
강의 - 코딩 초보자를 위한 파이썬(Python) 입문(Beginner)
이번 유데미 파이썬 기초 강의 정리에서는
헷갈렸거나 다시 볼 필요가 있을 내용 위주로만 정리해보았다.
1. 파이썬의 소개
파이썬의 기원과 특징
귀도 반 로섬이 크리스마스 주중에 취미로 개발
쉬운 언어, 단순함, 효율성, 가독성, 확장성
파이썬의 주목성
구글, 인스타그램, 넷플릭스, 유튜브 등 유명 기업들에서 파이썬으로 개발.
인공지능, ai, 업무 자동화, 사물 인터넷, 데이터 분석, 웹크롤링/스크래핑, 웹프로그래밍, C/C++과 연동
*참고: alt+방향키로 해당 코드 줄을 올렸다가 내렸다가 할 수 있음.
2. 자료형과 변수
이스케이프 문자
: 이스케이프 기호인 백슬래시() 뒤에 문자를 적는다.
\ : 백슬래시
\n : 개행 문자 (다음 행으로 바꿈)
\r : 개행 문자 (커서를 앞으로 이동)
\t : 탭 문자
\' : 작은 따옴표 (작은 따옴표 안에서 작은 따옴표를 쓰고 싶을 때 씀)
\" : 큰 따옴표 (큰 따옴표 안에서 큰 따옴표를 쓰고 싶을 때 씀)
boolean 자료형
참/ 거짓을 나타내는 자료형
print (3 > 4) # 거짓 false
print (3 < 4) # 참 True
print (not(3 > 4)) # 거짓 --> 부정 --> 참
# is_highschool = age>=17 -> 이렇게 조건을 변수에 넣어주는 것도 가능변수
: 공간을 주고, 그 공간 안에 값을 집어 넣어주는 것을 의미
3. 연산과 문자열 슬라이싱
##### 논리 연산 #####
# and 연산
print (1>2) and (2>3) # False
# --> and는 두 연산자가 모두 True인 경우에만 True 보여줌
print (1>2 & 2>3) # 두 연산자 간의 and 연산 진행
# or 연산
print (1<2) or (2<3) # True
# --> or 연산은 두 연산자가 모두 false 경우에만 false 값을 보여줌
print (1<2 | 2>3) # 두 연산자 간의 or 연산 진행
##### 랜덤한 값 구하기 #####
from random import *
print (random()) # 0.0부터 1.0미만의 실수가 나옴.
print (int(random()*10)) # 정수로 바꾸는 방법
print (int(random()*10)+1) # 1부터 10까지의 랜덤한 숫자
print (randint(1,10)) # 1부터 10이하의 랜덤한 숫자
##### 포맷 #####
a = "파이썬님의 무게는 70.5kg입니다."
name = "파이썬"
weight = 70.544
print( name + "님의 무게는 "+ str(weight) +"kg입니다.")
print("%s님의 무게는 %0.1fkg입니다"%(name, weight))
# %d = 정수 %s = 문자 %f = 실수형을 의미합니다.
print("%s님의 무게는 %skg입니다."% (name,weight))
print("{}님의 무게는 {:0.1f}kg 입니다.".format(name, weight))
print("{name}님의 무게는 {weight}kg 입니다.".format(name="자바", weight=60.8))
# 문자열 관련 함수
# find, index, count, upper, lower, strip, replace, split, len
word = 'apple'
print(word.find('p')) # 단어를 쭉 보다가 제일먼저 발견된 인덱스의 번호를 출력 1
print(word.count('p')) # 단어를 보다가 p라는 것이 값에 몇개 있는지 출력 해라.
print(word.index('p')) # 단어를 쭉 보다가 제일먼저 발견된 인덱스의 번호를 출력 1 # find
print(len(word)) # 값의 길이를 나타내주는 것
print(word.upper()) # 소문자를 대문자로
print(word[0].upper()) # 0번째 인덱스의 문자를 대문자로 바꿔라.
word = ' APPLE '
print(word.lower()) # 대문자를 소문자로 바꿔라
print(word.strip()) # 공백 삭제
word = 'my name is python'
print(word.replace('python', 'effino')) # 파이썬을 에피노로 바꿔라
print(word.split()) # 문자열을 단어 단위로 쪼개서 보여줍니다. 4. 리스트와 튜플 그리고 사전
##### 리스트 자료형의 함수 #####
list1 = [1,2,3,4,5]
list1.append(6)
print(list1)
list1.insert(2, 7) # 원하는 index 위치에 해당 value를 추가.
print(list1)
list1.extend([6,7,8,9,0]) # 리스트 끝에 입력한 iterable 자료형의 모든 항목을 넣음.
# append와 다른 점은 괄호( ) 안에는 iterable 자료형만 올 수 있다는 것.
list1 += [6,7,8,9,0]
# +를 사용하면 리스트 a의 값이 변하는 것이 아니라
# 두 리스트가 더해진 새로운 리스트가 반환됨.
# extend를 사용하면 리스트 a의 주소 값이 변하지 않고 유지됨
list1.pop(0) # 리스트에서 해당 인덱스를 제거
print(list1)
print(list1.pop(0))
print(list1)
list1.remove(4) # 리스트에서 해당 value를 제거
list1.clear() # 리스트의 모든 요소 제거
print(list1.count(3))
list1.extend([1,2,3,4,5])
list1.reverse()
print(list1)
list1.sort()
print(list1)
##### 리스트 다중 리스트 #####
list1 = [1,2,3,4,5,[1,2,3,4,5,[1,2,3,4,5]]]
print(list1[5][0])
print(list1[5][5][0])
##### 집합 자료형 #####
# set 동일한 값은 하나로 취급 (중복된값).
# set1 = set("hello hellen")
# print(set1)
# list1 = list(set1)
# print(list1)
# 리스트로 변환을 해서 인덱싱이나 슬라이싱 가능.
# 교집합 / 합집합 / 차집합
set1 = set([1,2,3,4])
set2 = set([3,4,5,6])
# 합집합을 구하는 공식
print(set1 | set2)
print(set1.union(set2))
# 차집합을 구하는 공식
print(set1 - set2)
print(set1.difference(set2))
# 교집합을 구하는 공식
print(set1 & set2)
print(set1.intersection(set2))
# 집합 자료형의 함수
set1.add(5)
print(set1)
set2.update([1,2])
print(set2)
set1.remove(5)
print(set1)5. 조건문과 반복문
# 구구단
for i in range(2,10) :
print("-----{}단 시작!-----".format(i))
for j in range(1,10) :
print("{} X {} = {}".format(i, j, i*j))6. input과 여러가지 입출력 방법
# 추가
##### 다양한 입출력 #####
# 문자열 사이에 sep으로 지정한 문자열이 끼워 넣어져 출력됨.
# 즉, sep은 구분자.
# end 를 사용하면 그 다음의 출력값과 이어서 출력함.
# 파이썬은 기본적으로 print() 하면 자동 개행이 되므로, 이를 무시하고 싶을 때 자주 사용
print("에피노", "자바", "파이썬", sep="vs") # 에피노vs자바vs파이썬
print("뭘할래?" + "축구", "야구", "농구", sep = "vs", end="?") # 뭘할래?축구vs야구vs농구?
##### 오른쪽 정렬(rjust) 왼쪽 정렬(ljust) #####
# 전체 글자 개수에서 남는 공백의 개수만큼 공백을 넣어준다.
# 이때 ljust는 문자열을 먼저 왼쪽으로 보내준 뒤 남은 자리에 공백이 들어가고,
# rjust는 문자열을 오른쪽으로 보내준 뒤 남은 자리에 공백이 들어감.
menu = {"김밥" : 3000, "순대" : 2000, "라면" :4500 }
for menu1, pey in menu.items():
# print(menu1,pey)
print(menu1.ljust(5), str(pey).rjust(10), sep=":")
# 김밥 : 3000
# 순대 : 2000
# 라면 : 4500
##### zfill #####
# 해당 문자열의 전체 개수에서 부족한 공백 개수만큼 해당 문자열의 앞에서부터 0을 채워줌
# 문자열.zfill(전체 개수)
num = 0
while num <= 10 :
print("대기번호 : "+ str(num).zfill(5))
num += 1
##### 3자리마다 콤마 1,000원 #####
print("내월급 : {0:,}원".format(2000000))
print("내자산 : {0:+,}원".format(2000000))
##### 정렬 #####
print("{0: >5}".format(10)) # 10을 일단 오른쪽으로 보낸 후 정렬 (그래서 10 앞에 3칸 띄어진 모습인 ' 10'이 출력됨)
print("{0: <5}".format(10))
print("{0: >+5}".format(10))
print("{0: >+5}".format(-10))
##### 빈칸채우기 #####
print("{0:*>10}".format(10)) # ********10
print("{0:*<10}".format(10)) # 10********-
정리:
"{<인덱스>:<채우려는문자><정렬방향><전체길이>}".format(이를적용시킬자료형변수->이는문자열로바뀌는듯)' -
이해를 위한 참고 그림
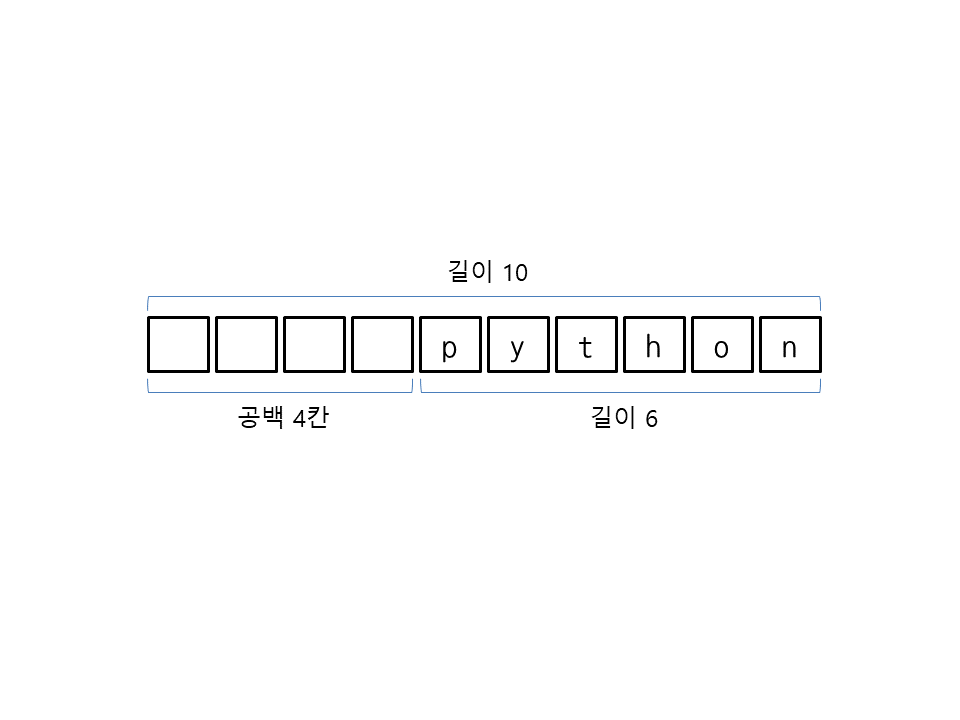
7. 함수
# 함수
def sum (a,b) :
result = a+b
return result
print(sum (1,2))
# 결과값이 없을 수도 있음.
def bank_open(name) :
print("%s님의 계좌가 개설되었습니다."%name)
bank_open("에피노")
# 입력값이 없는 함수
def hello_bank() :
print("안녕하세요. 에피노뱅크입니다.")
hello_bank()
# 초기값도 미리 설정할 수 있음.
def bank_open(name, bank_num, open=True):
if open == True :
print("%s님의 계좌가 개설되었습니다."%name)
print("%s님의 계좌번호는 %s입니다."%(name, bank_num))
else :
print("%s님의 계좌 개설이 거부되었습니다."%name)
bank_open("에피노", "010-1111-1111")
# lambda 함수
def add(a,b):
return a+b
print(add(1,2))
add = lambda a,b : a+b # 함수와 똑같은 역할.
print(add(1,2))
list1 = [lambda a,b :a+b, lambda a,b : a/b] # 리스트에 추가가 가능. def같은 함수는 리스트에 추가가 불가능
print(list1[1](2,1))본 후기는 정보통신산업진흥원(NIPA)에서 주관하는 <AI 서비스 완성! AI+웹개발 취업캠프 - 프론트엔드&백엔드> 과정 학습/프로젝트/과제 기록으로 작성 되었습니다.

유후랄라 개발일기