Sequential Model
-
문장은 항상 길이가 달라질 수 있으며 어순이나 바뀌거나 단어가 빠지는 문제들이 있기 때문에 모델링하기가 어렵다.
-
이러한 문제들을 해결하고자 Transformer self attention이라는 구조를 사용한다
Transformer

-
RNN은 재귀적인 구조인데, transform은 재귀적인 구조가 없고, attention이라고 불리는 구조를 활용했다.
-
이 방법론은 sequential 데이터를 처리하고 이 데이터를 encoding하는 방법이기 때문에 NMT(Neural Machine Translation)문제에만 적용되지 않는다.
-
따라서, transfromer는 image classification 또는 image detection , visual transformer등에 사용되기도 한다
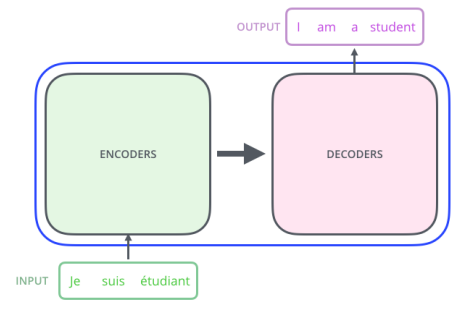
- 결국, 우리가 하려고 하는 것은 불어 문장이 주어지면 영어 문장으로 바꾸는 것과 같은 seq2seq 모델을 만드는 것이다
-
입력은 3개의 단어로 되어있고, 출력은 4개의 단어로 되어있는 것을 보아 입력 시퀀스와 출력 시퀀스의 단어 숫자가 다를 수 있고, 입력 시퀀스의 도메인과 출력 시퀀스의 도메인이 다를 수 있으며 이것이 한 개의 모델로 이루어져 있는 것을 볼 수 있다.
-
원래 RNN의 경우는 3개의 단어가 들어가면 3번의 무언가가 돌아가는데, transformer의 encoder는 3개의 단어나 100개의 단어나 상관없이 한번에 100개의 단어를 찍어낼 수 있으며, generateion 할 때는 auto regressive하게 된다.
-
즉, encoder는 한번에 n개의 단어를 한번에 처리할 수 있는 구조로 이해하면 된다.
-
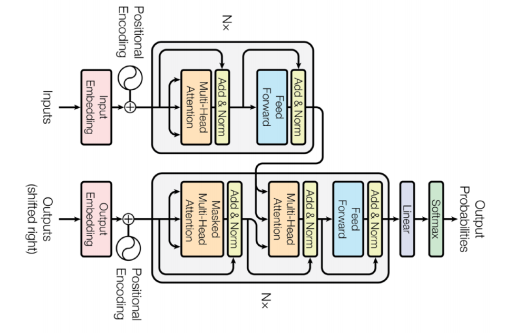
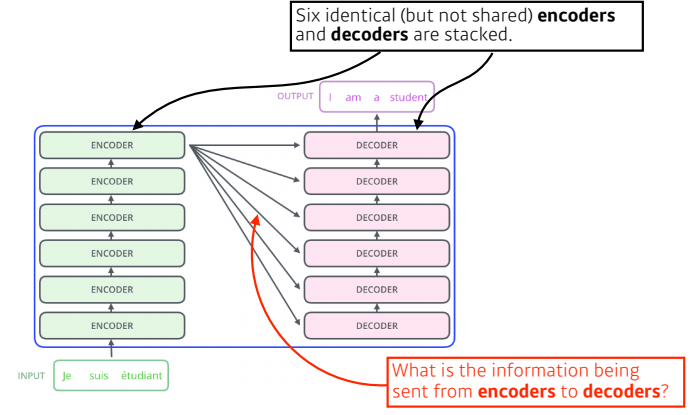
transformer는 encoder와 decorder가 동일한 구조로 stack되어있는 모델이다.
이제 알아봐야 할 것
- n개의 단어가 어떻게 encoder에서 처리가 되는지?
- encoder와 decoder 사이에 어떤 정보를 주고 받는지?
- decoder에서 어떻게 generation 할 수 있을지?
Encoder
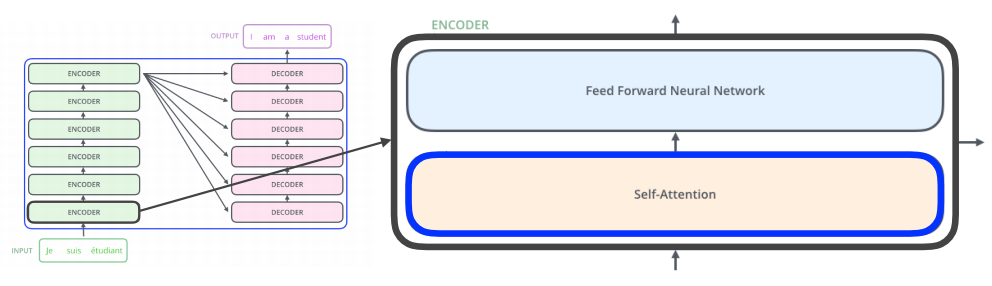
-
Encoder는 Self attetion과 Feed Forward network가 합쳐진 구조로, 이 한 쌍이 하나의 encoder가 된다.
-
첫 번째 레이어의 encoder에서 나온 출력값은 두 번째 레이어의 encoder로 들어가게 되고 이것을 반복하는 구조로 이루어져 있다.
-
Self-Attention이 transformer의 key point이며, feed forward network는 사실 mlp와 동일하다.
Self attention

- 3개의 단어가 들어오고 기계로 번역하여 특정 숫자의 3개의 벡터로 표현된다.
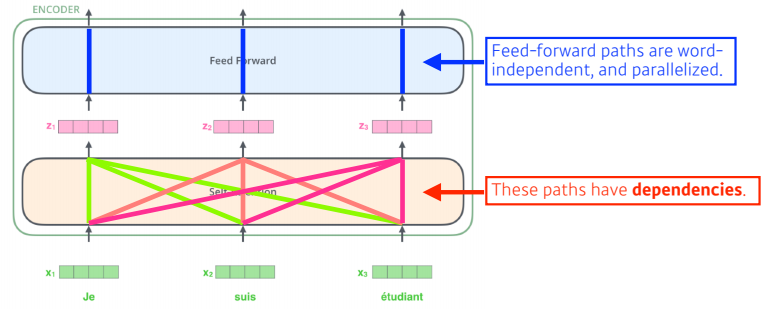
-
self attention은 3개의 단어가 주어지면 3개의 벡터를 찾아준다.
-
여기서 중요한 점은 하나의 벡터 x1이 z1으로 넘어갈 때 단순히 x1의 정보만 활용하는 것이 아니라 x2와 x3의 정보까지 함께 활용하는 것
-
즉, n개의 단어가 주어지고 n개의 z벡터를 찾는데 각각의 x_i를 z_i로 바꿀 때 나머지 n-1개의 x를 같이 고려를 하는 것으로 dependency가 존재한다
-
feed forward에서는 dependency가 존재하지 않고 z 벡터들을 그대로 feed forward를 통과시켜 변환해주는 것
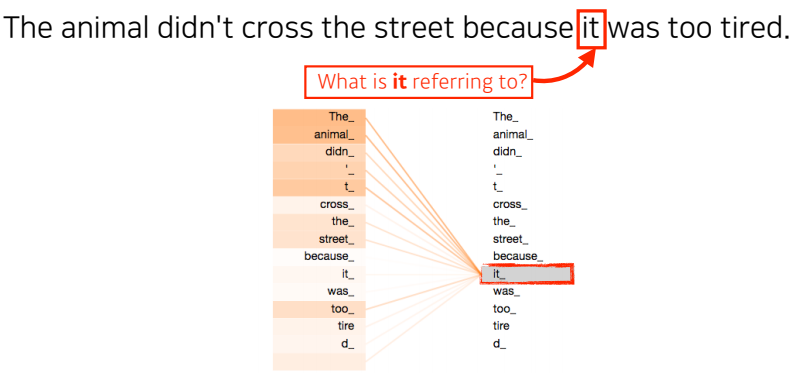
-
‘The animal didn’t cross the street because it was too tired.’ 이러한 문장이 주어졌을 때 문장을 이해하기 위해서는 뒤에 나오는 it이 어떤 단어에 dependent하는지 알아야 한다.
-
바꿔 말하면, 하나의 문장에서의 단어를 설명할 때는 단어 그 자체로만 이해하는 것이 아니라 문장 속에서 다른 단어들과 어떤 interaction이 있는지를 이해해야 한다.
-
transformer 는 it이라는 단어를 encoding하게 되면 다른 단어들과의 관계성을 보게 되고, it이 animal과 높은 관계가 있다고 학습이 되어진다
-
따라서, 이를 통해 기계가 단어를 더 잘 이해할 수 있다.
-
self attention 구조
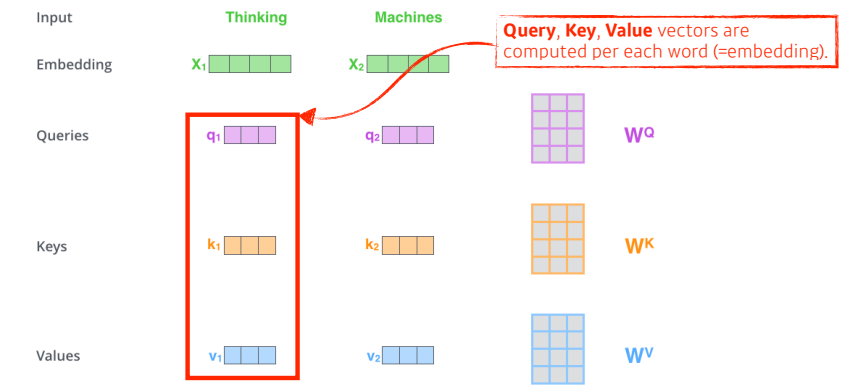
-
기본적으로 self attention 구조는 3가지의 Query,Key,Value 벡터를 만들어 내는데 각 단어마다 Q, K, V가 존재한다. 3개의 네트워크가 있다고 생각!
-
이러한 Q,K,V 벡터들은 주어진 입력이 주어졌을 때 하나의 단어당 3개의 벡터를 만들게 되고, x1이라는 첫번째 단어에 대한 임베딩 벡터를 새로운 벡터로 바꾸어 줄 것이다.
-
score vector
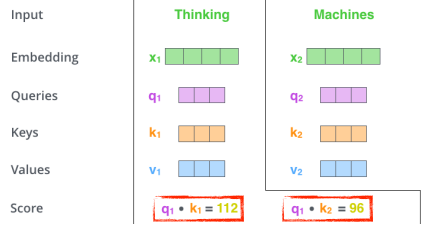
- 내가 encoding하고자 하는 Q vector와 나머지 n개의 단어에 대한 K vector를 구하고 이 두 벡터를 내적하는 것으로 score vector를 구할 수 있으며, 이는 i번째 단어가 나머지 단어들과 어떠한 interaction이 있는지 얼마나 유사한지를 알 수 있다.
- 위의 사진에서 첫번째 단어 ‘Thinking’에 대한 score vector를 계산하기 위해서는 내가 encoding하고자 하는 q1와 나머지 n개의 단어에 대한 k2의 내적으로 score vector를 나타낼 수 있다.
-
score vector를 통해 단어 간 얼마나 interaction 하는지를 학습하게 하는 것이고, 이를 attention 이라 한다.
-
interaction score
-
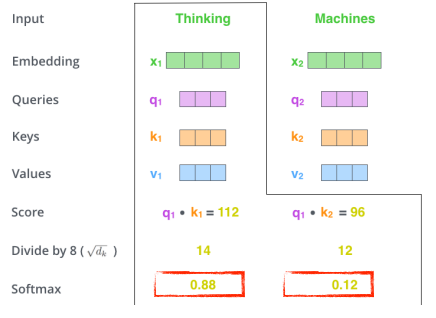
score vector를 sqrt(key dimension) 값으로 나눈다.
- 이렇게 나누는 이유는 Key vector의 dimension에 dependent하기 때문이다.
- 여기서는 64 demension 이기 때문에 8로 나눔
-
normalization된 score가 sum해서 1이 되도록 softmax를 취해주면 각 단어에 대한 interaction 값이 나타난다.
- Thinking이라는 단어의 자신과의 interaction 값은 0.88이 되고 Machine과의 interaction의 값은 0.12가 된다.
-
이렇게 만들어진 interaction score와 value vector의 가중합을 구하면 최종적으로 각 단어의 인코딩 된 벡터가 나타난다.
- 각 단어의 임베딩 벡터를 인코딩 벡터로 변환
self-attention 정리
- 단어에 대한 임베딩 벡터가 있고, Query,key,value vector 생성
- Query vector와 전체 단어에 대한 Key vector의 내적으로 score vector 생성
- score vector를 key value dimension의 제곱근으로 나눠준 후(normalization) softmax를 취하여 attention 생성
- attention과 value vector 의 가중합으로 최종 인코딩 벡터 생성
- 이를 반복함으로 각 단어에 대한 인코딩 벡터 생성
- 여기서 주의해야 할 점
- Q vector와 K vector는 내적을 해야 하기 때문에 항상 차원이 같아야 한다. 하지만, V vector는 가중합만 하기 때문에 차원이 달라도 된다.
- 최종적으로 나오는 인코딩 된 벡터의 차원은 V vector의 차원과 동일하다.
self-attention을 행렬로 표현
-
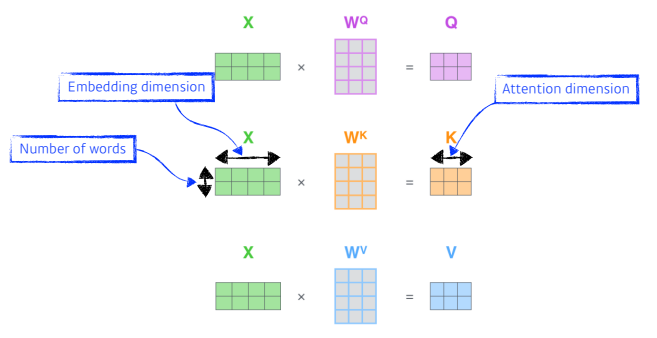
위의 그림은 임베딩 벡터에서 Q,K,V를 만드는 과정을 담아내고 있으며, 두 개의 단어가 주어졌을때 각각 두 개의 Q,K,V 벡터가 생성
-
X 의 2 x 4는 두 개의 단어가 있으며 각 단어의 임베딩 차원이 4인 것을 말한다.
-
WQ, WK, WV는 Q,K,V 벡터를 찾아내는 각각의 MLP로 생각하면 되고 , 이 MLP는 encoding된 단어마다 shared된다.
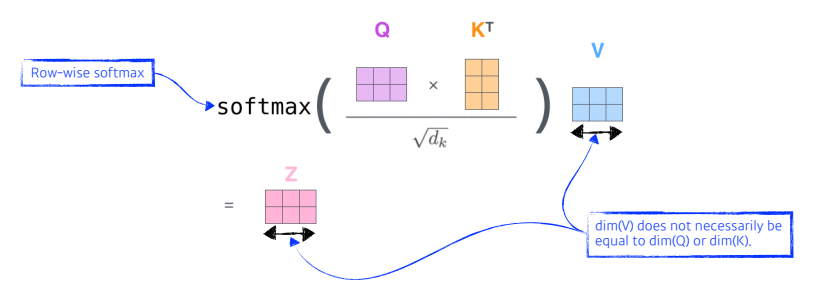
- 이전에 했던 인코딩 벡터를 추출하기 위한 방법을 나타낸 것으로, Q vector와 K vector를 내적하고, Key vector dimension의 제곱근으로 나눠준 후 V vector와 가중합이 이루어지는 과정이다,
왜 이 방법이 잘될까?
-
어떤 이미지 하나가 주어지고, 이 이미지를 MLP 혹은 CNN을 통해 dimension을 바꿀때 input이 fix되면 출력이 고정된다. → 내가 가지고 있는 weight나 conv filter가 고정되어 있기 때문에
-
하지만, transformer는 input이 고정되어 있다고 하더라도 encoding하고자 하는 단어와 옆에 있는 단어에 따라 encoding된 값이 달라진다.
-
이는 MLP보다 flexible한 모델으로 생각할 수 있으며, 입력이 고정되더라도 옆에 주어지는 다른 입력들에 따라 출력이 달라질 수 있는 여지를 줌으로 더 많은 것을 표현할 수 있다.
-
RNN은 n개의 단어가 주어졌을 때 그만큼 모델을 돌리면 되지만, transformer는 n개의 단어를 한번에 처리해야하고 연산비용이 에 비례하기 때문에 length에 따라 처리할 수 있는 한계가 있다.
Multi-headed attention
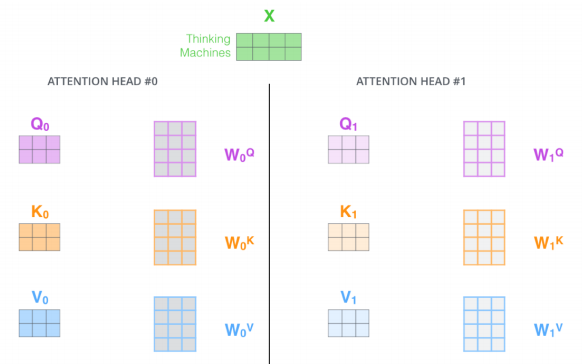
- 하나의 입력에 대해서 Q,K,V를 여러 개 만드는 네트워크
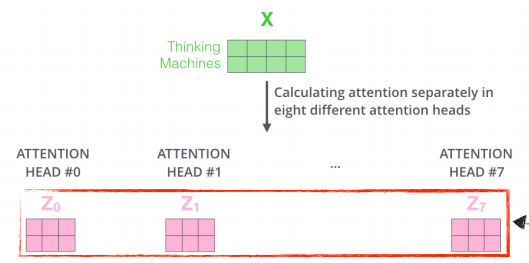
-
이를 통해 n개의 attention을 반복하게 되면 n개의 encoding된 vector가 나오게 된다.
- 여기서는 8개의 head가 사용되었고, 하나의 임베딩된 벡터가 있으면 8개의 encoding된 결과가 나타난다
-
여기서 고려해야 할 점은 encoder가 다음 번으로 넘어가기 위해서는 입력과 출력의 차원을 맞춰 주어야 한다. 즉, 임베딩된 dimension과 인코딩되어서 나오는 vector가 항상 같은 차원이어야 한다

- 이 때 선형변환을 통해 차원을 맞추어 주는데, input이 10 dimension이고 8개의 output이 나타났다고 하면, 80 dimension의 encoding된 vector가 있다고 할 수 있고, 이에 80 x 10행렬을 곱해서 줄여버린다 라고 생각하면 된다.
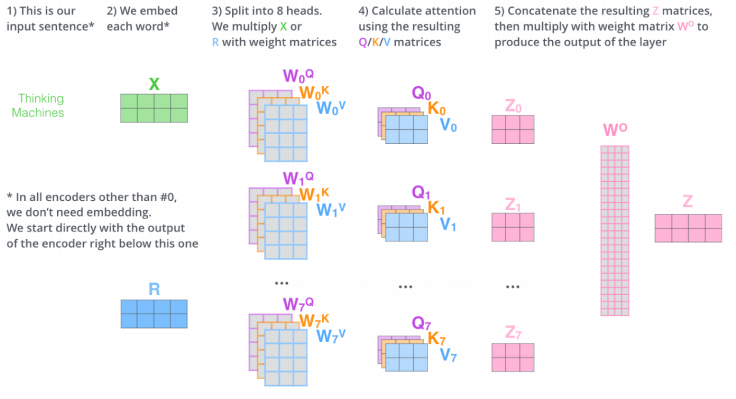
Multi-head attention 정리
- s x s 모양인 input이 들어오게 되면 각각의 단어를 임베딩한다
- n개의 head로 나누어 n개의 self attention을 통해 n개의 encoding vector를 만든다
- 다시 선형변환을 통해 s x s 차원을 맞춘다
Position encoding
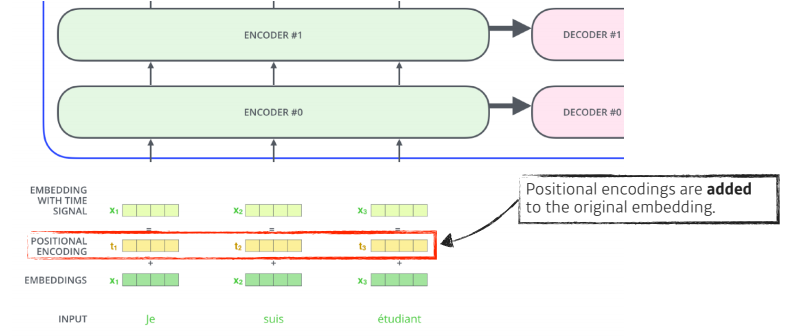
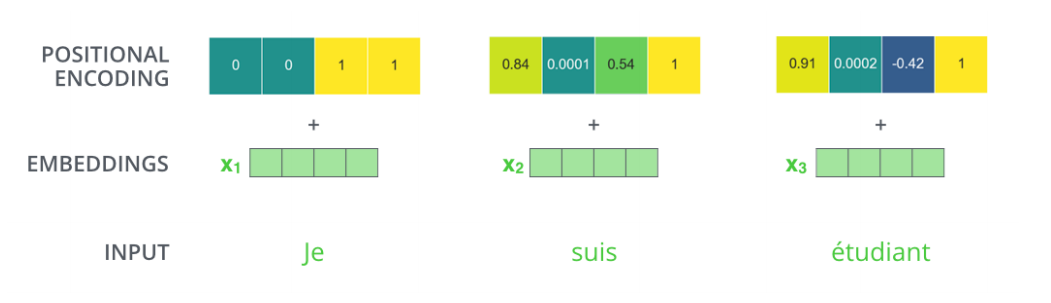
-
입력에 특정 값을 더해주는 bias라 생각하면 된다
-
n개의 단어를 sequential하게 넣어줬다고 하지만, sequential의 정보가 이 안에 포함되어 있지 않다
-
그렇기 때문에 문장 혹은 이미지에는 순서가 중요한데, position encoding이 필요하다.
-
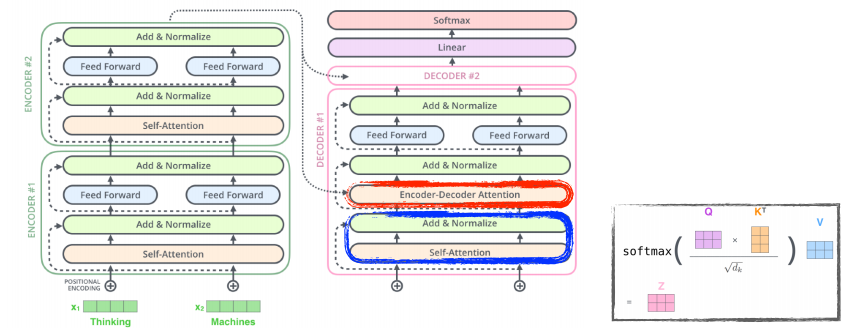
transformer에서의 encoder 구조
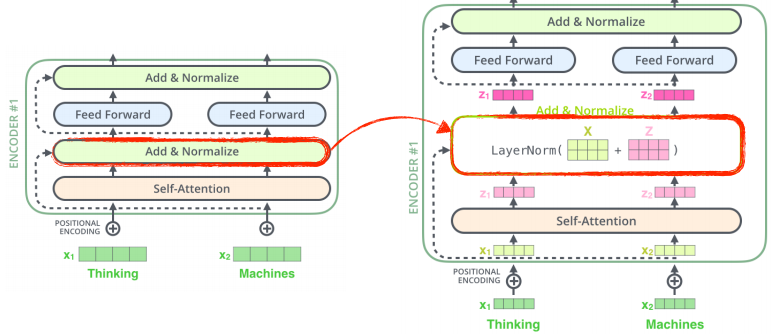
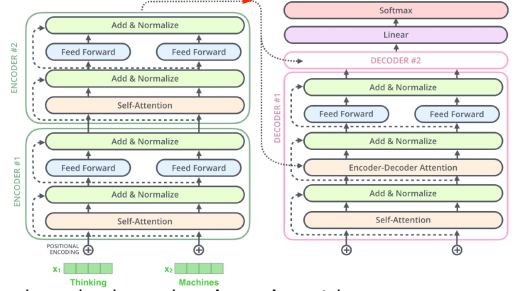
- 각 단어에 대한 임베딩 벡터는 self attention , add & normalize ,layer norm 를 거치고, 그렇게 생성된 각각의 Z(encoding된) vector에 대해 독립적으로 동일한 네트워크가 동작하는 것을 반복하는 구조이다.
Decoder
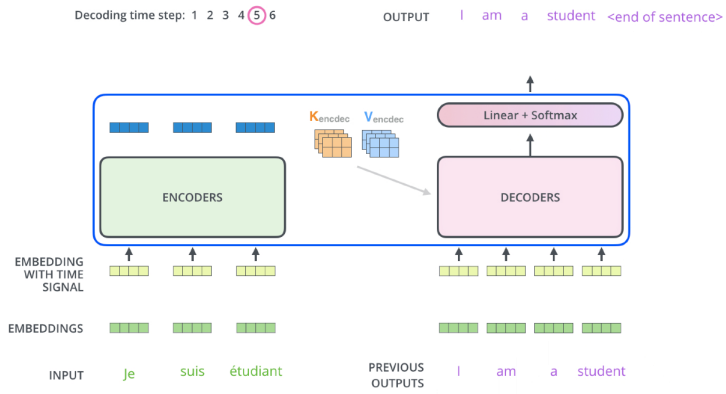
-
Encoder는 주어진 단어를 표현하는 것이고 Decoder는 생성하는 것
-
중요한 것은 Encoder에서 Decoder로 어떠한 정보가 전해지는 것인가?
-
input에 있는 단어들을 decoder에 있는 출력하고자 하는 단어에 대한 attention map을 만들려면 Key, Value vector가 필요하다
-
이 때의 Key,Value vector는 encoder가 stack이 되어있으므로 가장 상위의 encoder에서 나온 K,V vector를 사용한다.
-
학습할 때는 입력과 출력의 정답을 알고 있는데, 내가 i번째 단어를 만드는데 모든 문장을 다 알고 있으면 학습하는 의미가 없으므로 masking을 통해 이전 단어들만 dependent하고 뒤에 단어들에 대해서는 dependent하지 않게 한다.
-
Decoder는 이전까지의 generation 단어들만으로 Qurey를 만들고 encoder로 얻는 Key, Value 벡터들을 활용하여 출력을 나타낸다
-
final layer에는 단어들의 분포를 만들어 그 중 하나씩 sampling하는 것으로 작동한다.
VIT
-
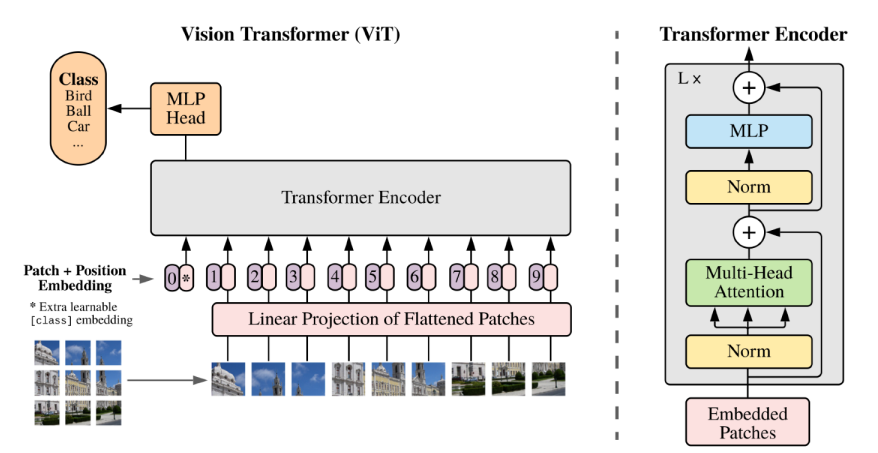
transformer 는 사실 NMT 문제에만 활용이 되었는데, self attention 구조를 이미지 도메인에서도 활용하는 VIT가 나타났다.
-
원래 NMT에서는 문장들이 주어지므로 Sequence가 주어지는데, 여기서는 이미지를 여러 영역으로 나누고, 각 영역에 있는 subpatch들을 Linear layer를 통과시킴으로써 하나의 입력으로 취급하는 것에 차이가 있다.
