Abstract
- 해당 연구는 추천 시스템, 협업 필터링, implicit feedback을 기반으로 함
- 논문 작성 이전까지는 협업필터링은 여전히 Matrix Factorization(행렬 분해)에 의존했음
-> user 및 item의 latent feature에 내적 적용 - NCF(Neural network-based Collaborative Filtering)는 latent feature 내적을 딥러닝으로 대체
-> 행렬 분해를 표현하고 일반화할 수 있음 - 비선형성으로 NCF 모델링을 강화하기 위해 다층 퍼셉트론을 활용
-> user-item interaction을 학습
Keywords
- 협업 필터링
- Neural Networks
- Deep Learning
- Matrix Factorization(행렬 분해)
- Implicit Feedback(암시적 피드백)
1. Introduction
개인화된 추천 시스템의 핵심은 협업 필터링으로 알려진 과거 상호 작용(예: 평가 및 클릭)을 기반으로 항목에 대한 사용자의 선호도를 모델링 하는 것임
Matrix Factorization
- Matrix Factorization(MF)는 협업 필터링 기술 중에 가장 인기 있는 방법
- user, item latent feature를 활용하여 user와 item을 공유된 latent space로 투영시킴
- item에 대한 user의 상호작용은 latent vector 내적으로 모델링됨
- MF를 향상시키기 위해 진행된 방법
- neighbor-based model과 결합
- item content topic model과 결합
- factorization machine으로 확장
Deep Neural Network
- 논문에서는 data의 interaction function을 학습하기 위해 Deep Neural Network 활용
- 컴퓨터 비전, 음성 인식, 텍스트 처리 등 여러 영역에서 효과적
-> 하지만 추천을 위해 DNN을 사용하는 연구는 상대적으로 적음 - 추천에 DNN을 적용하고 좋은 결과를 보여줌
- 하지만 보통 item의 텍스트 설명, 음악의 오디오 feature, 이미지의 시각적 content를 모델링하는 데 DNN을 사용
- 협업 필터링에는 여전히 user와 item latent feature를 내적하는 MF 활용
Implicit Feedback
- 논문은 user의 행동을 통해 선호도를 간접적으로 반영하는 Implicit Feedback 활용
- 논문에서는 noise가 있는 Implicit Feedback을 모델링 하기 위해 DNN 활용
vs Explicit Feedback
- 장점 : rating이나 review 같은 Explicit Feedback과 비교했을 때
Implicit Feedback은 자동으로 수집될 수 있음
-> 콘텐츠 제공자를 위해 수집하기가 훨씬 쉬움 - 단점 : user 만족도가 관찰되지 않고 부정적 feedback이 부족하기 때문에 활용하기 어려움
Main Contribution
- NCF는 user와 item의 잠재된 특징을 모델링하기 위한 신경망 기반의 협업 필터링 프레임워크
- 다층 퍼셉트론을 활용해서 NCF 모델링에 높은 수준의 비선형성을 부여할 수 있음
- 실험을 통해 NCF 접근 방식의 효율성과 협업 필터링에서 딥러닝의 가능성을 보여줌
2. Preliminaries
2.1 Learning From Implicit Data
- M과 N을 각각 user 수, item 수로 정의
User-item interaction matrix
- user의 implicit feedback으로부터 user-item interaction matrix Y 정의
- 식 1은 matrix Y에서 각 user,item의 interaction을 나타낸다.
- 값이 1이면 user u와 item i 사이에 상호 작용이 있음
-> user u가 실제로 item i를 좋아한다는 의미는 아님(선호도 반영 X) - 값이 0인 경우 user u가 item i를 비선호한다는 의미는 아님
-> user가 item을 인식하지 못하는 것일 수도 있음
- 값이 1이면 user u와 item i 사이에 상호 작용이 있음
사용자의 선호도나 부정적인 피드백이 부족할 수 있다는 문제 발생

식 1 : interaction between user u and item i
Recommendation Problem With Implicit Feedback
-
implicit feedback을 활용하는 추천 문제는 item의 ranking 추정에 사용되는 Y 내부의 관찰되지 않은 rating 점수를 추정하는 문제
-
Model-based approaches는 데이터가 기본 모델에 의해 생성 또는 설명될 수 있다고 가정
Negative Data Handling
Negative Data의 부재 처리 방법
-
관찰되지 않은 항목들을 negative feedback으로 처리
-
관찰되지 않은 항목들에서 negative instance 샘플링
Objective Functions
- Pointwise learning
- 예측값 와 target 사이의 square loss를 최소화
- Pairwise learning
- 관찰되는 항목이 관찰되지 않은 항목보다 rank가 높아야 함
- 관찰된 와 관찰되지 않은 사이의 margin 최대화
NCF는 Pointwise learning과 Pairwise learning을 모두 지원
2.2 Matrix Factorization
- 와 는 각각 user u와 item i에 대한 latent vector
- MF는 interaction 를 와 의 내적으로 추정 (식 2)
- K는 latent space의 차원
- MF는 latent space의 각 차원이 서로 독립적이고 동일한 가중치로 선형 결합한다고 가정
-> MF는 latent factor의 선형 모델로 간주될 수 있음
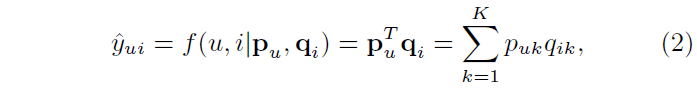
식 2 : MF에서 interaction 를 추정하는 식
MF's Limitation
Figure 1은 내적이 MF의 표현력을 어떻게 제한하는지 보여 줌
- user-item matrix
- u4는 u1, u3, u2 순으로 유사하다.
- user latent space
- p4가 p1과 가장 가깝도록 배치하면 p2가 p3보다 가까워짐
-> large ranking loss가 발생할 수 있음
- p4가 p1과 가장 가깝도록 배치하면 p2가 p3보다 가까워짐
Settings
- MF는 user와 item을 동일 latent space에 mapping하므로 내적 이외에도
두 user 간의 유사도를 잠재 벡터 사이의 각도 코사인으로도 측정할 수 있음 - Jaccard 계수를 MF가 복구해야 하는 두 사용자의 ground-truth 유사도로 사용
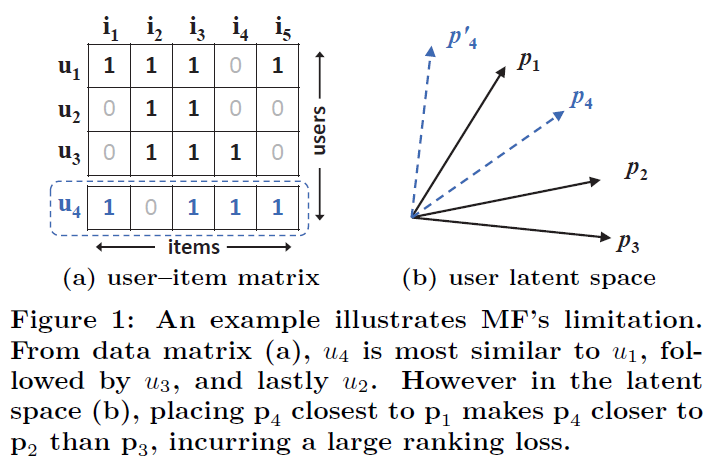
Fig 1 : matrix에서 유사해도 latent space에서 유사하지 않을 수 있다는 한계를 보여줌
해결 방법
- 많은 latent factors K를 사용하는 것
-> 하지만 sparse할 경우 데이터 과적합이 발생할 수 있음 - 논문에서는 DNN을 활용함으로서 한계 해결!!
3. Neural Collaborative Filtering(NCF)
3.1 General Framework
- user-item interaction 를 모델링하기 위해 multi-layer 표현 채택 (그림 2)
- 한 layer의 output은 다음 layer의 input으로 사용됨
- bottom input layer는 각각 user u와 item i를 설명하는 feature vector로 구성
- context aware, content-based, and neighbor-based와 같은 광범위한 user와 item 모델링을 지원하도록 사용자 정의 가능
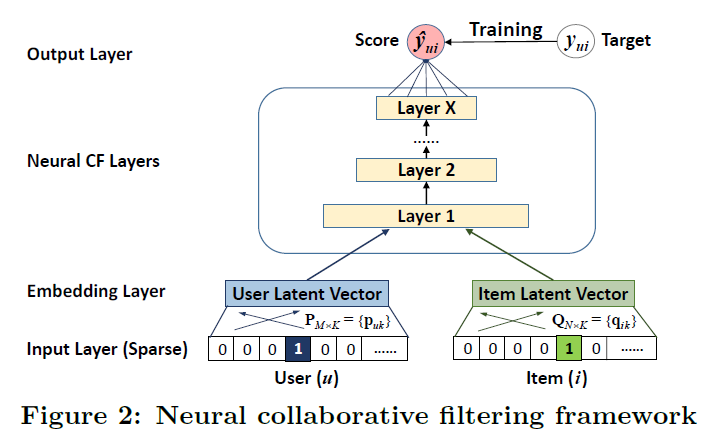
Input Layer
- 관측된 user와 item만 input feature로 활용하여 one-hot encoding을 통해 binary sparse vector로 변환
- cold start 문제 해결 가능하도록 조정하기 위해서 content feature를 사용하여 user와 item 표시
cold start : 추천 시스템이 새로운 또는 어떤 유저들에 대한 충분한 정보가 수집된 상태가 아니라서 해당 유저들에게 적절한 제품을 추천해주지 못하는 문제
Embedding Layer
- sparse representation을 dense vector로 변환하는 fully connected layer
- user(item) embedding은 user(item)에 대한 latent vector로 볼 수 있음
Neural CF Layer
- user(item) embedding을 이용하여 latent vector를 prediction score로 mapping
- 각 layer에서 user-item interaction의 특정 latent 구조를 가져올 수 있음
- 마지막 layer X는 model capacity를 결정
Output Layer
- predict rating 를 나타냄
-> 학습을 통해 과 target 간 pointwise loss 최소화 - pairwise learning도 사용
3.1.1 Learning NCF
squared loss
- pointwise learning에 기존에는 주로 squared loss를 활용함
- implicit data는 u가 i와 상호 작용했는지 여부를 나타내는 이진 값을 활용하므로 어울리지 않을 수 있음
NCF objective function
- predict rating 는 i가 u와 관련돼 있을 확률로 표현 가능
- NCF에 대해 확률적으로 처리하여, implicit feedback을 활용한 추천 문제를 이진 분류 문제로 처리함
-> binary cross-entropy loss 활용 (식 7)
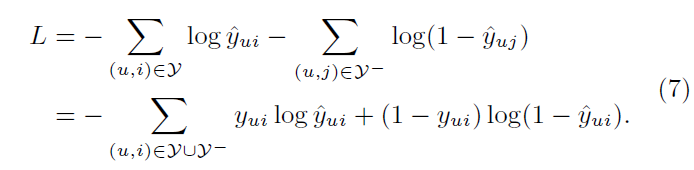
3.2 Generalized Matrix Factorization (GMF)
- user latent vector 와 item latent vector 를 element-wise product하여 mapping 함수 정의 (식 8)
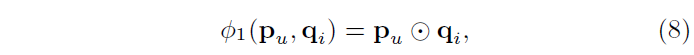
- vector를 output layer로 투영 (식 9)
- 은 output layer의 activation function
- 는 output layer의 edge weights
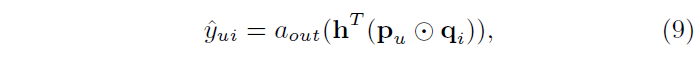
Generalized Matrix Factorization(GMF) setting
- 에 대해 sigmoid function 사용 -> 비선형성 추가해서 일반화
- logloss를 활용해서 를 학습시킴
3.3 Multi-Layer Perceptron (MLP)
- NCF는 user와 item을 concatenate해서 활용
-> 하지만 단순 concatenate는 user와 item 간 interaction을 설명하지 않음 - MLP를 활용해서 concatenate된 벡터에 hidden layer를 추가
-> user와 item latent feature 간 interaction 학습 - 와 간 interaction 학습을 위해 모델에 non-linearity와 flexibility 부여
-> GMF는 고정된 element-wise product만 활용 - 보통 layer size는 절반씩 줄인다.
NCF Framework MLP Formulation
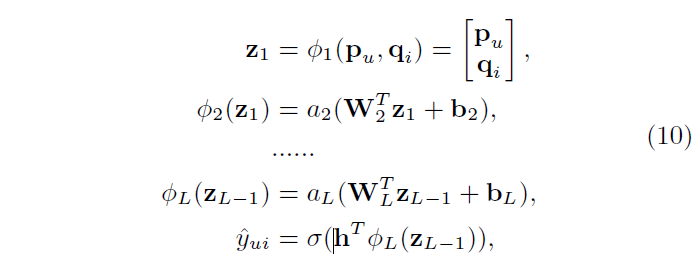
x-th layer 변수 설명
- : weight matrix
- : bias vector
- : activation function
activation function
sigmoid, tanh, ReLU, 혹은 다른 activation function 자유롭게 활용 가능
- sigmoid : 0 또는 1에 가까워지면 Gradient Vanishing(기울기 소실) 문제 발생
- tanh : sigmoid보단 낫지만 sigmoid를 rescale한 것에 불과
- relu : sparse data에 적합하고 overfitting 될 가능성 낮음 -> 성능 가장 높음
3.4 Fusion of GMF and MLP
- GMF는 linear kernel을 이용해 latent feature interaction 모델링
- MLP는 non-linear kernel을 이용해 데이터에서 interaction function 학습
-> 두 개를 융합하면 user-item interaction을 더 잘 모델링 할 수 있지 않을까?
Straightforward solution
- GMF와 MLP가 동일한 Embedding layer 공유

- GMF와 MLP가 동일한 크기의 임베딩을 사용해야 한다는 한계
-> 두 모델의 최적 임베딩 크기가 다를 경우 성능이 좋지 않을 수 있음
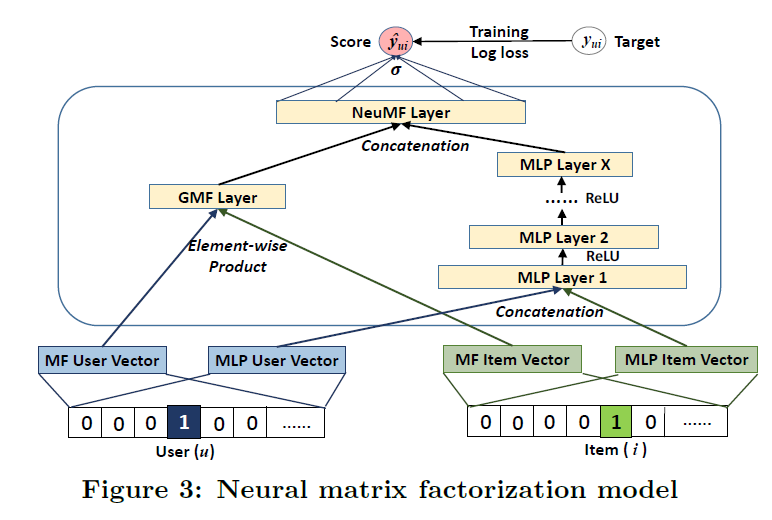
Paper solution
- GMF와 MLP가 별도의 Embedding 학습
-> last hidden layer를 연결하여 모델 결합 (NeuMF Layer)
Formulation
-
user-item latent structure 모델링을 위해 MF의 linearity와 DNN의 non-linearity 결합 -> NeuMF(Neural Matrix Factorization)
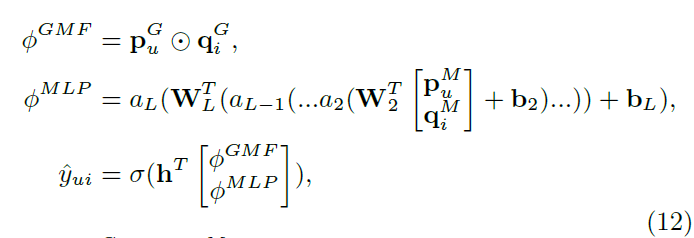
-
와 은 각각 GMF와 MLP에 대한 user embedding
-
와 은 각각 GMF와 MLP에 대한 item embedding
3.4.1 Pre-training
- 초기화는 딥러닝 모델의 수렴과 성능에 중요한 역할
-> Pretrained 모델을 활용해 NeuMF를 초기화 할 것을 제안 - random initialization을 활용해서 수렴할 때까지 GMF와 MLP 학습
- GMF, MLP model parameter를 NeuMF parameter의 각 부분의 초기화에 사용
- GMF 및 MLP 모델의 h 벡터를 나타내는 두 모델의 weight를 연결 (식 13)
-> 는 하이퍼 파라미터로 두 모델간의 trade off 결정
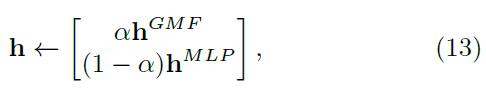
Optimizer
- GMF와 MLP Pre-train에는 Adam 이용
-> 빈번한 업데이트는 작게, 드문 업데이트는 크게 수행하여 각 parameter의 learning rate 조절 - NeuMF에 Pretrained parameter 입력 후에는 vanila SGD 활용
-> Adam은 업데이트를 위해 momentum 정보를 저장해야 할 필요가 있는데
NeuMF는 momentum 정보를 저장하지 않음
4. Experiments
4.2 Performance Comparison
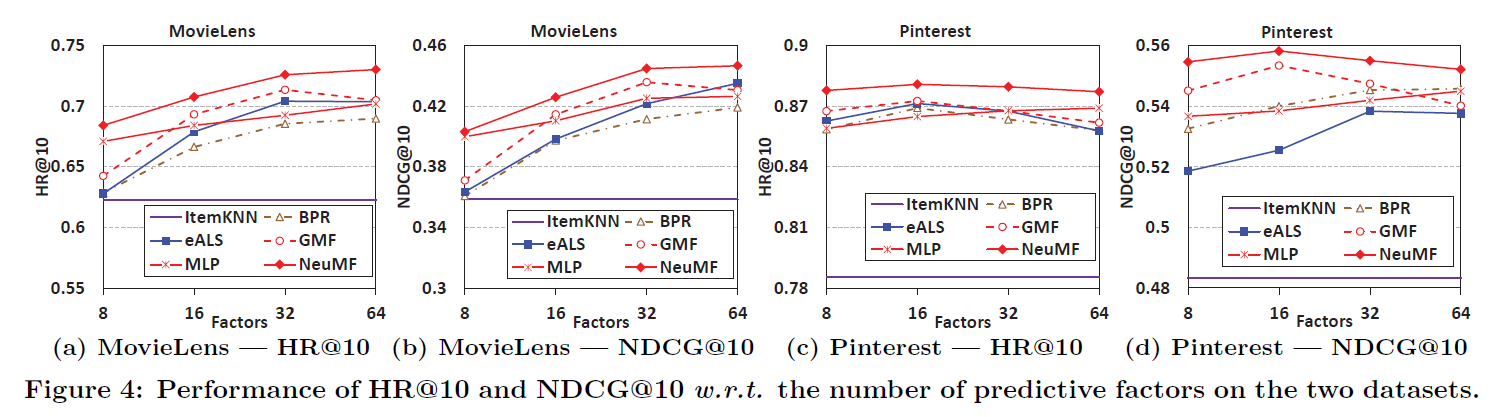
- Fig 4는 predictive factor 수에 따른 HR@10과 NDCG@10 성능 비교 결과
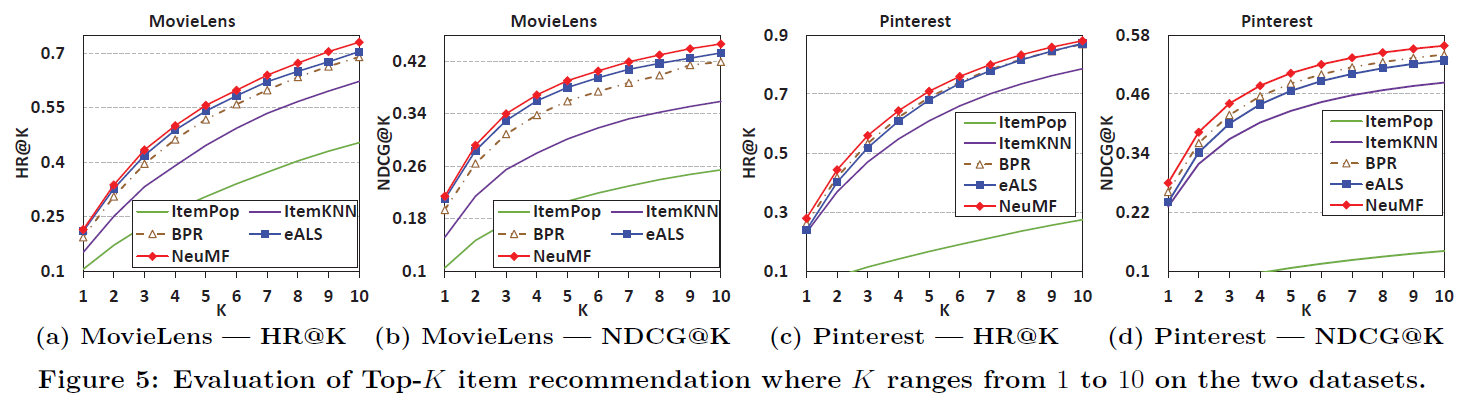
- Fig 5는 Top-K 추천 list K값 변화에 따른 HR@10과 NDCG@10 성능 비교 결과
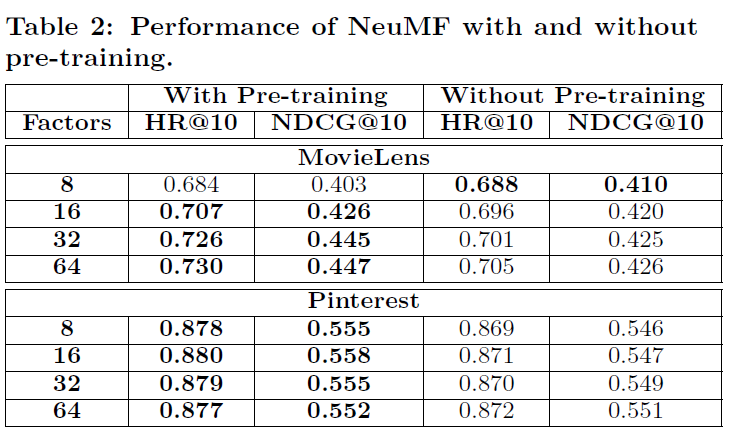
- Table 2를 통해 Pre-train이 성능 향상에 효과가 있음을 확인 가능
4.3 Log Loss with Negative Sampling
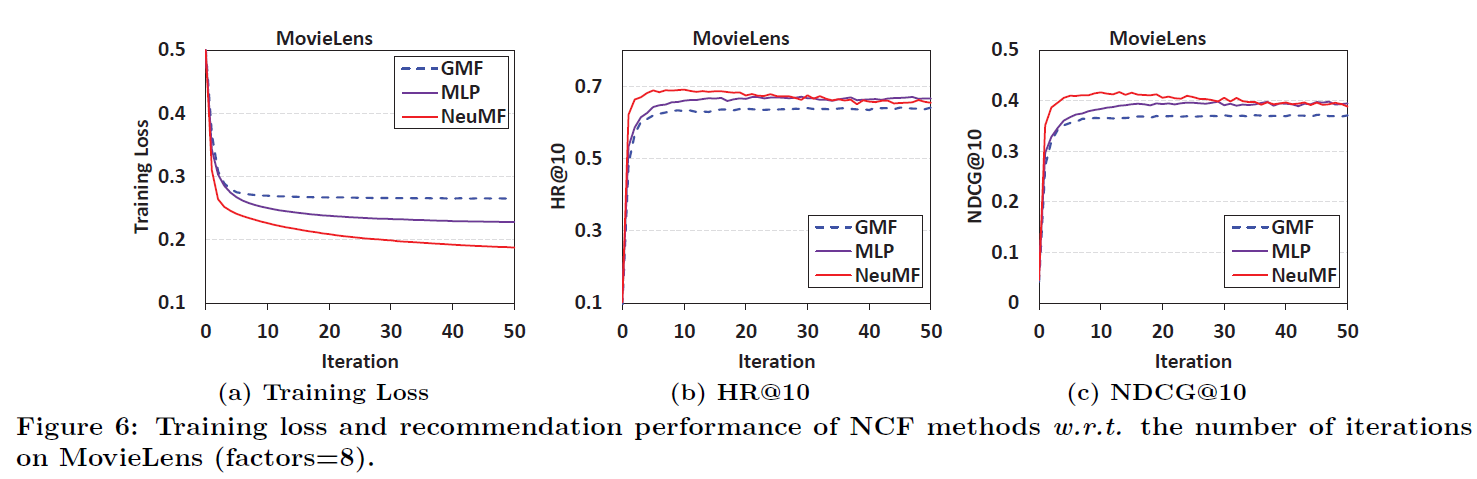
- Fig 6는 각 NCF method에 대한 training loss와 추천 성능 비교 결과
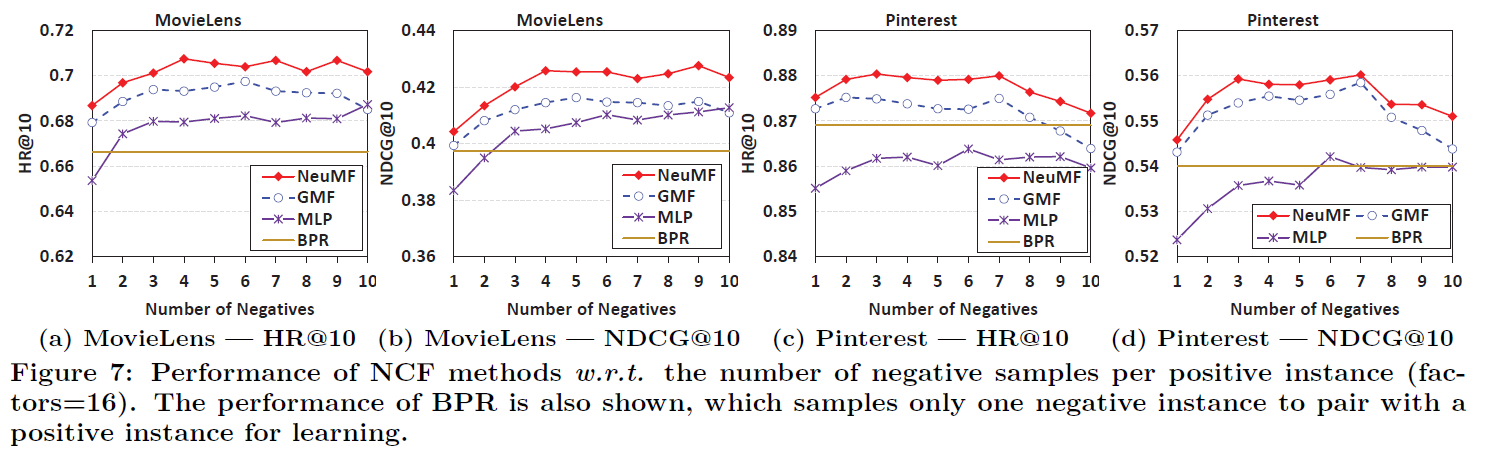
- Fig 7는 negative sampling ratio 변화에 따른 각 NCF method 성능 비교 결과
4.4 Is Deep Learning Helpful?
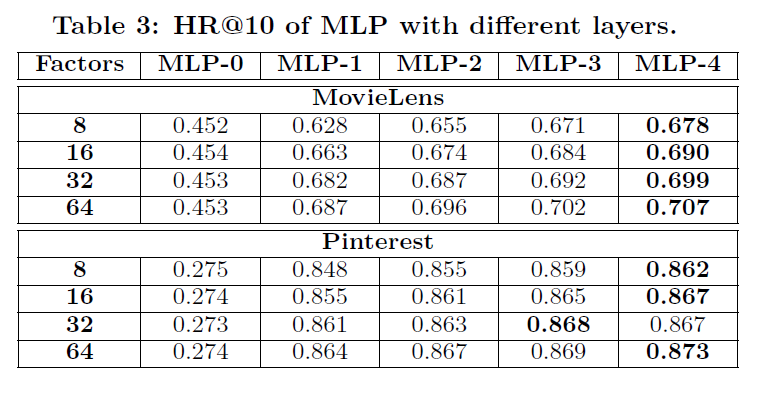
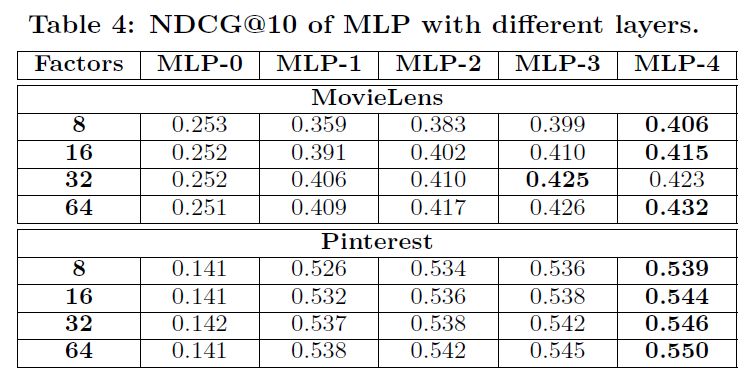
- Table 3, Table 4을 통해 layer가 깊어질수록 성능이 향상됨을 볼 수 있음