- Numerical Python
- 파이썬 고성능 과학 계산용 패키지
- 행렬과 매트릭스를 코드로 쉽게 표현할 수 있게 해준다
- 일반 List에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열에 대한 처리를 지원함
- 나중에 중요!
ndarray
test_array = np.array([1,4,5,8],float)
print(test_array)
type(test_array[3])
- np.array를 활용하여 배열 생성
- numpy는 하나의 데이터 type만 배열에 넣을 수 있다.
- List와 가장 큰 차이점 → dynamic typing not supported
- numpy array는 차례대로 값이 들어가지만, List는 값 자체가 들어가는 것이 아닌 주소(위치)를 저장하게 되기 때문에, 추가적으로 한번 더 찾아 들어가야 값을 찾을 수 있다.
- 따라서, ndarray는 List보다 접근과 연산이 쉽고 빠르다.
List
# ndarray & List 비교
a = [1,2,3,4,5]
b = [5,4,3,2,1]
a[0] is b[-1]is 라는 것은 메모리 주소를 비교하는 것이고, 리스트는 주소(위치)를 저장하기 때문에 메모리 비교를 하게 되면 True가 출력된다.
ndarray
a = np.array(a)
b = np.array(b)
a[0] is b[-1]반대로 array는 새로운 메모리에 할당하여 다른 메모리 주소를 가지기 때문에 False를 출력한다.
- shape : numpy array의 dimension 구성 반환
- dtype : numpy array의 data type 반환
test_array = np.array([1,4,5,"8"], float)
print(test_array)
print(type(test_array[3]))
print(test_array.dtype)
print(test_array.shape)array shape
- array의 Rank에 따라 불리는 이름이 다르다.

Matrix
ndim : number of dimensions (x,y,z)
tensor = [[[1,2,5,8],[1,2,5,8],[1,2,5,8]],
[[1,2,5,8],[1,2,5,8],[1,2,5,8]],
[[1,2,5,8],[1,2,5,8],[1,2,5,8]]]
np.array(tensor,int).shape- ndarray의 single element가 가지는 data type
- 각 element가 차지하는 memory의 크기가 결정됨
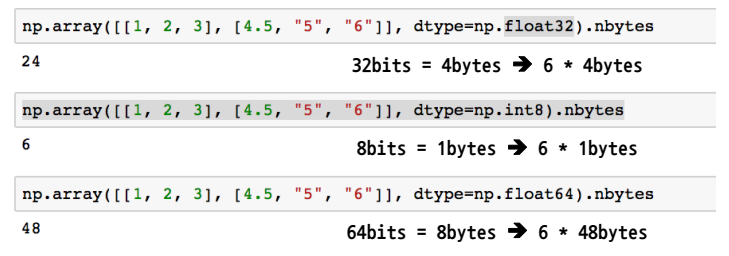
Reshape
- Array의 shape의 크기를 변경, element 갯수는 동일
test_matrix = [[1,2,3,4],[1,2,5,8]]
np.array(test_matrix).shape
np.array(test_matrix).reshape(1,-1).shape
np.array(test_matrix).reshape(1,-1,2).shape- flatten
-
다차원 array를 1차원 array로 변환
test_matrix = [[[1,2,3,4],[1,2,5,8]], [[1,2,3,4],[1,2,5,8]] ] np.array(test_matrix).shape np.array(test_matrix).flatten().shape
-
- indexing for numpy array
-
list와 달리 이차원 배열에서 [0,0] 표기법을 제공함
-
matrix 일 경우 앞은 row 뒤는 column을 의미
test_example = np.array([[1,2,3,4],[1,2,5,8]],int) print(test_example[0,1]) print(test_example[0][1]) -
list와 달리 행과 열 부분을 나눠서 slicing이 가능함
-
matrix의 부분 집합을 추출할 때 유용함
test_example = np.array([[1,2,3,4],[1,2,5,8]],int) print(test_example[:,2:]) print(test_example[1,1:3]) print(test_example[1:3])
-
creation function
- arange
-
array의 범위를 지정하여, 값의 list를 생성하는 명령어
-
range : List의 range와 같은 효과
np.arange(30) np.arange(0,10,0.5) # floating point도 가능 np.arange(30).reshape(5,6)
-
- ones, zeros, empty
-
특정 값을 가지는 행렬 생성
np.zeros(shape=(10,), dtype=np.int8) np.ones(shape=(10,), dtype=np.int8) np.empty(shape=(10,), dtype=np.int8)
-
- something_like
-
같은 reshape의 특정 값을 가지는 행렬 생성
test_matrix = np.arange(30).reshape(5,6) np.ones_like(test_matrix)
-
- identity
-
단위행렬 생성
np.identity(n=3, dtype=np.int8) np.identity(5)
-
- eye
-
대각선이 1인 행렬 생성
-
identity와 다르게 시작 값을 지정할 수 있다.
np.eye(3) np.eye(3,5,k=2) np.eye(N=3,M=5,dtype=np.int8)
-
- diag
-
대각 행렬의 값을 추출
-
eye와 마찬가지로 시작값 지정 가능
matrix = np.arange(9).reshape(3,3) np.diag(matrix) np.diag(matrix, k=1)
-
- random sampling
-
데이터 분포에 따른 sampling으로 array를 생성
np.random.uniform(0,1,10).reshape(2,5) # 균등분포 np.random.normal(0,1,10).reshape(2,5) # 정규분포
-
Operation function
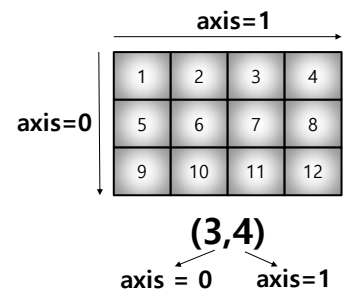
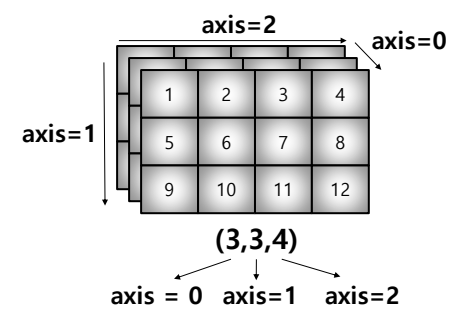
- axis
- 모든 operation function을 실행할 때 기준이 되는 dimention 축
- (3,4) 일 때, axis = 0 이면 4개의 값이 나타나고, axis =1 이면 3개의 값이 나타난다.
- 3차원인 경우 하나씩 밀려서 0 : x , 1 : y , 2 : z 식으로 작동
- mathematical functions
- sum : 합
- mean : 평균
- std : 표준편차
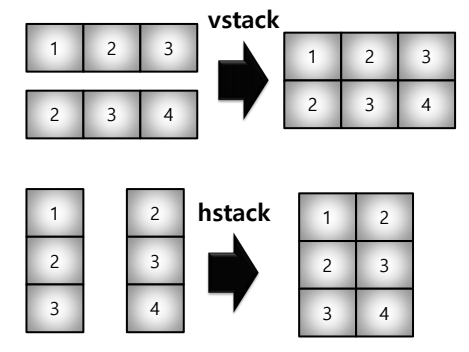
- concatenate
- numpy array를 합치는 함수
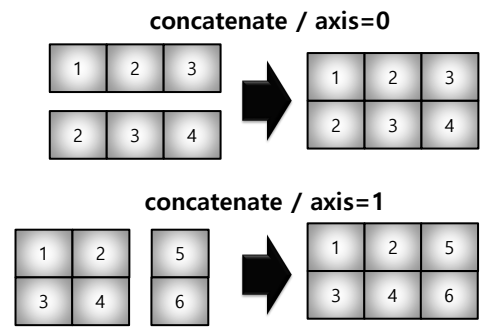
-
Operations b/t arrays
- numpy는 array간의 기본적인 사칙 연산을 지원
- dot product
-
matrix 기본 연산
test_a = np.arange(1,7).reshape(2,3) test_b = np.arange(7,13).reshape(3,2) test_a.dot(test_b)
-
- transpose
-
전치
test_a = np.arange(1,7).reshape(2,3) test_a.T
-
- broadcasting
-
shape이 다른 배열 간 연산 지원
test_matrix = np.array([[1,2,3],[4,5,6]], float) scalar = 3 test_matrix + scalar -
scalar - vector 외에도 vector - matrix 간의 연산도 지원
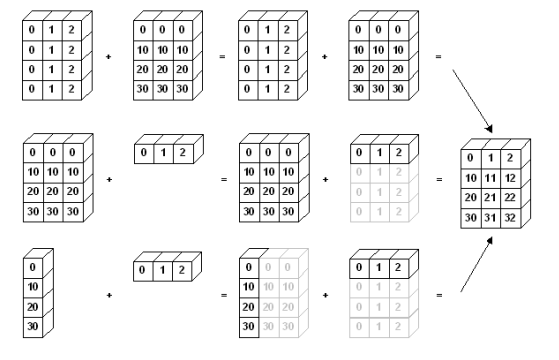
-
-
numpy performance
- timeit
- jupyter 환경에서 코드의 퍼포먼스를 체크하는 함수
- 일반적으로 속도는 for loop < list comprehension < numpy
- 100,000,000 번의 loop이 돌 때, 약 4배 이상의 성능 차이를 보임
- 대용량 계산에서는 가장 흔히 사용됨
- timeit
-
comparisons
- numpy array의 비교
- All & Any
-
Any : 하나라도 조건이 성립하면 True
-
All : 모든 element가 조건을 만족해야 True
-
element간 비교의 결과를 boolean type으로 반환
a = np.arange(10) np.any(a>5) , np.any(a<0) np.all(a>5) , np.all(a<10)
-
- np.where
-
whrere(condition, True, False)
-
condition 에 따라 True이면 True 자리에 있는 값 반환, False면 False 자리에 있는 값 반환
-
condition 단일로 사용하게 되면 조건에 해당하는 index 반환
np.where(a>0,3,2) a = np.arange(10) np.where(a>5)
-
- argmax & argmin
-
argmin : array 내 최소값의 index 반환
-
argmax : array 내 최대값의 index 반환
-
argsort : array 내 element 정렬의 순서 반환
a = np.array([1,2,3,4,5,8,78,23,3]) a.argsort() np.argmax(a) np.argmin(a) a[np.argmax(a)] a[np.argmin(a)]
-
-
boolean index
-
boolean array를 사용하여 특정 조건에 맞는 값을 뽑아오는 것
-
특정 조건에 따른 값을 배열 형태로 추출
-
같은 모양의 boolean list를 사용하여 값을 추출
test_array = np.array([1,4,0,2,3,8,9,7],float) test_array > 3 test_array[test_array > 3]
-
-
fancy index
-
numpy는 array를 index value로 사용해서 값 추출
-
boolean index와 다르게 모양이 같을 필요는 없지만, index 범위를 벗어나면 안된다.
-
integer list를 사용하여 값을 추출
a = np.array([2,4,6,8],float) b = np.array([0,0,1,3,2,1], int) a[b]
-
-
txt tpye 읽기/저장
- loadtxt : txt data 읽기
- savetxt : txt data 쓰기
