
Kafka 사전 정보
Apache kafka
이벤트 스트리밍 플랫폼
RabbitMQ vs kafka
- RabbitMQ
- 메시지 브로커 방식
- 큐에 저장된 메시지에 대해 컨슈머가 가져가게 되면 해당 메시지 삭제됨
- 데이터 처리보단 관리적 측면이나 다양한 서비스 구축할 때 사용
- kafka
- pub/sub 방식
- 메시지가 들어오면 topic으로 분류, 메시지를 가져가더라도 계속 유지됨
- 방대한 양의 데이터 처리할 때 유용함
- 중간에 데이터 전송이 끊기더라도 끊긴 시점부터 다시 시작 가능
프로세스
- 이벤트 발생 시 kafka를 통해 실시간 업데이트 -> hadoop hdfs에 데이터 저장 -> spark를 통해 분산처리
kafka broker
- 실행된 kafka 애플리케이션 서버 중 1대
- 주로 3대 이상의 브로커로 클러스터 구성
- 주키퍼와 연동
- n개 중 1대는 컨트롤러 기능 수행
- 컨트롤러 : 각 브로커에게 담당 파티션 할당 수행. 브로커 정상 동작 모니터링 관리
Record
객체를 프로듀서에서 컨슈머로 전달하기 위해 kafka 내부에 byte 형태로 저장할 수 있도록 직렬화/역직렬화 하여 사용
- 기본 제공 직렬화 class : StringSerializer, ShortSerializer 등
- 커스텀 직렬화 class 통해 Custom Object 직렬화/ 역직렬화 가능
Topic & Partition
- 메시지 분류 단위
- n 개의 파티션 할당 가능
- 각 파티션마다 고유한 오프셋 가짐
- 메시지 처리순서는 파티션 별로 유지 관리
- 파티션별로 순서대로 저장되는걸 보장하지 않음
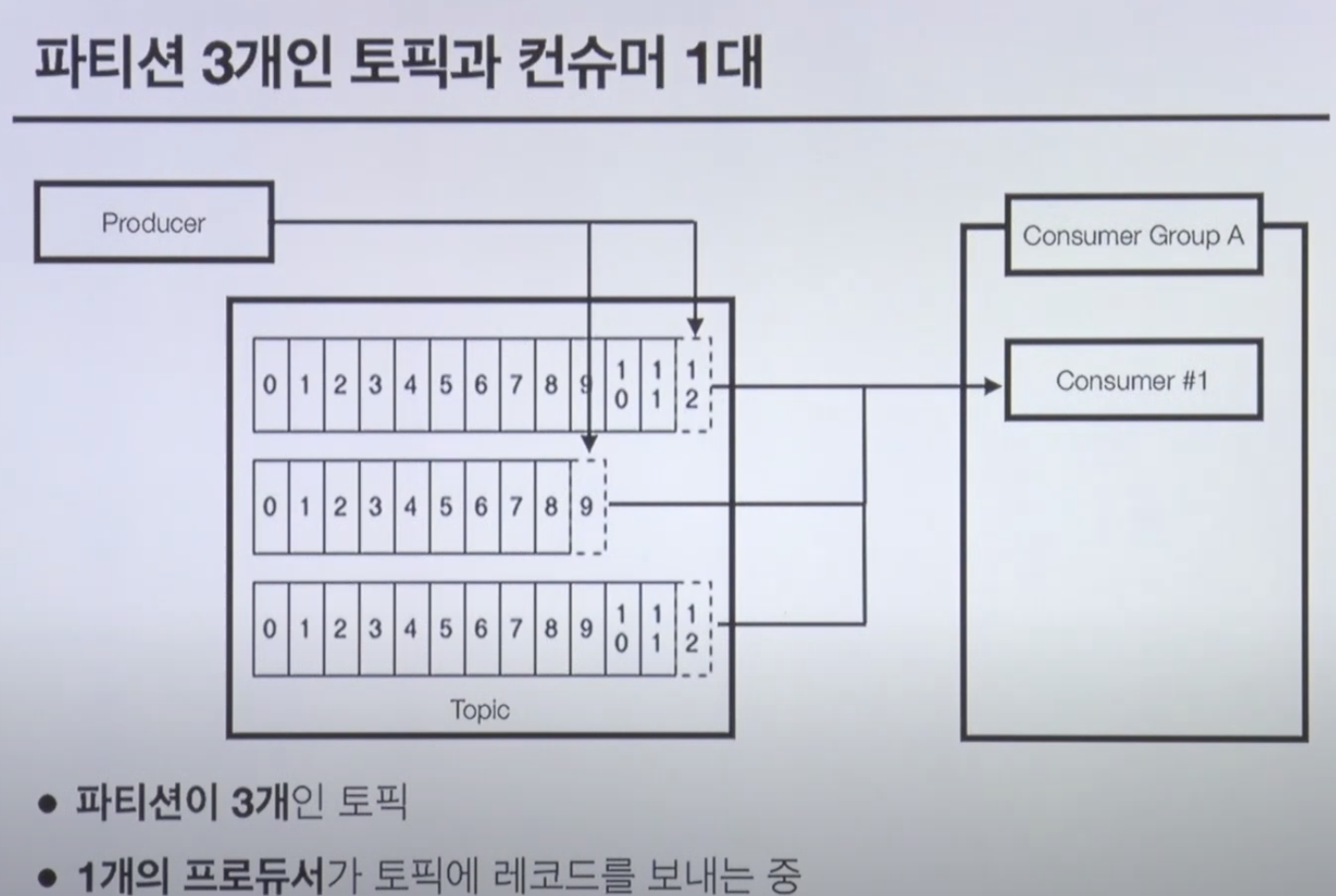
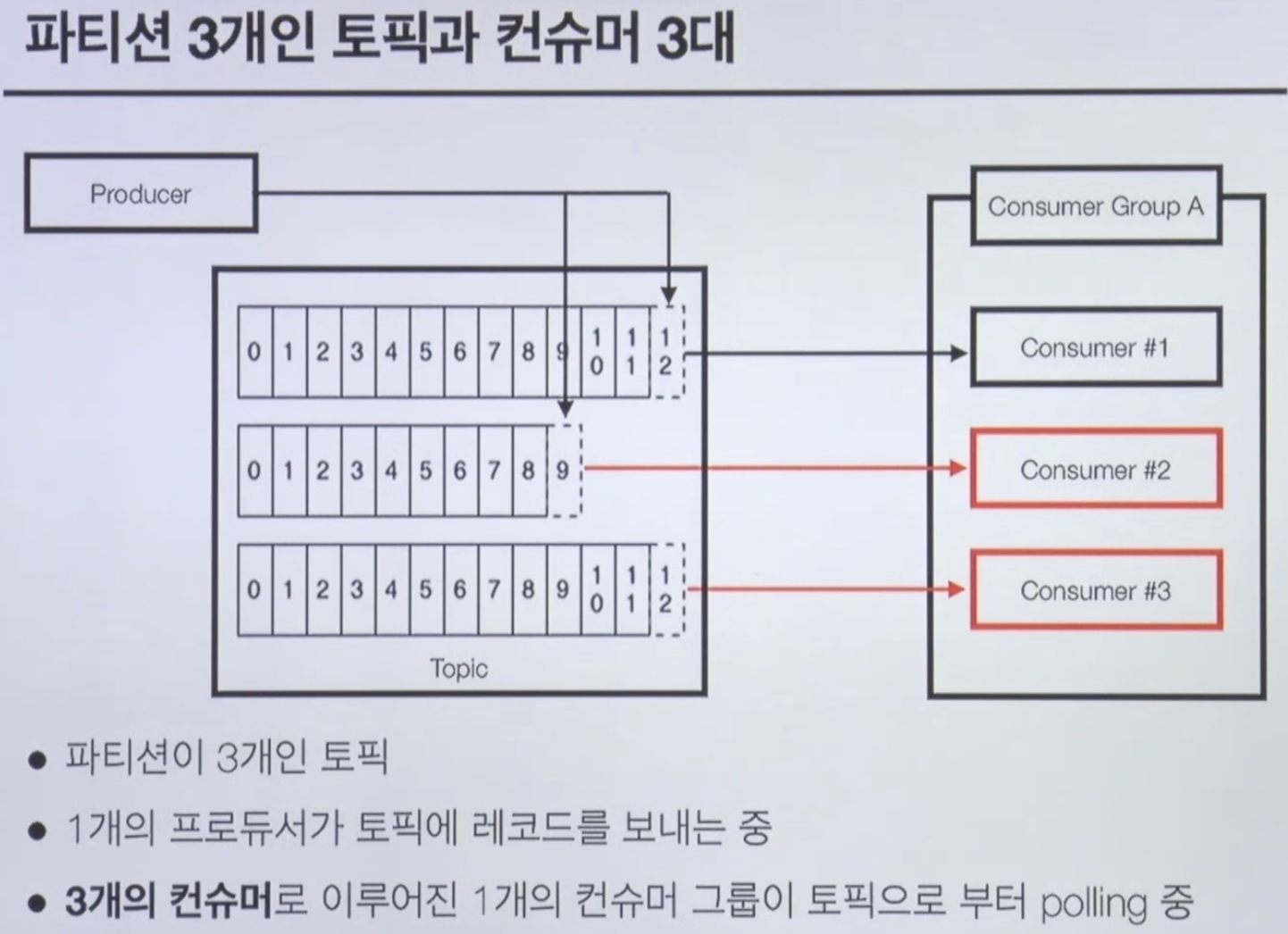
Producer & Consumer
- 프로듀서는 레코드를 생성하여 브로커로 전송
- 전송된 레코드는 파티션에 신규 오프셋과 함께 기록됨
- 컨슈머는 브로커로부터 레코드를 요청하여 가져감(polling)
- 컨슈머는 항상 파티션 개수보다 작거나 같아야함
- 남는 컨슈머는 할당받지 못하고 무한 대기함
- 목적에 따라 컨슈머 그룹을 분리할 수도 있음
- 토픽 생성 시 레플리케이션 개수를 지정하면 파티션을 복제하여 저장하므로 데이터 유실 방지 가능
- 리더 파티션 : kafka클라이언트와 데이터 주고 받는 역할
- 팔로워 파티션 : 리더 파티션으로부터 레코드를 지속 복제
- 리더 파티션이 동작 불가능할 경우 나머지 파티션 중 한개가 리더 파티션으로 지정됨
- 특정 파티션의 리더, 팔로워 레코드가 모두 복제되어 sync가 맞는 상태
→ ISR (In-Sync-Replica)
kafka 핵심요소
- Broker : kafka 애플리케이션 서버 단위
- Topic : 데이터 분리 단위, 다수 파티션 보유
- Partition : 레코드를 담고 있음. 컨슈머 요청 시 레코드 전달
- Offset : 각 레코드당 파티션에 할당된 고유 번호
- Consumer : 레코드를 polling 하는 애플리케이션
- Consumer group : 다수 컨슈머 묶음
- Consumer offset : 특정 컨슈머가 가져간 레코드 번호
- Producer : 레코드를 브로커로 전송하는 애플리케이션
- Replication : 파티션 복제 가능
- ISR : 리더 + 팔로워 파티션의 sysn가 된 묶음
Kafka Client
- kafka와 데이터를 주고받기 위해 사용하는 Java Library
- Producer, Consumer, Admin, Stream 등 kafka 관련 api 제공
- kafka broker 버전과 client 버전 하위호환 확인 필요
Kafka Streams
- 데이터를 변환하기 위한 목적으로 사용하는 API
- 스트림 프로세싱을 지원하기 위한 다양한 기능 제공
- Stateful or Stateless 와 같이 상태기반 스트림 처리 가능
- Stream api 와 DSL을 동시 지원
- Exactly-once 처리, 고가용성 특징
- Kafka securoty 완벽 지원
- 스트림 처리를 위한 별도 클러스터 불필요
Kafka Connect
- 많은 경우 kafka client로 kafka로 데이터를 넣는 코드를 작성할때도 있지만, kafka connect를 통해 data를 import/export 할 수 있음
- 코드 없이 configuration으로 데이터 이동시키는 것이 목적
- REST api 인터페이스를 통해 제어
- Stream or Batch 형태로 데이터 전송 가능
- 다양한 플러그인
Kafka Mirror Maker
- 특정 카프카 클러스터에서 다른 카프카 클러스터로 Topic 및 Record를 복제하는 tool
- 클러스터간 토픽에 대한 모든 것을 복제하는것이 목적
그 외…
- coonfluent/ksqlDB : sql구문을 통한 stream data processing 지원
- linkedin/kafka burrow : consumer lag 수집 및 분석
- yahoo/CMAK : 카프카 클러스터 매니저
- Spark stream : 다양한 소스로부터 실시간 데이터 처리
Kafka 클러스터 구축
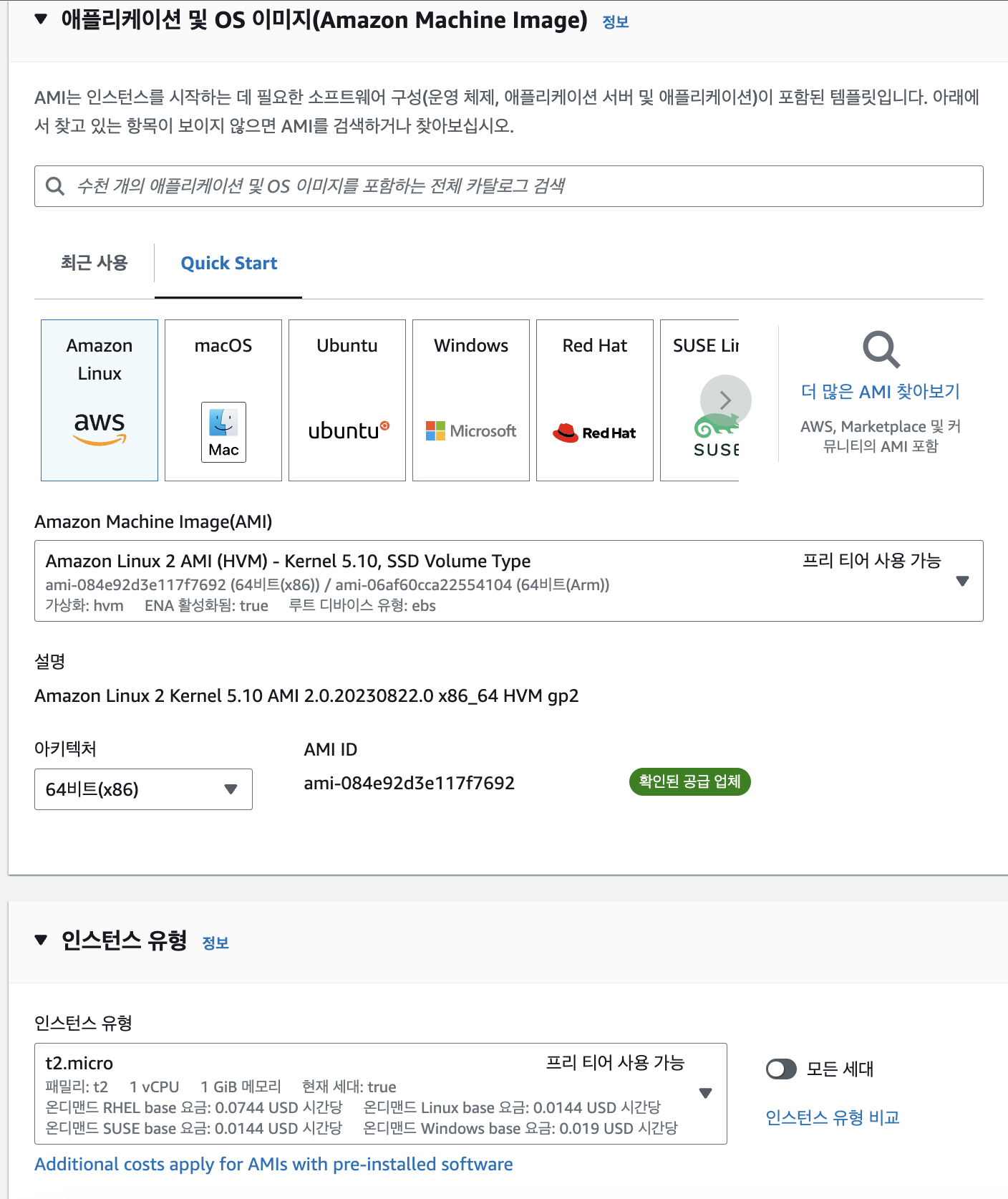
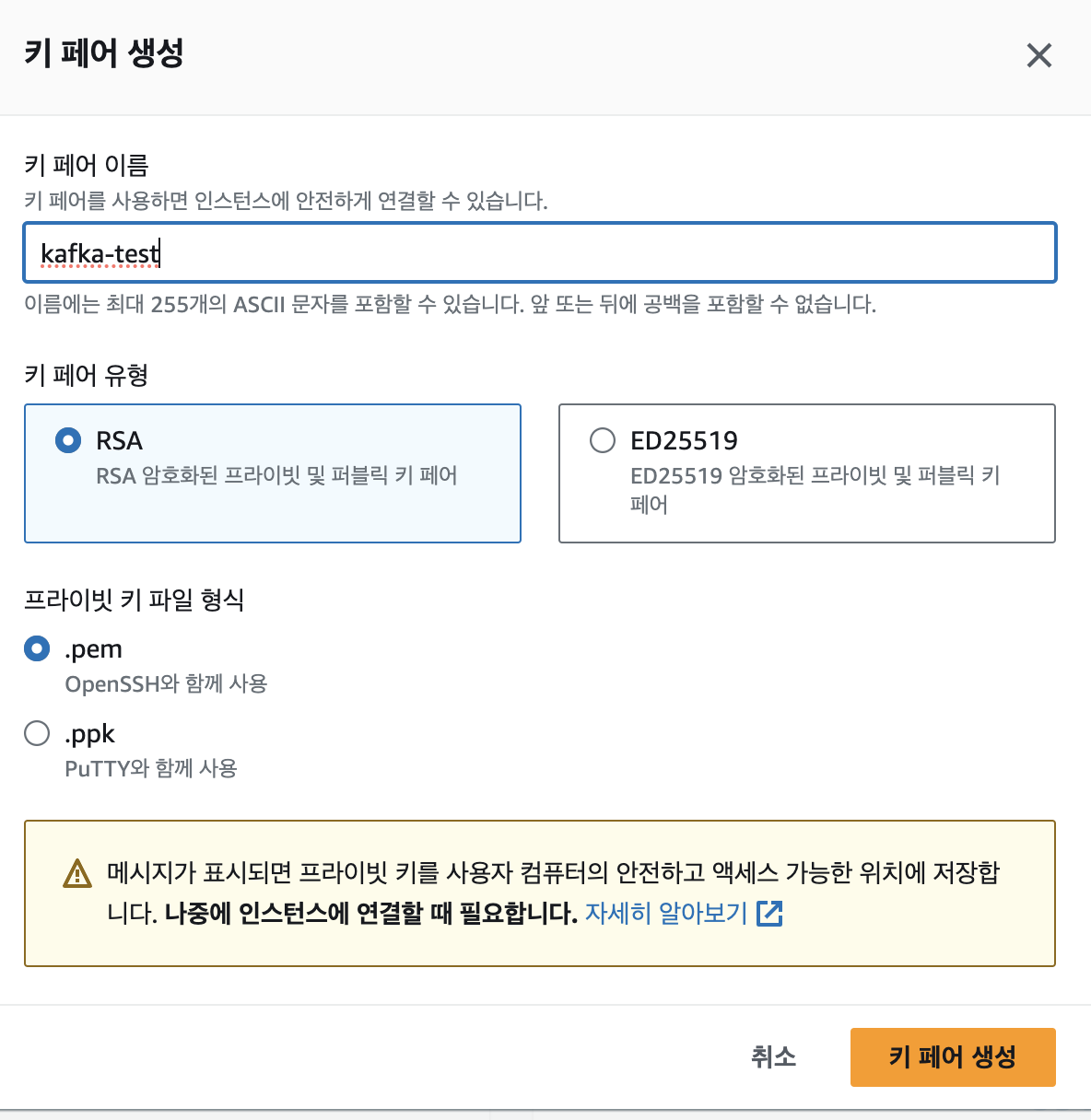
1. 인스턴스 생성
1-1 옵션 선택
1-2 키페어 생성
1-3 브로커 3개로 구축하기 위해 인스턴스 개수 3으로 설정 후 인스턴스 시작
인스턴스 생성 확인

2. 포트 설정
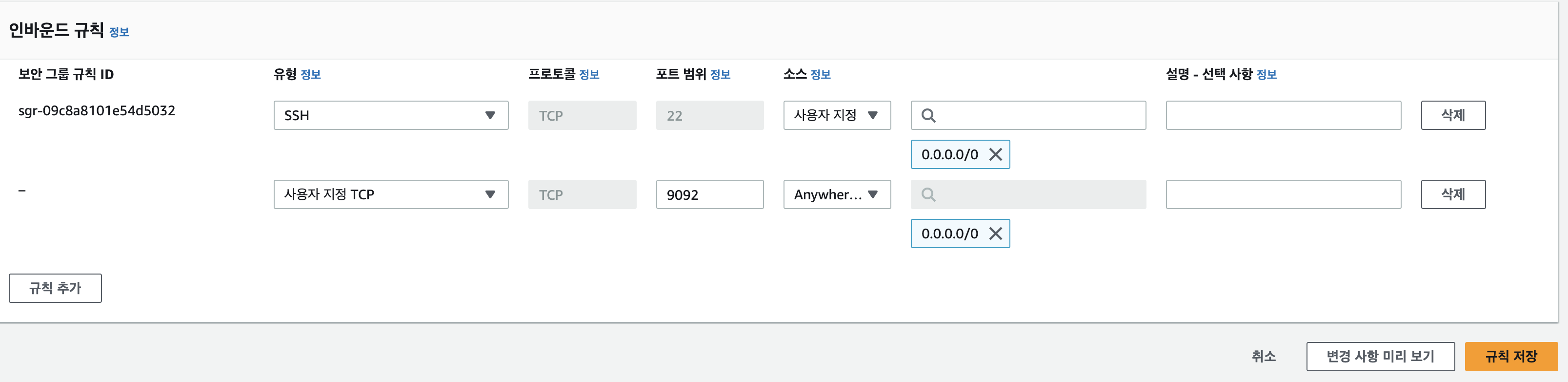
보안그룹 - 인바운드 규칙 편집으로 이동
위와 같이 규칙 추가한 후 저장
3. ec2 접속
# 키 파일 다운로드 받은 위치로 이동 $ cd {폴더명} # 권한 설정 $ chmod 400 {키파일 이름}.pem #ec2 접속 $ ssh -i {키파일 이름}.pem ec2-user@{aws ec2 public ip}
4. hostname 변경 및 설정
# hostname 변경 $ sudo hostnamectl set-hostname kafka-01 # 나머지 두개도 같은 방식으로 kafka-02, kafka-03으로 변경 $ sudo vi hosts # i 키 눌러 편집모드로 변경 0.0.0.0 kafka-01 x.x.x.x kafka-02 x.x.x.x{private IP} kafka-03 # kafka-02 에서는 0.0.0.0 kafka-02 로 설정
5. zookeeper 설치
https://zookeeper.apache.org/releases.html
위의 링크로 접속하여 버전 선택
(작성자의 경우에는 3.7.1)
링크 들어가서 다운로드 url 복사
각 인스턴스마다 설치
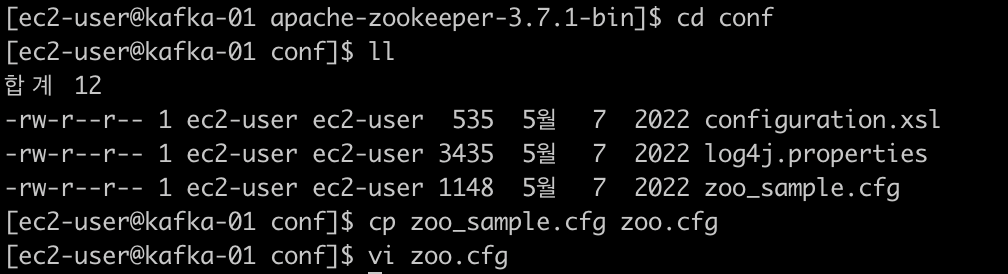
$ wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apachezookeeper-3.7.1-bin.tar.gz # 압축해제 $ tar xvf apache-zookeeper-3.7.1-bin.tar.gz # 경로 이동 후 설정 파일 수정 $ cd apache-zookeeper-3.7.1-bin/
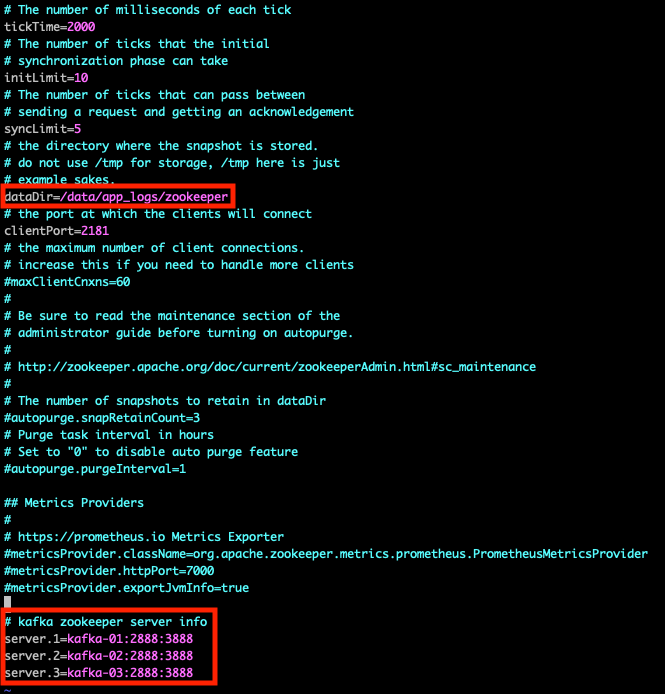
위와 같이 설정 파일 수정# 설정 파일에 로그파일 경로 생성 $ sudo mkdir -p /data/app_logs/zookeeper $ cd /data/app_logs $ sudo chmod -R 777 /data $ echo {인스턴스 번호} > /data/app_logs/zookeeper/myid # kafka-01이면 1, kafa-02 면 2 입력


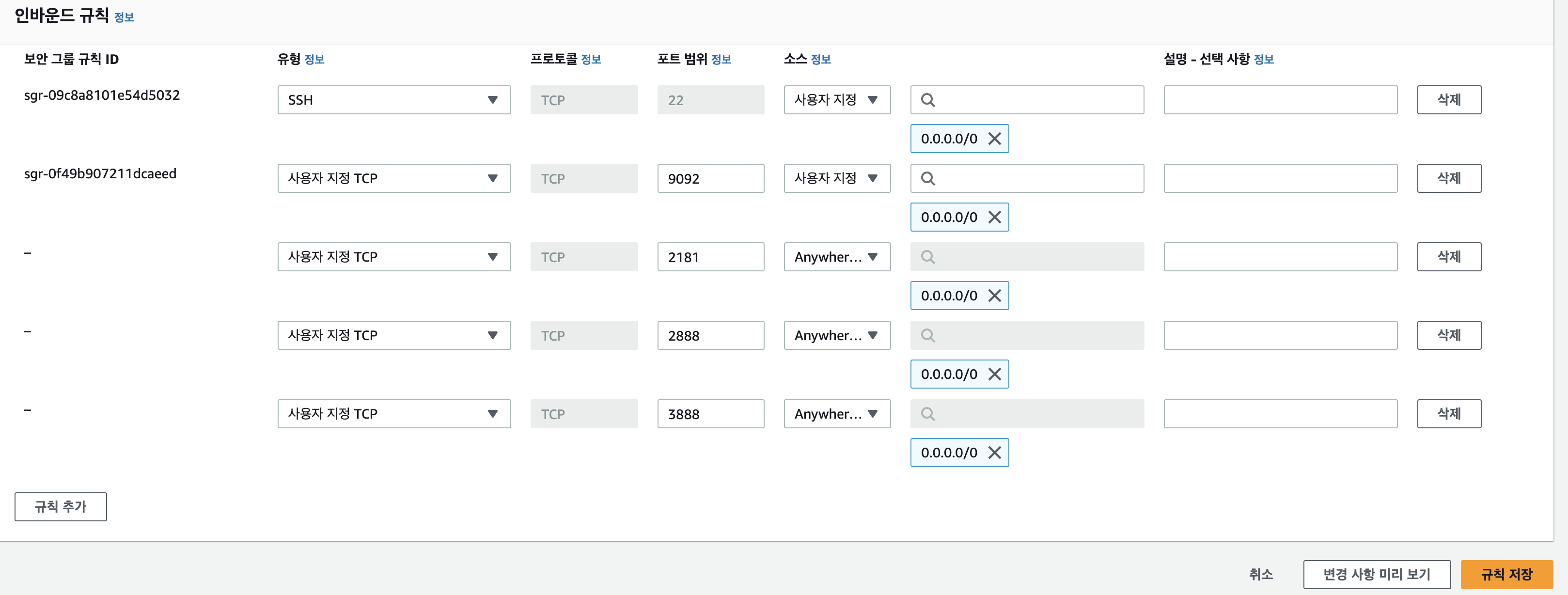
6. 방화벽 설정 수정
2번과 같은 방식으로 zookeeper 사용하기 위해 2181, 2888, 3888 포트 개방
# ec2 콘솔에서도 개방 # 확인 $ sudo iptables -L -n -v --line-numbers $ sudo iptables -A INPUT -p tcp --dport 22 -j ACCEPT $ sudo iptables -A INPUT -p tcp --dport 2181 -j ACCEPT $ sudo iptables -A INPUT -p tcp --dport 2888 -j ACCEPT $ sudo iptables -A INPUT -p tcp --dport 3888 -j ACCEPT $ sudo iptables -A INPUT -p tcp --dport 9092 -j ACCEPT
# hostname으로 통신하기 위해 /etc/hosts 수정 $ sudo vi /etc/hosts # 3개 다 설정 # kafka-02 에서는 0.0.0.0 kafka-02
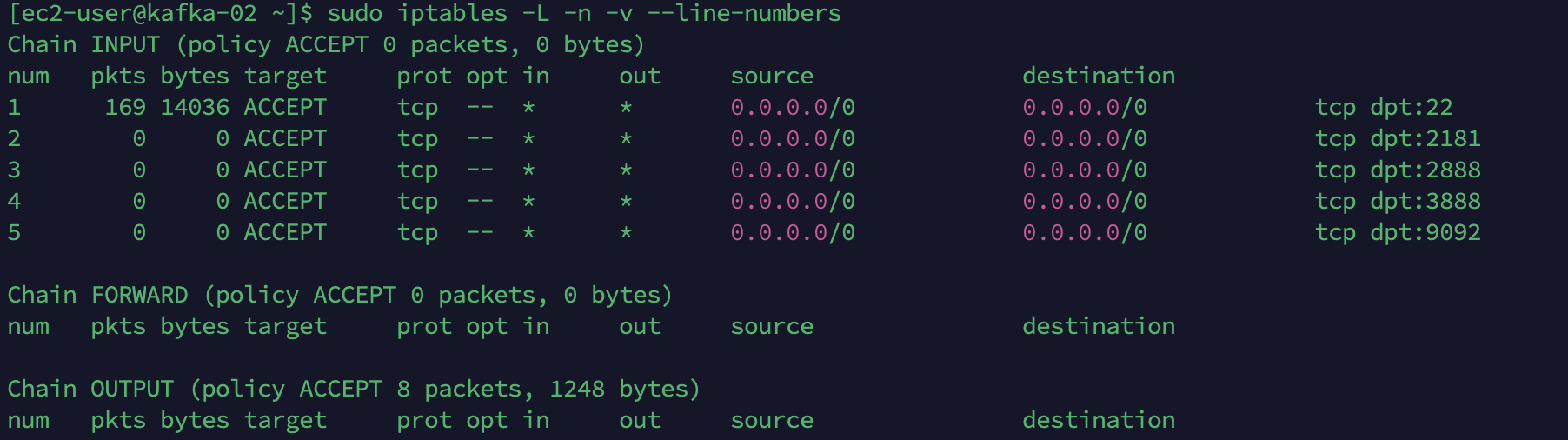

7. 자바 설치
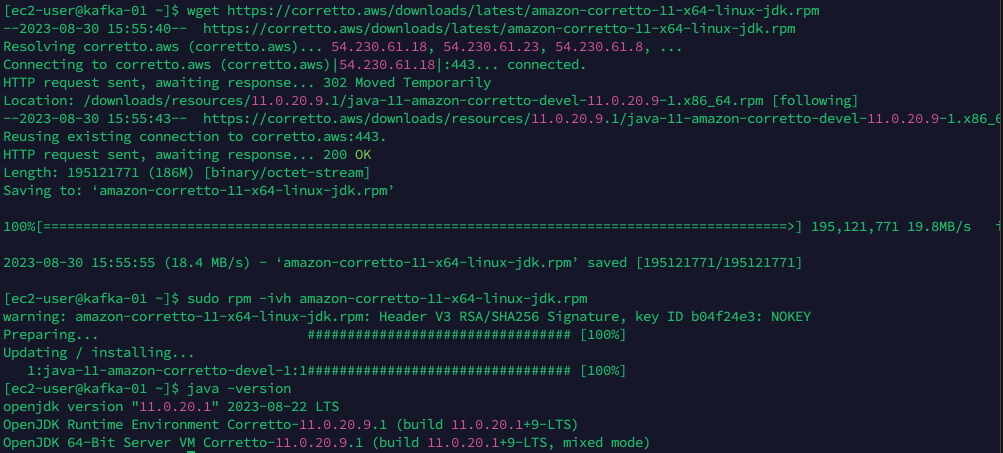
[Amazon Linux 2 에서 Java11 설치]$ wget https://corretto.aws/downloads/latest/amazon-corretto-11-x64-linux-jdk.rpm $ sudo rpm -ivh amazon-corretto-11-x64-linux-jdk.rpm # 설치 확인 $ java -version
8. alias 설정
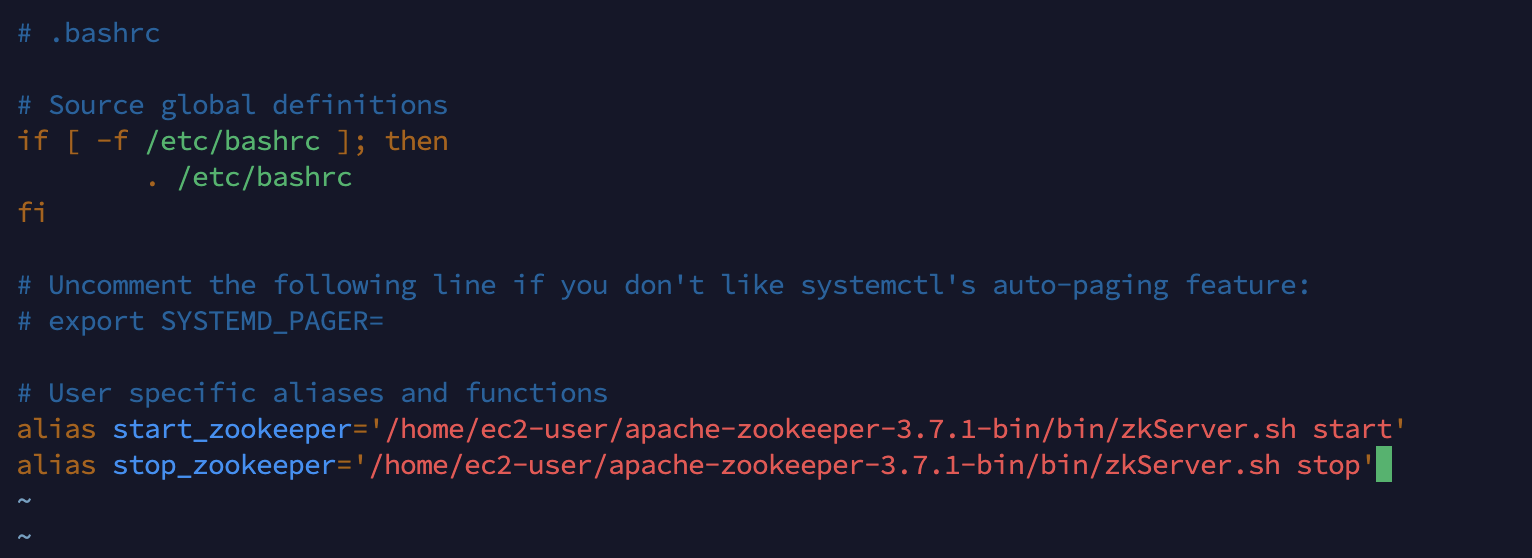
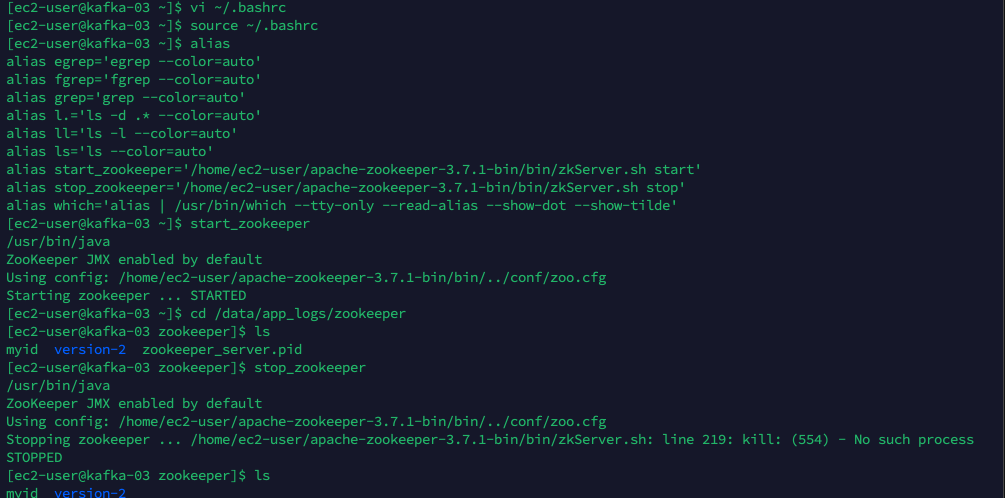
# alias 입력 $ vi ~/.bashrc # 편집모드 활성화 후 아래의 텍스트 입력 alias start_zookeeper='/home/ec2-user/apache-zookeeper-3.7.1-bin/bin/zkServer.sh start' alias stop_zookeeper='/home/ec2-user/apache-zookeeper-3.7.1-bin/bin/zkServer.sh stop' # 적용 후 확인 $ source ~/.bashrc $ alias # alias로 실행 $ start_zookeeper # 주키퍼 시작 시 pid 파일이 생기고 중단하면 사라짐 $ cd /data/app_logs/zookeeper $ ls # pid 파일 확인 $ stop_zookeeper $ cd /data/app_logs/zookeeper $ ls # pid 파일 삭제 확인
9. kafka 설치
# kafka 3.2.0 설치 $ wget https://archive.apache.org/dist/kafka/3.2.0/kafka-3.2.0-src.tgz $ tar -xzf kafka-3.2.0-src.tgz # 설정 수정 $ cd /kafka-3.2.0-src/config $ vi server.properties # kafka-01 broker.id=0 listeners=PLAINTEXT://:9092 advertised.listeners=PLAINTEXT://kafka-01:9092 zookeeper.connect=kafka-01:2181, kafka-02:2181, kafka-03:2181 # kafka-02 broker.id=1 listeners=PLAINTEXT://:9092 advertised.listeners=PLAINTEXT://kafka-02:9092 zookeeper.connect=kafka-01:2181, kafka-02:2181, kafka-03:2181 # kafka-03 broker.id=2 listeners=PLAINTEXT://:9092 advertised.listeners=PLAINTEXT://kafka-03:9092 zookeeper.connect=kafka-01:2181, kafka-02:2181, kafka-03:2181# alias 설정 $ cd ./kafka-3.2.0-src/config $ vi server.properties # 아래 내용 추가 alias start_kafka='/home/ec2-user/kafka-3.2.0-src/bin/kafka-server-start.sh -daemon /home/ec2-user/kafka-3.2.0-src/config/server.properties' alias stop_kafka='/home/ec2-user/kafka-3.2.0-src/bin/kafka-server-stop.sh -daemon /home/ec2-user/kafka-3.2.0-src/config/server.proper ties' # 적용 후 확인 $ source ~/.bashrc $ alias # 빌드 후 kafka 실행 $ ./gradlew jar -PscalaVersion=2.13.6 --parallel $ start_kafka빌드 시 속도가 너무 느린 문제가 발생한다면 swap메모리 설정해주자
https://velog.io/@seyoung755/AWS-EC2%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%B4-%EB%B0%B0%ED%8F%AC%ED%95%B4%EB%B3%B4%EC%9E%90-6-Swap-area-%EC%84%A4%EC%A0%95%ED%95%98%EA%B8%B0# 1번에서 프로듀서 실행 $ /home/ec2-user/kafka-3.2.0-src/bin/kafka-topics.sh --create --replication-factor 3 --partitions 2 --topic topic-A --bootstrap-server kafka-01:9092,kafka-02:9092,kafka-03:9092 # 다른 인스턴스에서 컨슈머 실행 $ /home/ec2-user/kafka-3.2.0-src/bin/kafka-topics.sh --list --bootstrap-server kafka-01:9092,kafka-02:9092,kafka-03:9092
출력확인
실시간으로 다른 브로커에서 출력되는것을 볼 수 있다!


참고

나의 개발기록