0주차
수업 보조 도구
- Slack
스파르타 코딩클럽은 Slack을 사용해 스터디 그룹을 관리한다. 매주 정해진 요일마다 진행하는 온라인 스터디 공지와 질의응답 등을 위해 사용한다고 한다.
- 개발일지
평소 OneNote를 사용하고 있기 때문에 온라인 개발일지를 제대로 사용해본 적이 없다. 강의에서 티스토리, 미디엄, 벨로그 등 개발일지를 작성해보라는 말을 듣고 이 참에 시작해보기로 했다. 이 세 가지 외에도 Github 블로그, 브런치, 노션 등 여러 가지 플랫폼을 찾아봤지만 벨로그가 Markdown 문법을 사용하며, 코드 첨부가 용이하다고 해서 더 고민하지 않고 벨로그를 선택했다.
1주차
통계 분석 vs. AI 분석
분석 목적 및 데이터의 특징에 따라 분석 방법 선택
통계
- 선형(Linear) 데이터 분석
- 전문가의 과 경험과 직관을 기반으로 가설 수립 및 확인
- 정형 데이터
AI
- 비선형(Non-Linear) 데이터 분석
- 데이터와 데이터간 관계를 새롭게 발견
- 이미지, 텍스트, 음성, 동영상 등 다양한 형태의 input data
ARIMA 모형의 한계
Autoregressive Integrated Moving Average(ARIMA)
Correlation(Linear Regression Model) + Cointegration(Trend)
ARIMA 모형의 한계와 ML/DL의 필요
ARIMA모형으로 분석하기 어려운 경우, 머신러닝 혹은 딥러닝 모형의 구현을 고려.
상황이나 데이터의 특성에 의해 ARIMA모형으로 분석하기 어려운 경우, 머신러닝 혹은 딥러닝 모형의 구현을 고려.
- Incomplete Data: ARIMA는 complete data을 요구
- Non-Linear Trend: ARIMA는 Linear Model만 가능. Non-Linear Trend는 Linear Regression으로 표현하기 어려움.
- 데이터, 이미지, 음성, 영상 등 다양한 형태의 데이터
- 대용량 데이터
딥러닝 For Biz: 올리브영 판매량 예측 모델
Q: 각 매장의 개별 상품들에 대한 판매량 예측
데이터: 3년간의 판매 데이터
-
Simple Linear 모형: Linear하지 않은 데이터를 Linear 모형에 적용.
평균 판매량 예측 가능 - 정확한 판매량 예측 불가. -
LSTM 모형: 매출의 트렌드 흐름 학습
Non-Linear한 Trend Line을 찾아서 판매량 예측 가능.
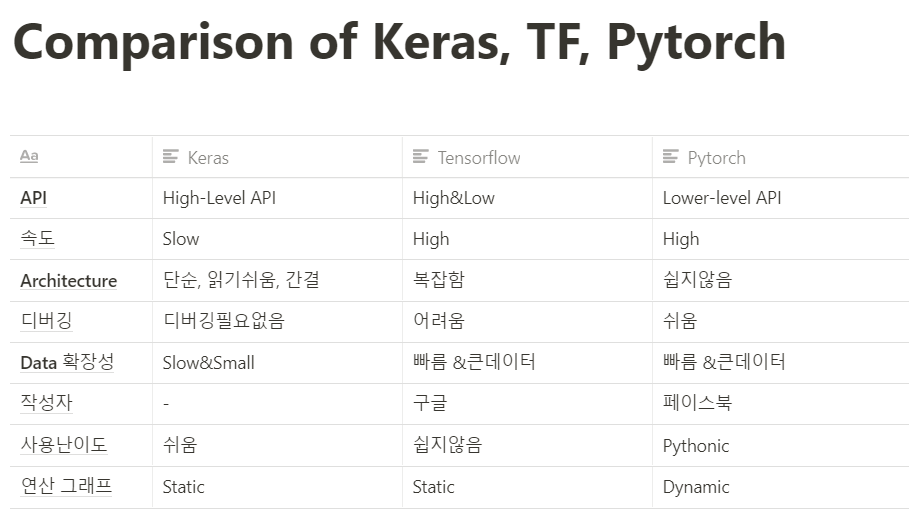
Tools: Colab, Pycharm, Tensorflow
Deep Learning
Single Layer Perceptron(SLP)
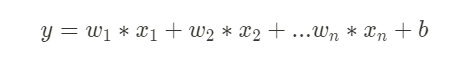
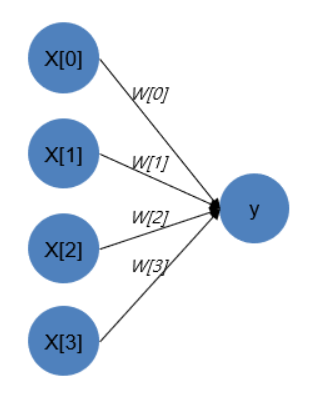
Multi-Layer Perceptron(MLP)
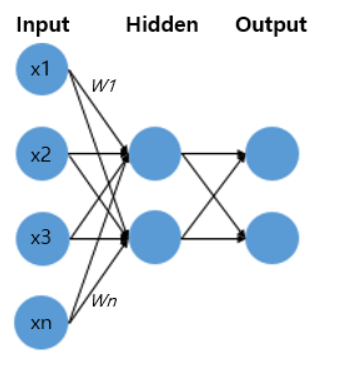
- 가장 기초가 되는 Feed Forward ANN 모형
- Non-Linear 모형을 학습하기 위한 가장 기본적인 딥러닝 모형
- 노이즈나 Missing Value에 잘 대처
- 시계열 데이터에서 지속적인 생각을 하지 못하고 순간 순간의 상황만 판단/예측 - RNN은 이전 단계에서 얻은 정보를 지속적으로 기억되도록 스스로를 반복하여 이 문제를 해결.
MLP의 기본 구성
- Input layer
- Hidden Layer
- Output Layer
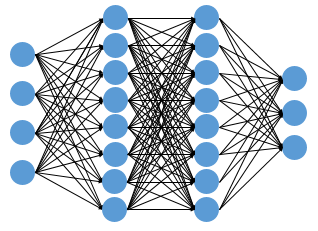
Deep Learning: 여러 은닉층(Hidden Layer)을 가진 Multi-Layer Perceptron
- 많은 Hidden Layer으로 구성된 대규모 신경망이 가능해지면서 Deep Learning이라는 개념 등장.
- Computing Power에 의존적
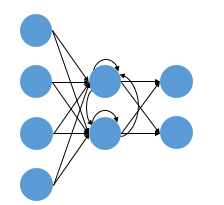
Recurrent Neural Network(RNN)
Concept
-
"시간", "순서" 개념이 들어간 딥러닝의 가장 기초 모형
-
지금의 순간을(t) 그 전 순간(t-1)을 바탕으로 (Context) 이해.
-
스스로를 반복하면서 이전 단계에서 얻은 정보가 지속적으로 기억되게함
-
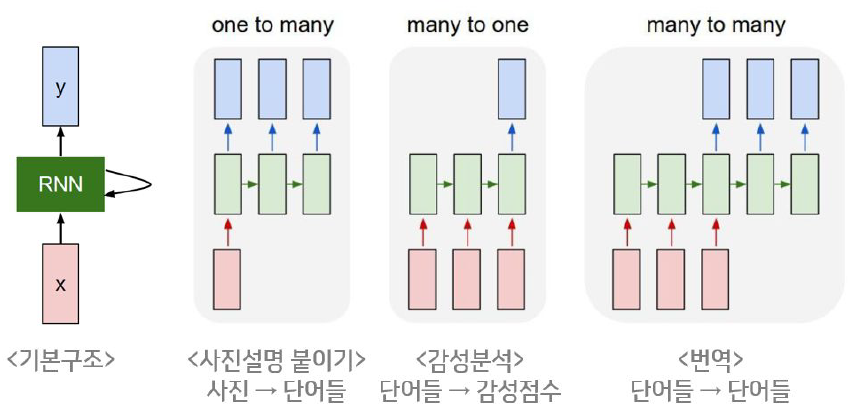
Sequence 길이의 제한이 없기 때문에 one-to-one 뿐만 아니라 one-to-many, many-to-one, many-to-many도 가능
-
나무보다 숲을 봐야하는 경우에 취약함: chain이 반복될수록 최근 학습한 내용은 잘 기억하는 반면 앞서 학습했던 내용은 잘 기억하지 못하기 때문.
블로그 게시글 분석 <<< 10글자 리뷰 분석
문맥 상 의미 추론 <<< 단어 분석
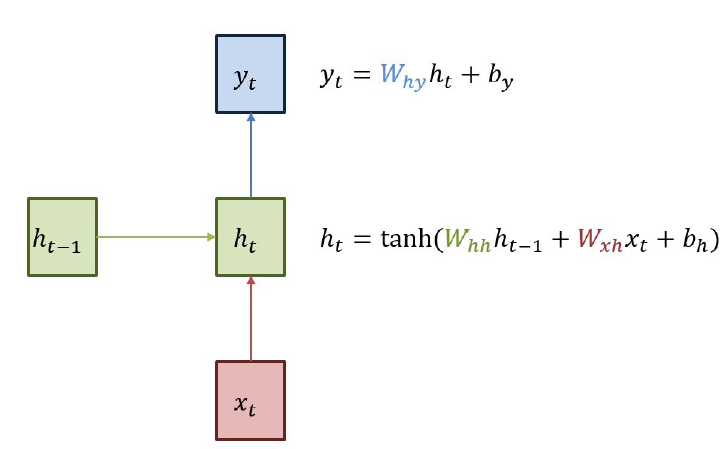
Structure
현재시점의 input: x
예측값: y
예측 시점: t
이전 chain의 결과값: h
bias: b
Long Short-Term Memory Network(LSTM)
- 긴 기간의 데이터에 취약한 RNN의 단점을 보완한 모델
