작년에 했던 포켓몬 이미지 생성 프로젝트!
깃허브에 코드만 저장해 놨었는데 글로 정리해놓고 싶기도 하고 파이토치 코드도 다시 복기하면서 공부할 겸 써본다.
DCGAN
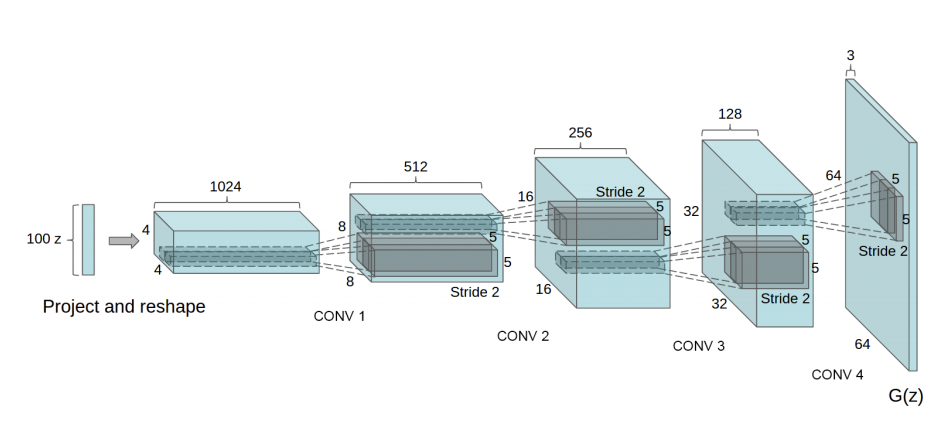
DCGAN은 Deep Convolutional Generative Adversarial Network의 약자로, 기존 Vanilla GAN에 Convolution Layer를 적용시켜 개선한 모델이다.
가장 큰 특징은 기존 Vanilla GAN의 Fully-Connected Layer를 제거하고 Convolution Layer를 추가했다는 것인데,
이를 통해 Vanilla GAN의 문제점이었던 학습의 불안정성을 상당히 개선해 안정적인 학습이 가능해졌다.
포켓몬 이미지 생성

캐글의 포켓몬 이미지 데이터셋을 사용했다.
생성 과정을 먼저 보이자면 이렇다.
이것이 Input 이미지 샘플
노이즈로부터 시작해 Input과 비슷한 이미지를 만들어가는 과정
좀 더 고화질의 그럴듯한 이미지를 생성하려면 다른 모델을 사용해야 한다.
일단 DCGAN으로 이정도 생성한 것에 만족한다🙃
pakage import
import os
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import ImageFolder
import torchvision.transforms as tt
from torch.utils.data import DataLoader
from torchvision.utils import make_grid,save_image
import cv2
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
%matplotlib inlineDataset
path = "/content/drive/MyDrive/pokemon_ds" # customize your image folder path
os.listdir(path)
image_size = 64
batch_size = 64
stats = (0.5, 0.5, 0.5), (0.5, 0.5, 0.5)
train_ds = ImageFolder(path,transform=tt.Compose([
tt.Resize(image_size),
tt.CenterCrop(image_size),
tt.ToTensor(),
tt.Normalize(*stats),
tt.RandomHorizontalFlip(p=0.5)
]))
train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=3, pin_memory=True)
def denorm(img_tensors):
return img_tensors * stats[1][0] + stats[0][0]
def show_images(images, nmax=64):
fig, ax = plt.subplots(figsize=(8, 8))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(denorm(images.detach()[:nmax]), nrow=8).permute(1, 2, 0))
def show_batch(dl, nmax=64):
for images, _ in dl:
show_images(images, nmax)
breakshow_batch(train_dl)
Device 설정
def get_default_device():
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
def to_device(data,device):
if isinstance(data,(list,tuple)):
return [to_device(x,device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
def __init__(self,dl,device):
self.dl = dl
self.device = device
def __iter__(self):
for b in self.dl:
yield to_device(b,device)
def __len__(self):
return len(self.dl)
device = get_default_device()
deviceDiscriminator
train_dl = DeviceDataLoader(train_dl, device)
discriminator = nn.Sequential(
nn.Conv2d(3,64,kernel_size=4,stride=2,padding=1,bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(64,128,kernel_size=4,stride=2,padding=1,bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(128,256,kernel_size=4,stride=2,padding=1,bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(256,512,kernel_size=4,stride=2,padding=1,bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2,inplace=True),
nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=0, bias=False),
nn.Flatten(),
nn.Sigmoid()
)discriminator = to_device(discriminator,device)Generator
latent_size = 128
generator = nn.Sequential(
nn.ConvTranspose2d(latent_size,512,kernel_size=4,stride=1,padding=0,bias = False),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(512,256,kernel_size=4,stride=2,padding=1,bias = False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256,128,kernel_size=4,stride=2,padding=1,bias = False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128,64,kernel_size=4,stride=2,padding=1,bias = False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64,3,kernel_size=4,stride=2,padding=1,bias = False),
nn.Tanh()
)Noise 생성
xb = torch.randn(batch_size, latent_size, 1, 1) # random latent tensors
fake_images = generator(xb)
print(fake_images.shape)
show_images(fake_images)
generator = to_device(generator,device)Train_Discriminator
def train_discriminator(real_images, opt_d):
# Clear discriminator gradients
opt_d.zero_grad()
# Pass real images through discriminator
real_preds = discriminator(real_images)
# real_targets = torch.ones(real_images.size(0), 1, device=device)
real_targets = torch.cuda.FloatTensor(real_images.size(0), 1).fill_(0.9)
real_loss = F.binary_cross_entropy(real_preds, real_targets)
real_score = torch.mean(real_preds).item()
# Generate fake images
latent = torch.randn(batch_size, latent_size, 1, 1, device=device)
fake_images = generator(latent)
# Pass fake images through discriminator
# fake_targets = torch.zeros(fake_images.size(0), 1, device=device)
fake_targets = torch.cuda.FloatTensor(fake_images.size(0), 1).fill_(0.1)
fake_preds = discriminator(fake_images)
fake_loss = F.binary_cross_entropy(fake_preds, fake_targets)
fake_score = torch.mean(fake_preds).item()
# Update discriminator weights
loss = real_loss + fake_loss
loss.backward()
opt_d.step()
return loss.item(), real_score, fake_scoreTrain_Generator
def train_generator(opt):
opt.zero_grad()
latent = torch.randn(batch_size,latent_size,1,1,device=device)
fake_images = generator(latent)
preds = discriminator(fake_images)
targets = torch.ones(batch_size,1,device = device)
loss = F.binary_cross_entropy(preds,targets)
loss.backward()
opt.step()
return loss.item()Sample 저장
sample_dir = '/content/drive/MyDrive/generated'
os.makedirs(sample_dir, exist_ok=True)def save_samples(index, latent_tensors, show=True):
fake_images = generator(latent_tensors)
fake_fname = '{0:0=4d}.png'.format(index)
save_image(denorm(fake_images), os.path.join(sample_dir, fake_fname), nrow=8)
print('Saving', fake_fname)
if show:
fig, ax = plt.subplots(figsize=(8, 8))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(fake_images.cpu().detach(), nrow=8).permute(1, 2, 0))fixed_latent = torch.randn(64, latent_size, 1, 1, device=device)save_samples(0, fixed_latent)
Training
def fit(epochs, lr, start_idx=1):
torch.cuda.empty_cache()
# Losses & scores
losses_g = []
losses_d = []
real_scores = []
fake_scores = []
# Create optimizers
opt_d = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
opt_g = torch.optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))
for epoch in range(epochs):
for real_images, _ in train_dl:
# Train discriminator
loss_d, real_score, fake_score = train_discriminator(real_images, opt_d)
# Train generator
loss_g = train_generator(opt_g)
# Record losses & scores
losses_g.append(loss_g)
losses_d.append(loss_d)
real_scores.append(real_score)
fake_scores.append(fake_score)
# Log losses & scores (last batch)
print("Epoch [{}/{}], loss_g: {:.4f}, loss_d: {:.4f}, real_score: {:.4f}, fake_score: {:.4f}".format(
epoch+1, epochs, loss_g, loss_d, real_score, fake_score))
# Save generated images
save_samples(epoch+start_idx, fixed_latent, show=False)
return losses_g, losses_d, real_scores, fake_scoreslr = 0.0002
epochs = 1000
history = fit(epochs, lr)
Result
losses_g, losses_d, real_scores, fake_scores = historyfrom IPython.display import Image
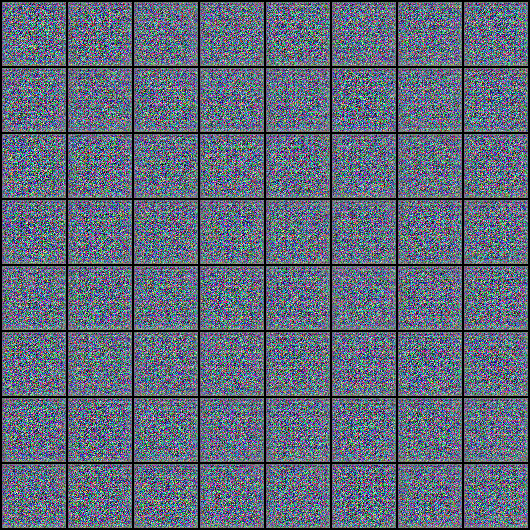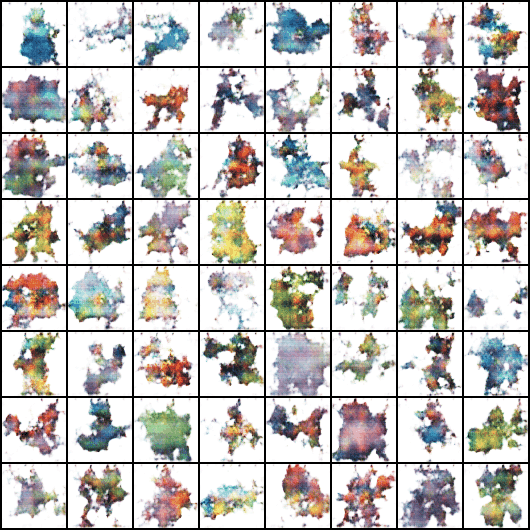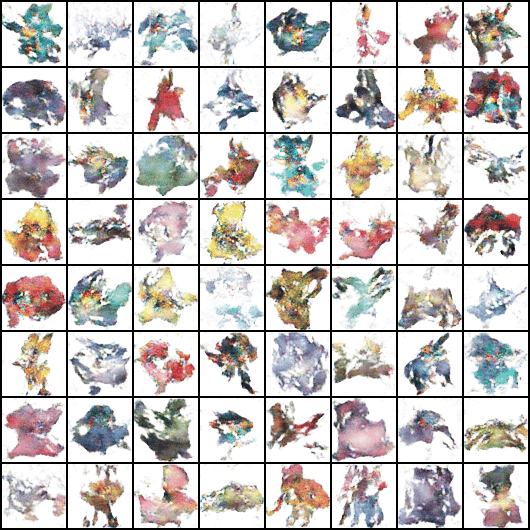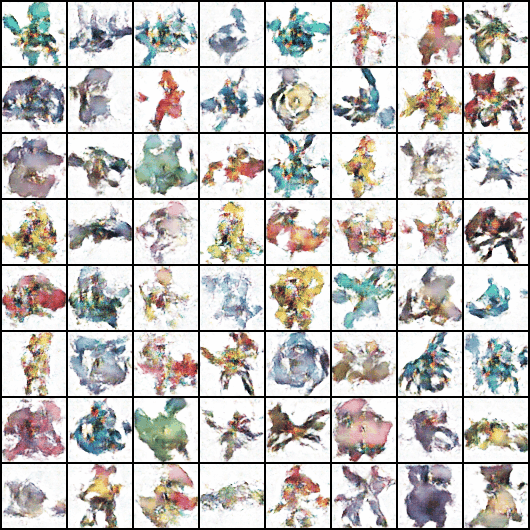
Image('/content/drive/MyDrive/generated/0999.png')
최종 생성된 이미지!
plt.plot(losses_d, '-')
plt.plot(losses_g, '-')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['Discriminator', 'Generator'])
plt.title('Losses');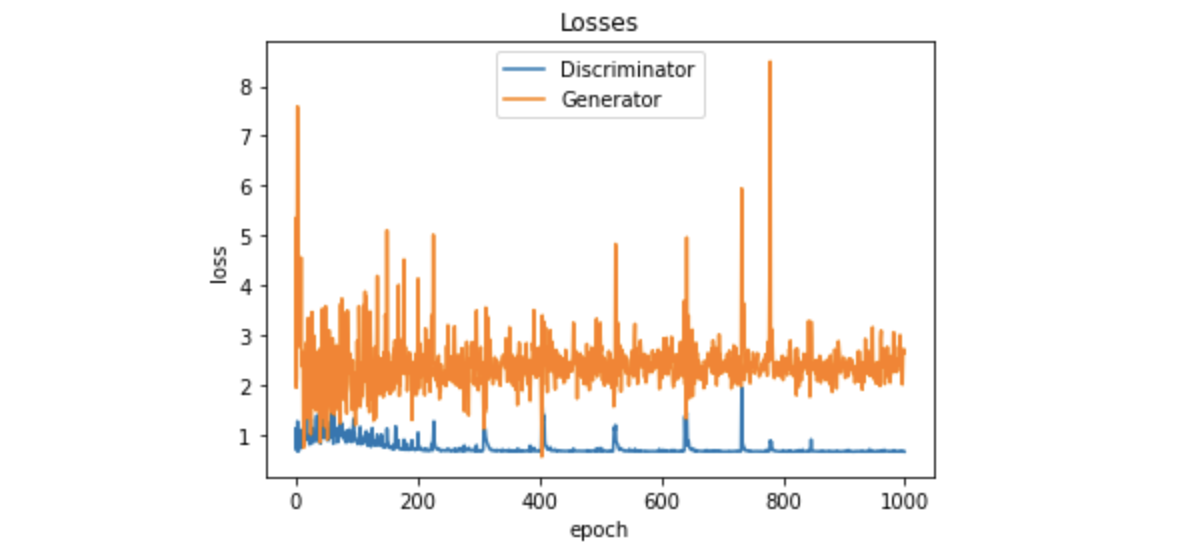
plt.plot(real_scores, '-')
plt.plot(fake_scores, '-')
plt.xlabel('epoch')
plt.ylabel('score')
plt.legend(['Real', 'Fake'])
plt.title('Scores');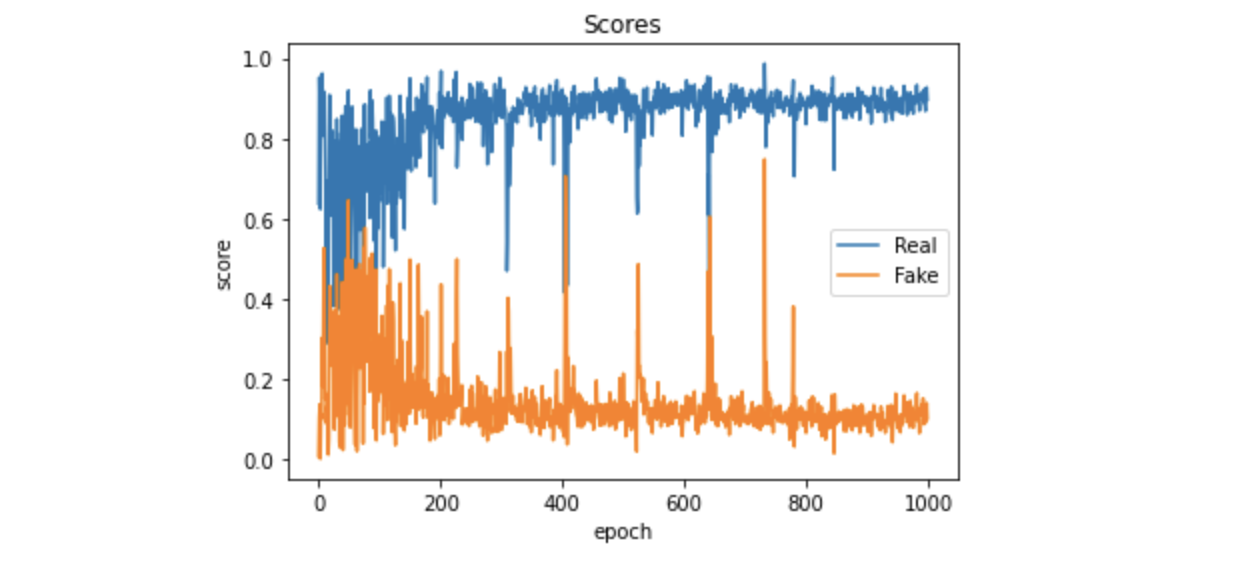

중요한 것은 꺾이지 않는 런타임
좋은 내용 공유해주셔서 감사합니다!
올리신 코드를 보면서 궁금한 점이 있는데 64x64 사이즈가 아니고 이보다 크게 하려면 코드에서 어떤걸 바꾸면 되나요?? image_size 와 batch_size를 각각 100으로 바꾸는 것 말고 generator 와 discriminator 도 바꿔줘야하는 부분이 있는지 궁금하네요!