PS
1.problem-1427

과정 리스트로 input string을 변환 리스트를 내림차순으로 정렬 join을 이용해서 리스트를 문자열로 변환 후 출력 print(''.join(sorted(list(input()),reverse=True)))
2.problem-2587
과정1\. 리스트로 받고2\. sum과 sorted를 이용해서 출력time: 1분
3.problem-25305
과정1\. n,k를 받고2\. map(int,input().split()을 list를 통해 리스트로 만든 후 sorted3\. 커트라인 출력time: 3분
4.problem-24060
과정1\. 문제의 merge_sort 및 merge 함수 구현2\. global cnt를 통해서 cnt==k일 경우 해당 값을 ans에 대입3\. ans값을 -1로 초기화하여 2번이 안 일어날 경우 그대로 출력time: 25분
5.problem-11729
an = n번째까지의 원판을 옮길 때, 필요한 횟수a n+1 = n번째까지의 원판을 다른 봉에 옮기기 + n+1번째 원판을 목표 봉에 옮기기 + n번째까지의 원판을 목표봉으로 옮기기a n+1 = an + 1 + antime: 50분
6.problem-2447
과정1\. 위, 중간, 아래 세 부분으로 나눠서 생각2\. 윗 부분은 그 전 star 33\. 중간 부분은 그 전 star + ' ' num//3 + star4\. 아래 부분은 그 전 star \* 35\. 합쳐서 returntime: 40분resolve requir
7.problem-14425
과정1\. a를 리스트로 받고 b를 defaultdict로 만들어서 받을때마다 개수를 1씩 올림2\. i가 a에 있으면, bi를 답에 더함3\. 총 합을 출력잘못된 풀이set을 이용해서 len(a)+len(b)-len(set(a+b))로 했지만, b의 경우 중복된 문자
8.problem-1269
과정1\. 두 리스트의 합을 set을 통해 중복을 없앤 다음 길이를 구하고2\. 이 길이에서 중복된 값의 개수를 빼줌으로써 모든 중복된 원소 제거time:5분
9.problem-11478
과정1\. 0부터 1씩 늘려가면서 문자열 추가2\. set을 통해서 겹치는 문자열 제거time:20분
10.problem-15649
과정1\. itertool에 permutations를 이용해서 출력2\. 자동으로 오름차순으로 정렬됨time:5분
11.problem-15651
과정1\. n과 m(2)에서 중복된 값을 제외하는 조건을 해제함time: 5분
12.problem-15652
과정1\. a의 마지막 원소보다 해당 값이 작으면 무시하는 조건 추가time: 5분
13.problem-2580
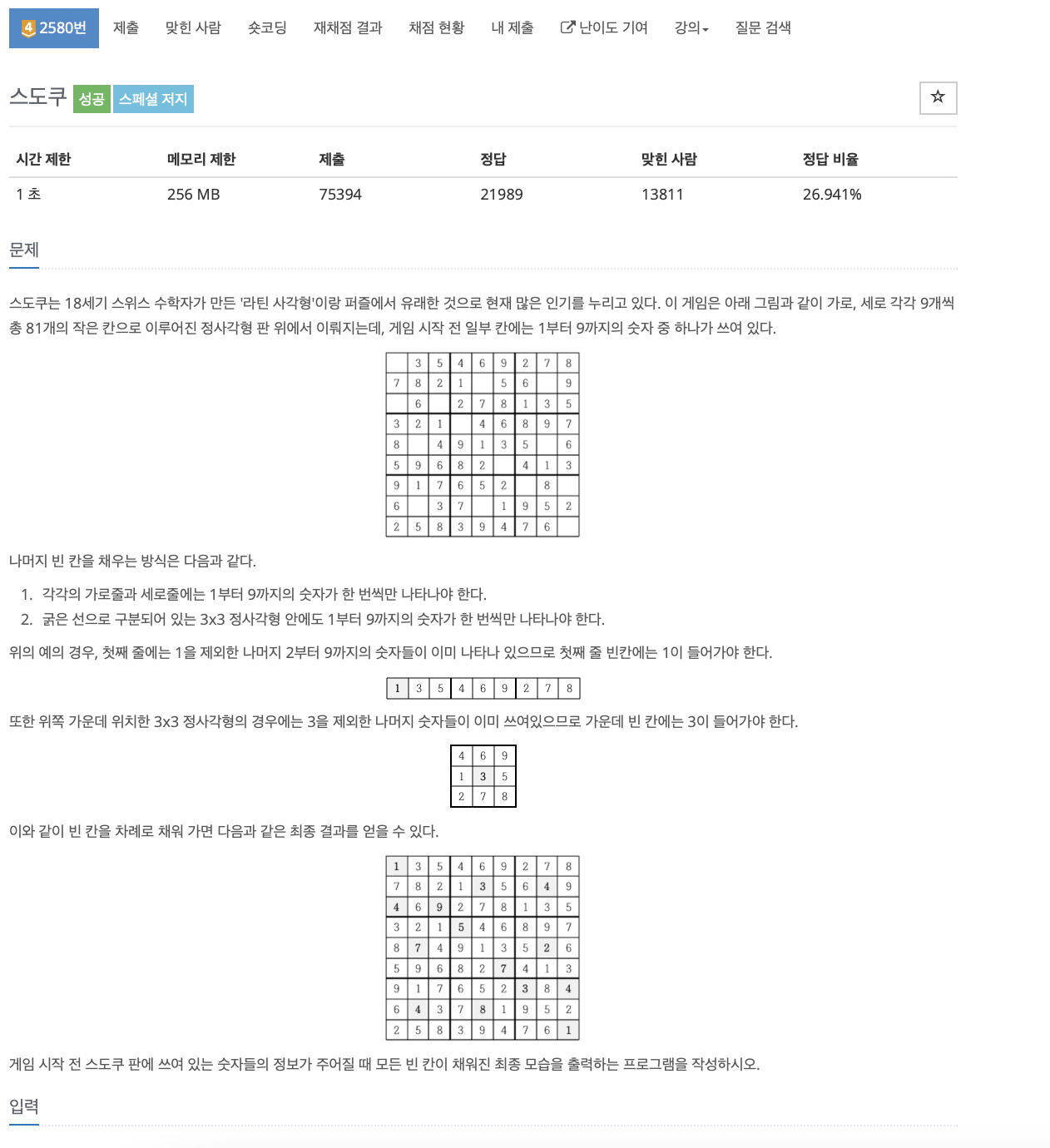
과정board를 저장하고 빈 공간 (숫자가 0)의 좌표를 need에 저장check_xy를 통해 여기에 num이 들어가도 괜찮은지 확인check_finish()를 통해 모든 board가 0 없이 채워졌는지 확인global found 를 통해 해답이 찾아졌는지 확인 ->
14.problem-24416

과정1\. 각 함수 의사코드 구현2\. 파이썬 시간초과로 인해 pypy3로 제출time:10분
15.problem-9184
과정1\. defaultdict를 이용해서 값을 저장2\. w함수에서 dic 값이 있으면 그걸 사용, 없으면 w함수를 통해 계산time:50분
16.problem-2565
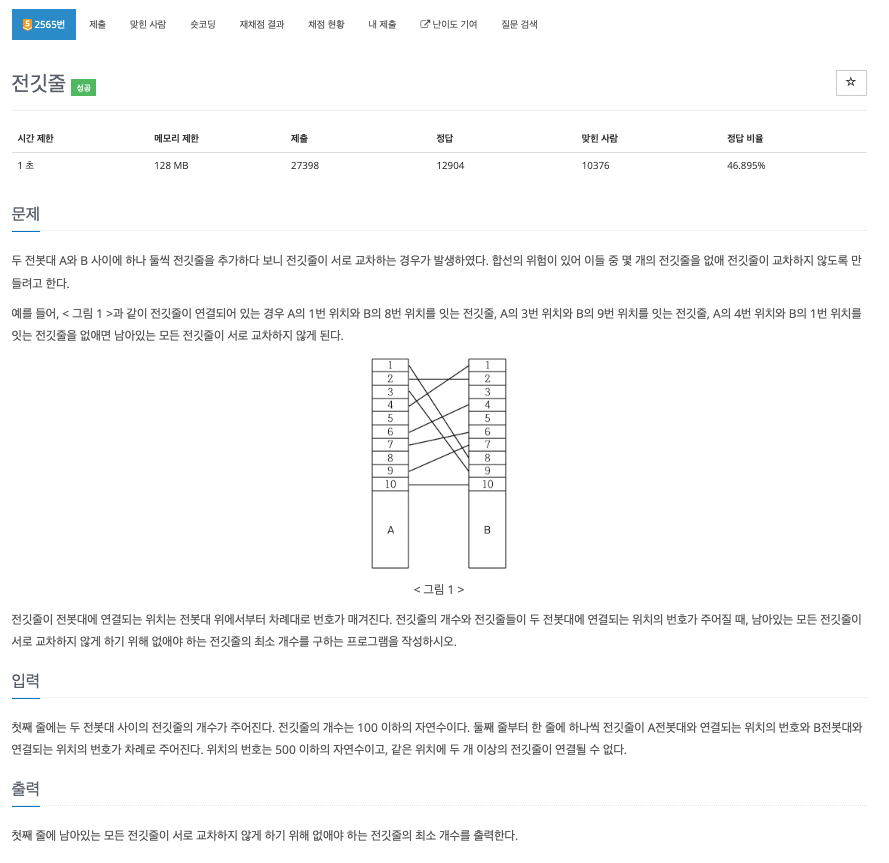
과정1\. input을 튜플로 받은 후, 정렬2\. 전선이 꼬이지 않기 위해서는 튜플1의 항목들이 모두 오름차순으로 정렬되어야함 -> 가장 긴 부분수열 찾기3\. dn은 n이 마지막(가장 큰) 수 일때 최대 길이의 부분수열4\. di=max(di,dj+1) -> j가
17.problem-9251

과정1\. dp2차원 배열 생성2\. 행 -> input a, 열 -> input b 3\. ai==bj이면, dpi = 그 전까지의 수열인 dpi-1+14\. ai!=bj이면, dpi = max(dpi-1,dpi)time: 80분resolved:x
18.problem-11054
과정1\. 오름차순 -> 내림차순 순서이기 때문에, dp를 오름차순용과 내림차순용으로 두개 만듬2\. 오름차순의 경우, 최장부분수열의 길이 dp 구하면 된다.3\. 내림차순의 경우, 오름차순의 마지막 값부터 수열의 마지막 값까지 안에서 최장내림차순부분수열의 길이를 구해
19.problem-2559
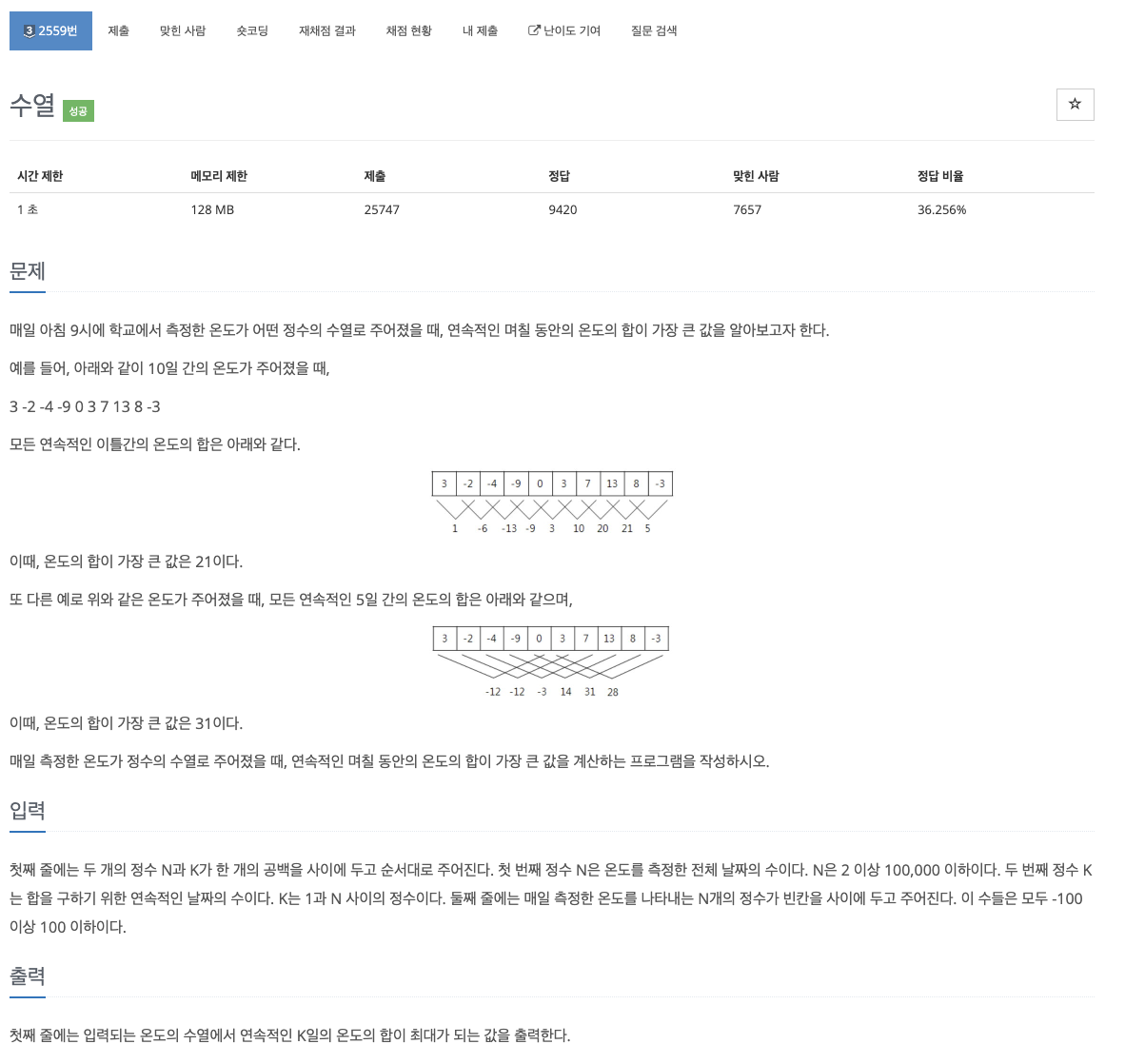
과정1\. O(n)으로 해결하기 위해 시간을 단축시킬 수 있는 방법은, for문 한번을 써야한다.2\. 합 s 를 설정한다.3\. for문 안에서 초기 s를 0부터 k-1까지만큼 더한 값을 넣는다.4\. 그 이후에는 s에서 i-1번째 (그 다음 시작 인덱스의 이전 인덱
20.problem-11660

과정 dp 2차원 테이블을 만든다. dpa에서 a는 board의 행, b는 board의 열, 그리고 dpa의 값은 boarda~boarda까지의 합이다. dp 값을 할당한 후, a,b,c,d 인풋을 받을 때마다 a부터 c까지 ans+=dp-dp을 통해 b부터 d까지의
21.problem-13305
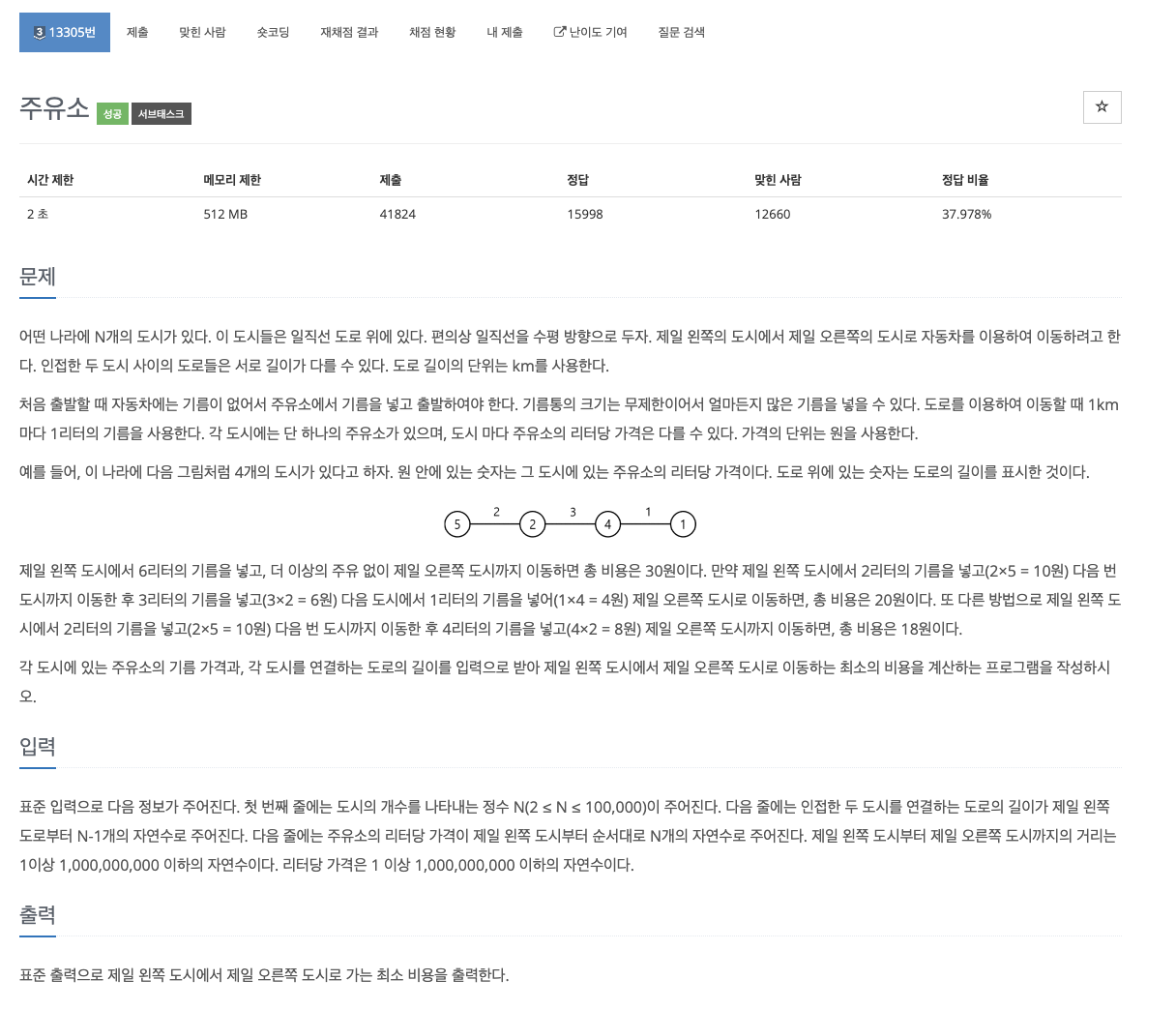
과정1\. disti : 해당 도시에서 다음 도시까지의 거리 cityi : 해당 도시에서의 기름 가격 cost : 최소한의 기름 가격 liter : 총 기름 가격의 합2\. cost = min(cost,cityi)로 설정하고 liter+=cost\*distitime:
22.problem-18258
과정1\. deque를 이용하여 que 설정time: 10분
23.problem-15828
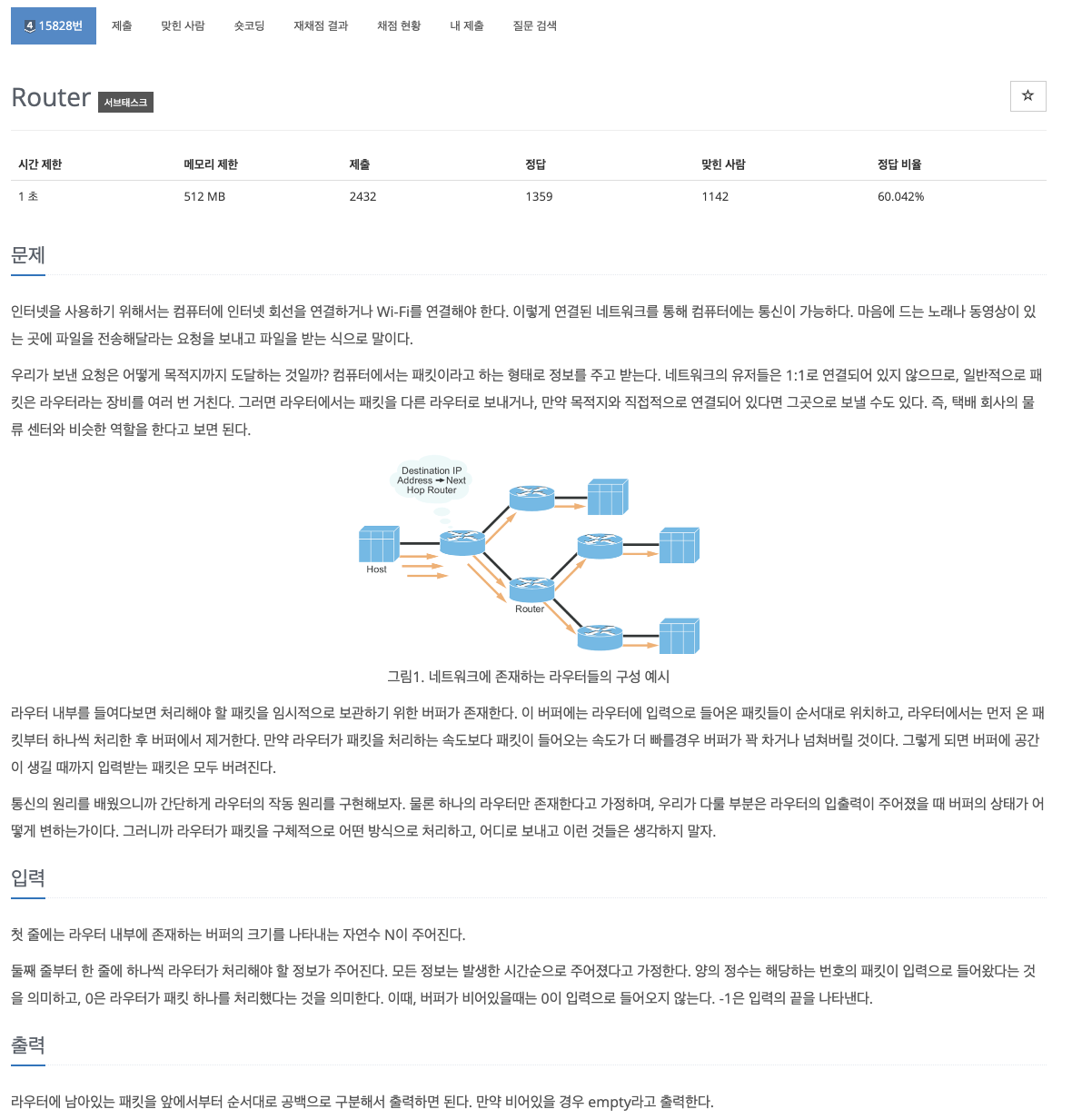
과정1\. deque를 통해 큐 설정2\. len(que)가 n보다 작을 때만 que에 추가time:15분
24.problem-2740
과정temp1 에 b행렬의 열들을 행으로 변환시켜 저장곱하기분할 정복으로 풀 수도 있지만, 이렇게 푸는것도 문제 없다.time:60분행렬 곱 구현에 오래걸렸다.
25.problem-1655
과정1\. q1, q2 두 개의 리스트를 생성 -> q1과 q2는 오름차순으로 정렬되어있고, max(q1)<=min(q2)2\. heapq를 이용하여 q1의 최댓값과 q2의 최솟값을 알아냄3\. q1의 마지막 원소를 중앙값으로 둠 -> len(q1)>=len(q2
26.problem-2293
과정1\. dpi = i를 만들 수 있는 경우의 수2\. for i in range(len(coin)) -> 각 코인에 대하여3\. for j in range(coini,k+1) -> 그 코인부터 k까지 (코인보다 작은 값은 만들지 못하기때문)4\. dpj+=dp\[j
27.problem-12015
과정처음에 dp를 이용해서 풀었을 때 시간초과로 안됨\-> 이분탐색 이용1\. i부터 n까지 for문 안에서2\. 만약 ai값이 result의 마지막값(제일큰값)보다 크면 그대로 result에 추가3\. 작으면 bisect모듈을 이용하여 들어갈만한 곳에 있는 값과 대치
28.problem-1300
과정1\. 숫자 num에 대하여, ai=i\*j로 이루어진 행렬에서 num보다 작거나 같은 수의 개수는 sum(min(num//i,n))2\. 이걸 통해 해당 num보다 작거나 같은 수의 개수를 찾음3\. 개수가 k보다 크거나 같으면 저장하고 end=mid-1 ||
29.problem-17298
과정1\. stack을 이용해서 i값이 stack-1값보다 작으면 그대로 스택에 추가2\. stack-1값보다 크면 스택안에 있는 값들을 비교하여 작은 것들은 모두 i 값을 오큰수로 설정3\. index 설정을 위해 리스트를 index,value 튜플로 받음4\. 마지
30.problem-17299
과정1\. 이전 오큰수 문제와는 다르게 stack에 index만 넣어서 메모리 낭비를 줄임2\. defaultdict를 이용하여 해당 값이 얼마나 등장하였는지 저장3\. 비교time:25분
31.problem-24479
과정1\. dfs문제2\. 양방향이기 때문에 edge를 추가할 때, edgeu=v 와 edgev=u3\. global cnt와 defaultdict를 이용해서 값을 저장time:40분
32.problem-24480
과정1\. dfs이용2\. 내림차순으로 해야하기 때문에 sort(reverse=True)이용time:20분
33.problem-24444
과정1\. bfs이용2\. defaultdict를 이용해서 값 저장time:15분
34.problem-24445
과정1.bfs2.sort(reverse=True)time:5분
35.problem-1026
과정1\. a를 오름차순으로 정렬2\. b를 내림차순으로 정렬3\. 곱해서 결과값에 더하기\-> 이 방법은 문제에서 금지하고 있긴 하다. 다른 방법으로는 a는 오름차순정렬, b에서는 최댓값의 인덱스를 찾아서 곱하고 그 최댓값을 b에서 제거하는 방식으로 하면 되지만 매우
36.problem-2217
과정1\. input 리스트 a를 오름차순으로 정렬2\. a를 순차적으로 탐색하며 최댓값을 구함3\. ai의 경우 ai\*n-i의 값이 최댓값이 됨. i보다 뒤에 있는 값들은 모두 ai만큼 들어올릴 수 있기 때문임import sysinput=sys.stdin.readl
37.problem-1946
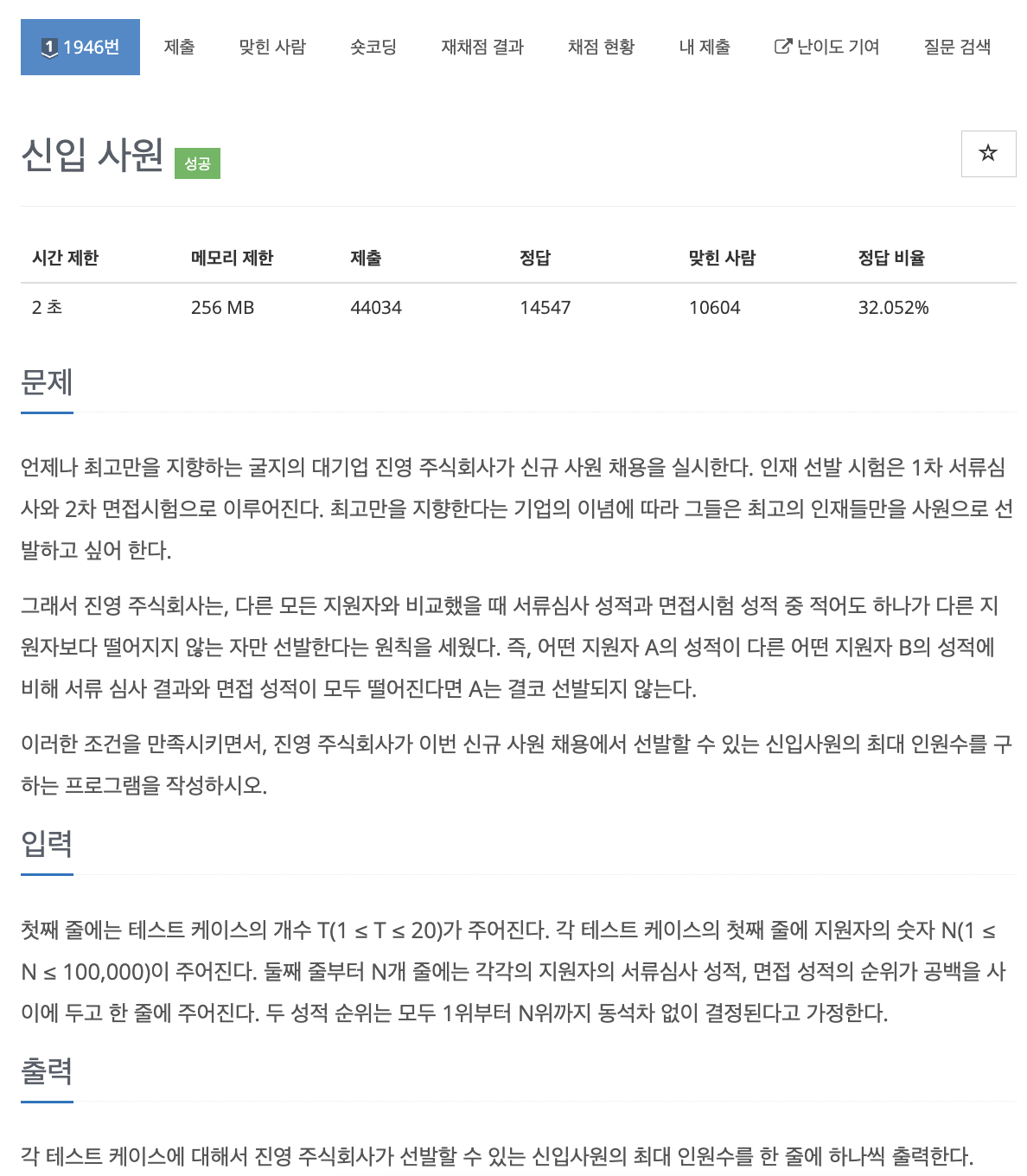
과정1\. score에 등수를 튜플로 담고 서류 순서대로 오름차순 정렬2\. 이제 면접 등수를 기준으로 ans+=1 3\. 이미 서류 순서대로 정렬되어있기 때문에 면접 등수가 기준보다 낮으면 앞설 수 있는 가능성이 없기 때문time:30분
38.problem-1789
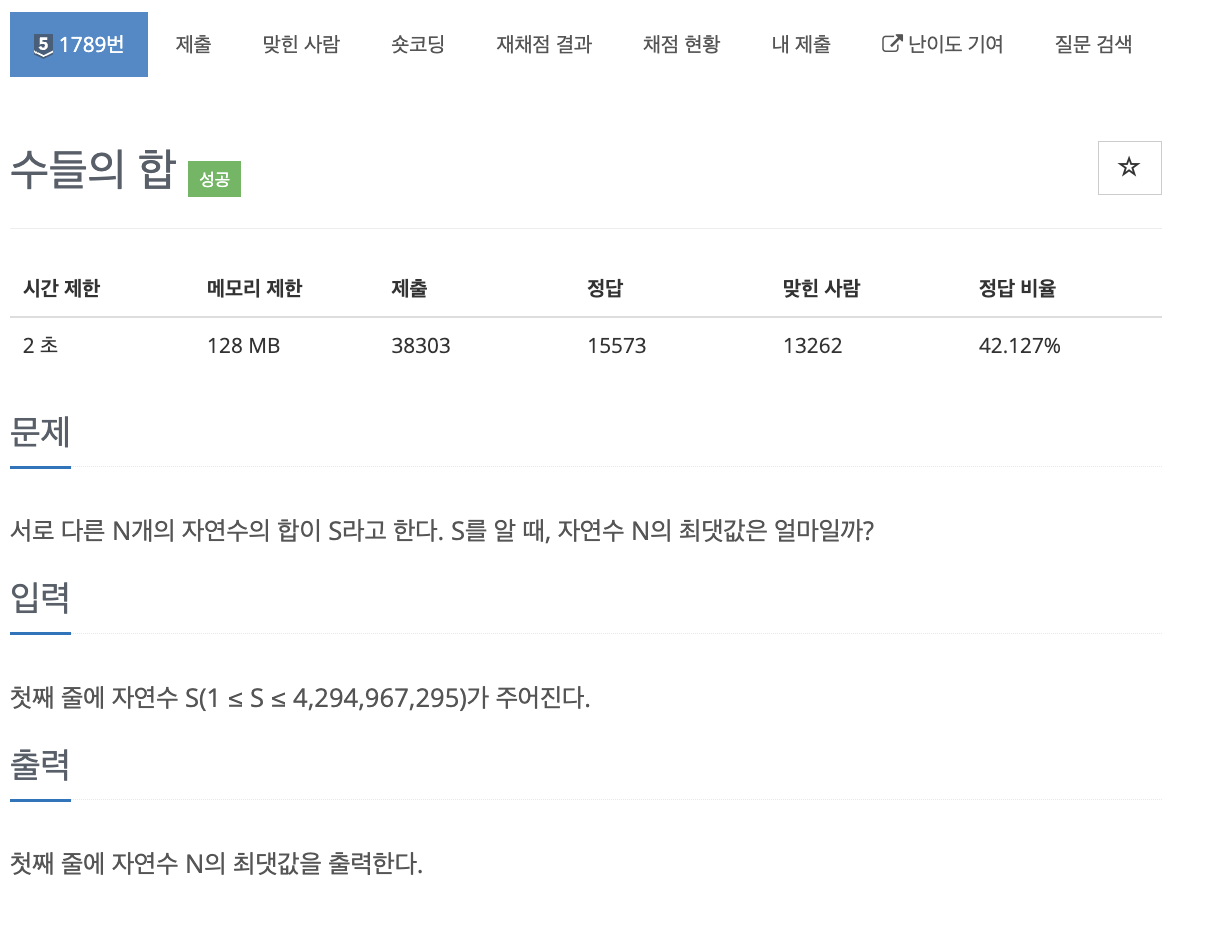
과정1\. 1부터 i 까지의 합이 s보다 커질 때 i-1이 n의 최솟값이다.2\. s보다 커지면 1부터 i까지 중에서 커진만큼의 숫자를 하나 빼면 되기 때문이다.time:5분
39.problem-10610
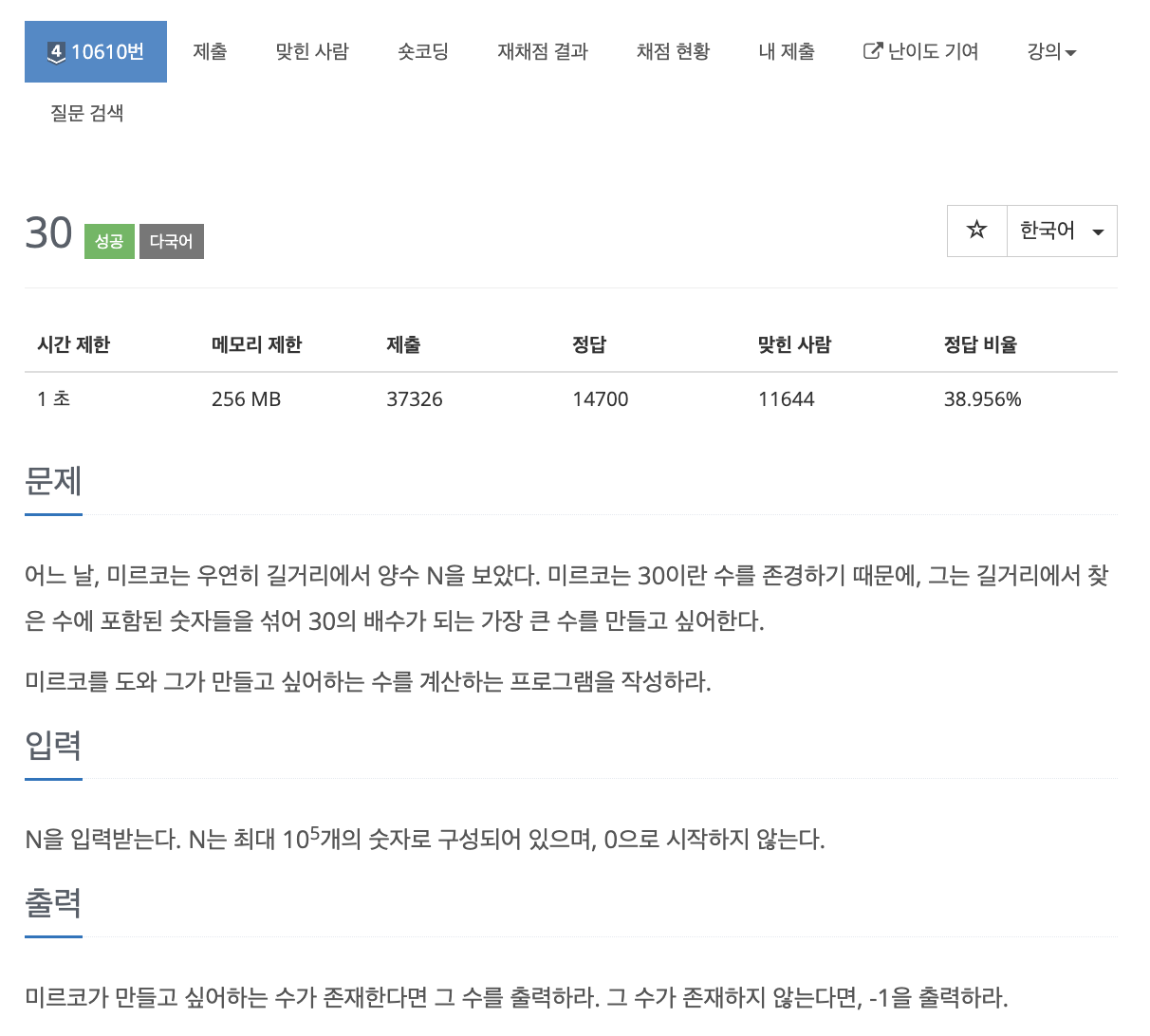
과정1\. 내림차순으로 정렬2\. 30의 배수 조건: 10의 배수이면서 3의 배수2-1. 10의 배수: 끝자리가 0이어야함.2-2. 3의 배수: 수에 포함된 숫자들의 총 합이 3의 배수여야함.time:15분
40.problem-14501
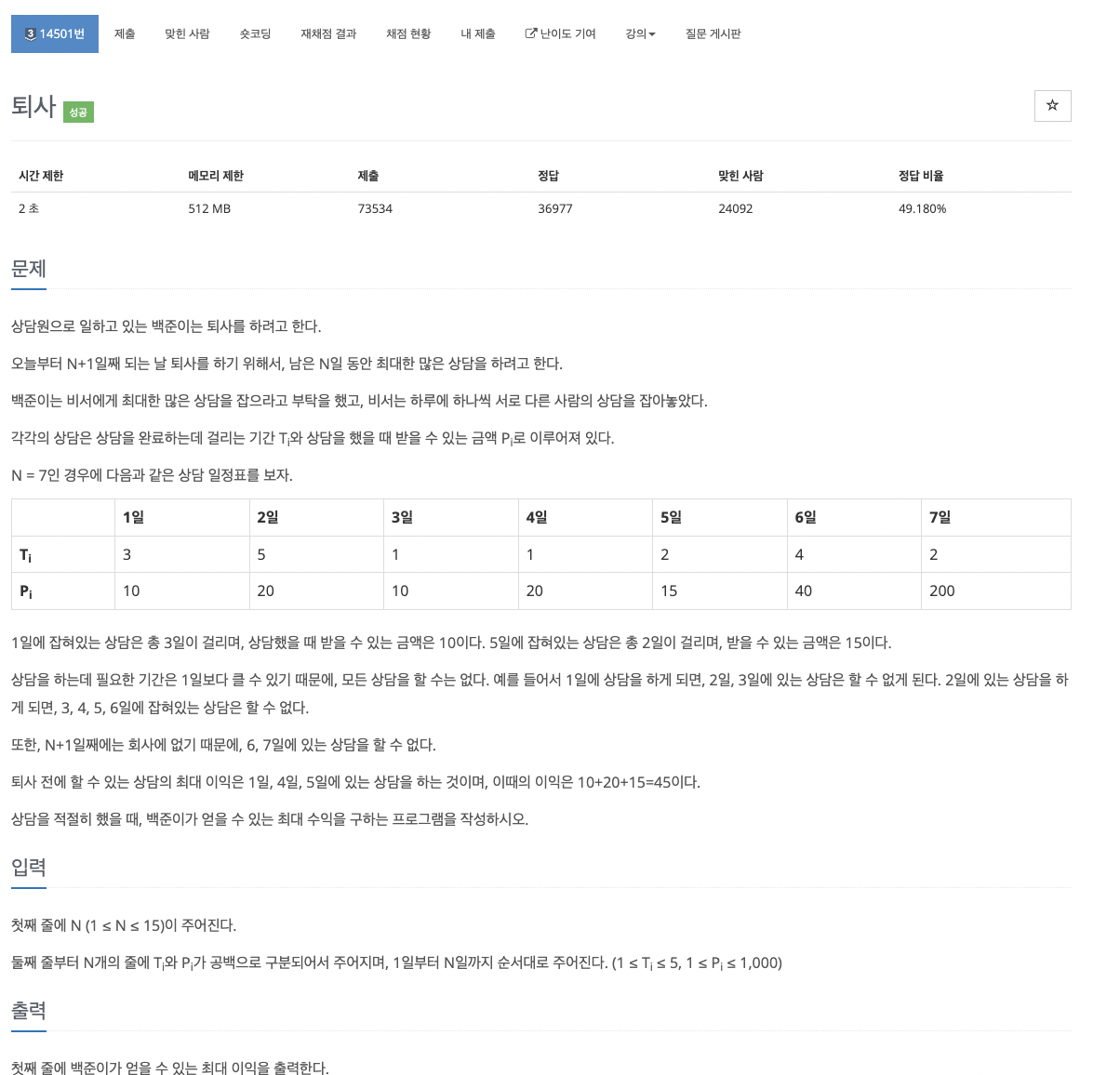
과정1\. dp를 마지막날부터 역순으로 찾아감2가지 경우의 수1\. i번째 날에 상담을 하게되면 n일안에 끝내지 못할 경우 \-> 상담불가능 dpi=dpi+12\. i번째 날에 상담이 가능한 경우 \-> dpi=max(dpi+1,dpi+t+p). \*\*여기서 t는
41.problem-9655
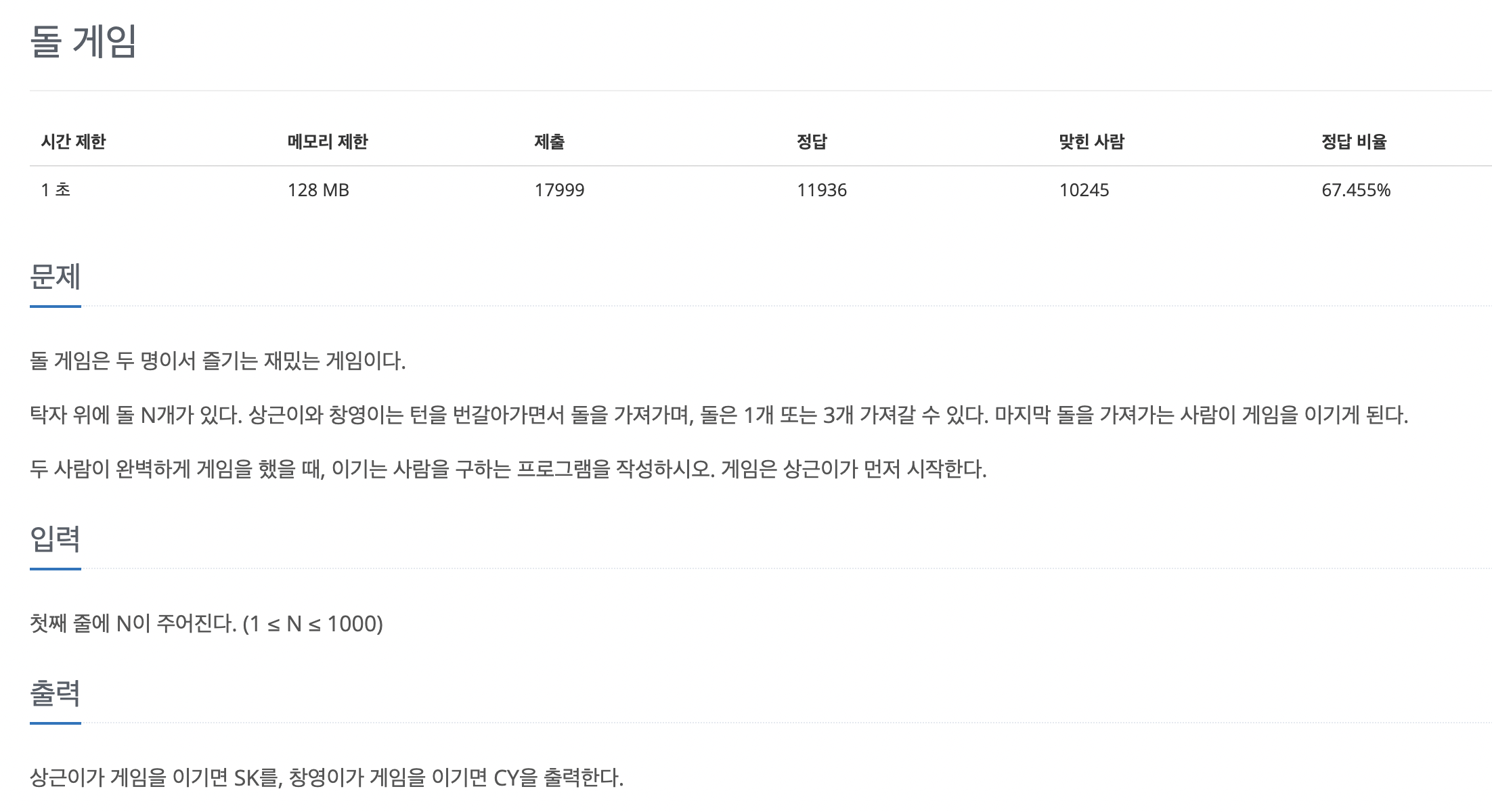
과정1\. 완벽하게 게임하기 때문에 dpn은 최소여야함2\. dpi = min(dpi-1+1,dpi-3+1)3\. 홀수일때는 SK, 짝수일때는 CYtime:40분
42.problem-6550
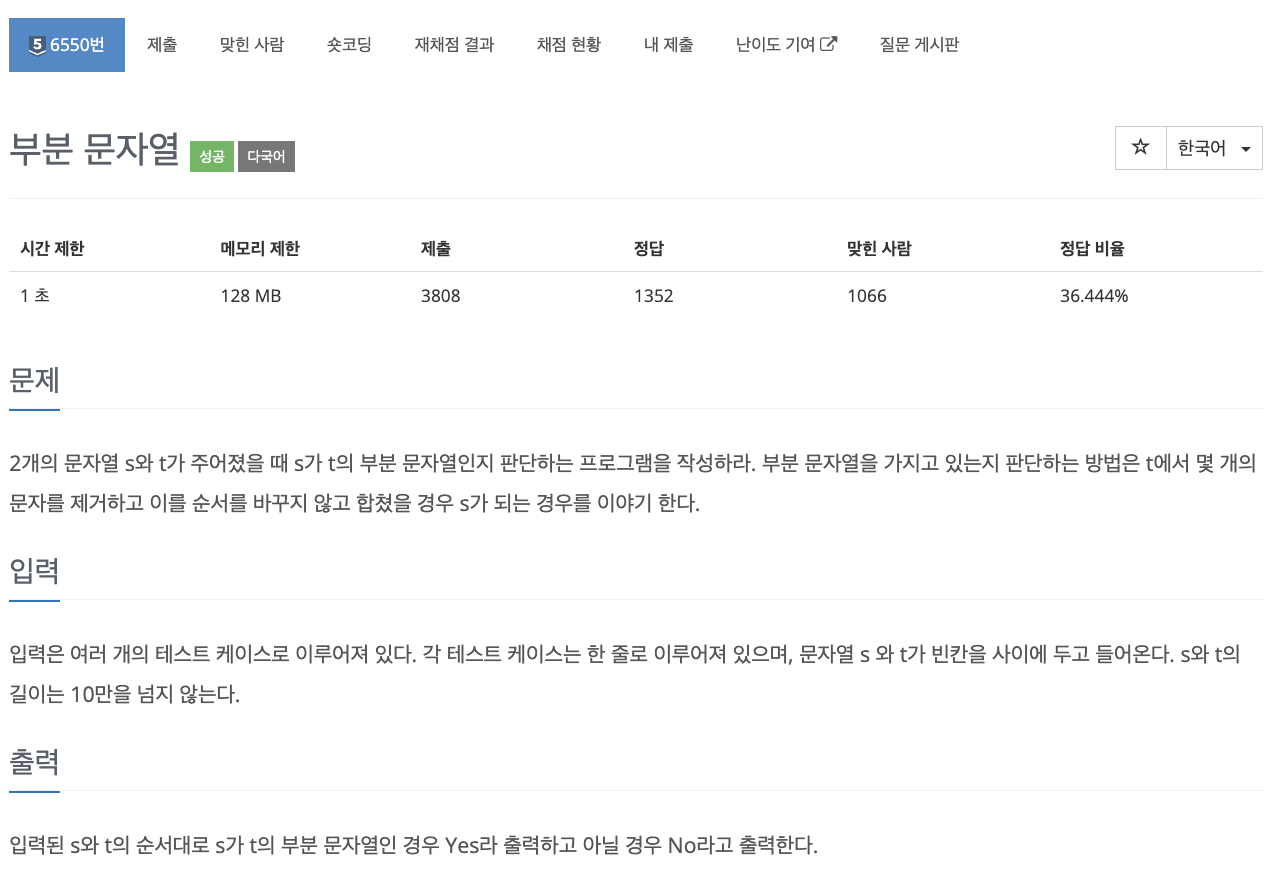
기억해야할 것문자 -> 아스키코드 : ord()아스키코드 -> 문자 : chr()
43.problem-2295
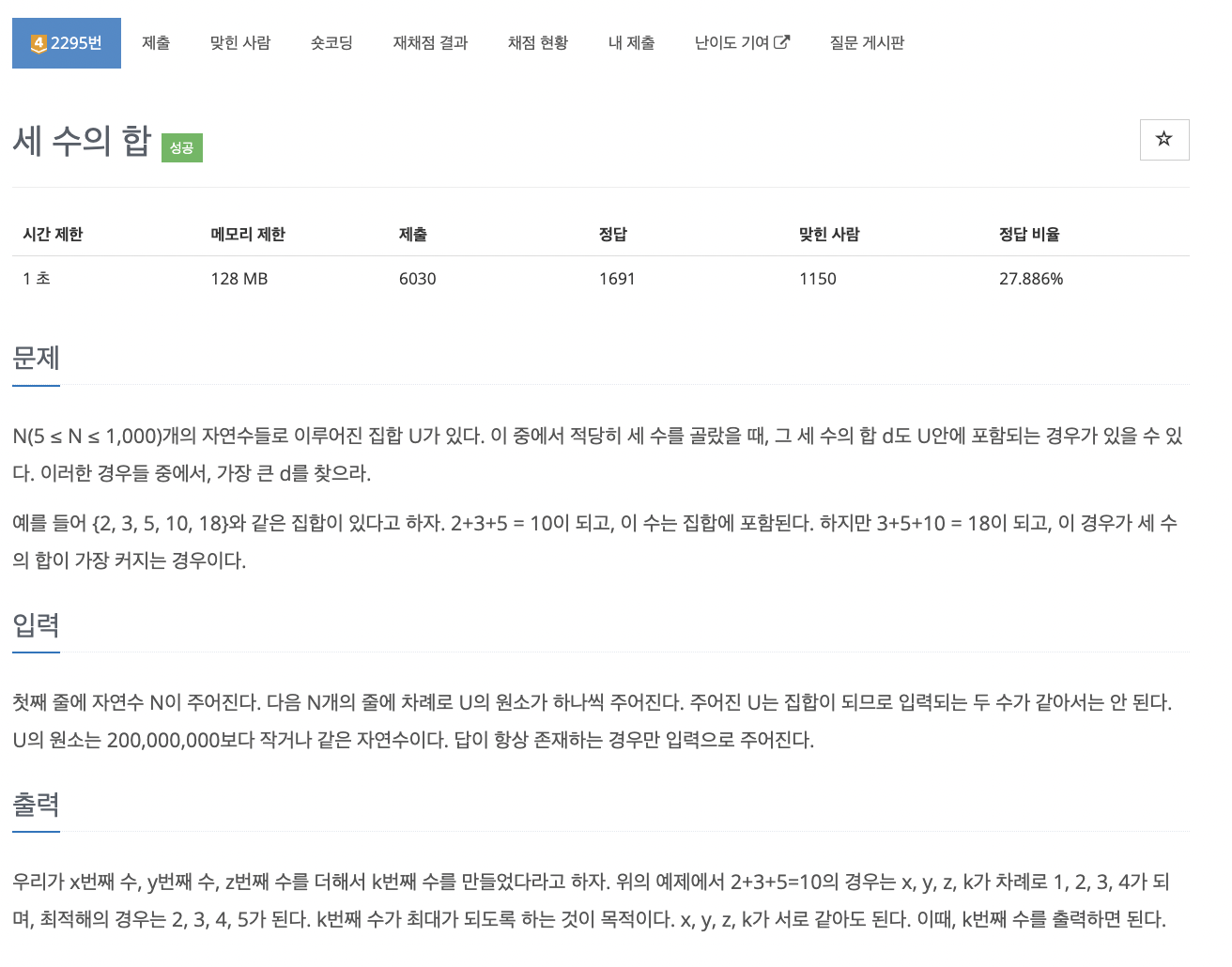
시간복잡도를 최소화하기 위해 두 수의 합 배열을 만듦
44.problem-17135
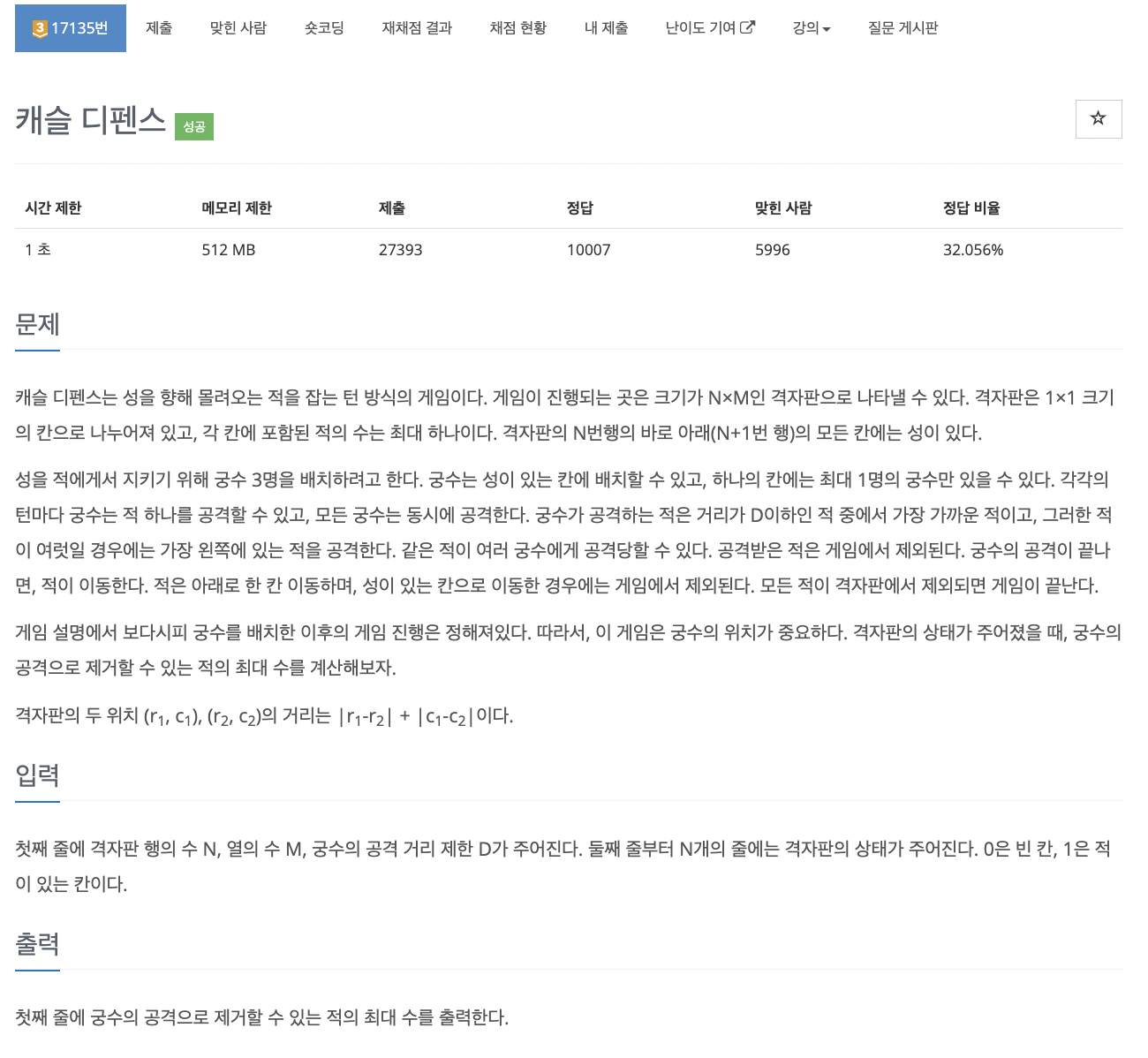
과정1\. slide_down 함수를 통해서 보드를 아래로 내림2\. is_finished 함수를 통해서 보드에서 적들이 다 사라졌는지 확인3\. original에 기존 보드를 저장해두고 combination을 이용해서 궁수들의 자리를 조합4\. 매 조합마다 아래 반복
45.problem-2573

과정1\. check 함수를 통해 이 빙산이 2개 이상으로 분리되었는지 확인한다.(bfs)2\. is_finished 함수를 통해 모든 빙하가 녹았는지 확인한다.3\. 기존 arr를 deep copy로 temp_arr로 복사해놓는다. \-> 순차적으로 녹는게 아니라
46.problem-1525
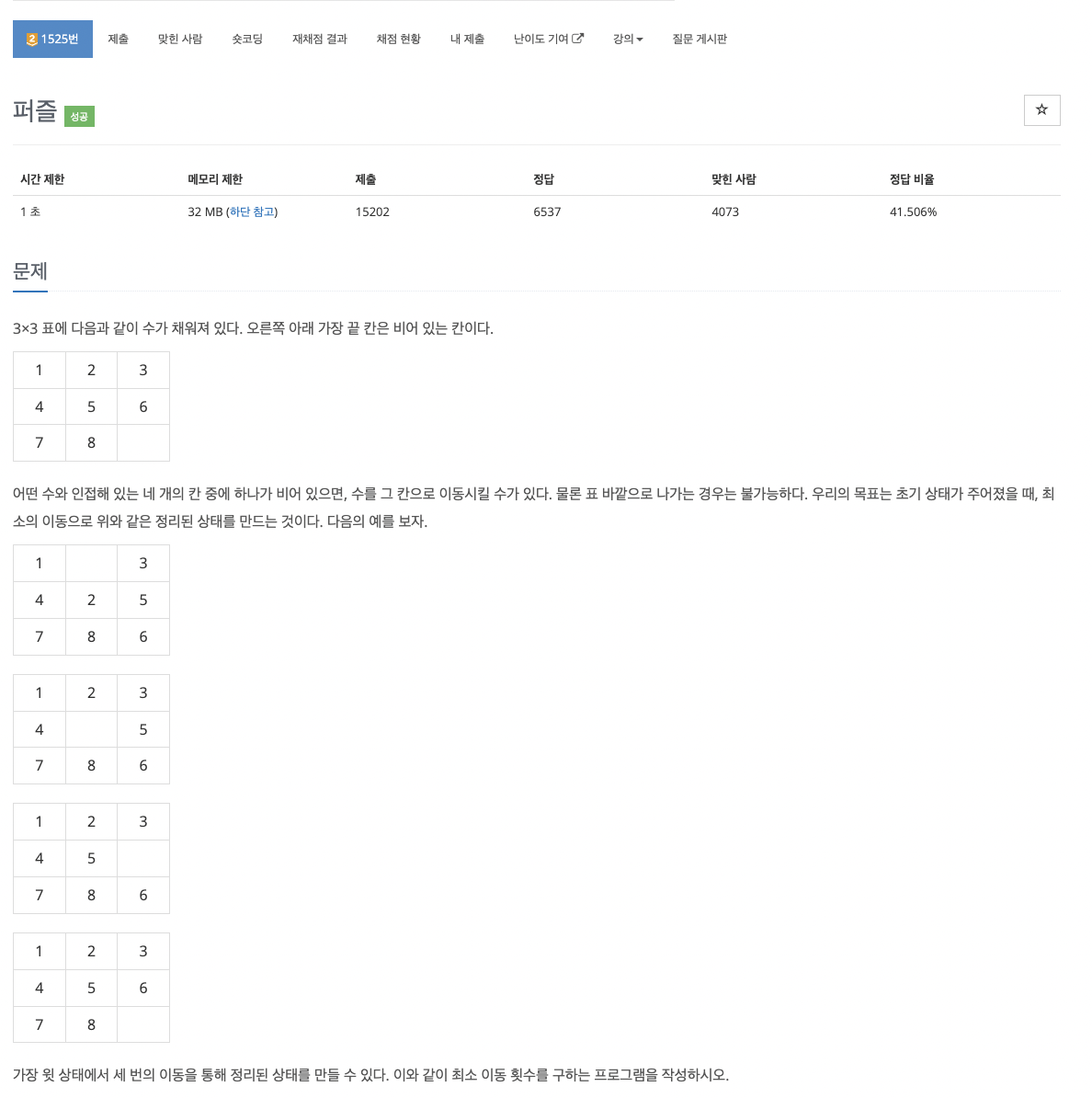
과정1\. 3x3리스트를 문자열로, 문자열을 리스트로 바꿔주는 함수를 만듬2\. 처음 0의 좌표를 저장3\. deque와 defaultdict를 이용해서 각 문자열을 만들 수 있는 최소 횟수를 저장4\. que에 문자열과 0의좌표를 넣고 반복문일반 bfs와 같이 탐색
47.problem-1520
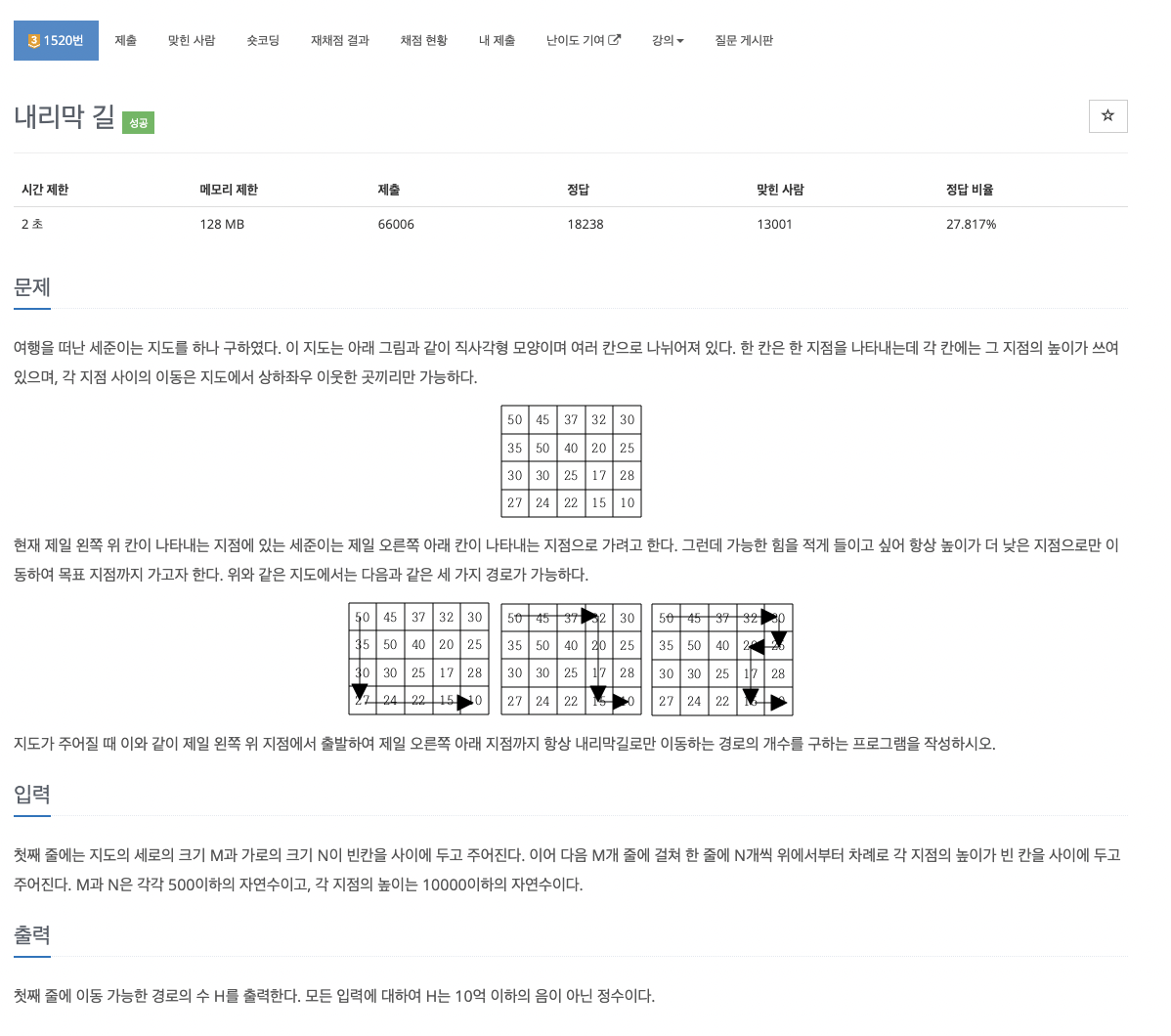
과정\*처음에 dfs로만 풀었는데, 이럴 경우 시간 초과가 발생 -> dp를 이용해야한다.1.dfs(x,y)를 통해 낮은 곳으로만 이동 -> visited함수는 필요없음 why? 작은 곳으로만 이동하기 때문에 그 전 노드로는 가지 않게 됨2\. 2차원 dp설정 -> d