들어가기 앞서
이 글은 주니온 님의 운영체제 공룡책 강의(https://www.inflearn.com/course/운영체제-공룡책-전공강의/)를 수강하며 학습한 내용과 Siberschatz et. al. 의 저서「Operating System Concepts」를 정리한 글입니다. 모든 출처는 해당 강의 및 저서에 있습니다.
1. 개요
1.1 CPU 스케줄링(CPU-Scheduling)
멀티 프로그래밍을 가능하게 하는 운영 체제의 동작 기법
💡 멀티 프로그래밍(Multi-programming) = 다중 프로그래밍
- 다수의 작업(혹은 프로세스, 이하 태스크)이 중앙 처리 장치(이하 CPU)와 같은 공용자원을 나누어 사용하는 것
- CPU 작업과 입출력 작업을 병행하는 것
- Multi-processing, Multi-tasking 이라고도 함
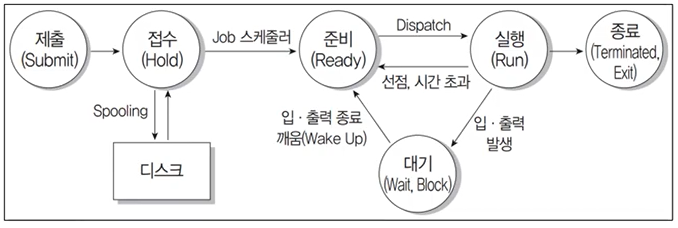
1.2 CPU 스케줄러(CPU-Scheduler)
Ready 상태의 프로세스 중에서 CPU에 어떤 프로세스를 할당할 것인지 결정하는 프로그램
1.3 선점 VS 비선점 스케줄링
✅ 선점(Preemptive) 스케줄링
프로세스가 스케줄러에 의해 CPU를 선점하는 방식 → 강제적
✅ 비선점(Non-preemptive) 스케줄링
- 프로세스가 자율적으로 반납할 때까지 CPU를 선점하는 방식
Terminate나Waiting상태로 전환되는 경우
1.4 스케줄링 결정 시점
| 상태 | 예시 | 방식 |
|---|---|---|
Running → Waiting | ◾ I/O 요청 ◾ wait() 요청을 통한 자식 프로세스 종료 | 비선점 |
Running → Ready | 인터럽트(interrupt) 발생 | 선점 or 비선점 |
Waiting → Ready | I/O 완료 | 선점 or 비선점 |
Terminate | 부모 프로세스 종료 | 비선점 |
선점 스케줄링이 효율적이므로 선점 스케줄링을 선택하는 것이 좋다.
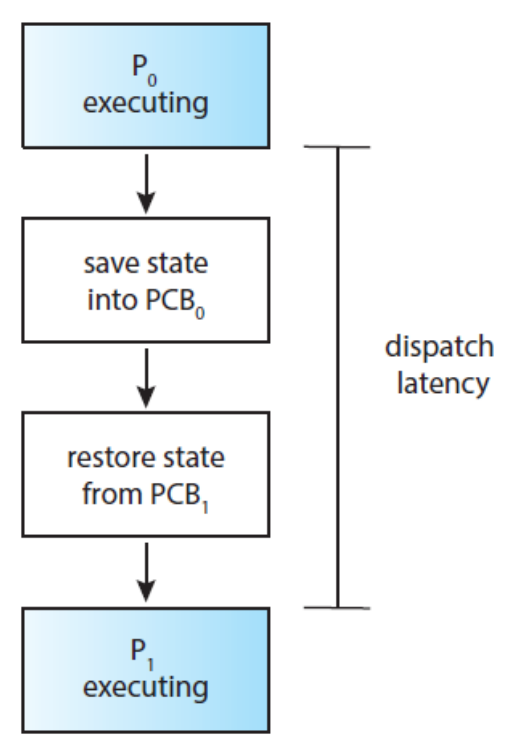
1.5 Dispatcher
-
CPU의 제어권을 CPU 스케줄러에 의해 선택된 프로세스에게 넘겨주는 모듈
-
일종의 Context Switch를 수행하는 모듈
💡 문맥 교환(Context Switch)
어떤 프로세스를 사용 중인 상태에서 다른 프로세스를 사용하기 위해, 이전의 프로세스의 상태(문맥)를 보관하고 새로운 프로세스의 상태를 적재하는 작업
-
기능
- 한 프로세스에서 다른 프로세스로 문맥 교환
- 커널 모드에서 유저 모드로 변경
💡 CPU Mode
- 유저 모드(User Mode)
- 응용 프로그램이 CPU를 사용할 때 수행되는 모드
- 어플리케이션 프로그램이 수행되는 모드
- 커널 모드(Kernel Mode)
- OS가 CPU를 사용할 때 수행되는 모드
- 프로그램이 수행되다가 인터럽트 걸려서 운영체제가 호출돼 수행되는 모드
- 유저 모드(User Mode)
- 사용자 프로그램의 재시작을 위해 해당 주소로 이동
-
문맥 교환이 일어날 때마다 호출 됨 → Dispatcher는 최대한 빨라야 한다.
💡 Dispatcher Latency
Dispatcher가 한 프로세스를 멈추고 다른 프로세스에게 CPU의 제어권을 넘기는 데 걸리는 시간
2. 평가 기준
| 항목 | 설명 | 목표 |
|---|---|---|
| CPU 사용률 (CPU Utilization) | 전체 시스템 시간 중 CPU가 작업을 처리하는 시간의 비율 | 최대화 |
| 처리량 (Throughput) | CPU가 단위 시간당 처리하는 프로세스의 개수 | 최대화 |
| 반환시간★ (Turnaround Time) | 프로세스가 시작해서 끝날 때까지 걸리는 시간 | 최소화 |
| 대기시간 ★★ (Waiting Time) | 프로세스가 준비 큐(Ready Queue)에서 대기한 시간의 총합 | 최소화 |
| 응답시간 (Response Time) | 요청 후 응답이 오기 시작할 때까지의 시간 | 최소화 |
3. Scheduling Algorithms
- 대기 시간(Waiting Time) = 마지막 작업 시작 시간 - 도착 시간
- 반환 시간(Turnaround Time) = 작업 종료 시간 - 도착 시간
3.1 FCFS Scheduling
- First Come First Served
- 먼저 자원 사용을 요청한 프로세스에게 자원을 할당해주는 방식
- 가장 간단한 CPU 스케줄링 알고리즘
✅ 대기 시간(Waiting Time) 계산
도착 시간은 모두 0초라고 가정한다.
🔎 도착 순서 : P1 → P2 → P3

- 프로세스 별 대기시간(Wating Time)
P1 = 0, P2 = 24, P3 = 27 - 총 대기시간(Total Wating Time)
0 + 24 + 27 = 51 - 평균 대기시간(Average Wating Time)
51 ÷ 3 = 17
🔎 도착 순서 : P2 → P3 → P1

- 프로세스 별 대기시간(Wating Time)
P1 = 6, P2 = 0, P3 = 3 - 총 대기시간(Total Wating Time)
6 + 0 + 3 = 9 - 평균 대기시간(Average Wating Time)
9 ÷ 3 = 3
✅ 반환 시간(Turnaround Time) 계산
🔎 도착 순서 : P1 → P2 → P3

- 프로세스 별 반환시간(Turnaround Time)
P1 = 24, P2 = 27, P3 = 30 - 총 반환시간(Total Turnaround Time)
24 + 27 + 30 = 81 - 평균 반환시간(Average Wating Time)
81 ÷ 3 = 27
🔎 도착 순서 : P2 → P3 → P1

- 프로세스 별 반환시간(Turnaround Time)
P1 = 30, P2 = 3, P3 = 6 - 총 반환시간(Total Turnaround Time)
30 + 3 + 6 = 39 - 평균 반환시간(Average Wating Time)
39 ÷ 3 = 13
🔥 참고
- FCFS는 비선점 스케줄링이다.
- 프로세스 별 점유 시간(Burst Time)의 차이가 큰 경우, 일반적으로 평균 대기시간이 최소가 아니며, 도착 순서에 따라 달라질 수 있다.
- 소요시간이 짧은 프로세스가 먼저 실행되도록 한 경우보다 성능이 떨어진다.
💡 호송 효과(Convoy Effect)
소요시간이 긴 프로세스가 먼저 도달하여 시간을 잡아먹고 있는 부정적인 현상
3.2 SJF Scheduling
- Shortest-Job-First = Shortest-next-CPU-burst-first
- CPU 점유 시간이 가장 짧은 프로세스에 CPU를 먼저 할당하는 방식
- 두 개 이상의 프로세스의 점유 시간이 같다면 FCFS 방식으로 처리
✅ 조건
- 도착 시간은 모두 0초라고 가정한다.
- 각 프로세스 별 점유시간은 다음과 같다.

✅ 대기 시간(Waiting Time) 계산
- 프로세스 별 대기시간(Wating Time)
P1 = 3, P2 = 16, P3 = 9, P4 = 0 - 총 대기시간(Total Wating Time)
3 + 16 + 9 + 0 = 28 - 평균 대기시간(Average Wating Time)
28 ÷ 4 = 7
✅ 반환 시간(Turnaround Time) 계산
- 프로세스 별 반환시간(Turnaround Time)
P1 = 9, P2 = 24, P3 = 16, P4 = 3 - 총 반환시간(Total Turnaround Time)
9 + 24 + 16 + 3 = 52 - 평균 반환시간(Average Wating Time)
52 ÷ 4 = 13
🔥 참고
-
최소 평균 대기 시간을 위해 최적화 된 스케줄링 알고리즘이다.
- 소요시간이 짧은 프로세스를 긴 프로세스보다 먼저 이동
→ 긴 프로세스의 대기 시간 증가량 > 짧은 프로세스의 대기 시간 감소량
∴ 평균 대기 시간 감소
- 소요시간이 짧은 프로세스를 긴 프로세스보다 먼저 이동
-
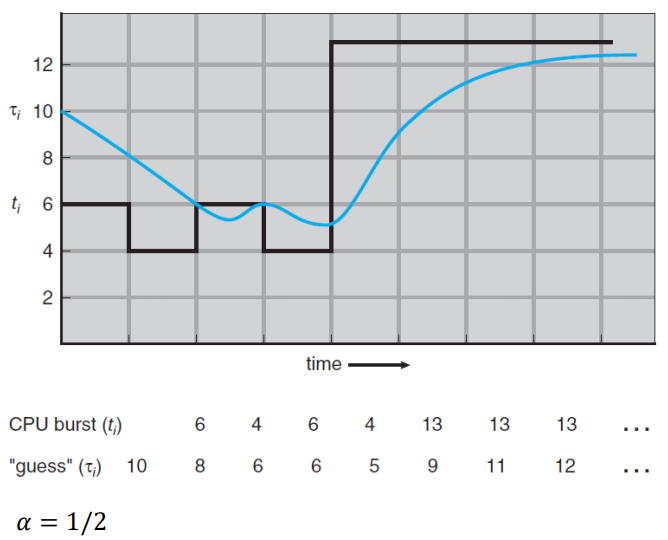
다음 CPU의 소요시간을 알 수 있는 방법이 없으므로 SJF는 현실성이 떨어진다.
→ 측정된 과거의 CPU 소요시간의 지수 이동 평균(Exponential Moving Average)으로 다음 CPU 소요시간 예측- 가중변수를 이용하여 최근 수치의 영향력은 높이고 과거 수치의 영향력은 낮춤
- 이동 평균이 가격변화를 보다 즉각적으로 반영하도록 하고 평균선의 움직임을 평활하게 해줌
💡 이동 평균(Moving Average)
전체 데이터 집합의 여러 하위 집합에 대한 일련의 평균을 만들어 데이터 요소를 분석하는 계산
- 계산식

- 예시
-
SJF는 선점 스케줄링과 비선점 스케줄링 모두 가능하다.
→ 선점 스케줄링이 더 효율적임- 조건
- Burst Time : P0 = 5, P1 = 1
- P0가 CPU 선점(작업 수행) 중일 때
- 선점 스케줄링 : P0의 작업을 멈추고 작업시간이 더 짧은 P1 먼저 수행 후 P0 나머지 작업 수행
- 비선점 스케줄링 : P0가 작업이 끝날 때까지 대기했다가 P1 수행
- 조건
3.3 SRTF Scheduling
- Shortest-Remaining-Time-First
- 선점 SJF 스케줄링
- 현재 작업 중인 프로세스를 중단시키고 새로 들어온 프로세스의 처리를 시작하는 방식
✅ 조건
1. SRTF Scheduling

2. 비선점 SJF Scheduling
도착 시간 및 소요 시간(Burst Time)은 위와 같다.

✅ 대기 시간(Waiting Time) 계산
🔎 SRTF Scheduling
- 프로세스 별 대기시간(Wating Time)
- P1 = 10 - 1 = 9
- P2 = 1 - 1 = 0
- P3 = 17 - 2 = 15
- P4 = 5 - 3 = 2
- 총 대기시간(Total Wating Time)
9 + 0 + 15 + 2 = 26 - 평균 대기시간(Average Wating Time)
26 ÷ 4 = 6.5
🔎 비선점 SJF Scheduling
- 프로세스 별 대기시간(Wating Time)
- P1 = 0
- P2 = 8 - 1 = 7
- P3 = 17 - 2 = 15
- P4 = 12 - 3 = 9
- 총 대기시간(Total Wating Time)
0 + 7 + 15 + 9 = 31 - 평균 대기시간(Average Wating Time)
31 ÷ 4 = 7.75
✅ 반환 시간(Turnaround Time) 계산
🔎 SRTF Scheduling
- 프로세스 별 반환시간(Turnaround Time)
- P1 = 17 - 0 = 17
- P2 = 5 - 1 = 4
- P3 = 26 - 2 = 24
- P4 = 10 - 3 = 7
- 총 반환시간(Total Turnaround Time)
17 + 4 + 24 + 7 = 52 - 평균 반환시간(Average Wating Time)
52 ÷ 4 = 13
🔎 비선점 SJF Scheduling
- 프로세스 별 반환시간(Turnaround Time)
- P1 = 8
- P2 = 12 - 1 = 11
- P3 = 26 - 2 = 24
- P4 = 17 - 3 = 14
- 총 반환시간(Total Turnaround Time)
8 + 11 + 24 + 14 = 57 - 평균 반환시간(Average Wating Time)
57 ÷ 4 = 14.25
3.4 RR(Round-Robin) Scheduling
-
시분할 선점 FCFS 스케줄링
-
스케줄러가 준비 대기열을 돌아다니며 프로세스들 사이에 우선순위를 두지 않고 순서대로 시간단위로 CPU를 할당하는 방식
💡 시간 단위(Time Quantum, Time Slice)
프로세스에게 할당되는 최대 CPU 시간
-
준비 대기열(Ready Queue)는 원형 큐(Circular Queue)의 형태로 구현된다.
✅ 동작 방식
-
프로세스가 시간 단위 미만의 CPU burst를 가지는 경우
- 프로세스가 자율적으로 반납
- 스케줄러가 Ready Queue의 다음 프로세스 진행
-
프로세스가 시간 단위를 초과한 CPU burst를 가지는 경우
- 타이머 종료 및 OS에 interrupt 발생
- 문맥 교환(context switch) 실행
- 프로세스가 준비 대기열의 맨 뒤에 위치
✅ 조건
- 도착 시간은 모두 0초로 가정한다.
- Burst Time은 다음과 같다.
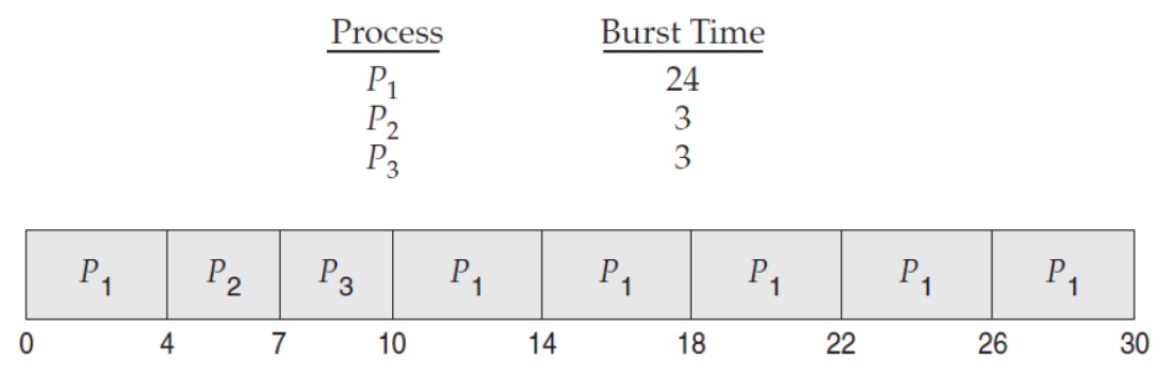
- 시간 단위(Time Quantum)는 4ms로 가정한다.
✅ 대기 시간(Waiting Time) 계산
- 프로세스 별 대기시간(Wating Time)
- P1 = 10 - 4 = 6
- P2 = 4
- P3 = 7
- 총 대기시간(Total Wating Time)
6 + 4 + 7 = 17 - 평균 대기시간(Average Wating Time)
17 ÷ 3 = 5.66
✅ 반환 시간(Turnaround Time) 계산
- 프로세스 별 반환시간(Turnaround Time)
- P1 = 30
- P2 = 7
- P3 = 10
- 총 반환시간(Total Turnaround Time)
30 + 7 + 10 = 47 - 평균 반환시간(Average Wating Time)
47 ÷ 3 = 15.66
🔥 참고
-
평균 대기 시간이 종종 긴 스케줄링 알고리즘이다.
-
RR는 선점 스케줄링이다.
→ 프로세스의 Burst Time이 시간 단위를 초과하는 경우, 해당 프로세스는 준비 대기열(Ready Queue)로 돌아가게 된다. -
성능은 시간 단위의 크기에 따라 결정된다.
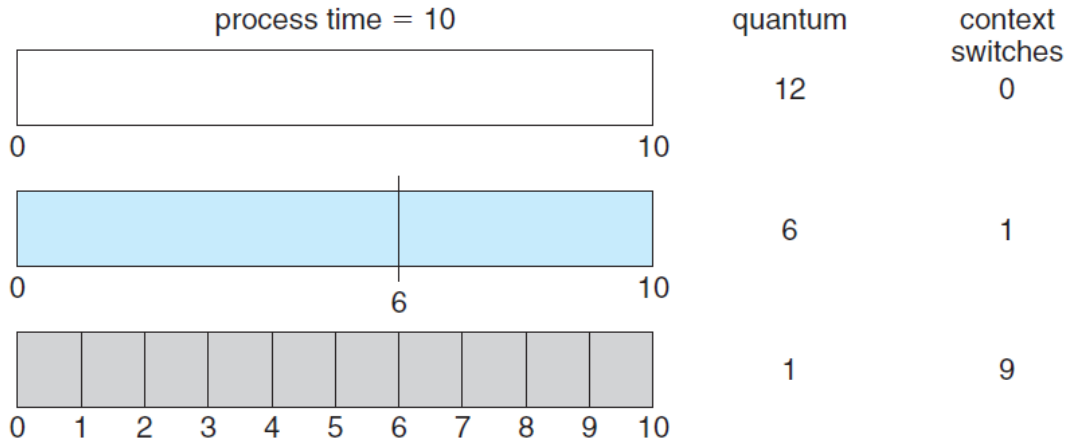
- 시간 단위(Quantum)의 크기 조절의 필요성
- 문제점 : context switch → dispatch latency 발생(성능 저하)
- 해결 방안
- context switch의 횟수가 적을수록 좋음
- quantum의 크기는 process time에 맞추어 적당히 조절
→ 너무 클 경우 FCFS가 됨
- 시간 단위에 따라 달라지는 반환 시간
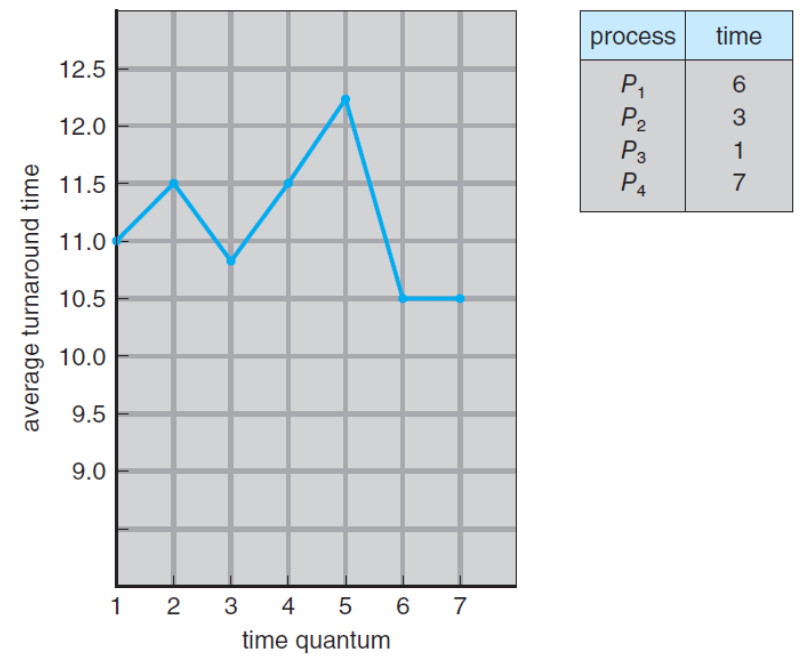
- 시간 단위(Quantum)의 크기 조절의 필요성
3.5 Priority-base Scheduling
- 우선 순위가 가장 높은 프로세스에 CPU를 할당하는 방식
- 각 프로세스에 우선 순위가 연결되어 있음
- 우선 순위가 같은 프로세스 → FCFS 순서로 스케줄링
- SJF : 우선 순위 기반 스케줄링의 특별 케이스
→ 우선 순위 = 다음(predicted) CPU Burst의 역순
∴ 낮은 숫자 = 높은 우선 순위
✅ 조건
도착 시간은 모두 0초로 가정한다.
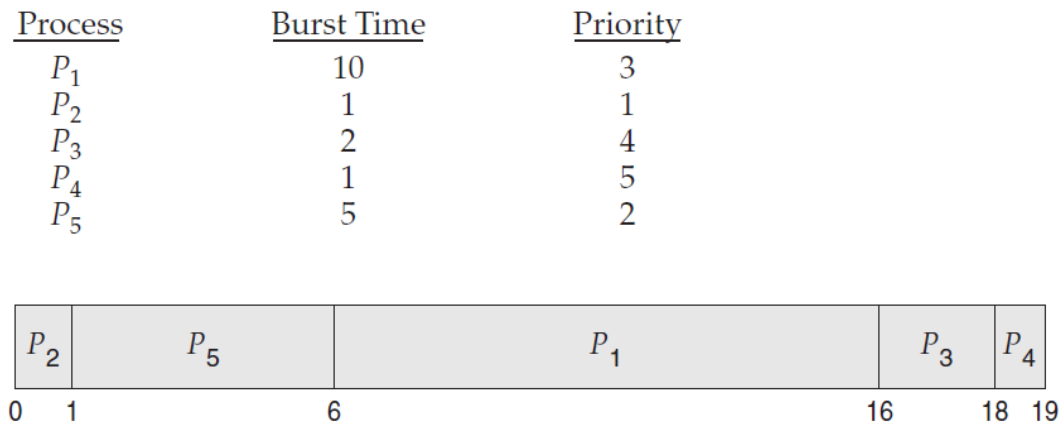
✅ 대기 시간(Waiting Time) 계산
- 프로세스 별 대기시간(Wating Time)
P1 = 6, P2 = 0, P3 = 16, P4 = 18, P5 = 1 - 총 대기시간(Total Wating Time)
6 + 0 + 16 + 18 + 1 = 41 - 평균 대기시간(Average Wating Time)
41 ÷ 5 = 8.2
✅ 반환 시간(Turnaround Time) 계산
- 프로세스 별 반환시간(Turnaround Time)
P1 = 16, P2 = 1, P3 = 18, P4 = 19, P5 = 6 - 총 반환시간(Total Turnaround Time)
16 + 1 + 18 + 19 + 6 = 60 - 평균 반환시간(Average Wating Time)
60 ÷ 5 = 12
🔥 참고
- Priority-base는 선점 스케줄링과 비선점 스케줄링 모두 가능하다.
- 선점 스케줄링 : SRTF
- 비선점 스케줄링 : SJF
- 기아(Starvation) 문제 = 무한 대기(Indefinite Blocking)
- 차단된 프로세스 : 실행할 준비가 됐지만 선점된 CPU를 기다림
- 우선 순위가 낮은 일부 프로세스의 경우 무기한 대기 가능성 존재
- 해결 방안 → "에이징(Aging)"
💡 에이징(Aging)
시스템에서 오랫동안 대기하는 프로세스의 우선순위를 점차 높이는 기법
3.6 MLQ Scheduling
- Multi-Level Queue
- 우선순위에 따라 준비 큐(Ready Queue)를 여러 개 사용하는 방식
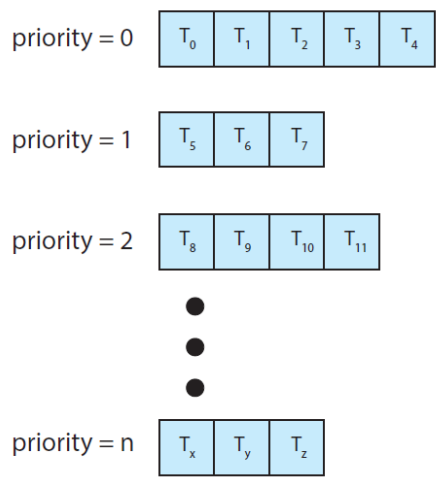
- 우선순위가 높은 큐에 CPU 먼저 할당
- 큐에 속한 모든 프로세스가 처리된 후 다음 우선순위 큐 실행
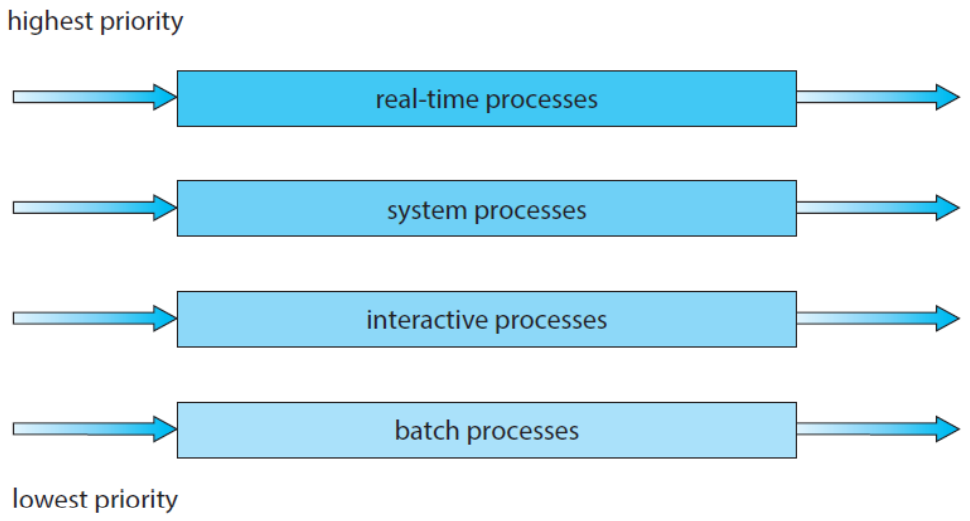
- 선점 스케줄링 알고리즘
- Priority-base와 마찬가지로 기아문제가 존재함
3.7 MLFQ Scheduling
- Multi-Level Feedback Queue
- MLQ를 보완한 방식
- Ready Queue 간 승격/강등의 개념이 존재 → 프로세스의 큐 이동 가능
- 우선순위에 따라 나뉜 Ready Queue에 우선순위를 맞춰 시간 할당
- 할당된 시간 안에 수행 x
- 우선순위 하락
- 다음 큐로 강등
- 모든 프로세스가 첫 번째 Ready Queue에 놓인 후 수행
- 우선순위가 낮은 큐에 타임 슬라이스 크기를 크게 할당
→ 우선순위 낮은 CPU를 오랫동안 사용(보완)
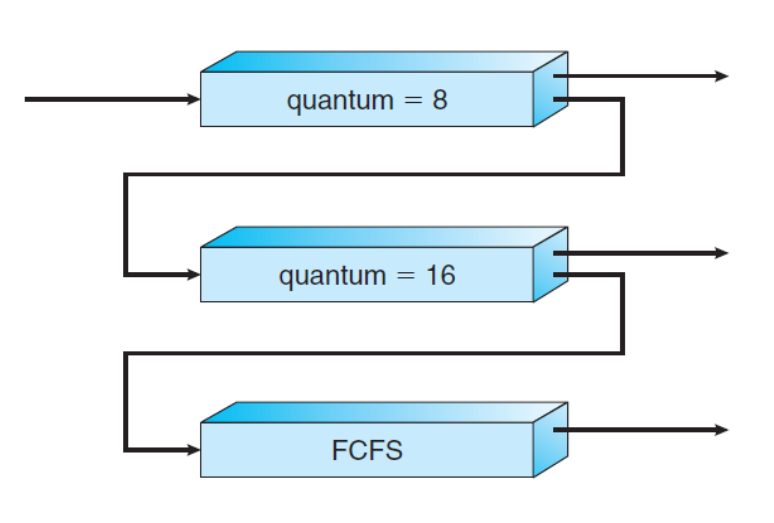
4. Thread Scheduling
- 대부분의 최신 운영 체제에서 스케줄링 되는 것은 프로세스가 아니라 커널 스레드(Kernel threads)이다.
- 사용자 스레드(User threads)는 스레드 라이브러리에 의해 관리된다.
- 커널이 인식하지 못함
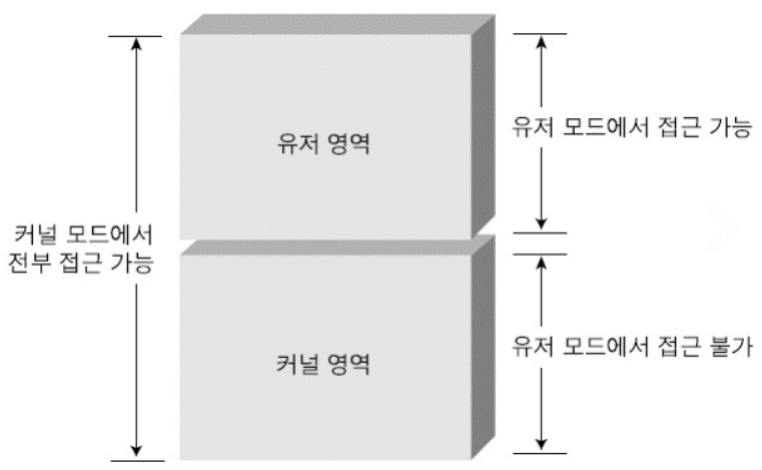
- 연관된 커널 스레드에 매핑됨
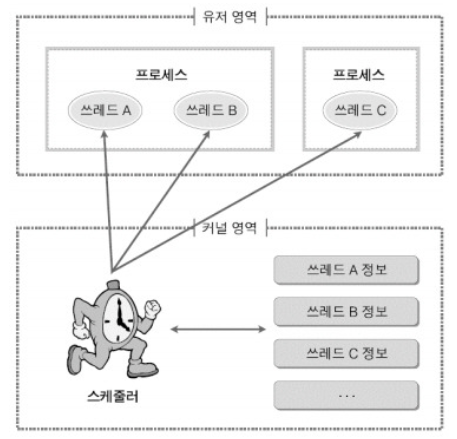
- 커널이 인식하지 못함
5. Real-Time CPU Scheduling
실시간(Real-Time) 운영 체제에서의 스케줄링은 다음과 같이 구분할 수 있다.
💡 실시간 운영체제(Real-Time Operating System, RTOS)
제한된 시간 내에 원하는 작업을 처리하는 것을 보장하는 운영 체제
5.1 Soft Real-Time
- 중요한 실시간 프로세스가 언제 예약되는지에 대해 보장하지 않는다.
- 중요한 프로세스가 중요하지 않은 프로세스보다 선호된다는 점만 보장한다.
ex) 전화기 : 통화 중 음성 끊김
5.2 Hard Read-Time
- 요구 사항이 더 엄격하다.
- 업무는 마감 기한까지 완료되어야 한다.
ex) 우주선 : 조금만 잘못 계산해도 궤도가 달라짐
📖 참고

깔끔하게 정리 잘 돼있네요!! 잘읽었습니다!! :D