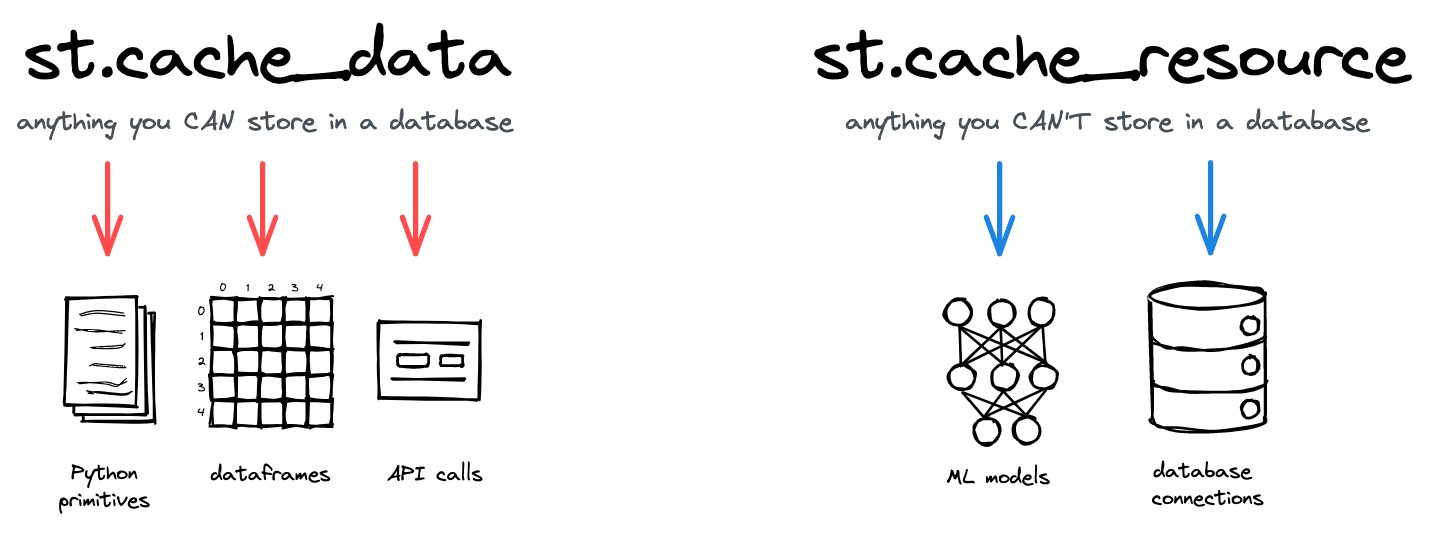
1. st.cache_data vs st.cache_resource
st.cache_data
- 주로 데이터(ex. DataFrame, NumPy array, API query 등)를 캐싱하는데 사용
- 주기적으로 변경되거나 업데이트 될 수 있는 데이터(ex. 웹 API에서 가져오는 정보)를 캐싱할 때 유용
- 입력 인자와 반환값을 기반으로 데이터를 캐싱
- 데이터가 업데이트 되면 자동으로 캐시가 무효화되어 새로운 데이터를 가져옴
- 특정 입력이 주어졌을 때 동일한 반환값을 재사용 가능(decorator)
- 거의 대부분
st.cache_data를 사용
st.cache_resource
- 주로 리소스 또는 외부 연결(ex. database 연결, API client 세션 등)을 캐싱하는데 사용
- 리소스 초기화에 비용이 많이 드는 작업(ex. database 연결)을 설정하는 경우, 매번 연결을 새로 하는 대신 동일한 연결을 재사용할 때 유용
- 변경 가능성이 낮고 초기화에 시간이 많이 소요되는 리소스에 적합
- 데이터 자체보다는 데이터와 연결된 리소스를 효율적으로 재사용
2. 크롤링 (Crawling)
정적 크롤링 (Static Crawling)
-
서버가 처음부터 고정된 상태로 제공하는 정적인 콘텐츠를 가져오는 방식
-
주로 HTML 페이지에 미리 로드된 텍스트나 이미지 등이 크롤링 대상
-
특징
- 서버에서 이미 완성된 HTML 파일을 받아오기 때문에 javascript 처리 없이 빠르게 크롤링 가능
- 파일들을 단순히 다운로드 하는 방식이므로 구현이 비교적 쉬움
-requests,BeautifulSoup라이브러리 등으로 정적인 데이터를 쉽게 추출 가능 -
장점
- 빠른 속도, 적은 자원 소모
- javascript 렌더링이 필요하지 않아 구현이 간단
- 추가적인 서버 요청이나 리소스 로딩 없이 HTML의 구조에만 의존해 간단하게 접근 가능 -
단점
- javascript로 동적으로 생성된 콘텐츠는 가져올 수 없음
- HTML 구조가 변경되면 데이터를 올바르게 가져오지 못함
동적 크롤링 (Dynamic Crawling)
-
javascript로 동적으로 생성된 콘텐츠를 포함해 웹페이지의 모든 내용을 가져와 데이터를 추출하는 방식
-
Selenium,Playwright와 같은 브라우저 자동화 도구를 통해 작업 -
특징
- javascript를 실행하여 사용자에게 보여지는 최종 결과를 가져옴
- 사용자 인터랙션을 자동화할 수 있어 모든 콘텐츠를 쉽게 추출 가능 -
장점
- javascript로 로드되는 모든 컨텐츠를 가져오는 것이 가능
- 사용자와 동일한 환경에서 웹페이지를 렌더링하기 때문에 크롤링의 완성도가 높음
- 웹페이지와 상호작용이 필요한 콘텐츠에도 접근 가능 -
단점
- 브라우저를 실행하기 때문에 속도가 느리고 자원 소모가 큼
- 설정이 복잡하고 코드 작성이 정적 크롤링보다 난이도 높음
- 계속적으로 서버 요청을 보내기 때문에 IP 차단 위험이 높아질 수 있음
3. 크롤링 실습
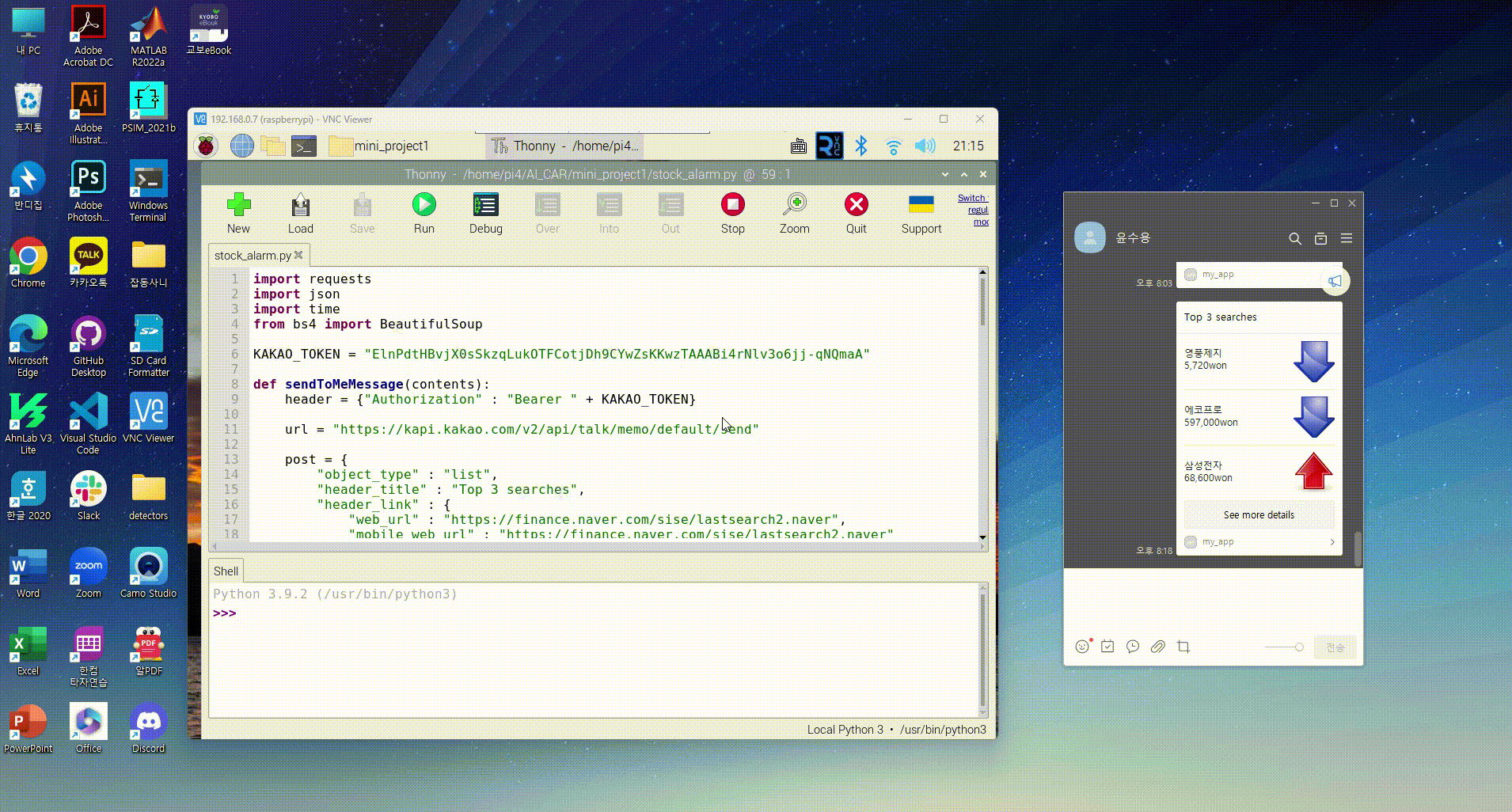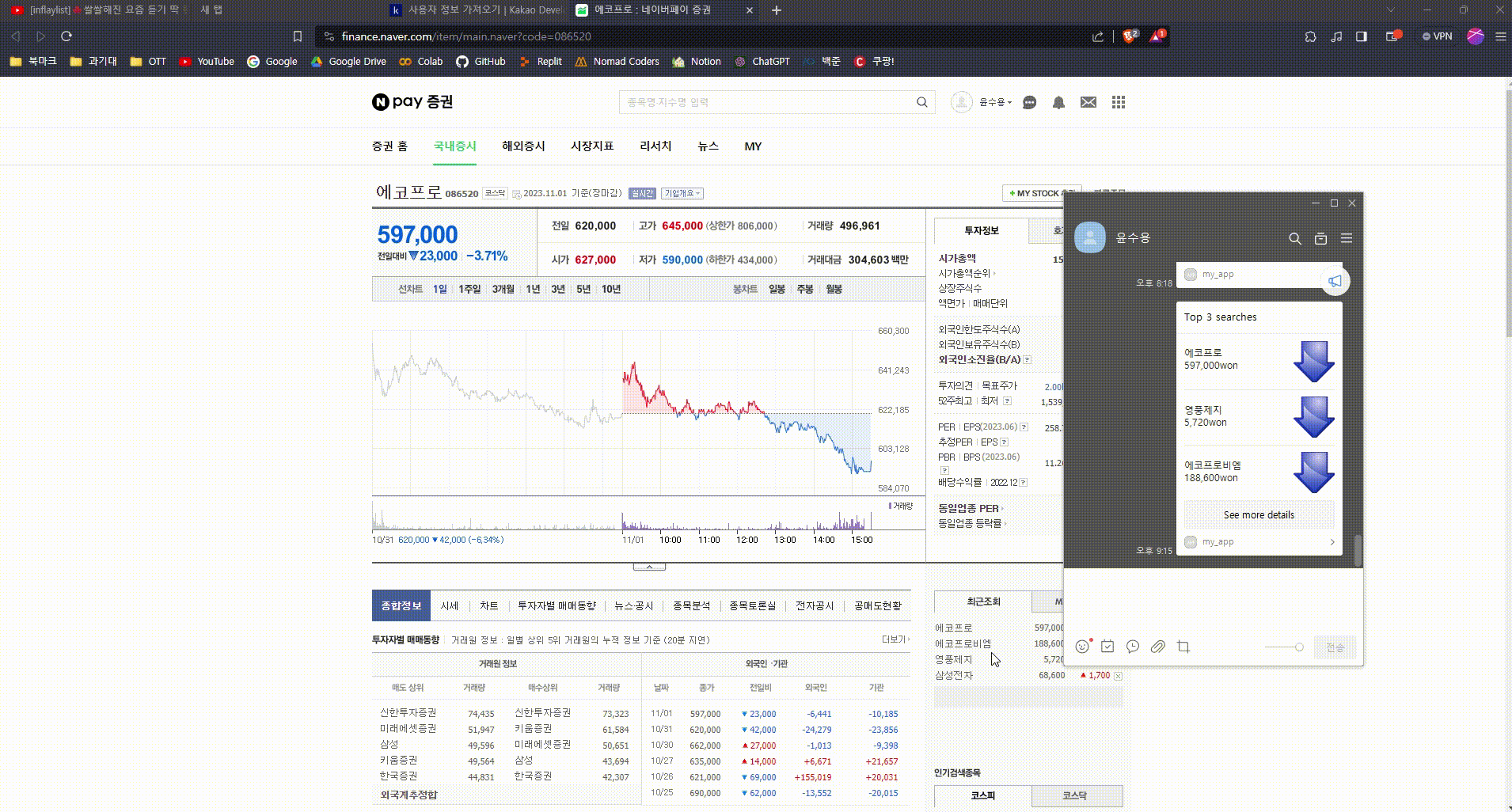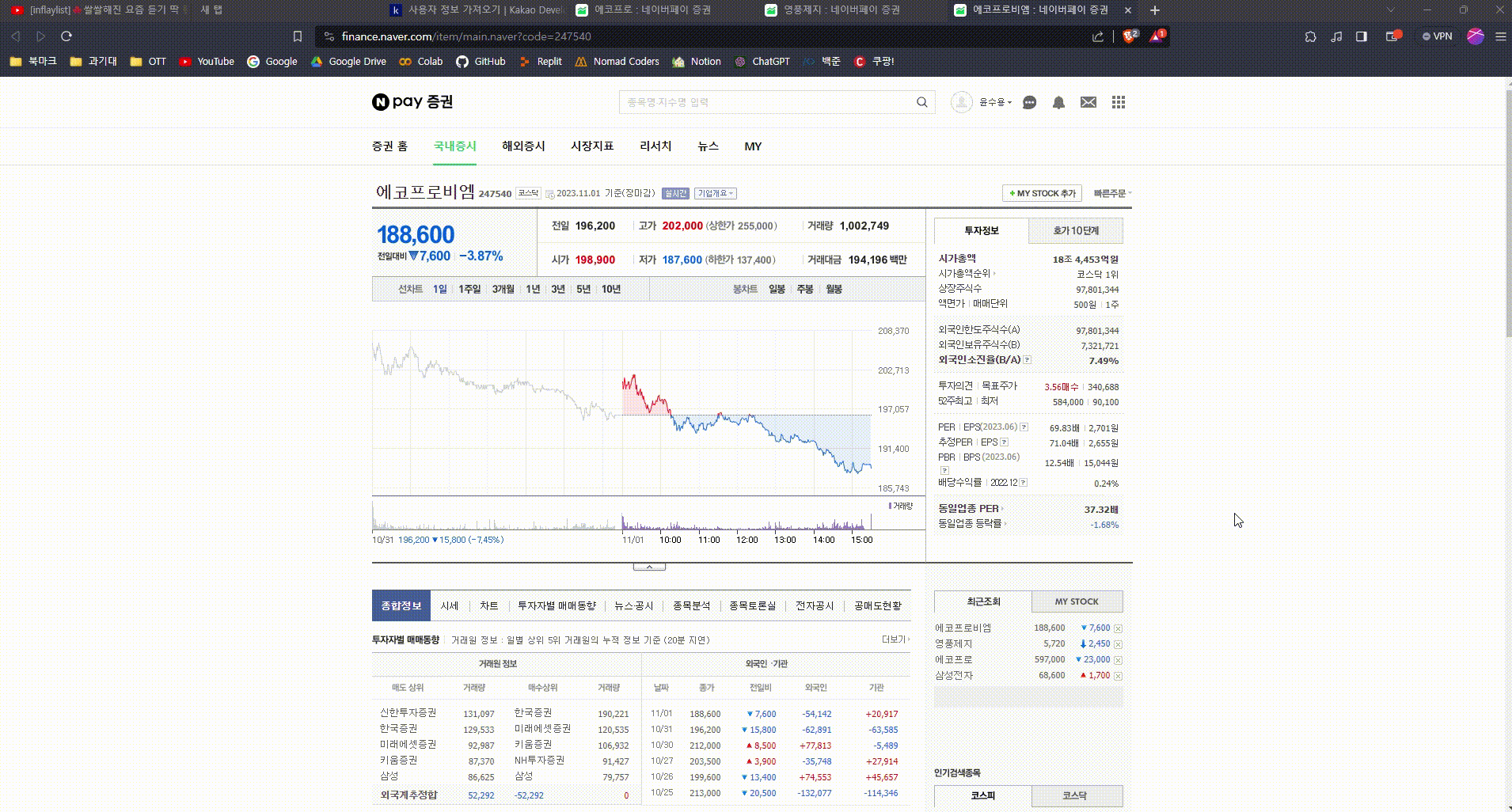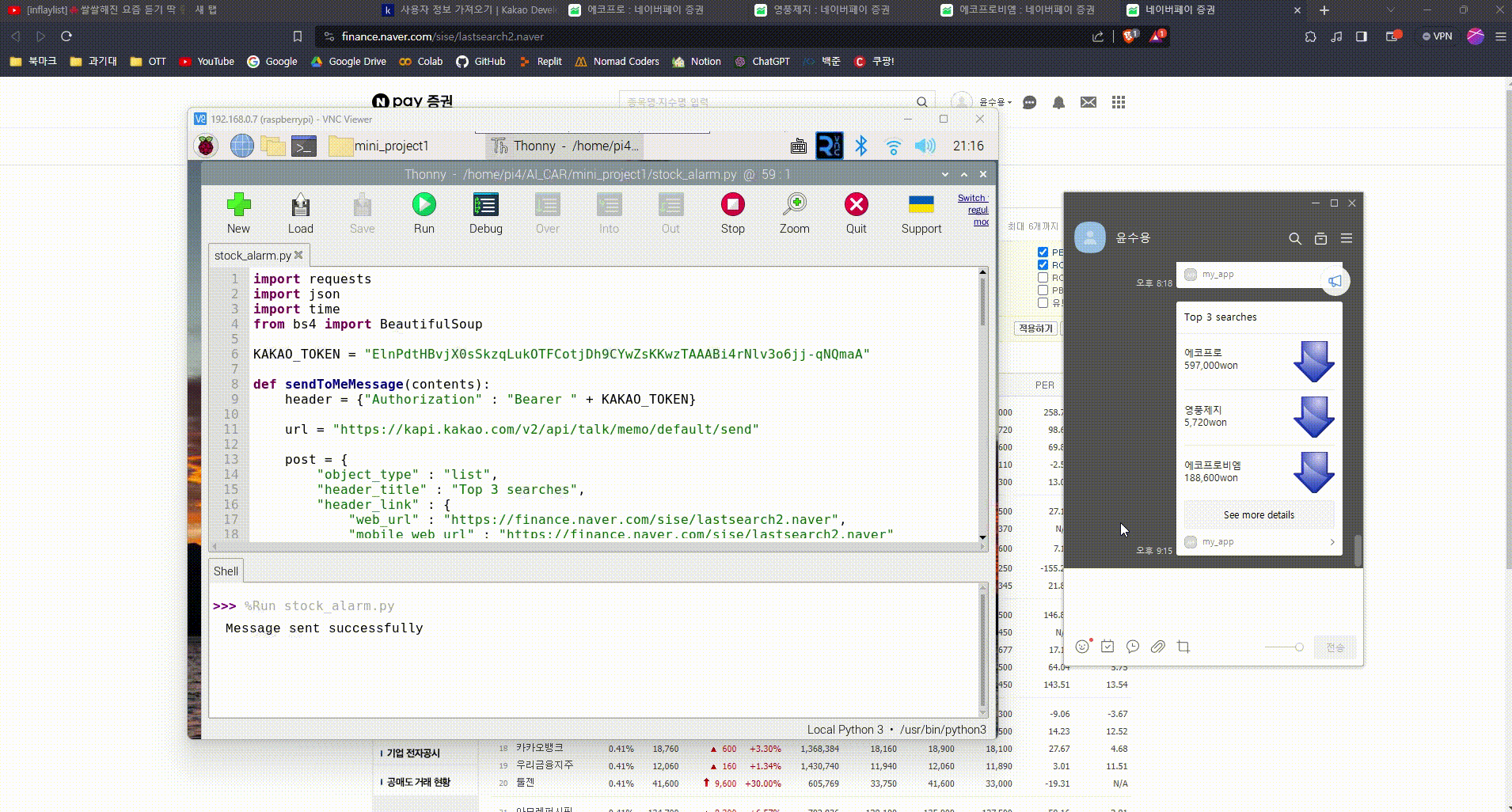
정적 크롤링을 활용한 카카오톡 주식 알리미
목표
- 네이버 증권 에서 검색 비율이 높은 세 종목을 높은 순서대로 알려주기
- 정적 크롤링을 이용하여 종목 이름, 현재가, 등락 정보 추출
- 추출한 정보를 카카오톡 '나에게 보내기' 메시지로 전송
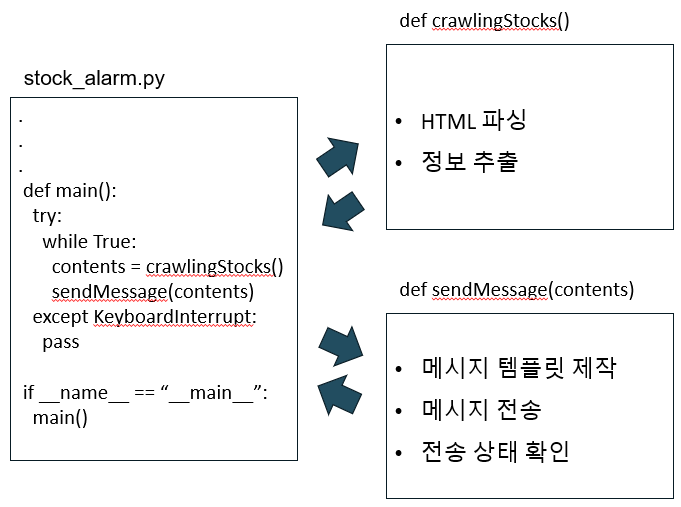
프로젝트 구조도
크롤링
-
인기 검색 종목들이 나타난 표 검색
-
표에서 검색 비율이 가장 높은 세 종목의 종목명, 현재 가격격, 전일비 검색
-
top3_items 리스트에 저장
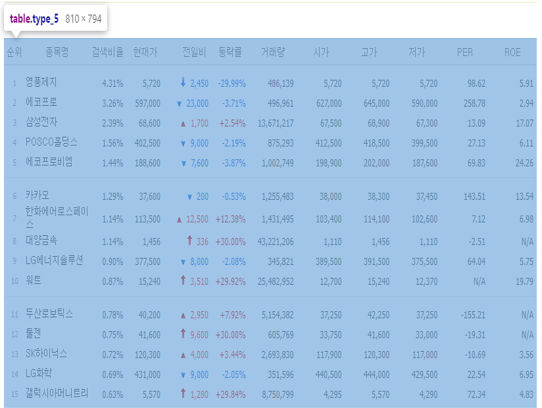
-
네이버 증권 TOP 종목 차트
-
HTML tag가 class="type_5"를 갖는 table임을 확인

- 각 종목에 대한 정보가 tr tag로 묶여있는 것을 확인
- 종목명을 나타내는 class="title"
- 전일비를 나타내는 span tag와 등락을 알 수 있는 class="nv01" (or class="red")
- 현재가는 class="number"들 중 두 번째에 위치함
def crawlingStocks():
url = "https://finance.naver.com/sise/lastsearch2.naver"
result = requests.get(url, headers={'User-agent': 'Mozilla/5.0'})
bs_obj = BeautifulSoup(result.content, "html.parser")
stocks = bs_obj.find("table", {"class" : "type_5"}) # TOP 종목 테이블
# 화살표 이미지 url
blue_arr = "https://cdn.pixabay.com/photo/2012/04/13/00/17/arrow-31192_1280.png"
red_arr = "https://cdn.pixabay.com/photo/2013/07/12/14/06/arrow-147743_1280.png"
dash = "https://cdn.pixabay.com/photo/2012/04/13/00/14/bar-31174_1280.png"
# 상위 20개 종목 긁어오기
stocks = stocks.find_all("tr")[:20]
top3_items = []
# 상위 3개 종목 리스트 생성
for i in range(len(stocks)):
anchor = stocks[i].find("a")
if anchor == None:
continue
else:
# 종목명, 현재가, 화살표를 찾아 템플릿에 맞게 가공
price = stocks[i].find_all("td", {"class" : "number"})[1]
arrow = stocks[i].find("span").get("class")[-1]
if "nv" in arrow:
arrow = blue_arr # 하락하면 파란 화살표
elif "red" in arrow:
arrow = red_arr # 상승하면 빨간 화살표
else:
arrow = dash # 변화 없으면 -
item = {
"title" : anchor.text + "\n" + price.text + "won",
"description" : "",
"image_url" : arrow,
"image_width" : 200,
"image_height" : 200,
# 종목을 클릭하면 해당 종목의 네이버 증권 페이지로 이동
"link": {
"web_url" : "https://finance.naver.com" + anchor.get("href"),
"mobile_web_url" : "https://finance.naver.com" + anchor.get("href")
}
}
top3_items.append(item)
if len(top3_items) >= 3:
break
return top3_items메시지 전송
- 카카오톡의 메시지 템플릿인 리스트 템플릿을 활용
- 리스트의 칸에 각 종목명, 현재 가격, 전일비를 표시
- 전일비는 화살표 이미지를 통해 보다 직관적이게 표현
- 각 칸을 클릭하면 해당 종목에 대한 네이버 증권 화면으로 이동
- See more details를 클릭하면 네이버 증권 홈으로 이동
def sendToMeMessage(contents):
⁝
url = "https://kapi.kakao.com/v2/api/talk/memo/default/send"
post = {
"object_type" : "list",
"header_title" : "Top 3 searches",
"header_link" : {
"web_url" : "https://finance.naver.com/sise/lastsearch2.naver",
"mobile_web_url" : "https://finance.naver.com/sise/lastsearch2.naver"
},
"contents" : contents, # 작성한 종목 정보들
"button_title" : "See more details"
}
data = {"template_object" : json.dumps(post)}
response = requests.post(url, headers=header, data=data)
⁝

메인 함수
- 1분마다 인기 종목 메시지를 불러오도록 설정
def main():
try:
while True:
contents = crawlingStocks()
sendToMeMessage(contents)
time.sleep(60) # 1min
except KeyboardInterrupt:
pass완성 영상