[Recsys Paper Review] Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
Recsys 논문 정리
Abstract
- Top-N sequential recommendation
- 각 user를 과거에 interact한 item으로 모델링
- "가까운 미래"에 interact할 가능성이 높은 top-N item 예측
- interaction의 순서는 sequence의 최신 item이 다음 item에 더 큰 영향을 미치는 데 중요한 역할을 함을 의미한다.
-> 이러한 요구 사항을 해결하기 위해 Convolutional Sequence Embedding Recommendation Model (Caser) 논문 제안 - 논문의 아이디어
- 최근 item의 sequence를 시간 및 latent space의 이미지에 포함
- Convolutional filter 사용하여 local feature로서 sequential pattern 학습
-> seqeunce 데이터에 CNN을 활용한다고 보면 될듯
- 논문의 아이디어를 통해 general preference와 seqential pattern을 다룰 수 있는 network 구조 제공
CCS Concepts
Information systems - 검색 모델 및 ranking
Keywords
- 추천 시스템
- 시퀀스 데이터 예측
- CNN(Convolutional Neural Networks)
1. Introduction
- top-N 추천과 같은 대부분의 시스템은 item의 최신성을 고려하지 않고 user의 선호도에 따라 item을 추천
-> 이전에는 item의 sequence를 고려하지 않았던 것으로 추측
General Preferences
- user의 long term static behavior를 나타낸다.
ex) 어떤 user는 항상 Apple 제품을 삼성 제품보다 선호
Sequental patterns
- user의 short term dynamic behavior를 나타낸다.(General Preference와 반대)
- 가까운 시간 내의 item 간의 특정 관계로부터 나타난다.
-> user가 최근에 사용한 item이나 action에 더 많이 의존한다.
ex) 평소에 휴대폰 악세서리를 구매하지 않는 사람이 휴대폰을 구매 후 휴대폰 악세서리를 구매
-> General Preference만 고려하면 휴대폰 악세서리 추천 기회를 놓칠 수 있다.
1.1 Top-N Sequential Recommendation
user가 가까운 미래에 interact할 가능성이 있는 top N item을 추천
description
- user set 와 item set 가 있다고 가정
- 각 user 는 의 일부 item의 sequence 데이터 를 가지고 있음
- 의 index 는 sequence에서 action이 일어난 순서를 의미함
-> absolute timestamp(절대 시간)이 아님
Goal
모든 user의 sequence 가 주어졌을 때
general preference와 sequential pattern을 모두 고려하여
각 user에게 만족도(요구사항)를 최대화하는 item list 추천
vs Convential top-N recommendation
user behavior를 set이 아닌 sequence로 나타냄
1.2 Limitations of Previous Work
- 이전에는 top-N sequental recommendation을 위해 Markov chain based 모델을 활용
-> L개의 이전 action을 기반으로 추천 - Markov chain based 모델 종류
- first-order Markov chain
- Factorized personalized Markov chains(FPMC)
- Factorized Sequential Prediction with Item Similarity ModeLs(Fossil)
- Markov chain based 모델에는 다음과 같은 제한 사항 존재(Fig 1)
- Fail to model union-Level sequential patterns(Fig 1(a), 1(b))
- Fail to allow skip behaviors(Fig 1(c))
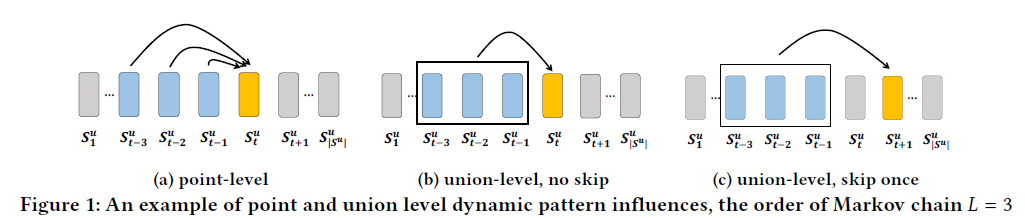
Fail to model union-Level sequential patterns
- Fig 1(a)에서 Markov chain은 previous action(blue)은 집합이 아닌 각각이 target action(yellow)에 영향을 미친다.
- Fig 1(a)의 point-level influence는
Fig 1(b)와 같은 union-level influence를 모델링하기에 적절하지 않다.
-> 이전 action이 target action에 공동으로 영향을 미친다.
union-level influence example
- 우유와 버터를 함께 구입하면 우유나 버터를 개별적으로 구매할 때에 비해 밀가루를 구입할 확률이 높아진다.
- RAM과 하드를 함께 구입하면 둘 중 하나만 구입할 때보다 운영체제를 구입할 확률이 높다.
Fail to allow skip behaviors
- 기존 모델은 Fig 1(c)와 같은 sequential pattern의 skip behavior를 고려하지 않음
-> 과거 behavior는 몇 단계를 건너뛰어도 여전히 강한 영향을 미칠 수 있음
skip behaviors example
- 관광객은 공항, 호텔, 레스토랑, 바, 관광지 순으로 체크인을 한다.
- 공항과 호텔 체크인은 관광지 체크인 바로 전에 이루어지지는 않지만 밀접한 관련이 있다.
- 오히려 레스토랑, 바 체크인은 관광지 체크인 직전에 이루어지지만 거의 영향을 미치지 않는다.
-> 이전 behavior가 그 전 behavior보다 영향력이 강하다는 보장이 없다.
Evidence
- union-level influence와 skip behavior의 효과를 나타내기 위해
MovieLens, Gowalla Data의 연관 규칙 활용 (Fig.2)
-> L=2, L=3 rule 개수를 통해 union-level influence가 적용되는 rule
skip once, twice rule 개수를 통해 skip behavior가 적용되는 rule이 많음을 보여 줌
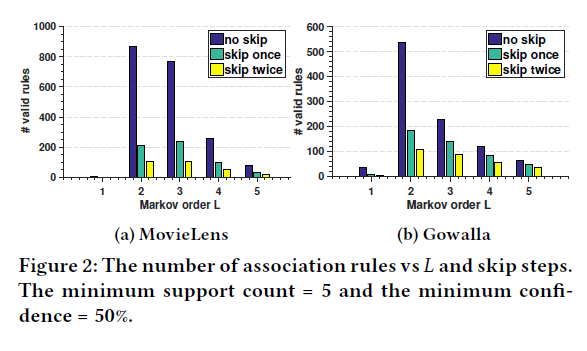
- support count : 특정 Item 집합을 포함하고 있는 Transaction(Record)의 수
- confidence : 사건 x가 일어났을 때 x 이후 y가 일어날 확률
1.3 Contributions
- 이전 연구들의 한계점을 해결하기 위해
top-N sequential 추천 solution으로
ConvolutionAl Sequence Embedding Recommendation Model(Caser) 제시
-> local feature(sequence) 처리를 위해 CNN의 convolution filter 활용
novelty
- 이전 L개의 item을 matrix E로 표현
- row를 통해 item 순서를 유지
- d는 latent dimension의 수
- Embedding matrix E를 latent space에 있는 L개 item의 이미지로 간주 가능
- 공통점
- 다양한 convolutional filter를 활용하여
local feature로서 sequential pattern 검색 가능
- 다양한 convolutional filter를 활용하여
- 차이점
- 기존 이미지와는 달리 입력으로 제공되지 않음(직접 만들어야 함)
- 모든 filter를 활용해서 동시에 학습되어야 함
- 공통점
distinct advantage
- horizontal, vertical convolution filter를 활용해서 point-level, union-level 그리고 skip behavior 등 sequence 패턴을 포착함
- user의 general preference와 sequential pattern을 모두 모델링함
- top-N sequential 추천 관련 이전 state-of-the-art 방법 능가
2. Further Related Work
논문 알고리즘(Caser)과 이전에 활용된 추천 알고리즘 비교
3. Proposed Methodology
Caser는 sequential feature 학습을 위한 CNN과
user specific feature를 학습하기 위한 LFM(Latent Factor Model)을 통합
Goal
- 관찰되지 않은 공간에서 user의 general preference와 sequential pattern을 union-level 및 point-level에서 capture
- skip behavior capture
Component(Fig 3)
- Embedding Look-up
- Convolutional Layers
- Fully-connected Layers
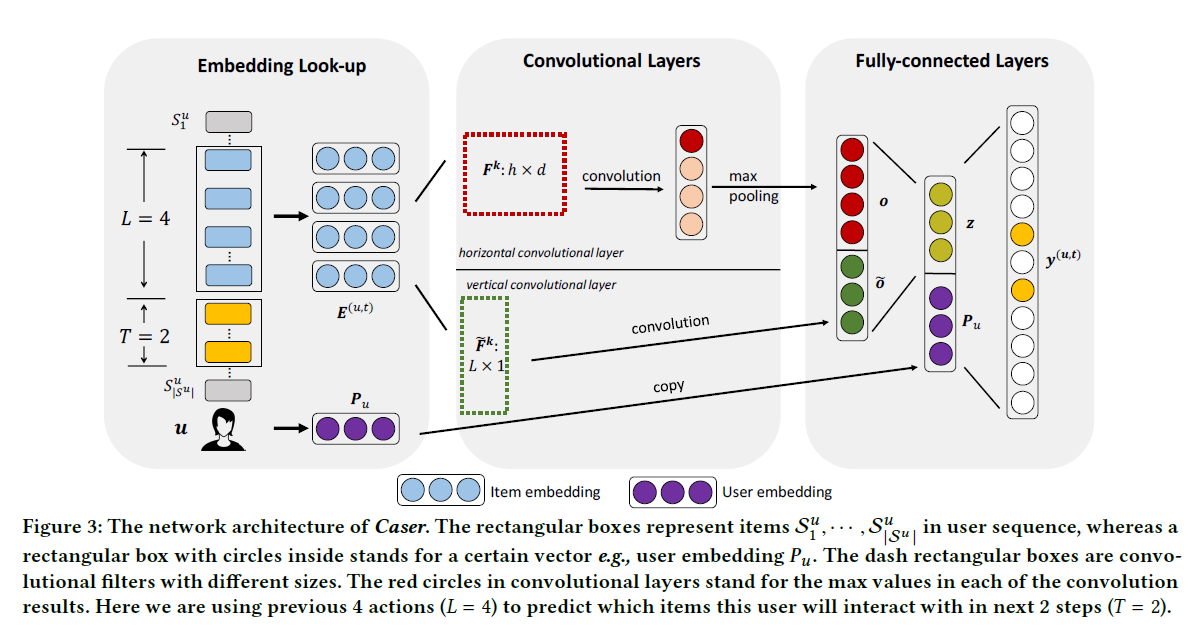
CNN Train
- 각 user u에 대해 user sequence 에서
연속적인 L item을 input으로, 다음 T item을 target으로 활용(Fig 3) - Sliding window 활용
- user sequence에서 L + T 크기만큼 sliding
- 각 window를 통해 u에 대한 training instance 생성
-> triplet(u, 이전 L item, 이후 T item)으로 표시
3.1 Embedding Look-up
- 이전 L item embedding을 neural network의 input값으로 활용
-> latent space에서 sequence feature를 캡처함 - item i embedding 는 latent factor와 비슷
-> d는 latent 차원 수 - Embedding Look-up을 통해 이전 L item embedding을 탐색하고 쌓아서
matrix를 생성 (식 2)- : user u
- : time step t
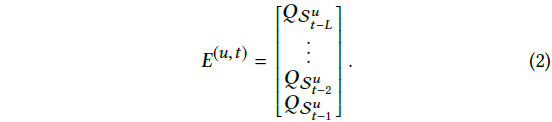
- item 이외에도 user u를 위한 embedding도 존재
-> latent space에서 user feature를 표현 - Fig 3 Embedding Look-up box에서
는 파란색 원, 는 보라색 원으로 표시
3.2 Convolutional Layers
- matrix E를 latent space에 있는 이전 L item의 이미지로 간주
- sequential pattern을 이미지의 local feature로 간주
-> convolutional filter를 활용해서 sequential pattern 검색 가능
Convolution Filter
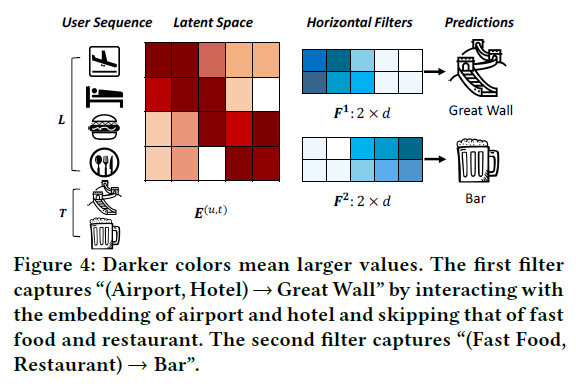
- Fig 4는 두 개의 union-level sequential pattern을 캡처하는
horizontal filter를 보여 준다.- filter는 matrix로 표현
-> Fig 4에서 h = 2, d는 전체 너비(dimension) - filter를 활용해 E 행의 sequential pattern 신호 포착
- filter는 matrix로 표현
- vertical filter는 matrix
-> matrix E의 column 탐색 - image recognition과 달리 image E는 주어지지 않는다.
- 모든 item i에 대한 임베딩 가 모든 filter와 동시에 학습되어야 하므로
Horizontal Convolutional Layer
Fig 3의 Second Component에서 확인 가능

- n개의 horizontal filter 를 가지고 있음
-> 는 filter의 height를 표현(row 개수) - filter 는 E의 모든 horizontal dimension과 interaction
-> item i의 범위 : - interaction의 결과는 다음과 같은 i번째 convolution 값으로 나타남(식 3)
- 기호는 내적을 나타냄
- 기호는 activation function을 나타냄
- 는 filter와 E의 행부터 행 sub-matrix의 내적
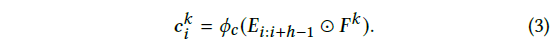
-
를 활용한 최종 convolution 결과(식 4)
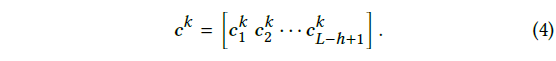
-
에 max pooling 적용
- 특정 filter에 대해 생성된 모든 값에서 최대값 추출
-> 최대값은 filter에서 추출한 가장 중요한 feature - layer의 n개의 filter에 대한 output (식 5)
- 특정 filter에 대해 생성된 모든 값에서 최대값 추출
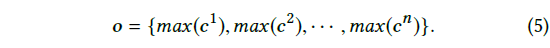
- 이러한 과정을 통해 horizontal filter는 multiple union size에서
union level pattern을 학습할 수 있다.
Vertical Convolutional Layer
Fig 3의 Second Component에서 확인 가능
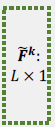
- 개의 size vertical filter 를 가지고 있음
- E의 column과 interact
-> d개의 convolution result 생성(식 6)
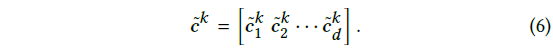
- convolution result는 E의 L rows와 vertical filter 의 weighted sum과 같음 (식 7)
- 은 E의 l번째 row
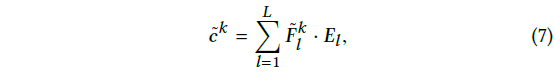
- vertical filter는 point-level sequential pattern 포착에 사용
-> 이전 L item의 latent 표현에 대한 weighted sum 계산을 통해 - 개의 vertical filter를 활용해서
모든 user에 대한 output 생성 (식 8)
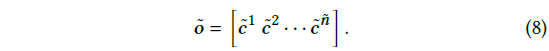
horizontal filter와 차이점
- vertical filter 크기는 로 고정
-> 한 번에 여러 개의 column과의 interaction은 의미가 없기 때문 - max pooling 연산을 적용할 필요가 없음
-> 모든 latent dimension에 대한 aggregation 유지를 위해서
3.3 Fully-connected Layers
- horizontal filter output과 vertical filter output을 concat하여
Fully-connected Layer에 입력
-> high-level의 추상적인 feature를 뽑아낼 수 있음(식 9)
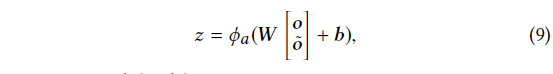
-
식 9 변수 설명
- W : weight matrix
- b : bias
- : activation function
- z : convolutional sequence embedding
-> 이전 L item의 sequential feature 인코딩
-
user의 general preference 포착을 위해 user embedding 와 concat
-> output layer로 보냄 (식 10)
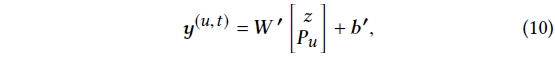
- 식 10 변수 설명
- 는 user u가 time t에서 item i와 interaction할 확률
- z는 short-term sequential pattern를 capture
- user embedding 는 user의 long-term general preference를 capture
를 last hidden layer에 넣는 이유
- 다른 model을 generalize 할 수 있음
- model parameter pretrain 가능
-> 다른 generalize된 model parameter를 활용
3.4 Network Training
- network를 train시키기 위해 output layer의 값 y를 확률로 변환(식 11)
-> sigmoid activation function 활용
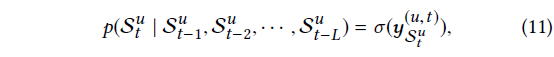
- dataset의 모든 sequence에 대한 likelihood(식 12)
-> 는 user u에 대한 prediction을 수행하려는 time step 모음
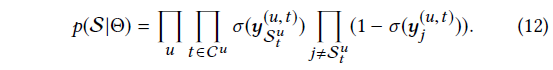
- skip behavior 캡처를 위해 next T target item 고려할 수 있음
- binary cross-entropy loss 활용(식 13)
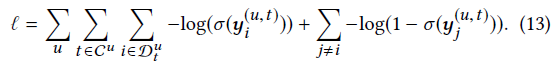
Settings
- Adam optimizer 활용
- batch size : 100
- l2 norm과 dropout(p=0.5) 사용 -> overfitting 방지
3.5 Recommendation
- time step t에 user u에게 item 추천
-> user embedding과 이전 L item embedding을 input으로 활용 - output layer y값이 가장 높은 N개의 item 추천
- Target item 개수 T는 하이퍼파라미터
3.6 Connection to Existing Models
Caser는 여러 이전 모델을 일반화한 것
-> MF, FPMC, Fossil 등 이전 모델과 같이 학습하도록 만들 수 있음
4.Experiments
Caser를 이전 sota 모델과 비교
4.1 Experimental Setup
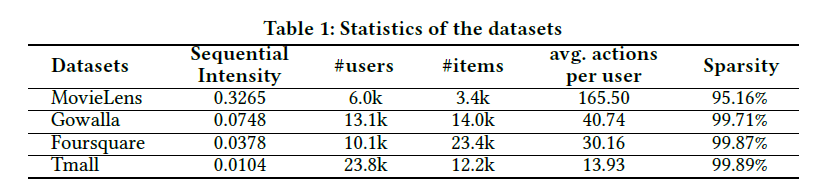
- dataset 통계치(Table 1)
- Sequential Intensity (SI) : 전체 rule / 전체 user
Evaluation Metric
Precision@N, Recall@N, Mean Average Precision(MAP) 등 사용
4.2 Performance Comparison
Caser와 이전 sota 모델 성능 비교
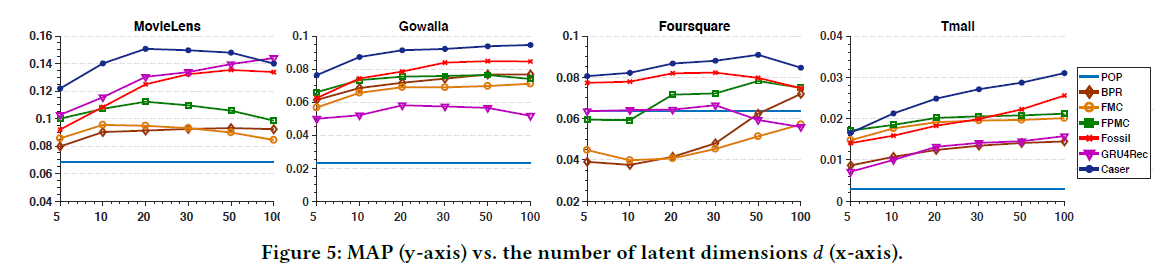
- latent dimension d를 변화시켰을 때 MAP 결과(Fig 5)
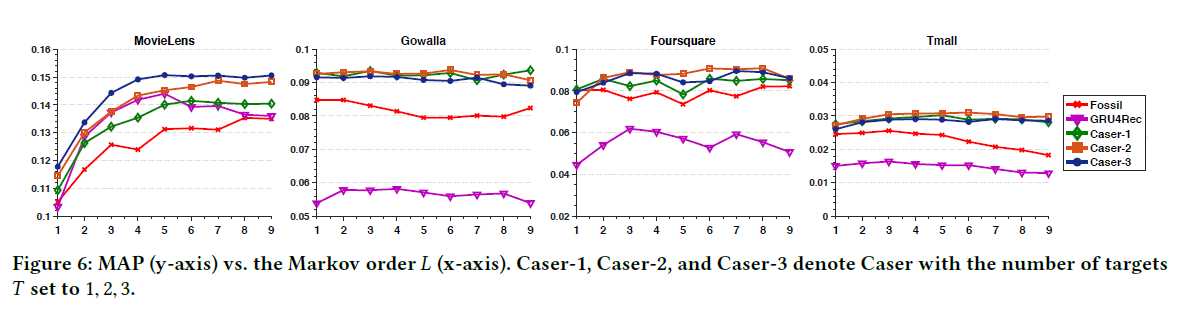
- target number T를 변화시켰을 때 MAP 결과(Fig 6)
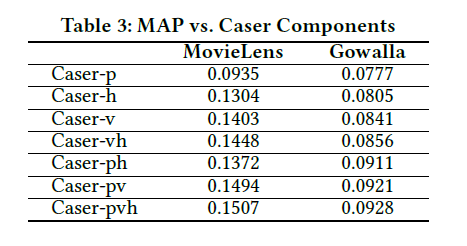
- 각 compontent 사용 여부에 따른 성능 결과(Table 3)
- p : personalization(user embedding 사용)
- h : horizontal convolutional layer
- v : vertical convolutional layer
-> 셋 다 썼을 때 성능이 가장 좋다.
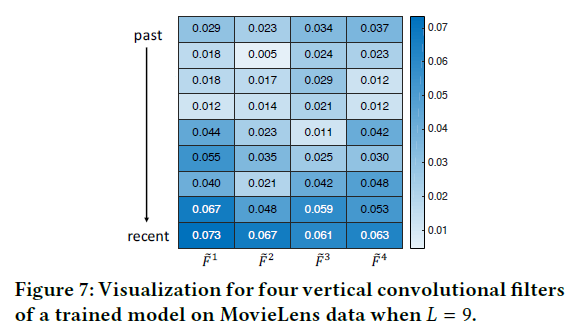
4.3 Network Visualization
- vertical convolutional filter 시각화(Fig 7)
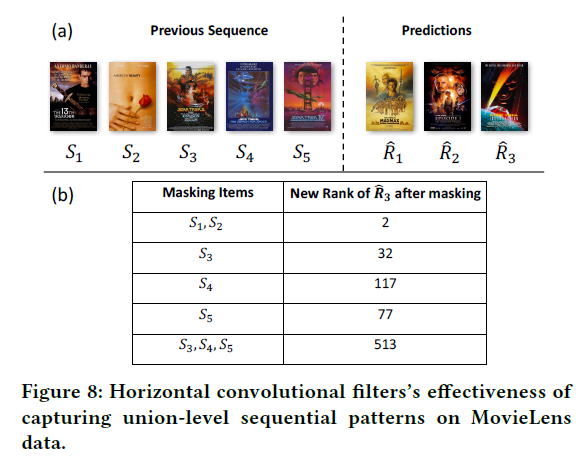
- horizontal filter에 의한 추천(Fig 8)
5. Conclusion
- Caser는 top-N sequential 추천에 대한 새로운 접근법
- 최근 action을 시간과 latent dimension의 이미지로 임베딩
-> convolution filter 활용 sequential pattern 학습 - sequential 추천을 위한 다양한 중요 feature를 capture 가능
- point-level sequential pattern
- union level sequential pattern
- skip behavior
- long term user preference
