
📙subQuery란?
SELECT, INSERT, UPDATE, DELETE에 포함된 query
- 괄호 안에 기술
💡subQuery를 사용한 쿼리문 작성하기
- ID가 1인 임직원과 같은 부서 같은 성별인 임직원들의 ID, 이름, 직군
SELECT id, name, position -- id, 이름, 직군
FROM employee
WHERE (dept_id, sex) = ( -- 동일한
SELECT dept_id, sex -- 부서, 성별과
FROM employee
WHERE id = 1 -- id가 1인 임직원의
);💡IN
- a IN (a1, a2, a3, ...) : a가 (a1, a2, a3, ...) 중에 하나와 값이 같다면 TRUE를 리턴한다.
- unqualified attribute가 참조하는 table은 해당 attribute가 사용된 query를 포함하여 그 query의 바깥쪽으로 존재하는 모든 queries 중에 해당 attribute 이름을 가지는 가장 가까이에 있는 table을 참조한다.
ex) ID가 5인 임직원과 같은 프로젝트에 참여한 임직원들의 ID
SELECT DISTINCT empl_id
FROM works_on
WHERE empl_id != 5 -- id가 5인 임직원 제외하고
AND proj_id IN( -- 중에서
SELECT proj_id FROM works_on WHERE empl_id = 5); -- ID가 5인 임직원이 참여한 프로젝트💡EXISTS
- correlated query : subQuery가 바깥쪽 query의 attribute를 참조
- EXISTS : subQuery의 결과가 최소 하나의 row라도 있다면 True를 리턴한다.
ex) ID가 7 혹은 12인 임직원이 참여한 프로젝트의 ID와 이름
SELECT P.id, P.name
FROM project P
WHERE EXISTS(
SELECT *
FROM works_on W -- works_on에 존재한다면
WHERE W.proj_id = P.id -- works_on의 id와 project의 id가 동일하고
AND W.empl_id IN (7,12) -- works_on의 empl_id가 7이거나 12인 것
);💡ANY
- v comparison_operator ANY (subquery) : subquery가 반환한 결과들 중에 단 하나라도 v와의 비교 연산이 True라면 True를 반환한다.
- SOME : ANY와 같은 역할
- <> : !=와 같은 의미
ex) 리더보다 높은 연봉을 받는 부서원을 가진 리더의 ID와 연봉
SELECT E.id, E.name, E.salary
FROM department D, employee E
WHERE D.leader_id = E.id AND E.salary < ANY (
SELECT salary
FROM employee
WHERE id <> D.leader_id AND dept_id = E.dept_id
);💡ALL
- v comparison_operator ALL (subquery) : subquery가 반환한 결과들과 v와의 비교 연산이 모두 True라면 True를 반환한다.
ex) ID가 13인 임직원과 한번도 같은 프로젝트에 참여하지 못한 임직원들의 ID, 이름, 직군
SELECT DISTINCT E.id, E.name, E.position
FROM employee E, works_on W
WHERE E.id = W.empl_id AND W.proj_id <> ALL(
SELECT proj_id
FROM works_on
WHERE empl_id = 13
);📙NULL
unknown, unavailable, not applicable
💡Null과 Three-Valued Logic
three-value logic : 비교/논리 연산의 결과로 True, False, Unknown을 가진다.
UNKNOWN
- SQL에서 NULL과 비교 연산을 하면, unknown이다.
- unknown은 True일 수도 있고, False일 수도 있다는 의미이다.
- where 절에 있는 condition의 결과가 True인 튜플만 선택된다.
✔️즉, 결과가 False이거나 Unknown이면, tuple은 선택되지 않는다. - v NOT IN(v1, v2, v3)
-> v != v1 AND v != v2 AND v != v3에서 v1, v2, v3 중에 하나가 NULL이라면❓
💡NOT IN을 사용하여 쿼리문 작성하기
- 2000년대생이 없는 부서의 ID와 이름
SELECT D.id, D.name
FROM department AS D
WHERE D.id NOT IN(
SELECT E.dept_id
FROM employee E
WHERE E.birth_date >= '2000-01-01'
AND E.dept_id IS NOT NULLSELECT D.id, D.name
FROM department AS D
WHERE NOT EXISTS(
SELECT *
FROM employee E
WHERE E.dept_id = D.id AND E.birth_date >= '2000-01-01'📙Join이란?
두 개 이상의 table들에 있는 데이터를 한 번에 조회하는 것
💡implicit join과 explicit join
-
implicit join
- from 절에는 table 들만 나열하고 where 절에 join condition을 명시
- where절에 selection condition과 join condition이 같이 있기 때문에 가독성이 떨어진다.
- 복잡한 join 쿼리를 작성하다 보면 실수로 잘못된 쿼리를 작성할 가능성이 크다.
-- ID가 1인 임직원이 속한 부서 이름 SELECT D.name FROM employee AS E, department AS D WHERE E.id = 1 and E.dept_id = D.id; -
explicit join
- from 절에 JOIN 키워드와 함께 joined table들을 명시
- from 절에서 ON 뒤에 join condition이 명시
- 가독성이 좋다.
- 복잡한 join 쿼리 작성 중에도 실수할 가능석이 적다.
-- ID가 1인 임직원이 속한 부서 이름 SELECT D.name FROM employee AS E JOIN department AS D ON E.dept_id = D.id WHERE E.id=1;
💡inner join과 outer join
-
inner join
- 두 table에서 join condition을 만족하는 tuple들로 result table을 만드는 join
- FROM table1 [INNER] JOIN table2 ON join_condition
- join condition에 비교 연산자 사용 가능
- join condition에서 null 값을 가지는 tuple은 result table에 포함되지 않는다.
SELECT * FROM employee E INNER JOIN department D ON E.dept_id = D.id; -
outer join
-
두 table에서 join condition을 만족하지 않는 tuple들로 result table에 포함하는 join
-
join condition에 비교 연산자 사용 가능
-
FROM table1 LEFT [OUTER] JOIN table2 ON join_condition
SELECT * FROM employee E LEFT OUTER JOIN department D ON E.dept_id = D.id;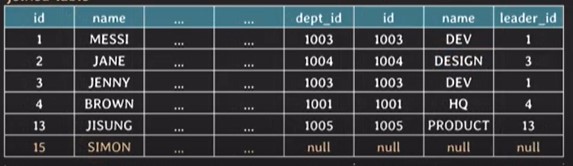
-
FROM table1 RIGHT [OUTER] JOIN table2 ON join_condition
SELECT * FROM employee E RIGHT OUTER JOIN department D ON E.dept_id = D.id;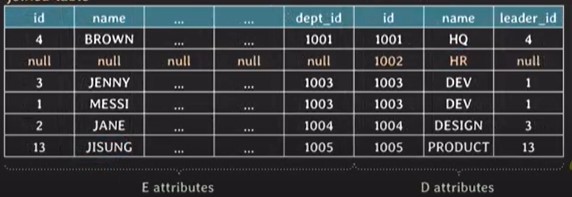
-
FROM table1 FULL [OUTER] JOIN table2 ON join_condition
SELECT * FROM employee E FULL OUTER JOIN department D ON E.dept_id = D.id;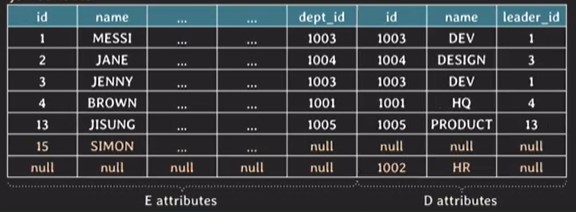
-
💡equi join
- join condition에서 =(동등 연산자)를 사용하는 join
💡using을 사용하면❓
- 두 table이 equi join할 때 join하는 attribute의 이름이 같다면, USING으로 작성 가능하다.
- 이때, 같은 이름의 attribute는 result table에서 한번만 표시
SELECT * FROM employee E FULL OUTER JOIN department D USING (dept_id);
💡natural join
- 모든 table에서 같은 이름을 가지는 모든 attrbute pair에 대해서 equi join을 수행
- join condition을 따로 명시하지 않는다.
- FROM table1 NATURAL [INNER] JOIN table2
SELECT *
FROM employee E NATURAL INNER JOIN department D;💡cross join
- 두 table의 tuple pair로 만들 수 있는 모든 조합(= Cartesian product)을 result table로 반환한다.
- join condition이 없다.
- implicit cross join의 경우, FROM table1, table2
- explicit cross join의 경우, FROM table1 CROSS JOIN table2
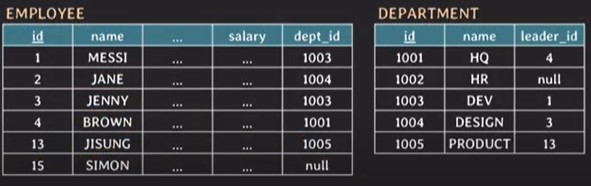
=> SELECT employee CROSS JOIN deparment; 하면
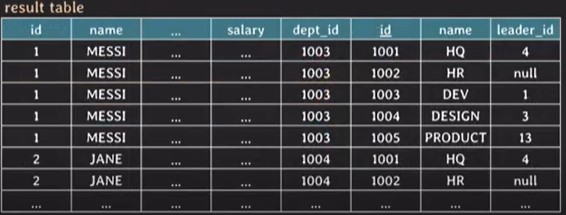
💡self join
- table이 자기 자신에게 join하는 경우
💡JOIN 사용 예제
-
ID가 1003인 부서에 속하는 임직원 중 리더를 제외한 부서원의 ID, 이름, 연봉
SELECT E.id, E.name, E.salary FROM employee E JOIN department D ON E.dept_id = D.id WHERE E.dept_id = 1003 and E.id != D.leader_id; -- ID가 1003인 부서 이고, 리더가 아닌 임직원 중에서 -
ID가 2001인 프로젝트에 참여한 임직원들의 이름, 직군, 소속 부서 이름
SELECT E.name AS empl_name, E.position AS empl_position, D.name AS dept_name FROM works_on W JOIN employee E ON W.empl_id = E.id LEFT JOIN department D ON E.dept_id = D.id WHERE W.proj_id = 2001;✔️이때, LEFT JOIN을 하는 이유는❓
E.dept_id가 null인 경우에도, join 했을 때 employee 정보가 남아있기 위해서
📙데이터 조회하기
💡ORDER BY
- 조회 결과를 특정 attribute(s) 기준으로 정렬하여 가져오고 싶을 때 사용한다.
- 오름차순(ASC, default), 내림차순(DESC)
SELECT * FROM employee ORDER BY dept_id, ASC, salary DESC;✔️이때, 오름차순 정렬 시 NULL을 우선적으로❗
💡aggregate function
- 여러 tuple들의 정보를 요약해서 하나의 값으로 추출하는 함수
- COUNT, SUM, MAX, MIN, AVG 함수
- NULL 값들은 제외하고 요약 값을 추출한다.
SELECT COUNT(*), MAX(salary), MIN(salary), AVG(salary) -- 임직원 수, 최대 연봉, 최소 연봉, 평균 연봉
FROM works_on W JOIN employee E ON W.empl_id = E.id
WHERE W.proj_id = 2002; -- 프로젝트 2002에 참여한💡GROUP BY
- 관심있는 attribute(s) 기준으로 그룹을 나눠서 그룹별로 aggregate function을 적용하고 싶을 때 사용한다.
- grouping attribute(s) : 그룹을 나누는 기준이 되는 attribute(s)
- grouping attribute(s)에 NULL 값이 있을 때는 NULL 값을 가지는 tuple 끼리 묶인다.
SELECT W.proj_id, COUNT(*), MAX(salary), MIN(salary), AVG(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id;✔️ 이때 그룹화 기준인 W.proj_id를 적어줘야 한다.
💡HAVING
- GROUP BY와 함께 사용한다.
- aggregate function의 결과값을 바탕으로 그룹을 필터링하고 싶을 때 사용한다.
- HAVING절에 명시된 조건을 만족하는 그룹만 결과에 포함된다.
SELECT W.proj_id, COUNT(*), MAX(salary), MIN(salary), AVG(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id
HAVING COUNT(*) >= 7;💡예제
- 각 부서별, 성별 인원수를 인원 수가 많은 순서대로 정렬
SELECT dept_id, sex, COUNT(*) AS empl_count FROM employee
GROUP BY dept_id,sex;
ORDER BY empl_count DESC;- 회사 전체 평균 연봉보다 평균 연봉이 적은 부서들의 평균 연봉
SELECT dept_id, AVG(salary)
FROM employee
GROUP BY dept_id
HAVING AVG(salary) <
(SELECT AVG(salary) FROM employee);- 각 프로젝트별로 프로젝트에 참여한 90년대생들의 수와 이들의 평균 연봉
SELECT proj_id, COUNT(*), ROUND(AVG(salary), 0)
FROM works_on W JOIN employee E ON W.empl_id = E.id
WHERE E.birth_date BETWEEN '1990-0101' AND '1999-12-31'
GROUP BY W.proj_id;
ORDER BY W.proj_id; -- proj_id를 기준으로 정렬 - 프로젝트 참여 인원이 7명 이상인 프로젝트에 한정해서 각 프로젝트 별로 프로젝트에 참여한 90년대생들의 수와 이들의 평균 연봉
SELECT proj_id, COUNT(*), ROUND(AVG(salary),0)
FROM works_ond W JOIN employee E ON w.empl_id = E.id
WHERE E.birth_date BETWEEN '1990-01-01' AND '1999-12-31'
AND W.proj_id IN (SELECT proj_id FROM works_on GROUP BY proj_id HAVING COUNT(*) >=7)
GROUP BY W.proj_id
ORDER BY W.proj_id;📙SELECT문 정리하기
SELECT attribute or aggregate function -- 6
FROM table -- 1
[ WHERE condition ] -- 2
[ GROUP BY group attribute ] -- 3
[ HAVING group condition ] -- 4
[ ORDER BY attribute ] -- 5