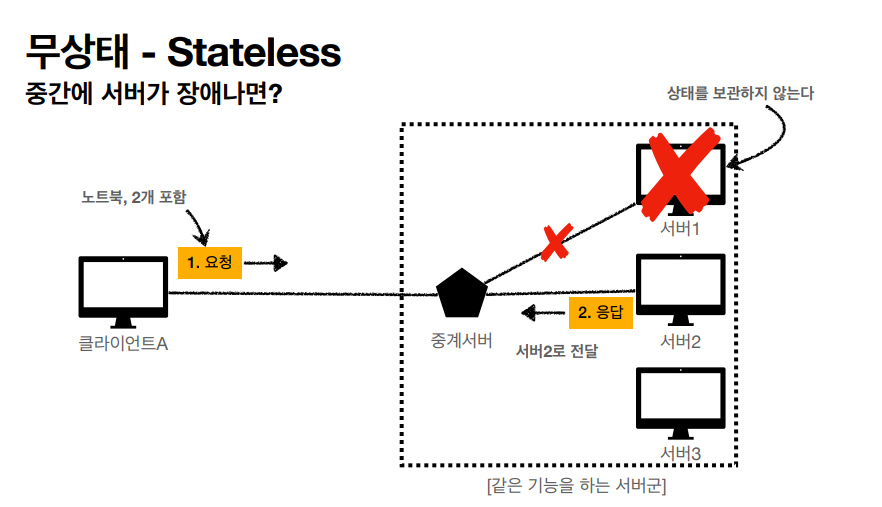
장애가 나온다 하더라도 다른 서버에서의 응답도 가능하게 할 수 있다.
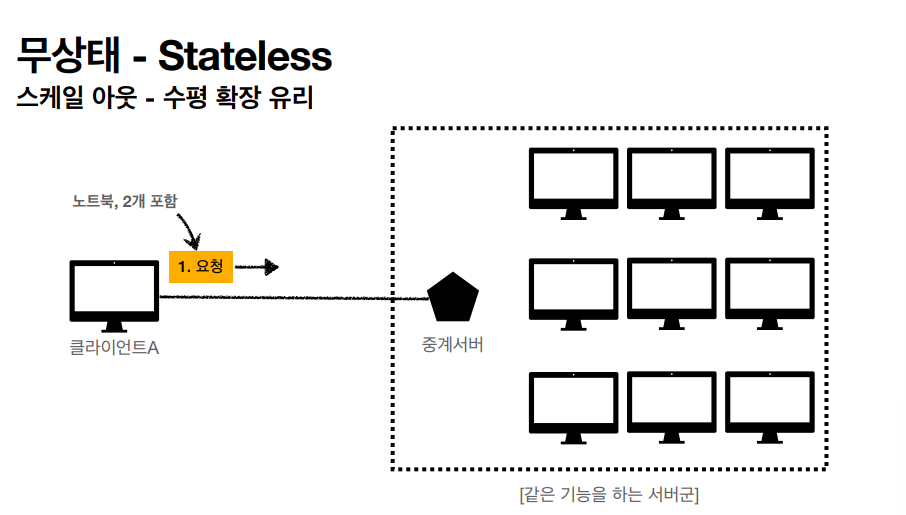
마지막으로 확장또한 가능하다는 장점까지 포함했다.
장점을 나열한다면 다음과 같다,
- 서버가 클라이언트의 상태를 보존 안해도 된다
- 장점: 서버 확장성이 높다 (Scale out)
- 단점: 클라이언트가 추가 데이터를 전송한다
당연하게도 스테이리스 상태를 유지하는게 훨씬 유리하지만 상태유지를 해야하는 로그인 같은 화면에서 우리는 브라우저 쿠키와 서버 세션등으로 상태를 어쩔수 없이 유지 해야하는 경우도 있다.
비 연결성(connectionless)
연결을 유지하는 모델과 연결을 유지하지 않아도 되는 모델은 실용성에서 확연한 차이를 보인다.
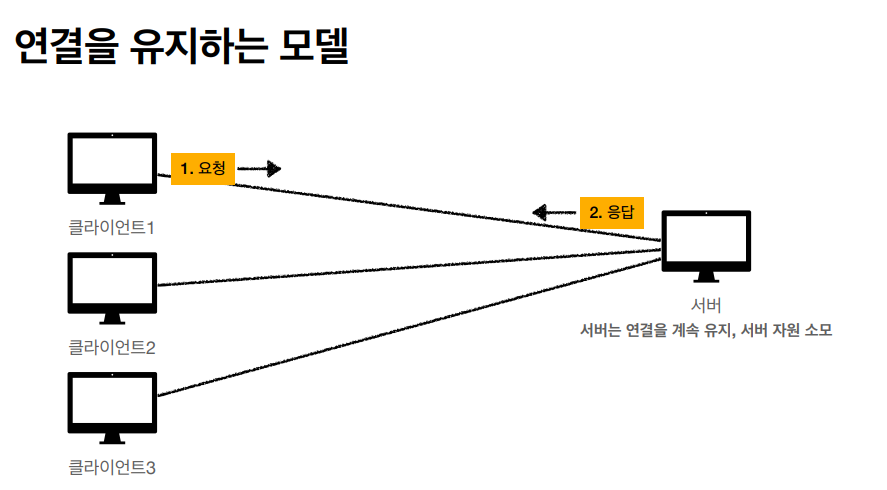
연결을 유지할 경우 어떤 요청과 응답의 시간이 끝나더라도 계속 유지하기때문에 당연히 서버 자원은 그만큼 더 많이 소모된다.

비연결성을 유지함으로서 우리는 자원을 효율적으로 사용하고
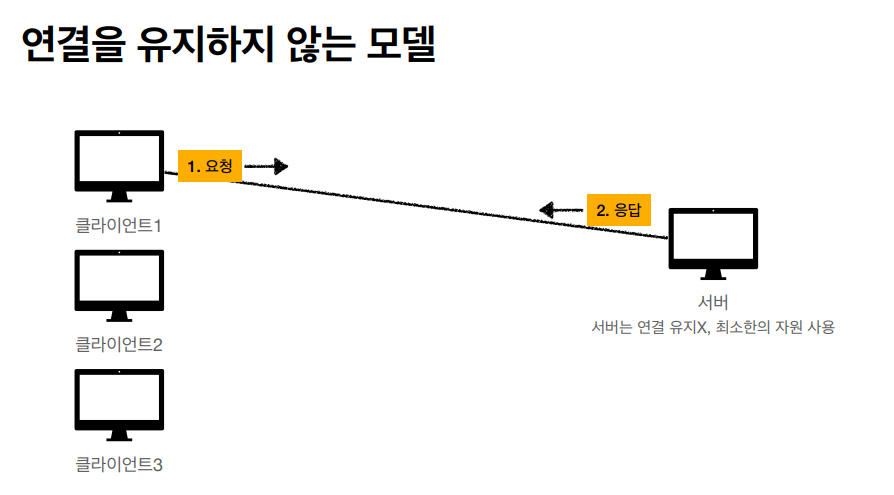
이렇게 요쳥과 응답이 끝난 모델 같은 경우 비연결성을 사용함으로 자원을 아낄 수 있다.
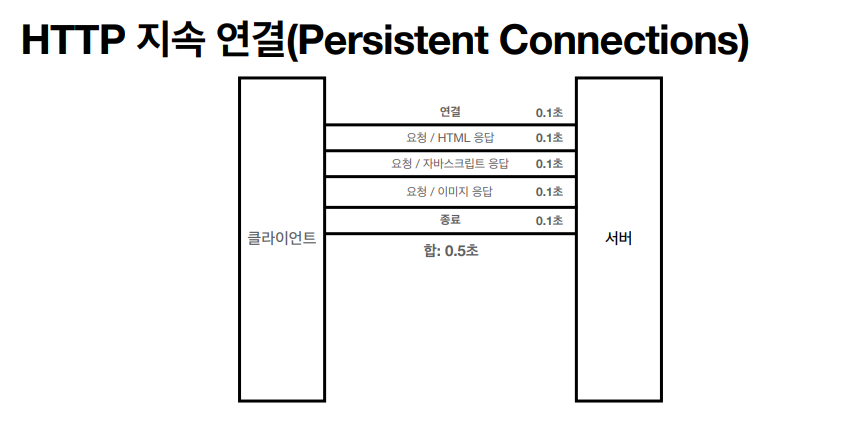
그러나, 이런류의 모델은 TCP/IP 연결을 새로 맺어야 함으로, 3 way handshake 시간이 추가 된다. 그러나 지금은 HTTP 지속 연결 (Persistent Connnections) 로 문제를 해결하고 있다.
HTTP 메세지
HTTP는 기본적으로 요청과 응답메세지 구조로 상태를 공유하는데 구조는 다음과 같다,
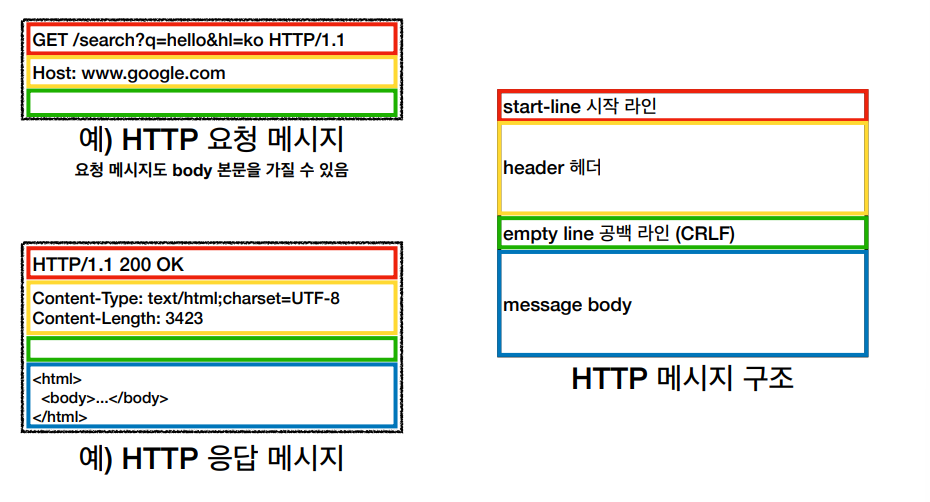
시작라인 같은 경우 GET/POST/PUT/DELET 등 다양한 요청을 할수도 있다.
그 외에 헤더와 메세지 구조 같은 경우에는 HTTP 전송에 필요한 모든 부가정보가 추가적으로 들어가있고 바디에는 실제 전송할 데이터 정보가 다음과 같이 들어있다.


HTTP 메서드
HTTP 메서드에 대한 기본적인 설명을 들었다. HTTP API를 만들때는 리소스를 이용한 설계가 중요하다고 말했다.

조회, 등록, 수정 등등 API 를 만들때 저렇게 하나하나 이름을 짓는게 아닌 리소스인 Member 자체로만 설계하는게 좋다고 하였다.

추후에 설명할 HTTP 메서드 설명을 보면은 어떤식으로 만들지 더 이해가 되겠지만 특정하게 read, create 등등을 적는게 아닌 members 라는 리소스 하나로 모든 API를 설계했다.

대표적인 HTTP 메서드 종류이다. 가장 대표적으로 쓰이는것들은 GET 하고 POST 인데 각 메서드마다 사용방법과 동작방법이 조금씩 달랐다.

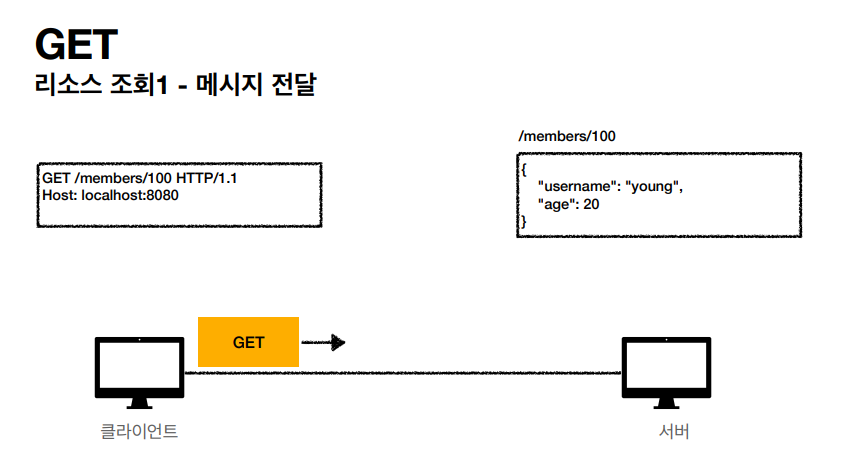
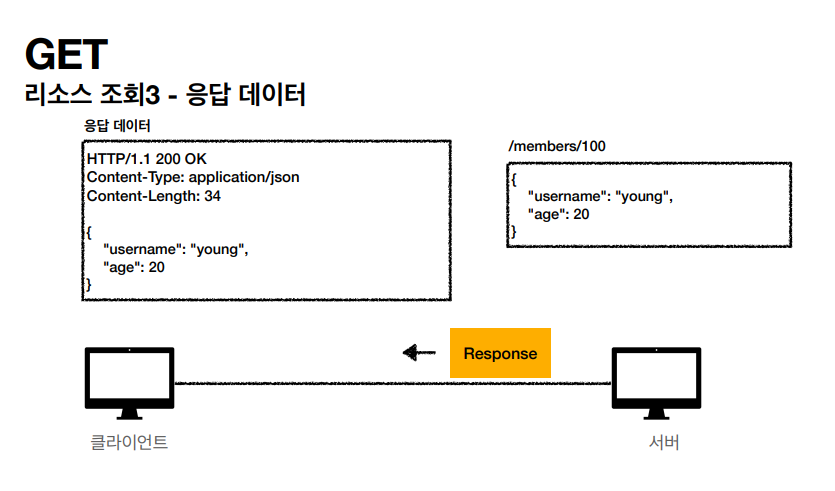
GET 메서드를 내가 원하는 리소스, /members/100 에 접근하고 서버가 응답하는 답을 통해서 JSON 형태의 Body를 받아 원하는 정보를 출력한다.

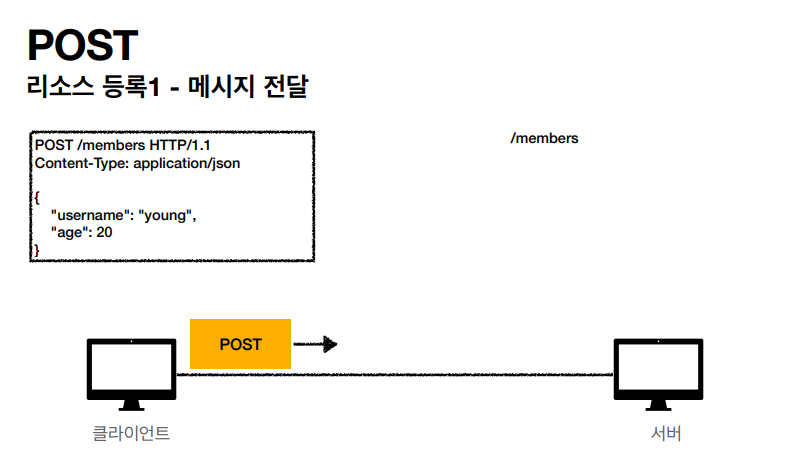
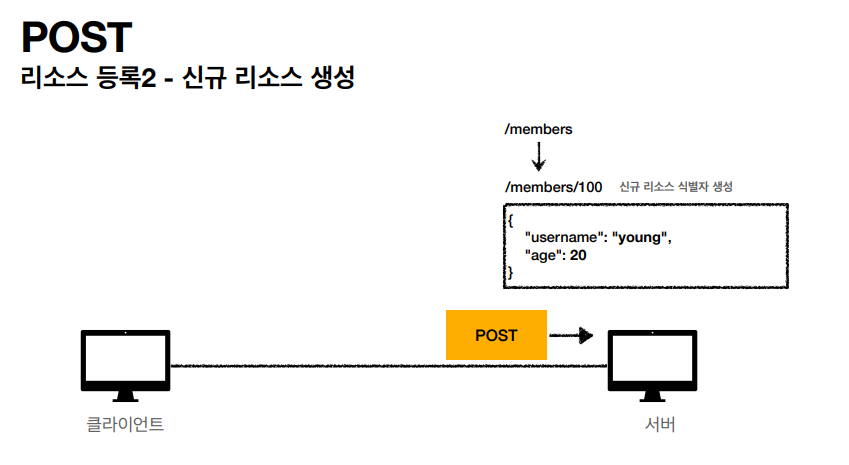
POST 같은 경우 HTTP 메서드 중 에서도 꽤 중요한 부분을 차지하기 때문에 더 자세한 설명을 했지만, 정리하자면 아래와 같다.

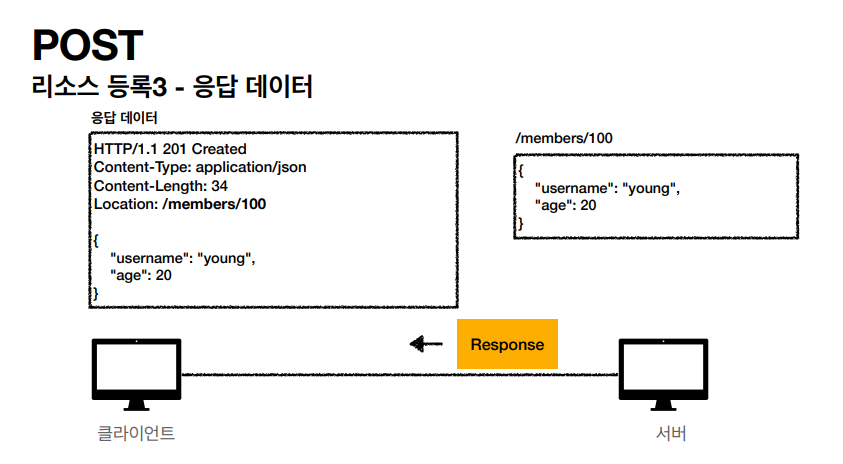
위에서 설명했던 POST 동작 방식에서 가장 중요한거는 새 리소스를 생성 (등록) 하는 부분인거 같다. 분명 나는 post 를 할때 /members 로만 보냈었는데 서버는 Body 부분을 등록을 해준다음에 새로운 리소스의 형태로 /members/100 로 응답을 해주었고 Location 필드에 새로운 리소스가 생성됐다.

PUT 같은 경우는 업데이트를 위해 쓰는 메서드라고 생각하면 되지만, POST 같은 경우는 서버가 식별 되지 않는 새 리소스를 생성하는 점이 있지만 PUT 같은 경우는 클라이언트가 리소스를 식별 해야한다는 부분이 있다.
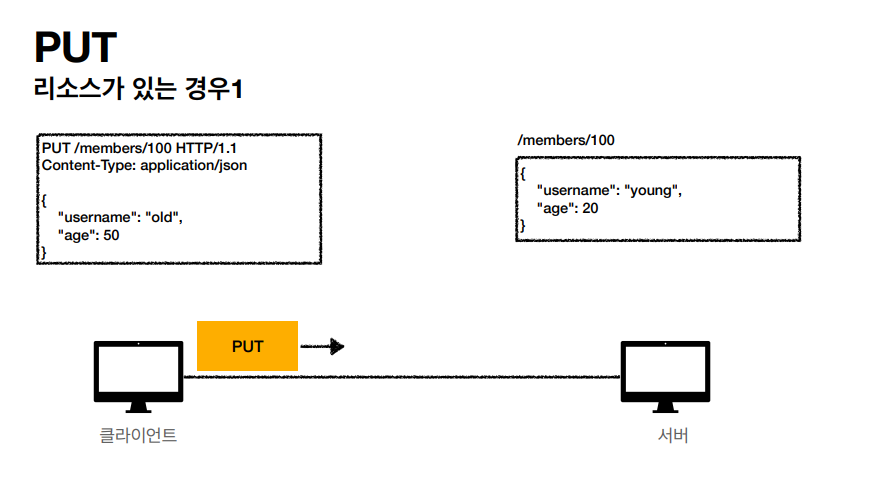
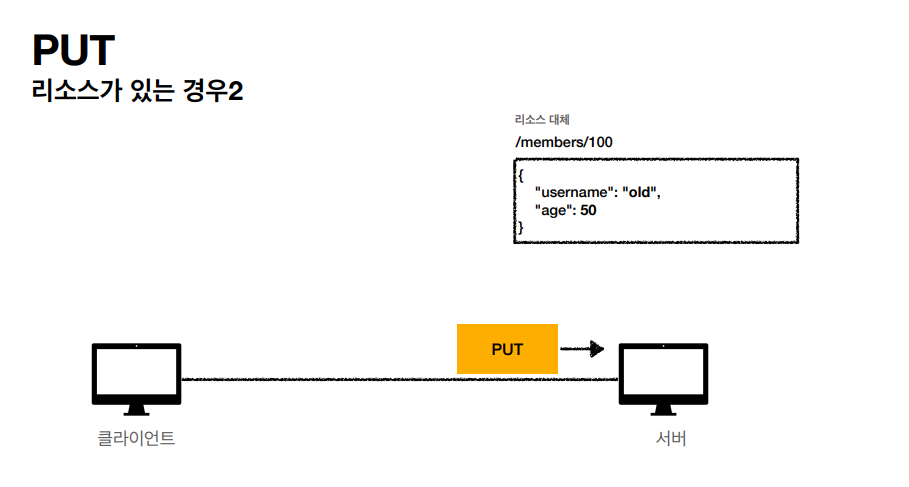
/members/100 같이 리소스스를 세부적으로 넣어서 PUT 메서드를 실행하고있다.
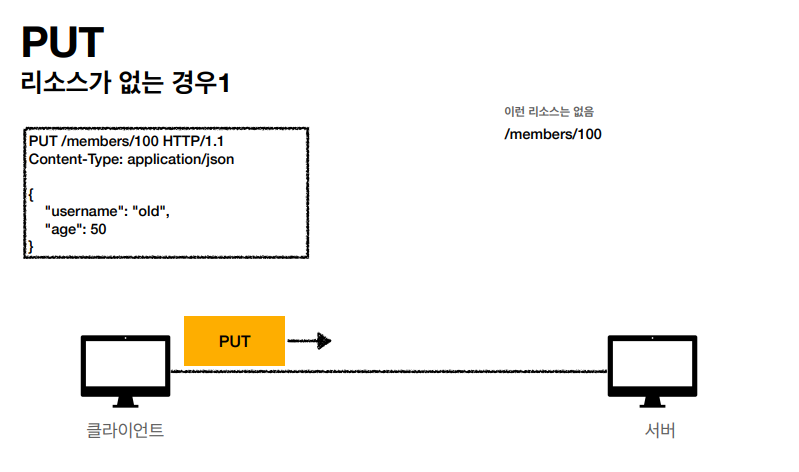
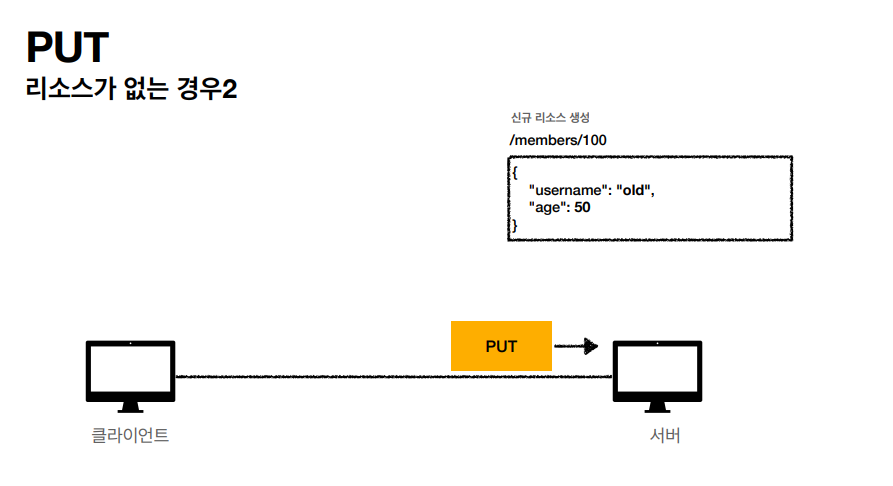
리소스가 없는 경우에는 이렇게 생성하기도 한다. PUT 같은 경우 리소스를 완전히 대체해서 필드를 업데이트 할때 기존에 서버에 남아있는 필드마저도 전부 대체할수있다.
PATCH - 리소스 부분 변경, PUT 으로 완전 덮혀지는 것을 방지하기 위해서다
DELETE - 말 그대로 리소스를 제거 하는거
HTTP 메서드 활용


대표적인 예를 설명 해주었다, GET 같은 경우는 검색을 하는데 쓰이고 나머지 POST, PUT, PATCH 등등은 메세지 바디를 통해서 전송하는 방식으로 주로 회원가입, 상품 주문 등에 쓰인다는 점. 그리고 HTML Form 을 통한 데이터 전송 방법이 있다는것을 배웠고 API 를 통해서 데이터를 전송할수도 있다는것을 배웠다.
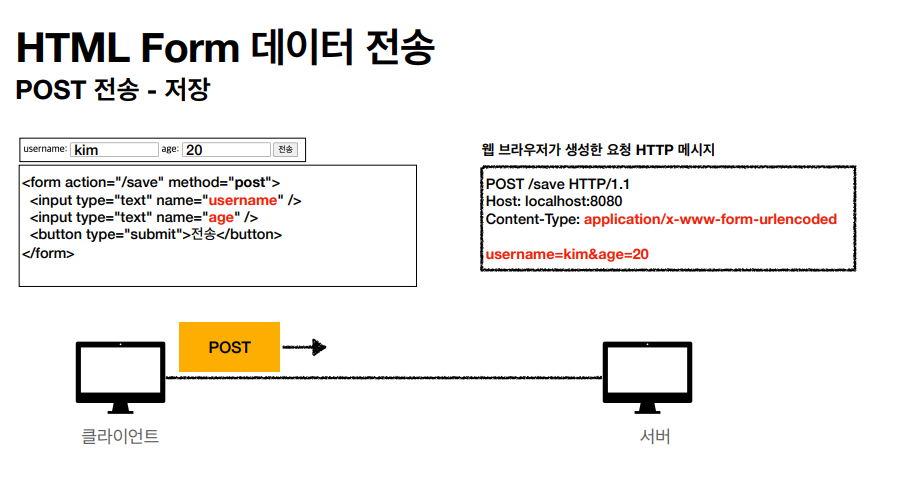
HTML Form 에서 포스트 방식으로 데이터를 저장하고 보내는 방법을 표현한 그림이다.

좋은 정보였던거같다, HTML Form 에서 POST 를 누른 순간 데이터는 전송이 되고 GET 과 POST 만 지원한다고 하였다.

그 외에도 HTTP API 를 통해서 데이터를 전송할수 있지만 자바스크립트 등을 사용해서 통신에 사용된다고 했다.

가장 기본적인 회원 관리 시스템 또한 이런식으로 등록이 가능하다,

HTTP 상태코드
중요한 내용만 요약해서 적어보겠다

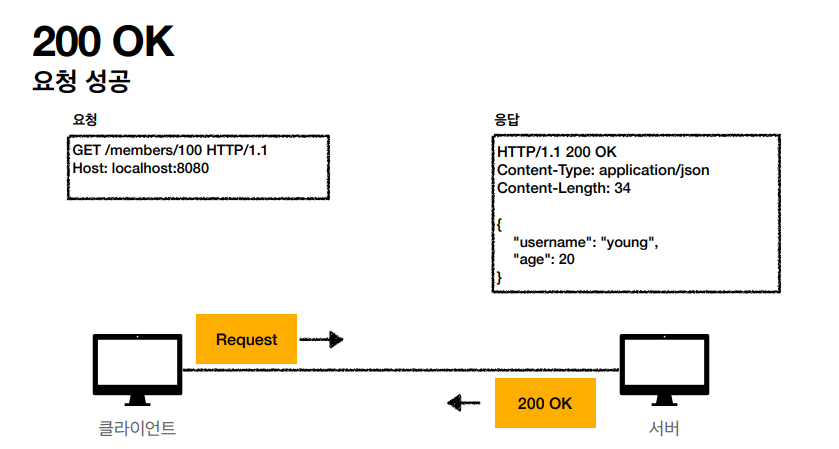
클라이언트 요청이 성공적으로 처리 되었을경우 위에 상태코드가 리턴이 되는데, 200OK 가 가장 흔하게 사용되는것 같다.
3xx 같은 경우는 리다이렉션 요청을 처리하기 위해 필요한 상태코드라고 설명을 했는데

이 후에 캐시 설명에서 나오는 304 NOT MODIFIED 가 가장 흔하게 사용된다.
나머지, 4xx 는 클라이언트 오류고 5xx는 서버 오류다.
HTTP 헤더1, 일반 헤더
HTTP 헤더에는 HTTP 전송에 필요한 많은 부가정보가 들어있다.

그냥 대표적인거 몇개만 나열해보겠다.


컨텐트 쪽이 가장 많은 부분을 차지한는거 같다.
특별한 정보 또한 포함 할 수 있는데 HOST 정보가 가장 중요하다.

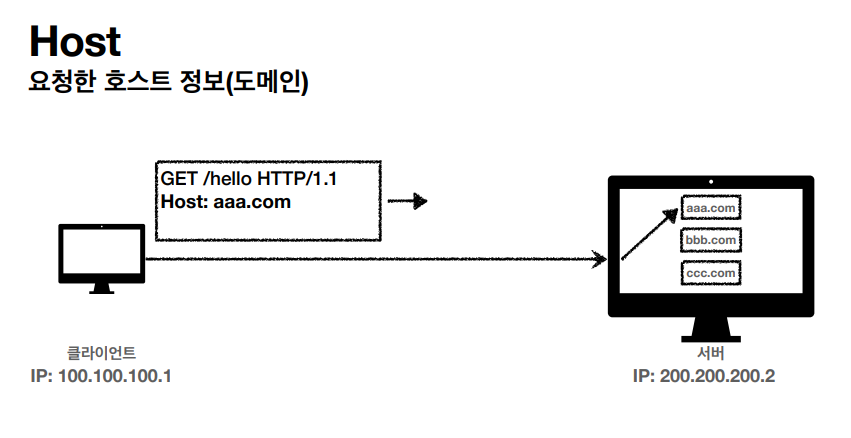
호스트 정보를 나열 하지 않으면은 내가 보낸 HTTP 요청에 여러가지 도메인을 한번에 처리 할 수 있는 서버 애플리케이션이 응답을 못한다. 그렇기 때문에 구체적으로 어떤 호스트인지를 포함시키는게 중요하다.

쿠키에 사용또한 이번 섹션에 중요한 정보 중 하나였는데 기본적으로 HTTP는 무상태 (Stateless) 프로토콜이다, 그렇기 때문에 클라이언트와 서버가 요청과 응답을 주고받으면 연결이 끊겨지고 기억을 하지 못하는데, 이것은 로그인을 해야 볼 수 있는 웹사이트를 사용할 경우 매우 치명적이고 쿠키는 이럴때 사용된다.
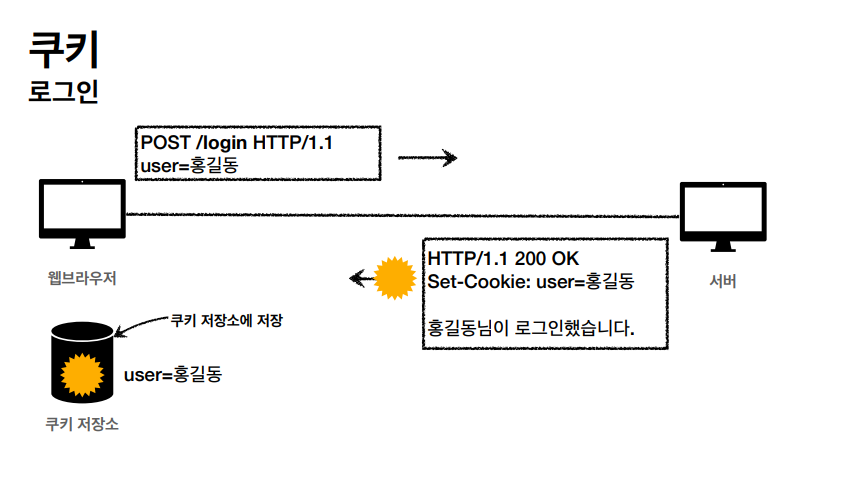
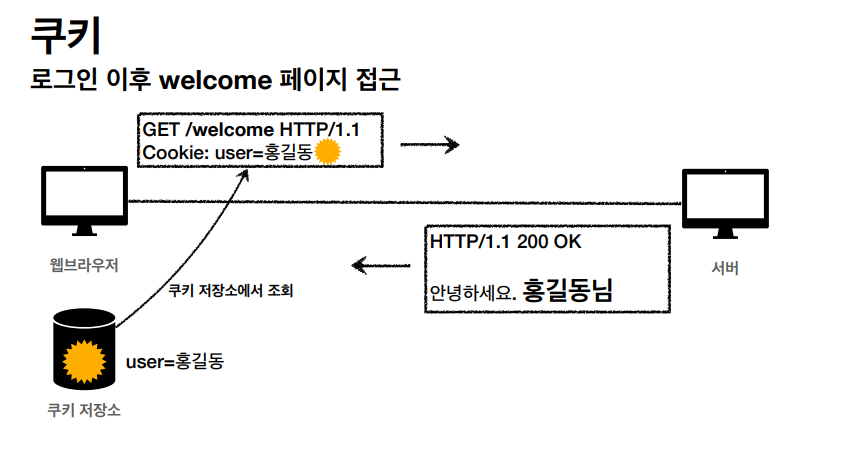
쿠키의 생명주기, 경로, 보안 또한 따로 설정할 수 있다.
HTTP 헤더 2
캐시 (Cache) 에 대한 중요한 컨셉을 배웠다.
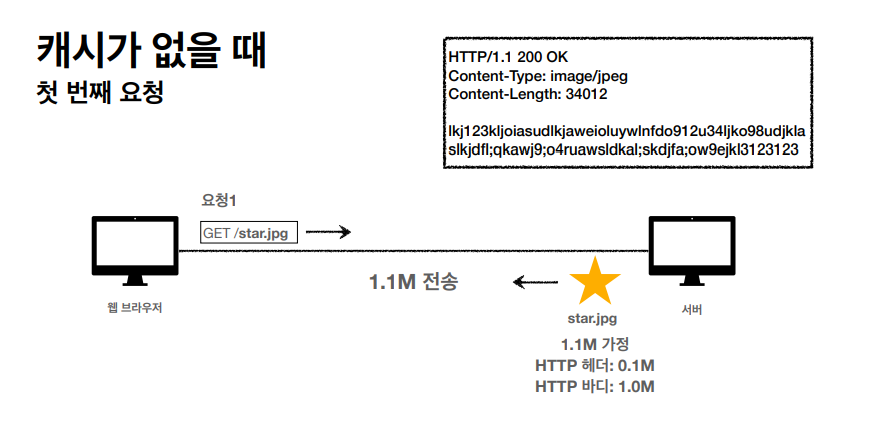
웹상, 캐시가 존재하지 않다면 위와 같은 요청이 한번 이상 들어왔을때 서버는 같은 자료를 계속 포함해서 응답해야하고 이것은 브라우저 로딩 속도를 매우 느리게 만든다.
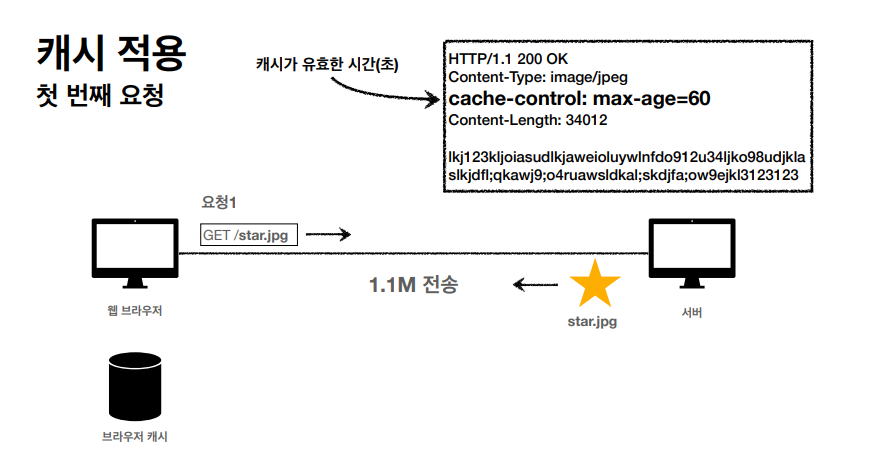
캐시를 위와 같이 적용하면,
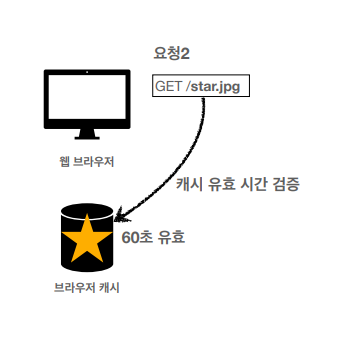
첫 요청에 원하는 정보를 캐시에 저장하고 그 이후에 요청에서 캐시에서 정보를 꺼내서 응답을 한다.
캐시를 적용한다면, 비싼 네트워크 사용량을 줄일수있고 빠른 사용자 경험을 가능하게 한다.
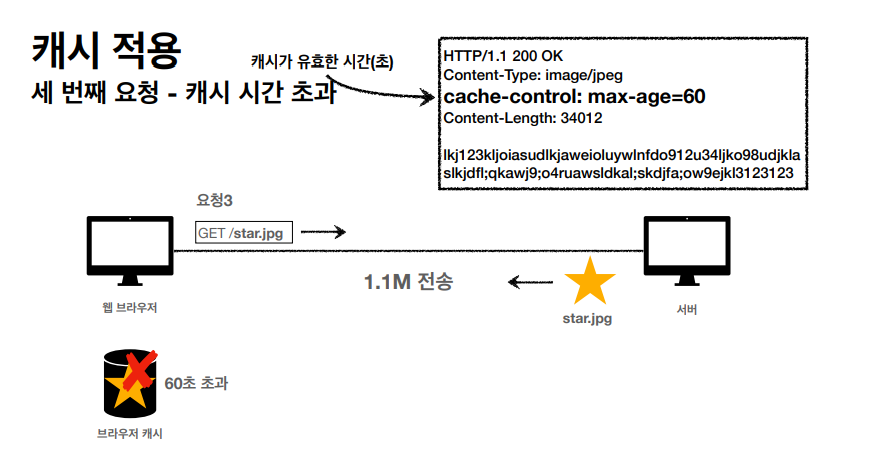
하지만 위처럼, 캐시의 생명 주기가 끝나고 다시 정보를 요청하게 된다면 서버는 다시 정보를 보내고 캐시에 저장하고 하는 과정을 반복하게 되어 시간이 초과 될때마다 계속해서 요청을 받을 것이다.

캐시 시간이 초과 될 경우 서버에서 기존 데이터를 변경 할수도 있고 아닐수도 있다, 그리고 이때 검증 헤더 라는 새로운 주제를 배우게됐다.
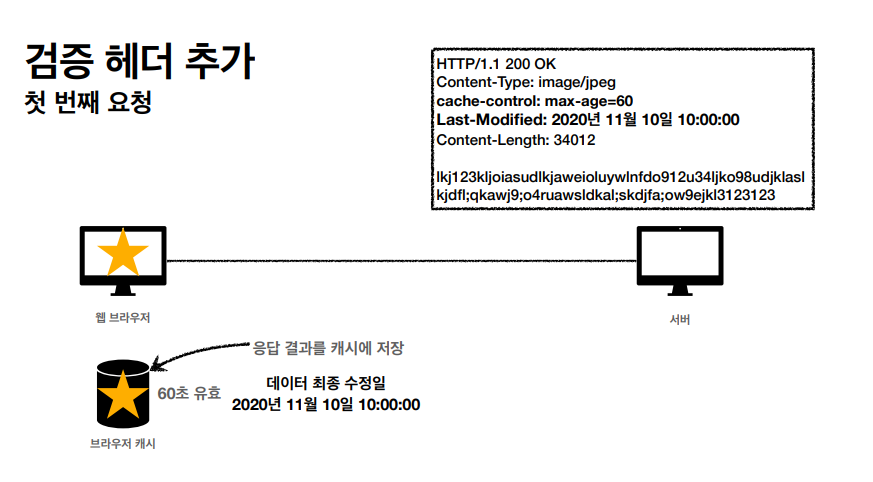
LAST MODIFIED 라는 검증 헤더를 추가 시켰고
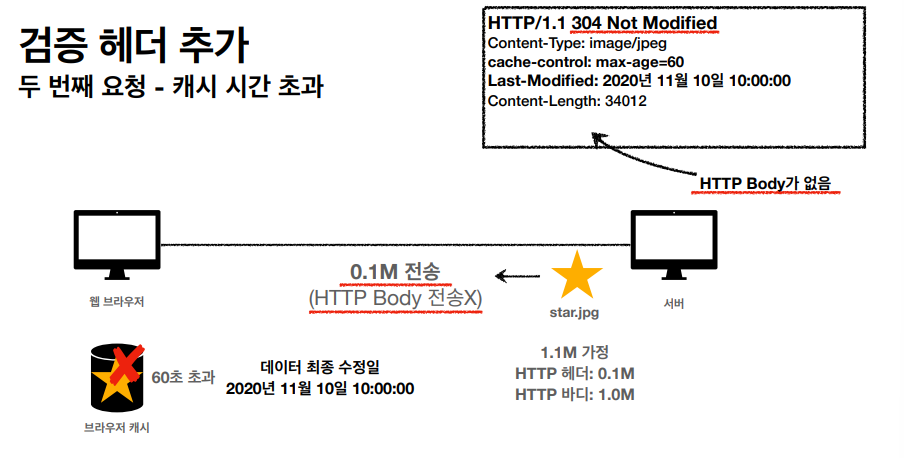
캐시의 생명주기가 끝난 후에 브라우저가 정보를 요청했을때 이 헤더를 매칭 시키고, 기존 정보가 수정이 된게 아니라면 HTTP BODY 를 전송시키지 않고, 응답 결과를 재사용해서 캐시를 살린다.
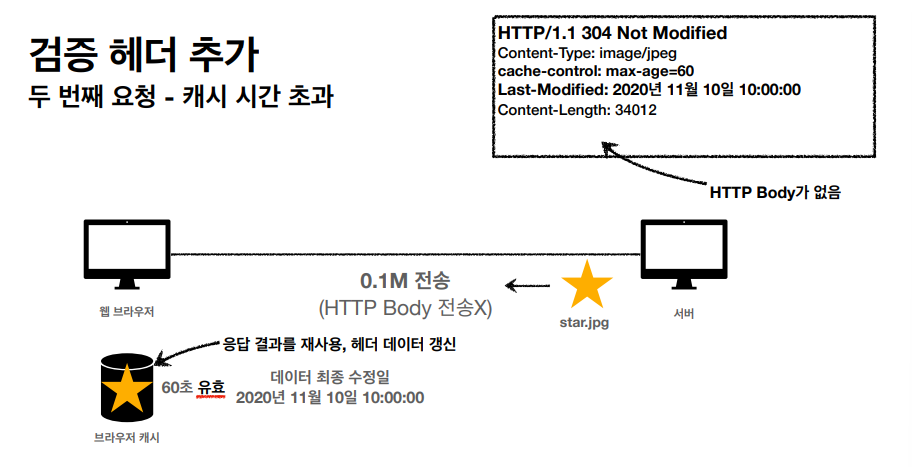
이런식으로 캐시를 재사용 가능하게 만든다. 304 NOT MODIFED는 정보가 달라진게 없다를 알리는 응답 메세지라고 생각하면은 편할거 같다.



부가적인 설명들이다. LAST-MODIFIED 와 IF-MODIFIED 는 유용하지만 특정 조건에 따라서 다른 방법을 사용하고 싶을거고 ETag 라는 검증 헤더또한 써볼 수 있다.

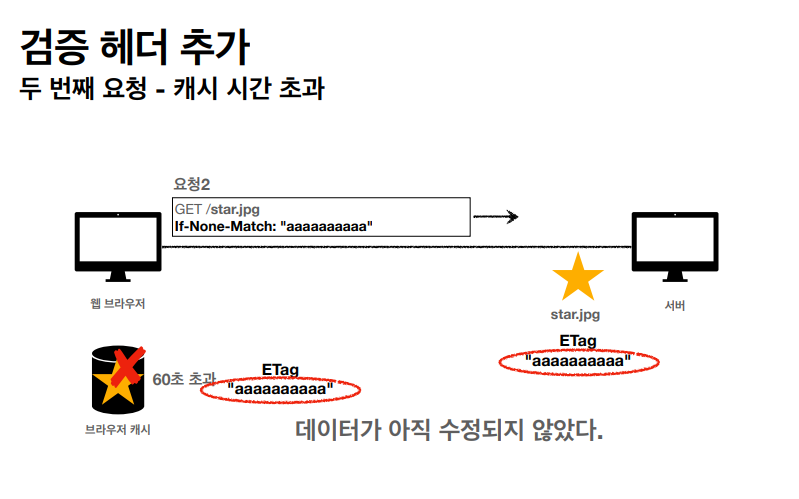
캐시 시간이 초과되고 재요청을 보낼때 이렇게 ETag 를 확인한다

캐시 제어 헤더 또한 존재하는데,

이정도만 외워두면 좋을거같다.
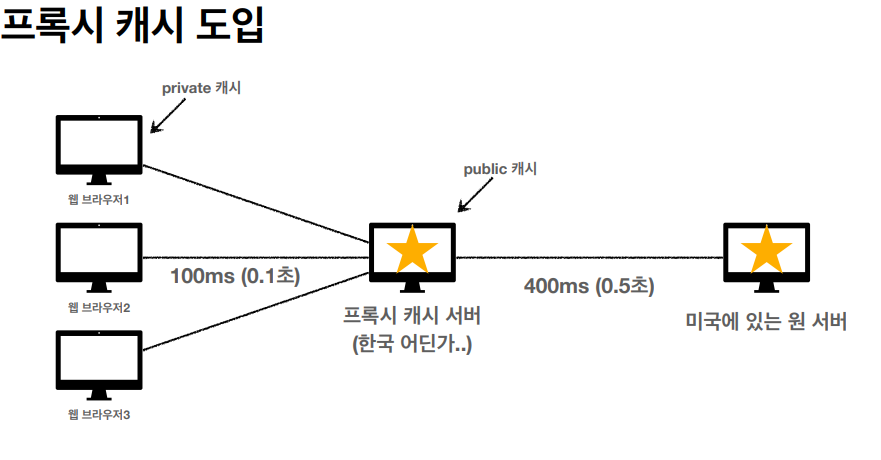
프록시 캐시
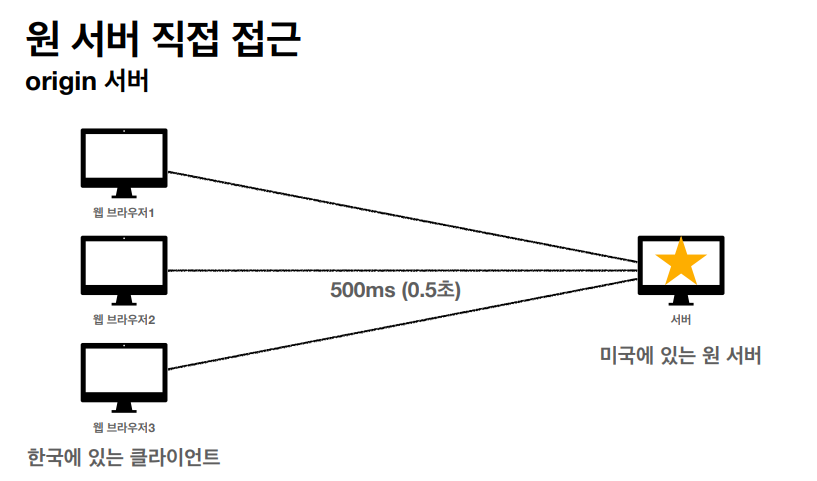
클라이언트가 직접적으로 원서버에 접근하는거는 굉장히 오랜 시간이 필요하지만 현재 우리는 AWS의 클라우드 프론트 같은 프록시 서버를 이용해서 외국 서버에 접근하는 속도를 굉장히 빠르게 유지하고 있다.
배운점
강의를 끝내고..
생각보다 많이 배웠던거 같다. 지금까지 들었던 강의에 비해서 실제로 굉장히 짧았고 HTTP 메서드에서 사용되는 대표적인 GET, POST 그리고 네트워크에 대한 기본적인 지식을 잘 배운기분이다. 물론 정리를 하나부터 열가지 다 하다보니 또 긴 포스팅이 나왔고 조금 어지러운것도 있지만 그래도 서버에 대한것을 더 배운거같아서 기분이 좋다. 이 다음부터는 JPA를 활용한 실전 수업에 들어갈건데, 강의 내용도 잘 정리하고 실제로 인텔리제이를 사용해서 따라해봐야겠다.
기존에 적었던 스프링 기본강의에서 사용하던 @GetMapping, PostMapping 등등 이 강의를 보고 다시 보니깐 HTML 에서 Form 을 제출하던 방식도 그렇고 좀 더 입체적으로 배웠던거같다. 앞으로 실전 위주의 강의를 더 들으면서 배운것을 직접 활용해보고싶다. 예상 강의 끝내는 시간을 3일 정도로 잡았는데 6일만에 끝낸거면 그래도 좋은 페이스 같다.
