Introduction
1. What is RAG?
- RAG(Retrieval Augmented Generation): 검색 증강 생성 기법
- 이미 학습된 LLM에 외부의 지식 베이스를 참조하도록 하는 프로세스
2. RAG 구조
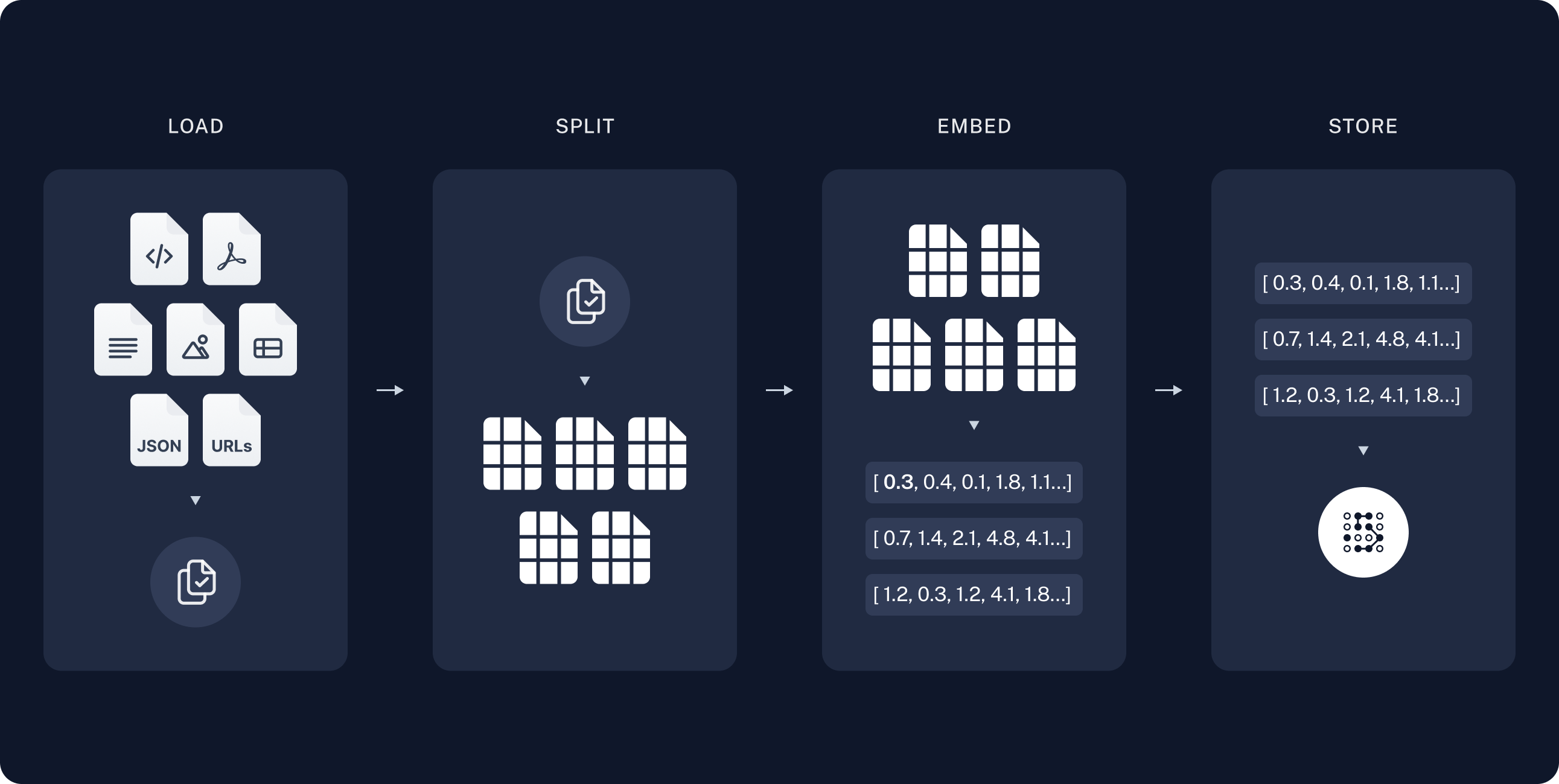
- Indexing: 외부 지식 소스에서 테이터를 수집하고 인덱싱하는 파이프라인
1) Load: DocumentLoaders에 의해 데이터 로드
2) Split: Text splitters에 의해 큰 문서들이 더 작은 문서 조각들로 변환됨
3) Store: VectorStore와 Embeddings 모델에 의해 저장
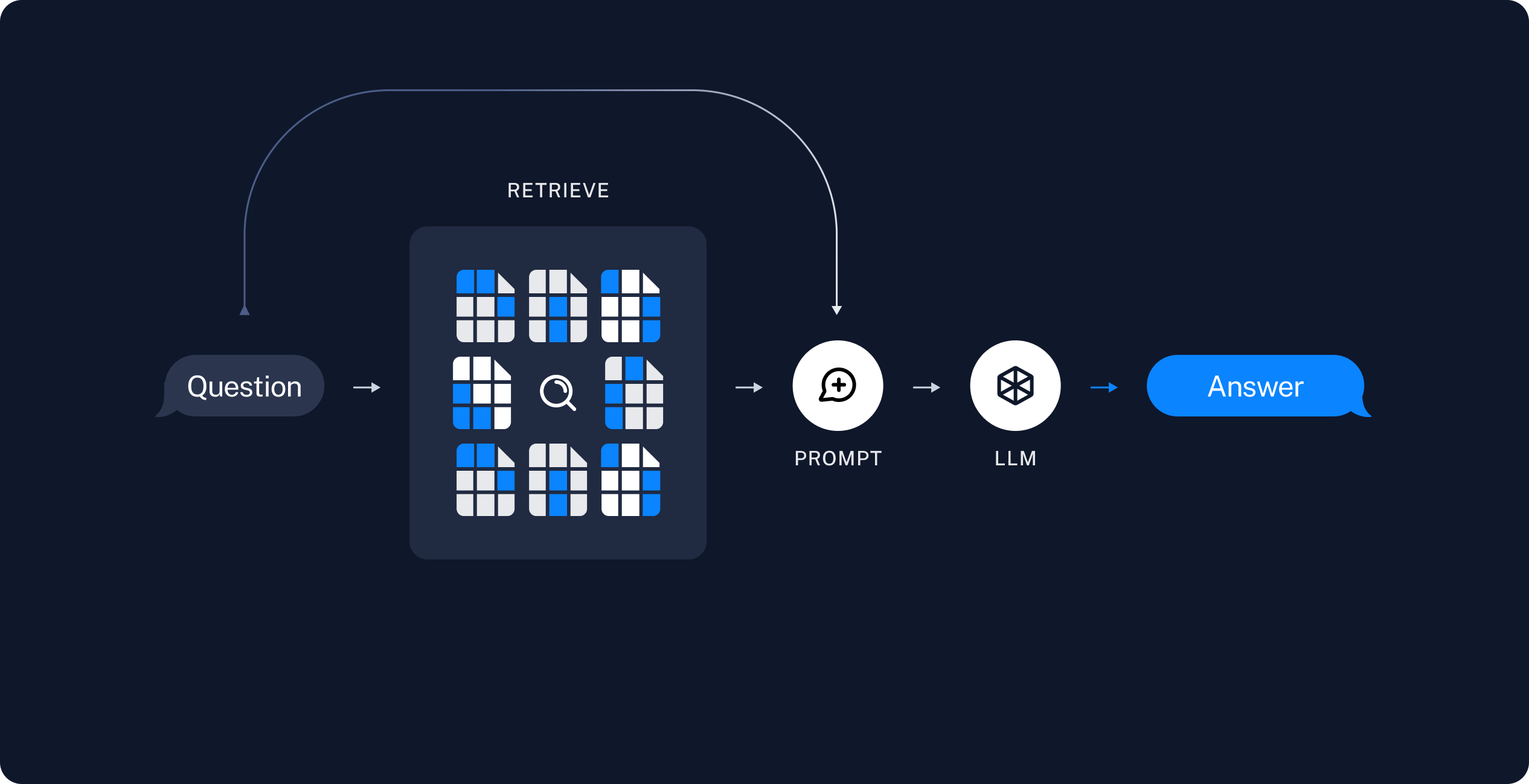
- Retrieval and generation
4) Retrieve: Retriever로 주어진 user input과 관련있는 조각들을 저장소에서 가져옴
5) Generate: 4번의 것들을 prompt에 담고, LLM에게 제공해 답변을 받음
Data Loaders and Splitters
1. Data Loader
- 데이터를 모델에 로딩하는 역할
- RAG에서 사용할 문서나 텍스트 데이터를 불러와서 처리 가능한 형식으로 변환하는 과정
2. Splitter
- 로드된 데이터를 적절한 크기로 나누는 역할
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50, # 앞 문서의 끝부분을 조금 가져오는 정도
)
loader = UnstructuredFileLoader('./files/chapter_one.docx')
print(loader.load_and_split(text_splitter=splitter))from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
separator="\n", # 구분자를 기준으로 분할
chunk_size=950,
chunk_overlap=100, # 앞 문서의 끝부분을 조금 가져오는 정도
)
loader = UnstructuredFileLoader('./files/chapter_one.docx')
print(loader.load_and_split(text_splitter=splitter))Tiktoken
1. Tiktoken
- OpenAI에서 만든 tokenization 라이브러리
- 빠른 속도로 tokenize/detokenize 할 수 있도록 최적화되어 있음
- 각 모델(GPT-3, GPT4 등)에 맞는 토큰화 규칙을 지원
- 자주 등장하는 단어 조합 단위로 분할하는 BPE(Byte Pair Encoding) 방식을 사용
2. CharacterTextSplitter vs CharacterTextSplitter.from_tiktoken_encoder
- CharacterTextSplitter
-length_function = len을 기본으로 사용
- 일반적인 문자 개수를 기준으로 텍스트를 분할
- 문자 개수에 맞추기 때문에 문장 or 단어 중간이 끊기게 분할할 수도 있음 - CharacterTextSplitter.from_tiktoken_encoder
-tiktoken의 인코딩 방식 사용
- 단어 단위나 문장의 자연스러운 구분에 맞춰 토큰을 분할
- 비교적 사람에 가까운 텍스트 조절
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
# Tiktoken: OpenAI에서 만든 tokenization library.
splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=950,
chunk_overlap=100,
)
loader = UnstructuredFileLoader('./files/chapter_one.docx')
print(loader.load_and_split(text_splitter=splitter))Vectors
1. Embedding
- 단어, 문장 또는 문서 등의 텍스트 데이터를 수치 벡터로 변환하는 방법
- 텍스트의 의미를 숫자 벡터로 표현하므로, 두 벡터 간의 거리나 유사도를 계산하여 텍스트 간의 의미적 유사성을 비교 가능
2. Embedding example
- 단어가 아래의 표와 같이 임베딩 되었다고 하면, 그림과 같이 3차원 좌표로 나타낼 수 있음
| 남성성(Masculinity) | 여성성(Femininity) | 왕족성(Royalty) | Embedding result | |
|---|---|---|---|---|
| King | 0.9 | 0.1 | 1.0 | [0.9 0.1 1.0] |
| man | 0.9 | 0.1 | 0.0 | [0.9 0.1 0.0] |
| queen | 0.1 | 0.9 | 1.0 | [0.1 0.9 1.0] |
| woman | 0.1 | 0.9 | 0.0 | [0.1 0.9 0.0] |
| Nobility | 0.5 | 0.5 | 0.5 | [0.5 0.5 0.5] |
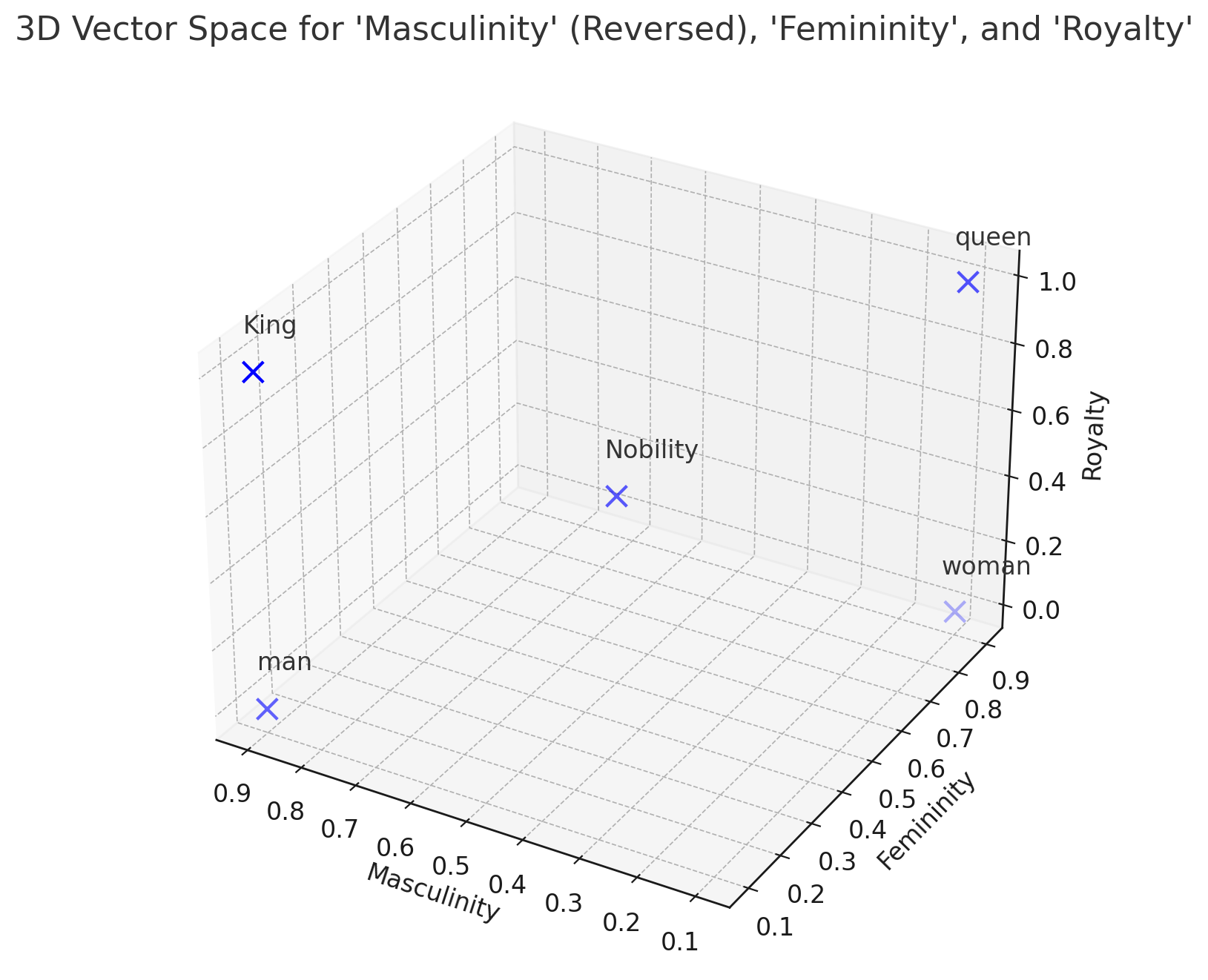
- What is man + (queen - woman) = ?
- man + (queen - woman) =[0.9 0.1 1.0]= king
- Word 2 Vec 에서의 결과도 king에서 두번째로 높은 유사도를 보임
- 단어끼리 연산이 가능하다는 장점이 있음


잘 먹고 잘 살자