1. 3주차 전체 내용, 기본 프로그램 설치 & 2주차 내용 복습 (나홀로 메모장에 openAPI 덧붙이기)
강사님이 3주차에서는 드디어 코딩 언어들 중 대표 언어인 파이썬쪽을 공부한다고 하셨다. 정확히는 파이썬을 이용해 웹 데이터를 긁어오는 크롤링에 대해서 배운다고 하셨다. 그외 mongoDB라는 프로그램을 이용해 그 데이터를 저장하고 이후 인생 첫 데이터베이스를 만들어본다고 하시면서 실습에서는 파이썬을 기반으로 영화목록들을 불러와 웹페이지에 적용하는 방법을 배운다고 하셨다. 그래서 이번주 수업을 위해 설치해야할 프로그램들이 있었다.파이썬,mongoDB,robo3T,Git Bash 윈도우만!이 바로 그것이다. 미리 올려두신 강의자료와 영상에 따라 설치를 하니 간단했다.
그 후 2주차 나홀로메모장에 openAPI 내용을 붙이는 실습으로 ajax 부분을 다시 복습했다.
그래서 만든 코드문(script 태그만 발췌)은 다음과 같다.
<script>
$(document).ready(function () {
$('#cards-box').empty('');
listing();
});
function listing() {
$.ajax({
type: "GET",
url: "http://spartacodingclub.shop/post",
data: {},
success: function (response) {
let articles = response['articles']
for (let i = 0; i < articles.length; i++) {
let article = articles[i]
let comment = articles[i]["comment"]
let desc = articles[i]["desc"]
let image = articles[i]["image"]
let title = articles[i]["title"]
let url = articles[i]["url"]
let temp_html = `<div class="card">
<img class="card-img-top"
src="${image}"
alt="Card image cap">
<div class="card-body">
<a href="${url}" target="_blank" class="card-title">${title}</a>
<p class="card-text">${desc}</p>
<p class="card-text comment">${comment}</p>
</div>
</div>`
$('#cards-box').append(temp_html)
}
}
})
}
/<script>$(document).ready(fucntion) 기능을 통해 페이지가 로딩되면 자동적으로 함수가 발동하도록 한 뒤 listing 함수에 $.ajax get 요청 코드문을 작성, 넣을 데이터가 있는 url로 수정하고 reponse의 변수값을 articles로 선언한 뒤 for 반복문을 돌려 articles 안에 웹페이지에 붙여넣을 데이터들만 또 변수 선언한 뒤(comment,desc,image,title,url) temp_html에 백틱을 이용해 앞서 뽑았던 데이터들을 넣은 html 코드문을 작성후 append 기능을 이용해 붙여넣기까지 완성하면 된다. 추가로 전에 넣었던 html 내용을 지우기 위해 함수 상단 혹은 $(document).ready 기능 상단에 empty기능까지 입력해주면 완벽해진다.
2. 파이썬 시작하기 & 기초 문법
파이썬(Python)은 요즘까지도 많이 쓰이는 코딩 어셈블리 언어들 중 하나로 기계어(0과1로 이루어진 2진수, 컴퓨터가 이해하는 언어)와 사람들이 이해하고 쓸수 있는 언어인 어셈블리어 사이에서 컴퓨터와 사람이 서로 데이터를 주고 받을수 있게 번역해주는 언어라고 보면 된다고 강사님이 말씀하셨다. 그러면서 우리가 줄곧 써왔던 파이참에서 파이썬을 만들고 실행하는 법을 알려주셨다. (File-New Project-Pure Python-프로젝트 저장할 폴더 지정 (꼭 경로 마지막에 "venv"가 있어야 함! 또한 만들어진 프로젝트에서 venv 폴더는 절대 건들지 말것!)-Base Interpreter는 python 3.8-create a main.py welcome script 체크 해제)
이렇게 하면 프로젝트 화면이 뜨는데 코드 치는 본문에다가 "print ('hello sparta')"를 치고 본문 화면 빈공간에 오른쪽 클릭-run 'hello'를 누르면 쳐둔 코드문이 실행되면서 아래 콘솔창에 입력했단 hello sparta가 출력된다. 이렇게 첫 파이썬 프로젝트를 만들어보았고 다음은 파이썬 기초 문법을 배웠다.(앞서 배웠던 자바스크립트 기초 문법과 유사하다.)
1) 변수
a = 3 # 3을 a에 넣는다
b = a # a를 b에 넣는다
a = a + 1 # a+1을 다시 a에 넣는다
num1 = a*b # a*b의 값을 num1이라는 변수에 넣는다
num2 = 99 # 99의 값을 num2이라는 변수에 넣는다
# 변수의 이름은 마음대로 지을 수 있음!
# 진짜 "마음대로" 짓는 게 좋을까? var1, var2 이렇게?2) 자료형
- 숫자, 문자형
name = 'bob' # 변수에는 문자열이 들어갈 수도 있고,
num = 12 # 숫자가 들어갈 수도 있고,
is_number = True # True 또는 False -> "Boolean"형이 들어갈 수도 있습니다.
#########
# 그리고 List, Dictionary 도 들어갈 수도 있죠. 그게 뭔지는 아래에서!- 리스트 형 (Javascript의 배열형과 동일)
a_list = []
a_list.append(1) # 리스트에 값을 넣는다
a_list.append([2,3]) # 리스트에 [2,3]이라는 리스트를 다시 넣는다
# a_list의 값은? [1,[2,3]]
# a_list[0]의 값은? 1
# a_list[1]의 값은? [2,3]
# a_list[1][0]의 값은? 2- Dictionary 형 (Javascript의 dictionary형과 동일)
a_dict = {}
a_dict = {'name':'bob','age':21}
a_dict['height'] = 178
# a_dict의 값은? {'name':'bob','age':21, 'height':178}
# a_dict['name']의 값은? 'bob'
# a_dict['age']의 값은? 21
# a_dict['height']의 값은? 178- Dictionary 형과 List형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}]
# people[0]['name']의 값은? 'bob'
# people[1]['name']의 값은? 'carry'
person = {'name':'john','age':7}
people.append(person)
# people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}]
# people[2]['name']의 값은? 'john'3) 함수
- 함수의 정의 - 이름은 마음대로 정할 수 있음!
# 수학문제에서
f(x) = 2*x+3
y = f(2)
y의 값은? 7
# 참고: 자바스크립트에서는
function f(x) {
return 2*x+3
}
# 파이썬에서
def f(x):
return 2*x+3
y = f(2)
y의 값은? 7- 함수의 응용
def sum_all(a,b,c):
return a+b+c
def mul(a,b):
return a*b
result = sum_all(1,2,3) + mul(10,10)
# result라는 변수의 값은? 1064) 조건문
- if / else 로 구성!
def oddeven(num): # oddeven이라는 이름의 함수를 정의한다. num을 변수로 받는다.
if num % 2 == 0: # num을 2로 나눈 나머지가 0이면
return True # True (참)을 반환한다.
else: # 아니면,
return False # False (거짓)을 반환한다.
result = oddeven(20)
# result의 값은 무엇일까요? truedef is_adult(age):
if age > 20:
print('성인입니다') # 조건이 참이면 성인입니다를 출력
else:
print('청소년이에요') # 조건이 거짓이면 청소년이에요를 출력
is_adult(30)
# 무엇이 출력될까요? 성인입니다5) 반복문 (length 사용 x)
- 항상 리스트와 함께 쓰임!
fruits = ['사과','배','감','귤']
for fruit in fruits:
print(fruit)
# 사과, 배, 감, 귤 하나씩 꺼내어 찍힙니다.- 과일 리스트 응용해보기
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1 // <- count = count +1과 동일한 의미
print(count)
# 사과의 개수를 세어 보여줍니다. 2def count_fruits(target):
count = 0
for fruit in fruits:
if fruit == target:
count += 1
return count
subak_count = count_fruits('수박')
print(subak_count) #수박의 개수 2
gam_count = count_fruits('감')
print(gam_count) #감의 개수 1- 리스트+딕셔너리에 적용하면 어떻게 나올까?
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
# 모든 사람의 이름과 나이를 출력해봅시다.
for person in people:
print(person['name'], person['age'])
# 이번엔, 반복문과 조건문을 응용한 함수를 만들어봅시다.
# 이름을 받으면, age를 리턴해주는 함수
def get_age(myname):
for person in people:
if person['name'] == myname:
return person['age']
return '해당하는 이름이 없습니다'
// <- else에 해당할시 나오는 return값 (return 값이 길지 않으면 else 표시 x)
print(get_age('bob')) 20
print(get_age('kay')) 해당하는 이름이 없습니다여기까지 봤을때 개인적으로는 특이한게 앞서 배웠던 자바스크립트나 내가 독학했던 자바와 달리 함수나 조건문, 반복문을 선언할때 안의 내용물을 중괄호{}를 이용하는게 아니라 콜론:을 이용한다는게 특이했다. 강사님이 말하시길, 파이썬은 직관적인 언어라 콜론: 이후 탭을 이용한 줄바꿈을 인식하여 안의 내용물의 시작과 끝을 구분한다고 하셨다. 확실히 중괄호를 썼던 코드보다는 보기에 간편함을 느꼈다.
3. 파이썬 패키지 설치하기 & 사용해보기
파이썬도 여타 다른 프로그램과 동일하게 라이브러리가 있는데 파이썬에서는 이걸 패키지라고 한다.(묘듈, 일종의 기능들 묶음) 또한, 종종 호환성 문제로 프로젝트별로 패키지를 다르게 가져갈수도 있는데 이때 서로 다른 프로젝트들 파일들에 영향을 주지 않기 위해 격리된 실행 환경, 즉 가상 환경(Virtual Environment)를 가지는데 이는 앞서 우리가 봤던 "venv"폴더와 같다. 일단 그렇게 해서 강사님이 파이썬 패키지에 대해 개념부터 알려주셨고 그 다음 pip(python install package) 사용해 앞으로 쓸 requests 패키지를 설치하는 법을 알려주셨다.
먼저, 윈도우 기준 File-Settings-Project: 해당 프로젝트 이름-Project Interpreter에서 +버튼 누르고,
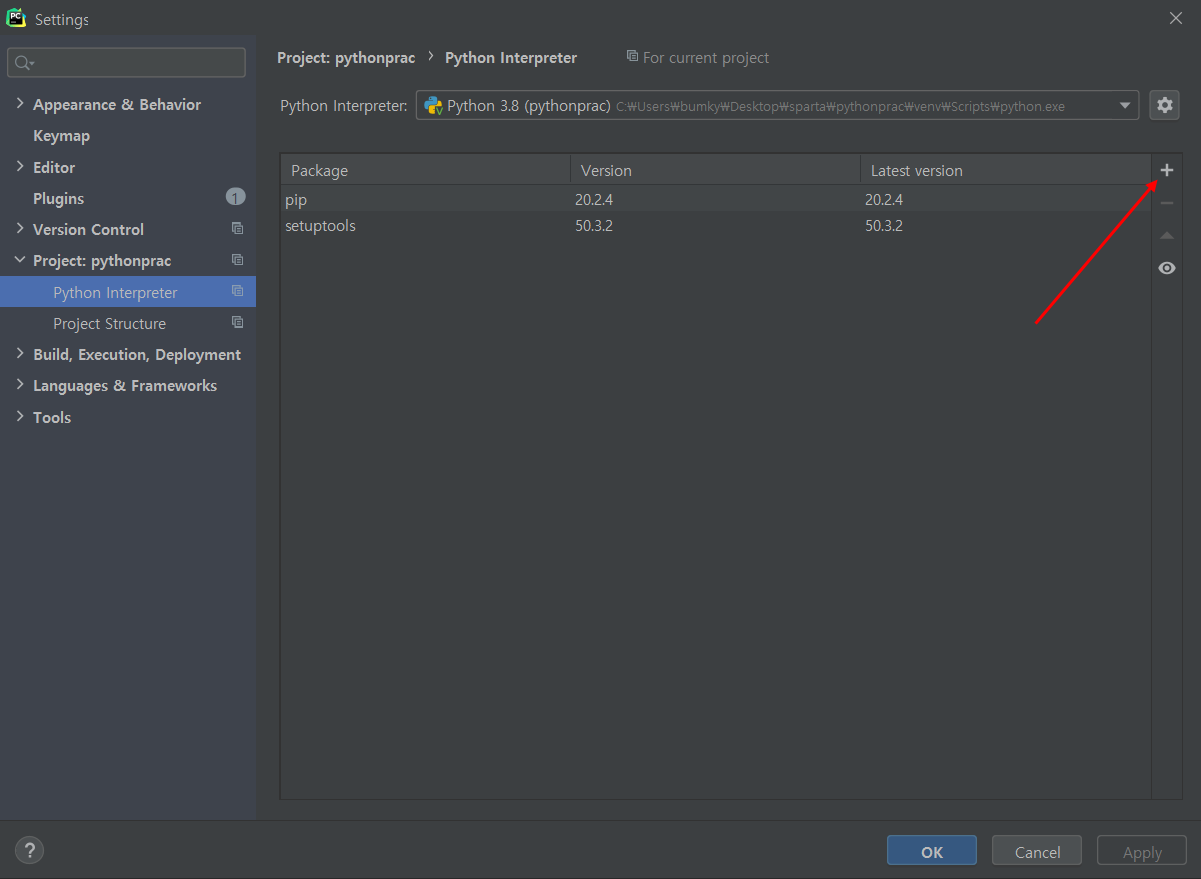
검색창에 requests 입력-나오는 패키지를 확인후 왼쪽 하단 install Package 클릭하면 패키지 설치가 완료된다.
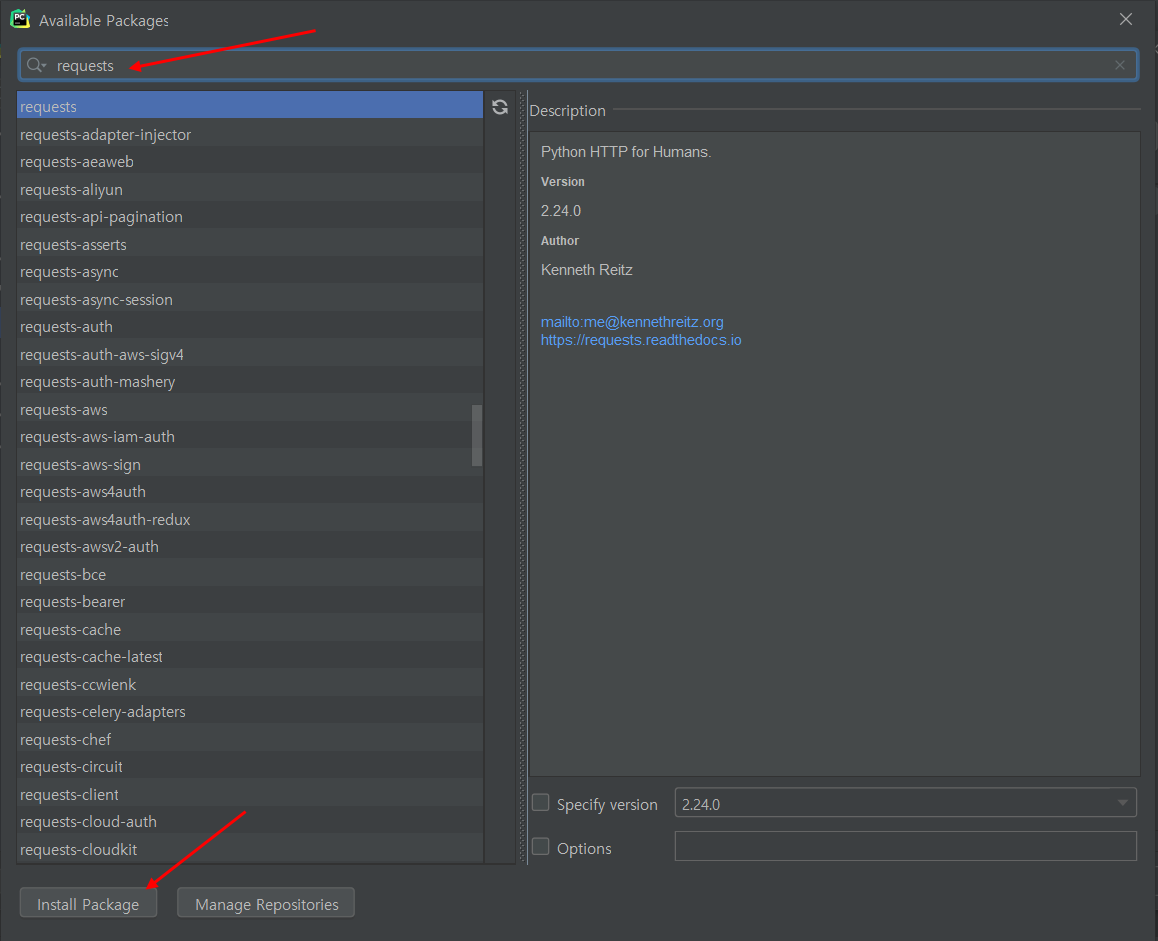
그렇게 해서 다음은 실제로 패키지를 사용해보는 연습을 해보았다. (서울시 미세먼지 openAPI 이용)
일단 다음 코드문으로 모든 구의 이름과 각 구의 미세먼지 수치를 출력했다.
import requests # requests 라이브러리 설치 필요
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
gus = rjson['RealtimeCityAir']['row']
for gu in gus:
print(gu['MSRSTE_NM'], gu['IDEX_MVL'])request 패키지를 사용해 우리가 ajax때 했었던 서울시 미세먼지 openAPI에 get 요청을 하고 그걸 json 형태로 받아 또다시 r에서 gus 변수 형태로 전달, 마지막에 for 반복문으로 gu 변수에 넣고 print 기능으로 출력하면 된다.
강사님 영상에는 if문을 추가해 미세먼지가 100 이상인 구를 표시하라고 했지만 현재 그런 구가 없어서 조금 비틀어 미세먼지 수치 90 미만 구들만 출력한다고 했을때 다음 코드문과 같이 더 작성할수 있었다.
import requests # requests 라이브러리 설치 필요
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
gus = rjson['RealtimeCityAir']['row']
for gu in gus:
gu_name = gu['MSRSTE_NM']
gu_mise = gu['IDEX_MVL']
if gu_mise<90:
print(gu_name, gu_mise)4. 웹 스크래핑(크롤링) 기초 & Quiz_웹 스크래핑(크롤링) 연습
이제 패키지도 다루는 법도 배웠으니 이 패키지를 이용해 데이터를 긁어오는 웹 스크래핑(크롤링)을 해볼 차례였다. 웹 스크래핑이 될 대상은 네이버영화 페이지였다. 여기서 순위, 영화이름, 평점 등을 긁어와서 데이터로 쓰게 될것이다. 그러기 위해선 패키지가 또 필요하여 이전처럼 File-Settings-Project: 해당 프로젝트 이름-Project Interpreter에서 +버튼 누르고 "bs4"를 검색해 beautifulsoup4 패키지를 설치해야했다.
설치를 완료한 뒤, 아래와 같은 코드문을 파이썬 프로젝트 파일에 넣으면 기본 준비는 끝난다.
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################구조를 보면 전에 설치한 request 패키지와 합쳐서 네이버 영화 페이지에서 데이터를 일단 get 요청해서 가지고 오고 BeautifulSoup 패키지를 이용해 soup라는 변수에 해당 데이터를 검색이 용이하게 대입하는 구조라고 강사님이 설명하셨다.
이제 soup에 대입한 전체 데이터(html 형태)에서 원하는 데이터만 우리가 뽑아내기 위해 강사님은 select_one과 select 기능을 소개해주셨다.
select_one은 소괄호안에 찾으려는 데이터가 어디있는지 알려주는 선택자(검사-해당 데이터 복사-selector 복사)를 이용해서 데이터를 찾는 기능이다.단, 하나의 데이터만 가능하다.
(또한, 태그.text = 태그 안 텍스트 반환/ 태그['속성'] = 태그 속성 반환)
하지만 이번에는 하나의 영화가 아니라 다수의 영화 목록을 가져와야하기 때문에 select를 써야 한다.
select는 아까 봤던 select_one 기능으로 뽑아왔던 데이터가 전체 html 데이터 soup 중 html 코드만 비슷하다면 리스트 형태로 무조건 데이터 목록으로 만들어주는 기능으로
일단 기준이 되는 코드를 뽑아내야하는데 네이버 영화 패키지 웹사이트에서 보면 웹사이트 안에 수많은 데이터들 중 영화 목록 데이터에 해당하는 데이터들이 다 아래와 같은 코드를 동일하게 가진다.
#old_content > table > tbody > tr그래서 이걸 선택자로서 select 기능에 기준값으로 넣고 돌린 다음 for 반복문과 아까 배웠던 select_one 기능 그리고 태그.text 기능을 이용해 영화의 제목 등 원하는 데이터 값만 뽑을수 있다.(영화 제목에 해당하는 데이터의 선택자 값은 #old_content > table > tbody > tr 의 뒷부분, td.title > div > a 태그이다.)
+) 해보면 실제로 줄바꿈때문에 None 값이 나오는 경우가 있으므로 None.text 값은 오류가 뜨니 if문을 추가로 달아서 not None임을 조건으로 달아 그 경우엔 태그.text로 print 출력하게끔 하면 완성된다.
이런 내용들을 모두 정리해 코드로 요약하자면 아래 코드문과 같다.
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text)이러면 아래 그림처럼 콘솔창에 영화 제목만 데이터로 뜨게 된다.
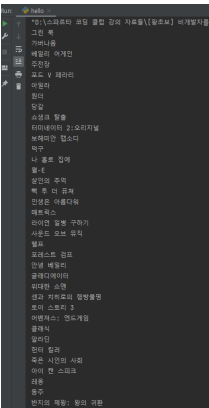
- select 사용법
선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
- 선택자 뽑아내는 방법 (크롬 개발자 도구 이용, 항상 정확하지는 않음)
(1) 원하는 부분에서 마우스 오른쪽 클릭 → 검사
(2) 원하는 태그에서 마우스 오른쪽 클릭
(3) Copy → Copy selector로 선택자를 복사할 수 있음
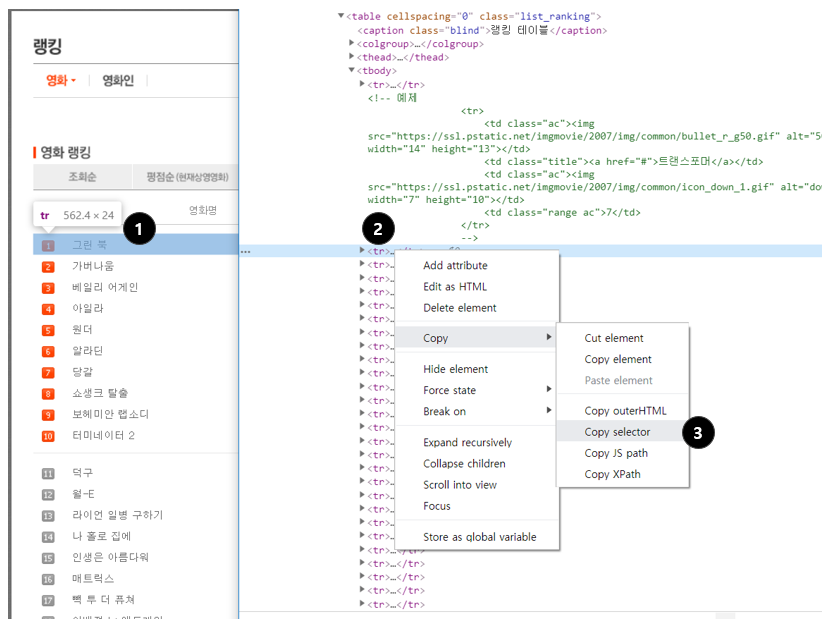
이렇게 해서 웹 스크래핑(크롤링)을 어떻게 하는지 알아보았고 마지막으로 복습 겸 강사님이 퀴즈를 주셨다. 이번에는 아까 했던 순위와 평점까지 해보라고 하셨다. (아래 그림 참고)
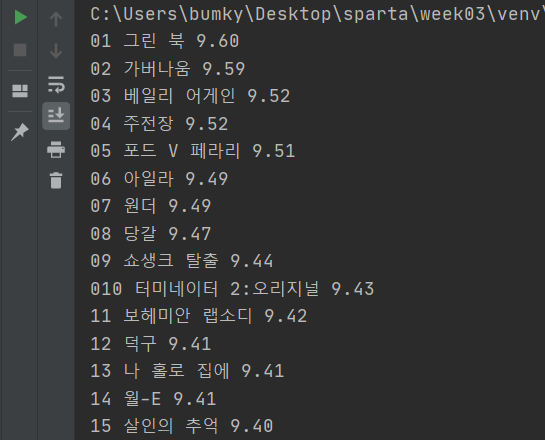
먼저 방식은 아까 배웠던것과 동일하지만 선택자를 각각 찾아야 하기에 크롬 개발자 기능으로 검색해보면 순위는 Image 태그로 되어있는데 보아하니 alt 속성에 맞춰서 하면 될거 같고,(정확히는 td:nth-child(1) > img 태그의 alt 속성값) 제목은 아까 했던것처럼 'td.title > div > a'가 선택자가 되고, 평점은 td.point 태그가 된다. 그리고 print할 결과값은 순위는 속성값, 제목과 평점은 텍스트값이 된다. 그래서 완성하자면 아래와 같은 코드문이 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
grade = movie.select_one('td.point').text
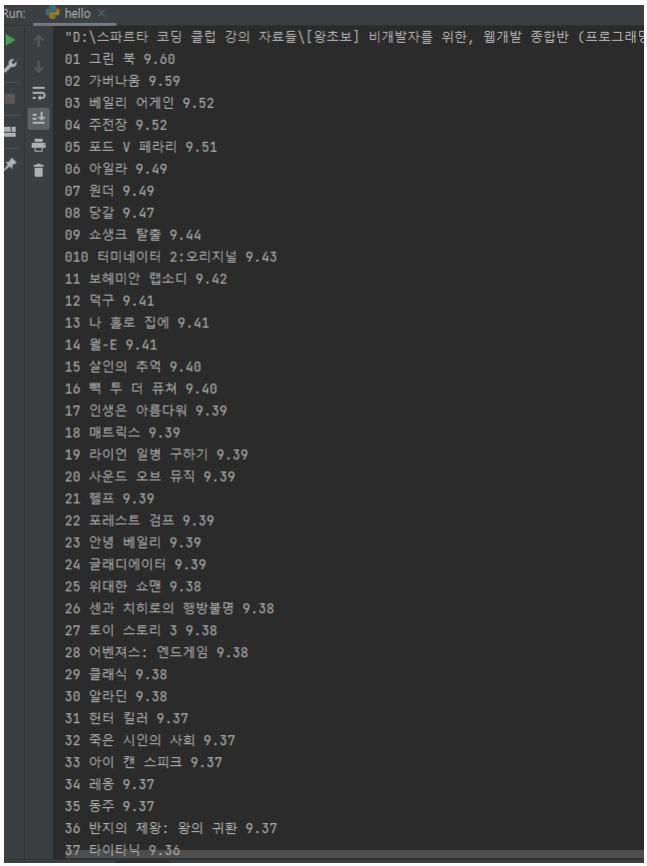
print (rank, title, grade)그러면 아래 사진과 같이 결과값이 나온다.
5. 데이터베이스 DB 개념 및 Pymongo로 DB 저장하는 법 배우기
이렇게 파이썬을 다루는 법부터 패키지, 웹 스크래핑(크롤링)까지 배웠으니 모든걸 하고 나온 데이터를 마지막에 저장하는 방법, 데이터베이스 다루는 법까지 배워야 이번 3주차는 완성이 된다고 할수 있을거 같다. 강사님이 말씀하시길 먼저 저번에 설치한 데이터베이스(MongoDB)가 잘 작동하는지 확인하기위해 크롬에서 새 탭을 열고 다음 문장을 입력하라고 하셨다.
http://localhost:(로컬 포트 숫자)/그러면 아래 사진과 같이 본문 내용에 뜨면은 DB 설치는 문제없이 돌아가고 있다고 하셨다.

그리고 데이터베이스인 MongoDB 프로그램은 따로 그래픽인터페이스(GUI, Graphic User Interface)가 없어서 데이터가 있어도 사용자가 직접 데이터를 볼 수 없기에 같이 설치했던 robo3t 프로그램을 이용해 데이터를 직접 볼 수 있다.
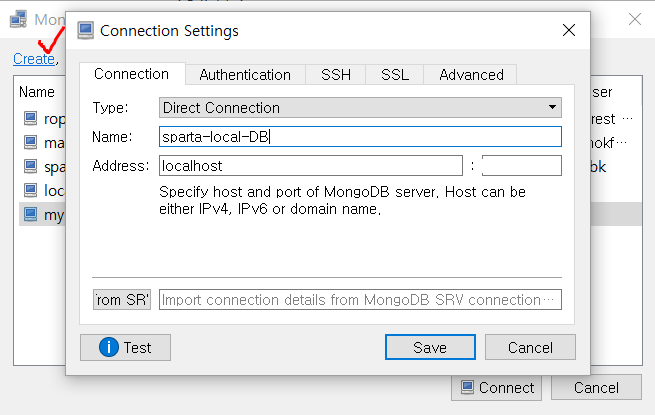
아래 사진과 같이 설정해주면 일단 데이터베이스 초기 접속은 일단 끝이 나는거 같다.
그런 뒤 강사님은 왜 데이터베이스를 해야하는지, 데이터베이스가 무엇인지 설명해주셨다.
데이터베이스는 우리가 나중에 쓰려고 물품들이나 책을 창고나 책장에 잘 정리해서 넣어놓듯이,
나중에 쓸 데이터들을 일단 지금은 정리해 후일에 꺼내어 쓸때 시간적으로나 비용적으로 더 효율적으로 이용하기위해 사용하는 의미라고 생각하면 될듯 하다.
그러면서 강사님은 일단 데이터베이스에는 두 가지 종류가 있다고 한다.
오직 SQL과 SQL 뿐만 아니라 여러가지 형태가 담긴 NoSQL(Not Only SQL).
SQL은 흔히 우리가 자주 접하는 엑셀 프로그램처럼 행과 열로 이뤄진 바탕에 데이터를 저장하기에
정형화,일관성이 있기에 분석이 매우 용이하다. 하지만, 구조 특성상 중도에 새로운 유형의 데이터 추가는 힘들다.
ex)MS-SQL, My-SQL
NoSQL은 딕셔너리 형태로 데이터들이 저장되면서 여러가지 형태의 데이터들이 저장될수 있다. 즉 모든 데이터가 동일한 값 유형을 가질 필요가 없어서 자유로운 형태의 데이터를 저장하는데는 좋지만, 분석이 힘들다.
ex)MongoDB
이렇게 데이터베이스에 대해 간략하게 알아보았다면 이제 직접 MongoDB를 이용해 데이터베이스를 다뤄볼 차례이다. 강사님과 했던 것은 그 중 PyMongo였는데 이것도 MongoDB의 라이브러리라고 한다.
(Pymongo 라이브러리 설치하는 방법은 패키지 설치와 동일하게 File-Settings-해당 프로젝트 파일 이름-Python interpreter-+클릭해 pymongo 검색후 설치)
아래는 Pymongo를 다루기 위한 기본 코드문이다.
from pymongo import MongoClient
client = MongoClient('localhost', 로컬포트숫자)
db = client.dbsparta
# 코딩 시작그 후 pymongo 라이브러리 안에 기능들을 간단히 배웠는데 크게 요약하면 다음 4가지로 나뉜다.
insert / find (list) / update / delete
아래는 강사님이 요약해주신 정리본이다. 강의가 끝난 뒤에도 꼼꼼히 보면서 복습했다.
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})이제 이 pymongo 사용법을 이용해서 아까 우리가 뽑았던 데이터 영화목록을 데이터베이스에 넣어줄 차례였다. 강사님 말씀대로 다음과 같은 코드문으로 데이터베이스에 영화목록을 넣었다.
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 로컬포트숫자)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
grade = movie.select_one('td.point').text
doc = {
'title':title,
'rank':rank,
'grade':grade
}
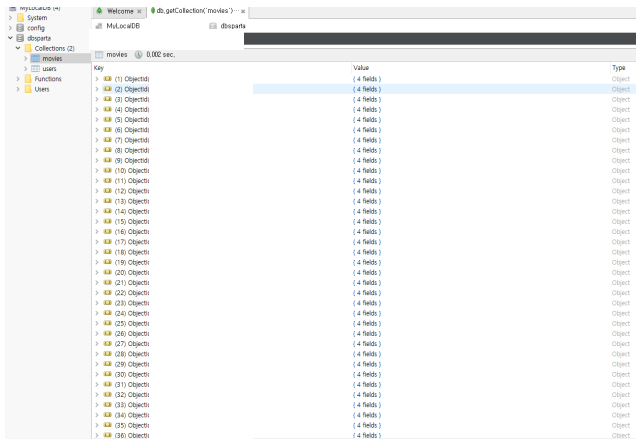
db.movies.insert_one(doc)doc 안에 title, rank, grade 키와 밸류값을 넣어 딕셔너리 객체로 만든 위 데이터가 들어갈 공간, 데이터 집합체(Collections)의 이름을 movies로 바꾼 뒤 insert_one 기능을 이용해 아까 뽑았던 영화목록을 데이터베이스에 넣었다. 그랬더니 아래 사진과 같이 robo 3t에 데이터베이스 목록에 떴다.
그렇게 숙제전 마지막으로 데이터베이스 다루는법까지 복습 겸 퀴즈를 진행했다.
퀴즈는 영화 '매트릭스'에 대해서 3가지 문제를 푸는 것이었는데 다음과 같았다.
(1) 영화 매트릭스의 평점 가져오기
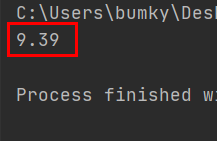
from pymongo import MongoClient
client = MongoClient('localhost', 로컬포트 숫자)
db = client.dbsparta
matrix = db.movies.find_one({'title' : '매트릭스'})
matrix_grade = matrix['grade']
print(matrix_grade)(2) 매트릭스와 같은 평점을 가진 영화들 가져오기

from pymongo import MongoClient
client = MongoClient('localhost', 로컬포트 숫자)
db = client.dbsparta
matrix = db.movies.find_one({'title' : '매트릭스'})
matrix_grade = matrix['grade']
movies = list(db.movies.find({'grade' : matrix_grade}))
for similar_grade_movies in movies:
print(similar_grade_movies['title'])(3) 매트릭스 평점을 0으로 만들기

db.movies.update_one({'title':'매트릭스'}, {'$set':{'grade':'0'}}) // <- 현재 데이터베이스안에 grade는 문자열로 등록되어있으므로 관리 편의상 0은 숫자지만 데이터 변경할때 문자열로 등록 ''6. 3주차 숙제
3주차 숙제는 지니뮤직 사이트에서 1위부터 50위까지의 곡들을 스크래이핑 해오는것이었다.(아래 사진 참고)
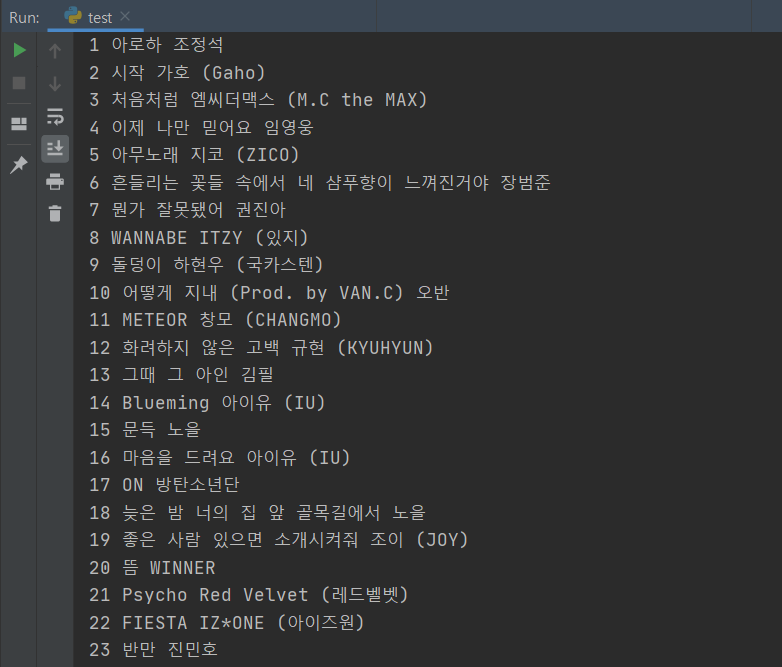
강사님은 덧붙여 순위와 곡 제목이 깔끔히 떨어져서 나오지 않을거니 파이썬 문자열 자르기, 파이썬 공백 제거 등을 검색해 파이썬 내장 함수 strip()을 이용하라고 힌트까지 주셨다.
완성 코드는 아래와 같이 직접 만들었다.
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 로컬포트숫자)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in songs:
title = song.select_one('td.info > a.title.ellipsis').text.strip()
rank = song.select_one('td.number').text[0:2].strip()
artist_name = song.select_one('td.info > a.artist.ellipsis').text
print(rank,title,artist_name)어찌저찌해서 선택자까지는 제대로 넣었지만, 강사님 말씀대로 공백이 너무 많아 잘 보이지 않았다. 그래서 크롬 개발자 도구를 통해 유심히 보니 rank부분은 1위부터 50위니까 딱 "두 칸"만
표시되도록 문자열을 바꿔야 했기에 파이썬 문자열 자르는 법을 참고해 text 속성값 뒤에 [0:2]를 추가했고, strip 함수는 파이썬 공백 제거 (replace, strip 2가지 방법 사용)링크를 참고했다. replace 함수도 있지만 코드가 길어지니까 strip 함수를 사용, 왼쪽과 오른쪽 둘 중 하나만 공백을 제거하거나(lstrip, rstrip) 아니면 양쪽 둘 다 제거하는 방법이 있는데 이번에는 rank, title 모두 다 양쪽에 공백이 있었으므로 둘 다 제거하는 strip 함수를 사용했다. artist_name은 공백이 없어서 그냥 text 속성값만 넣어도 문제가 없었다.
