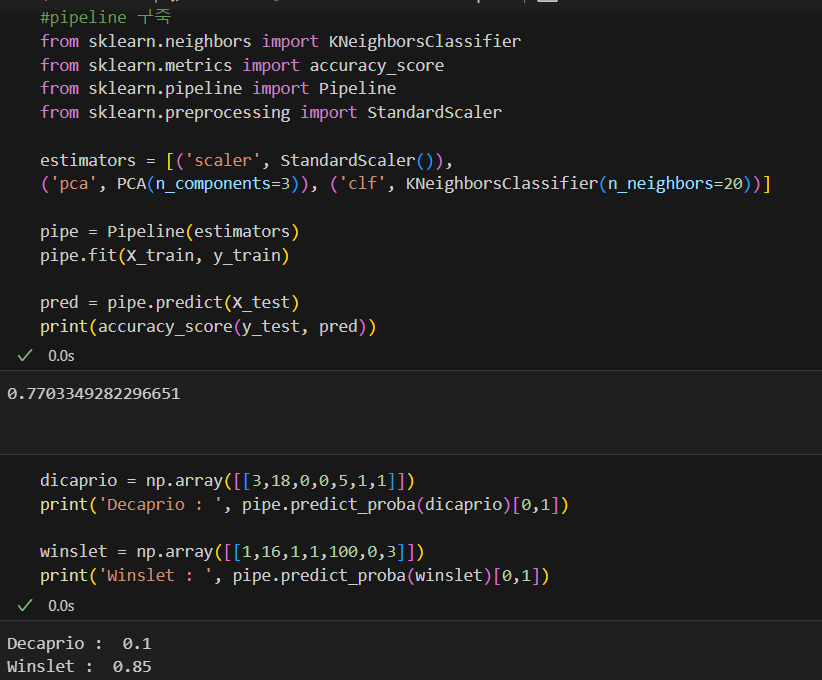
Olivetti 데이터로 실습을 해보자
#데이터읽기
# from sklearn.datasets import fetch_olivetti_faces
# faces_all = fetch_olivetti_faces()
원래는 위 코드로 데이터를 읽어오는데,
HTTP 403 error가 발생하여서 아래 코드로 실행함
import pickle
faces_all = pickle.load(open('olivetti_faces.p', 'rb'))
20번인 데이터를 불러오자
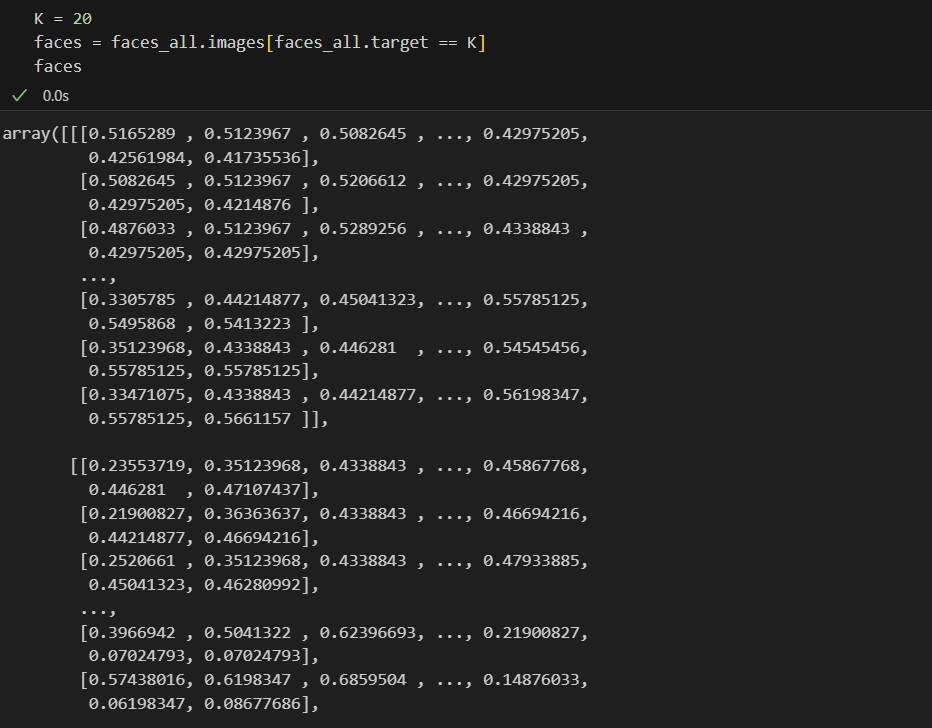
#K=20인 한 사람의 10장 사진 불러오기
import matplotlib.pyplot as plt
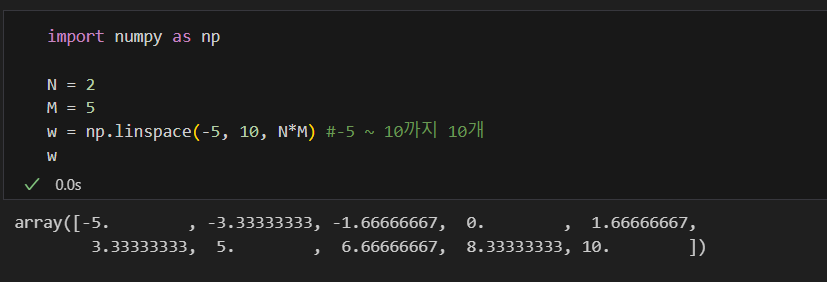
N = 2
M = 5
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(faces[n], cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([]) #x축 표기 안하려고 []
ax.yaxis.set_ticks([]) #y축 표기 안하려고 []
plt.show()
2개의 성분으로 분석해보자
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X = faces_all.data[faces_all.target == K]
W = pca.fit_transform(X)
X_inv = pca.inverse_transform(W)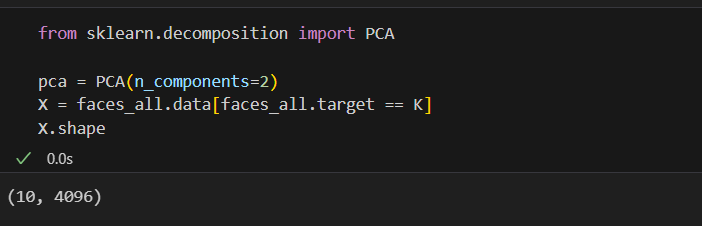
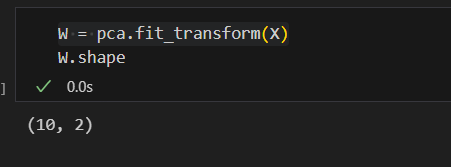
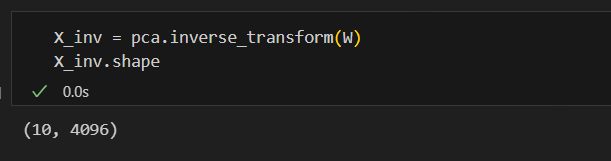
결과 확인
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(X_inv[n].reshape(64,64), cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([]) 더 흐리게 나온다
더 흐리게 나온다
원점과 두 개의 eigen face
face_mean = pca.mean_.reshape(64,64)
face_p1 = pca.components_[0].reshape(64,64)
face_p2 = pca.components_[1].reshape(64,64)
plt.figure(figsize=(12,7))
plt.subplot(131) #1행 3열에서 1번째 값
plt.imshow(face_mean, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([]); plt.title('mean')
plt.subplot(132) #1행 3열에서 2번째 값
plt.imshow(face_p1, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([]); plt.title('face_p1')
plt.subplot(133) #1행 3열에서 3번째 값
plt.imshow(face_p2, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([]); plt.title('face_p2')
plt.show()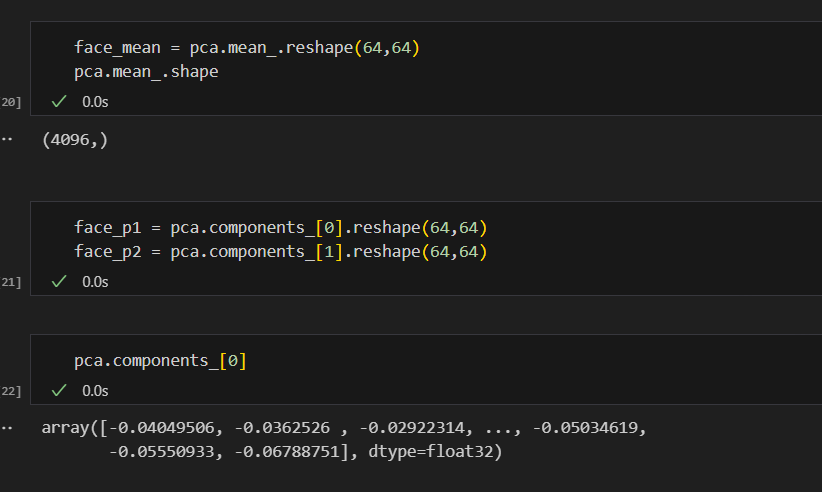
 10장의 사진은 이 세장으로 모두 표현할 수 있다
10장의 사진은 이 세장으로 모두 표현할 수 있다
먼저 가중치를 선정한다
첫번째 성분의 변화를 보자
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(face_mean + w[n] * face_p1, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([])
plt.title('Weight : ' + str(round(w[n])))
plt.tight_layout()
plt.show() 표정이 변하는 것 같다
표정이 변하는 것 같다
두번째 성분의 변화를 보자
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(face_mean + w[n] * face_p2, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([])
plt.title('Weight : ' + str(round(w[n])))
plt.tight_layout()
plt.show() 전반적인 얼굴 형태도 변화했다
전반적인 얼굴 형태도 변화했다
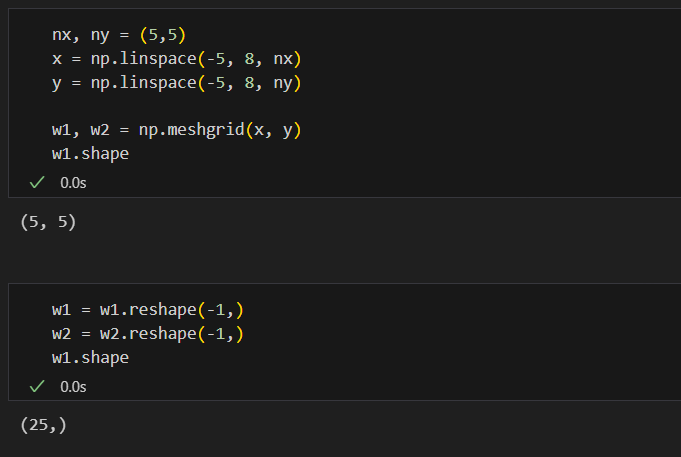
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for n in range(N*M):
ax = fig.add_subplot(N, M, n+1)
ax.imshow(face_mean + w1[n] * face_p1 + w2[n]*face_p2, cmap=plt.cm.bone)
plt.grid(False); plt.xticks([]); plt.yticks([])
plt.title(str(round(w1[n])) +', '+ str(round(w2[n])))
plt.tight_layout()
plt.show()
HAR 데이터

from sklearn.decomposition import PCA
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca
#PCA 결과를 저장하는 함수
def get_pd_from_pca(pca_data, col_num):
cols = ['pca_'+str(n) for n in range(col_num)]
return pd.DataFrame(pca_data, columns=cols)
#components 2개
HAR_pca ,pca = get_pca_data(X_train, n_components=2)
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train
HAR_pd_pca.head()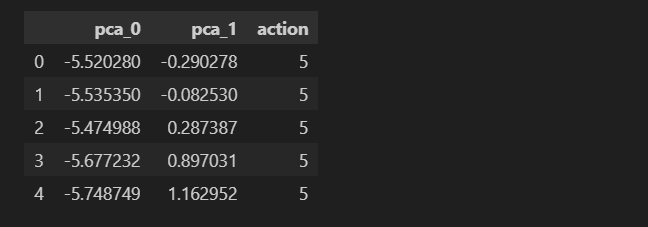
#그래프
import seaborn as sns
sns.pairplot(HAR_pd_pca, hue='action', height=5, x_vars=['pca_0'], y_vars=['pca_1']);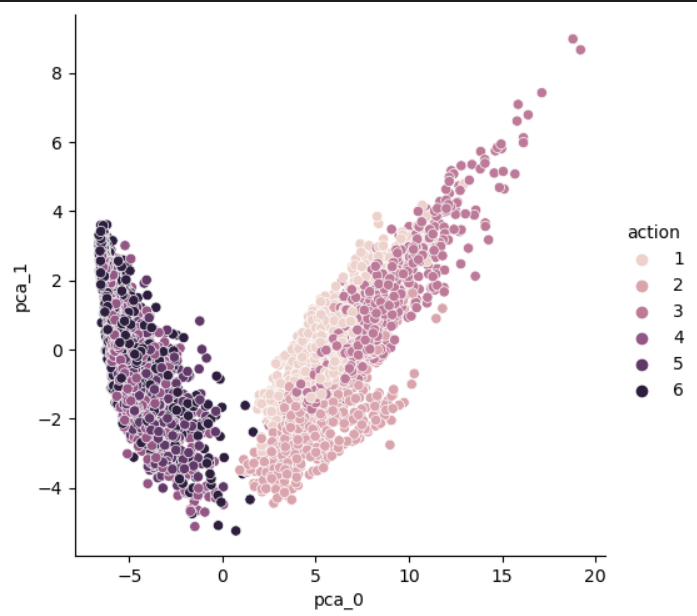 1,2,6번 정도는 잘 구분이 된다.
1,2,6번 정도는 잘 구분이 된다.
그러나 나머지는 잘 구분이 안된다
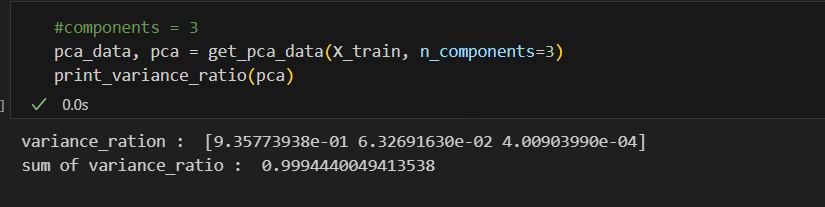
def print_variance_ratio(pca):
print('variance ratio : ', pca.explained_variance_ratio_)
print('sum of variance ratio : ', np.sum(pca.explained_variance_ratio_))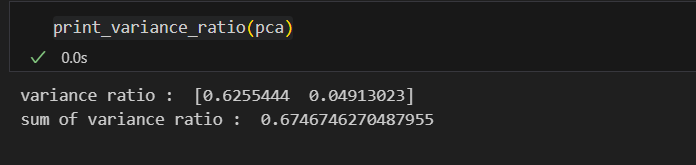
components 3개는
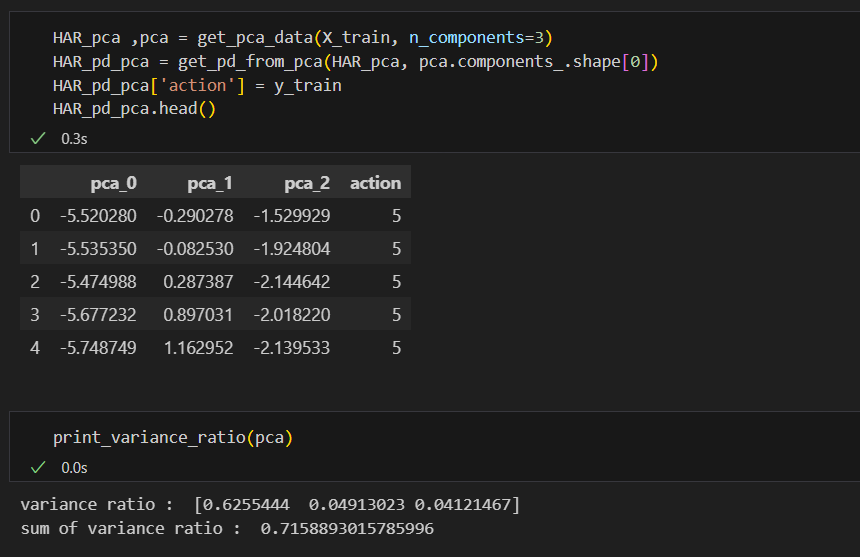
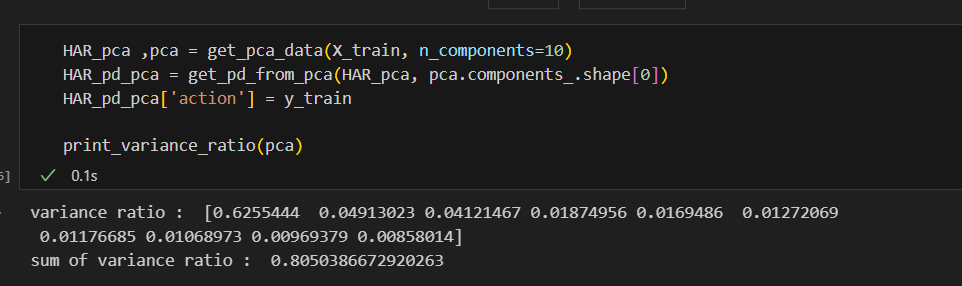
components 10개는
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth':[6,8,10],
'n_estimators':[50,100,200],
'min_samples_leaf':[8,12],
'min_samples_split':[8,12]
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(HAR_pca, y_train.values.reshape(-1,))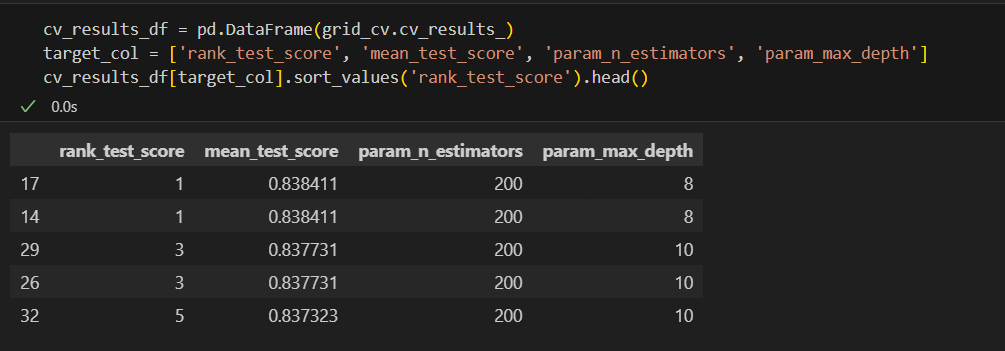
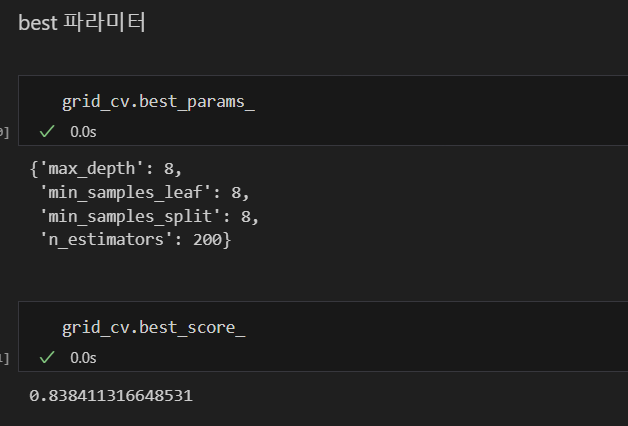
#테스트 데이터에 적용
from sklearn.metrics import accuracy_score
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(HAR_pca, y_train.values.reshape(-1,))
pred1 = rf_clf_best.predict(pca.transform(X_test))
#train 데이터로 pca를 통과시키고 그 pca로 test를 transform 시키는 것이 중요,
#test 데이터는 fit시키거나 직접적으로 건들이면 안됨
accuracy_score(y_test, pred1)
0.8527315914489311#xgboost 지도학습 중 생긴 오류 대응코드
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.fit_transform(y_test)
from xgboost import XGBClassifier
evals = [(pca.transform(X_test), y_test)]
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(HAR_pca, y_train.reshape(-1,), early_stopping_rounds=10, eval_set=evals)
accuracy_score(y_test, xgb.predict(pca.transform(X_test)))
0.8629114353579912MNIST

데이터 읽기
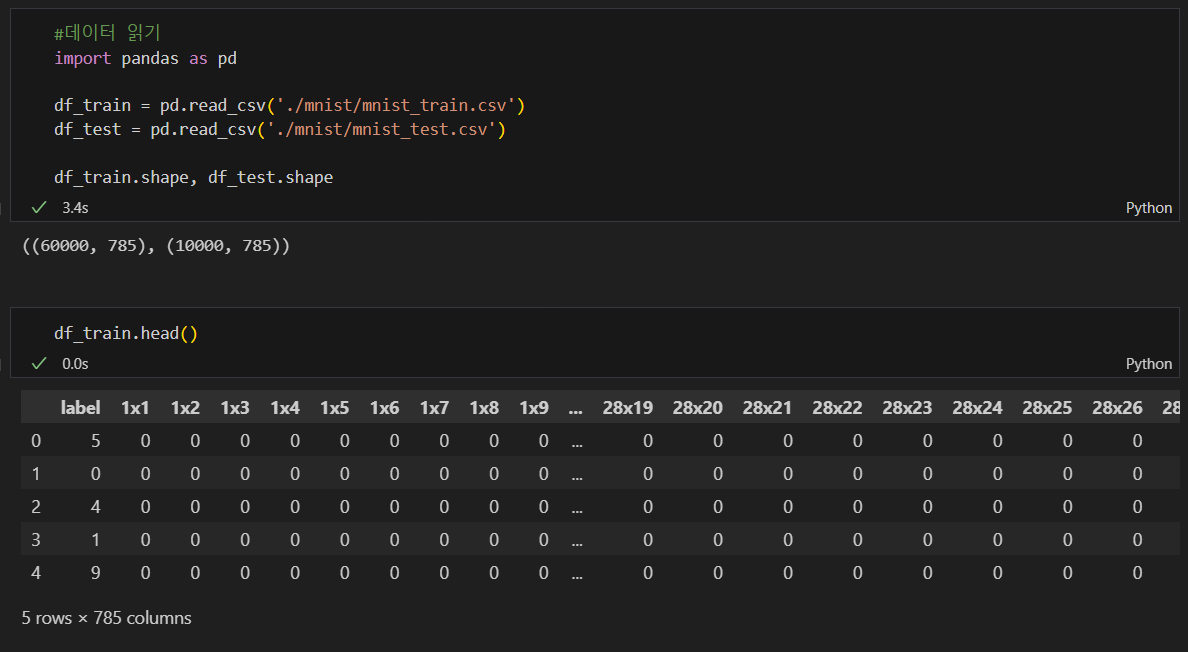
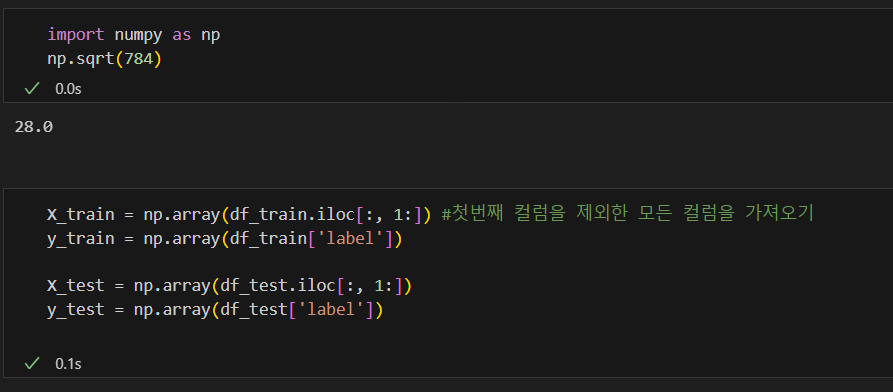
어떻게 생긴 데이터인지 확인해보자
랜덤하게 16개만
import matplotlib.pyplot as plt
plt.figure(figsize=(14,12))
for idx, n in enumerate(samples):
plt.subplot(4,4,idx+1)
plt.imshow(X_train[n].reshape(28,28), cmap='Greys')
plt.title(y_train[n])
plt.show()
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
pred = clf.predict(X_test)
accuracy_score(y_test,pred)
0.9688kNN에서 PCA로 차원을 줄여주자
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV, StratifiedKFold
pipe = Pipeline([
('pca', PCA()),
('clf', KNeighborsClassifier())
])
parameters = {
'pca__n_components':[2,5,10],
'clf__n_neighbors' :[5,10,15]
}
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=13)
grid = GridSearchCV(pipe, parameters, cv=kf, n_jobs=-1, verbose=1)
grid.fit(X_train, y_train)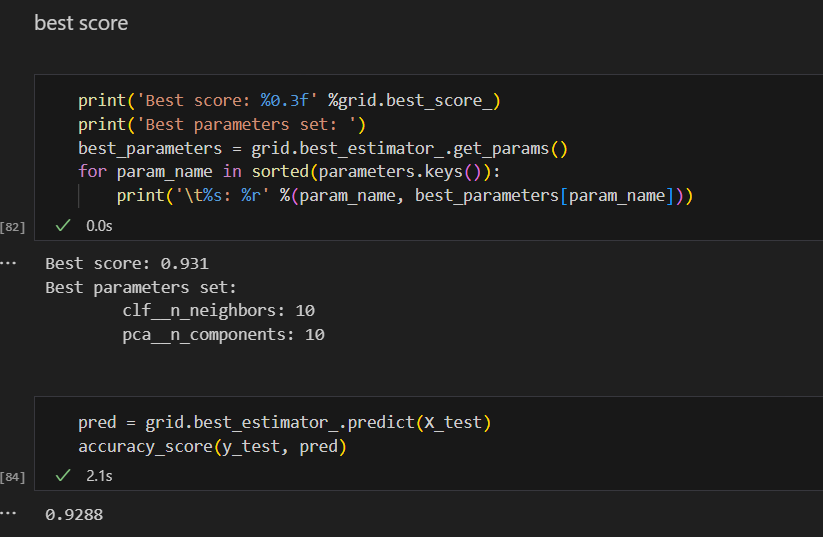
pca로 차원을 축소시키니까 훨씬 시간이 단축되었다.
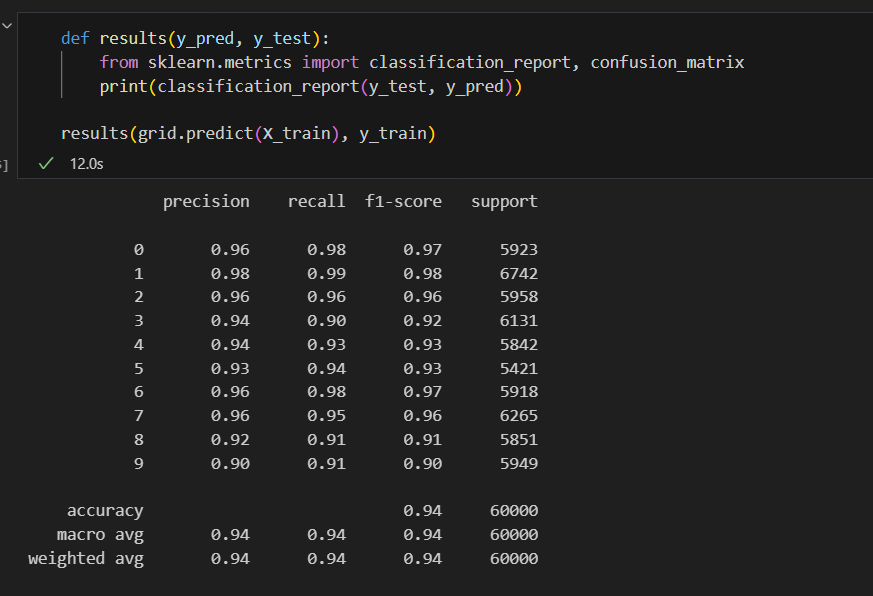 골고루 잘 맞추고 있다
골고루 잘 맞추고 있다
숫자를 다시 확인해보자
#700번째 숫자를 그리고
n = 700
plt.imshow(X_test[n].reshape(28,28), cmap='Greys', interpolation='nearest')
plt.show()
# 그 숫자를 예측해보자
print('Answer is : ', grid.best_estimator_.predict(X_test[n].reshape(1, 784)))
print('Real Label is :', y_test[n])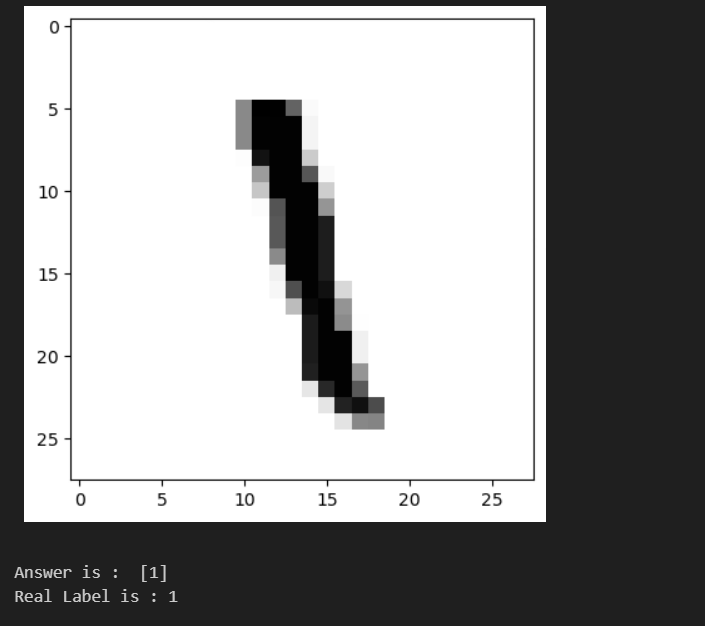
틀린 데이터를 관찰해보자
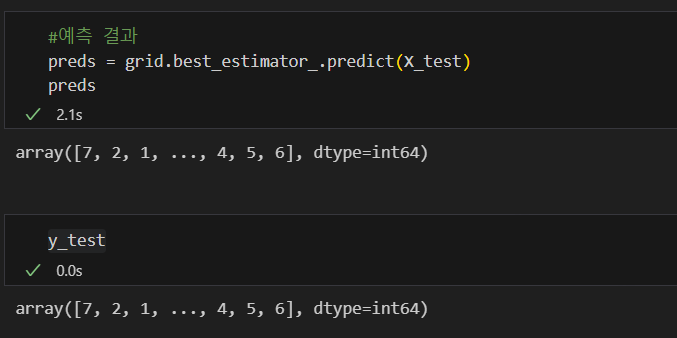
#test데이터의 참값과 예측값이 다른 경우만 모아놓은 데이터
wrong_results = X_test[y_test != preds]
samples = random.choices(population=range(0, wrong_results.shape[0]), k=16)
#그려보자
plt.figure(figsize=(14,12))
for idx, n in enumerate(samples):
plt.subplot(4,4, idx+1)
plt.imshow(wrong_results[n].reshape(28,28), cmap='Greys')
pred_digit = grid.best_estimator_.predict(wrong_results[n].reshape(1,784))
plt.title(str(pred_digit))
plt.show()
타이타닉 데이터에 적용해보자
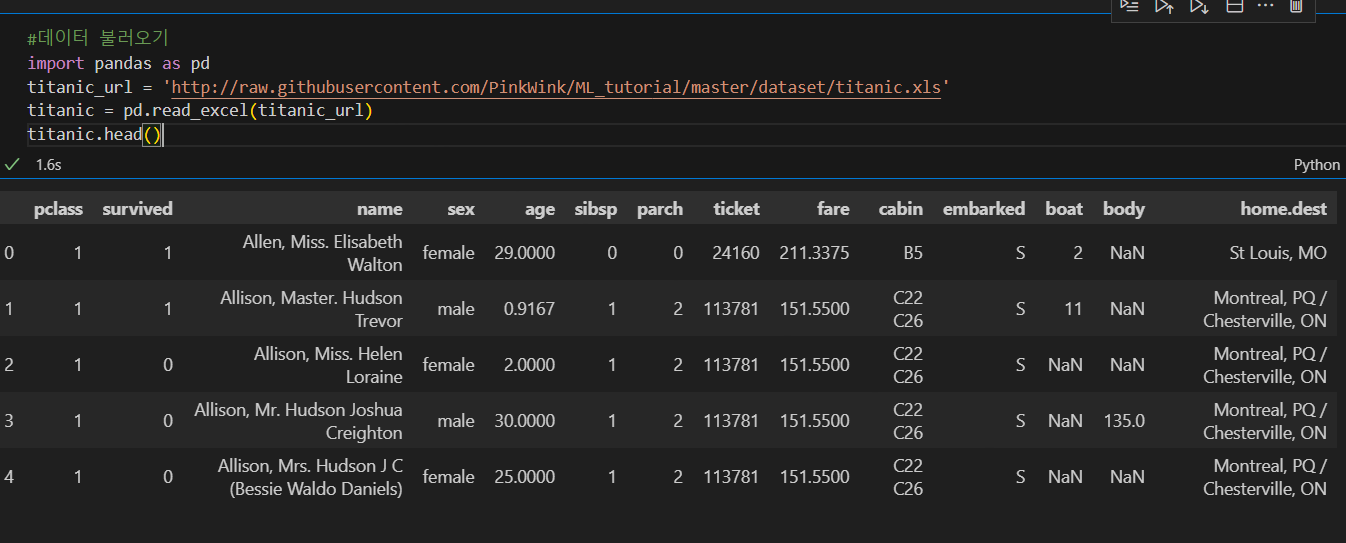
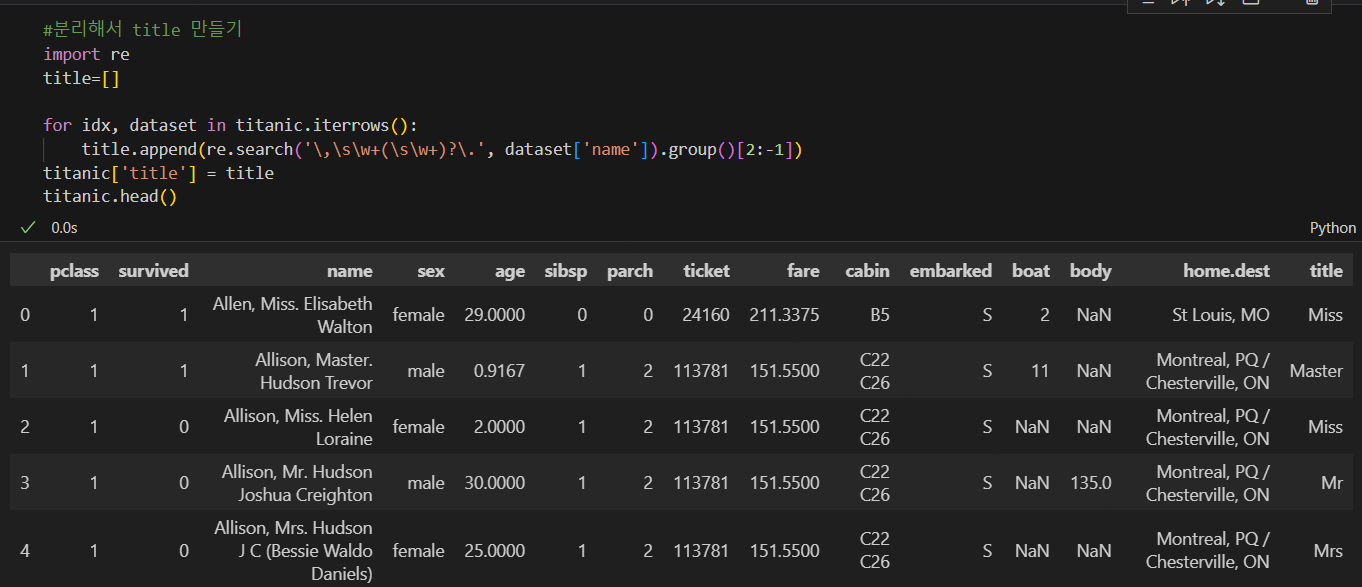
#귀족, 평민 등급 구별
titanic['title'] = titanic['title'].replace('Mlle', 'Miss')
titanic['title'] = titanic['title'].replace('Ms', 'Miss')
titanic['title'] = titanic['title'].replace('Mme', 'Mrs')
Rare_f = ['Dona', 'Dr', 'Lady', 'the Countess']
Rare_m = ['Capt', 'Col', 'Don', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Master']
for each in Rare_f:
titanic['title'] = titanic['title'].replace(each, 'Rare_F')
for each in Rare_m:
titanic['title'] = titanic['title'].replace(each, 'Rare_m')
#gender 컬럼 생성
from sklearn.preprocessing import LabelEncoder
le_sex = LabelEncoder()
le_sex.fit(titanic['sex'])
titanic['gender'] = le_sex.transform(titanic['sex'])
#grad 컬럼 생성
le_grade = LabelEncoder()
le_grade.fit(titanic['title'])
titanic['grade'] = le_grade.transform(titanic['title'])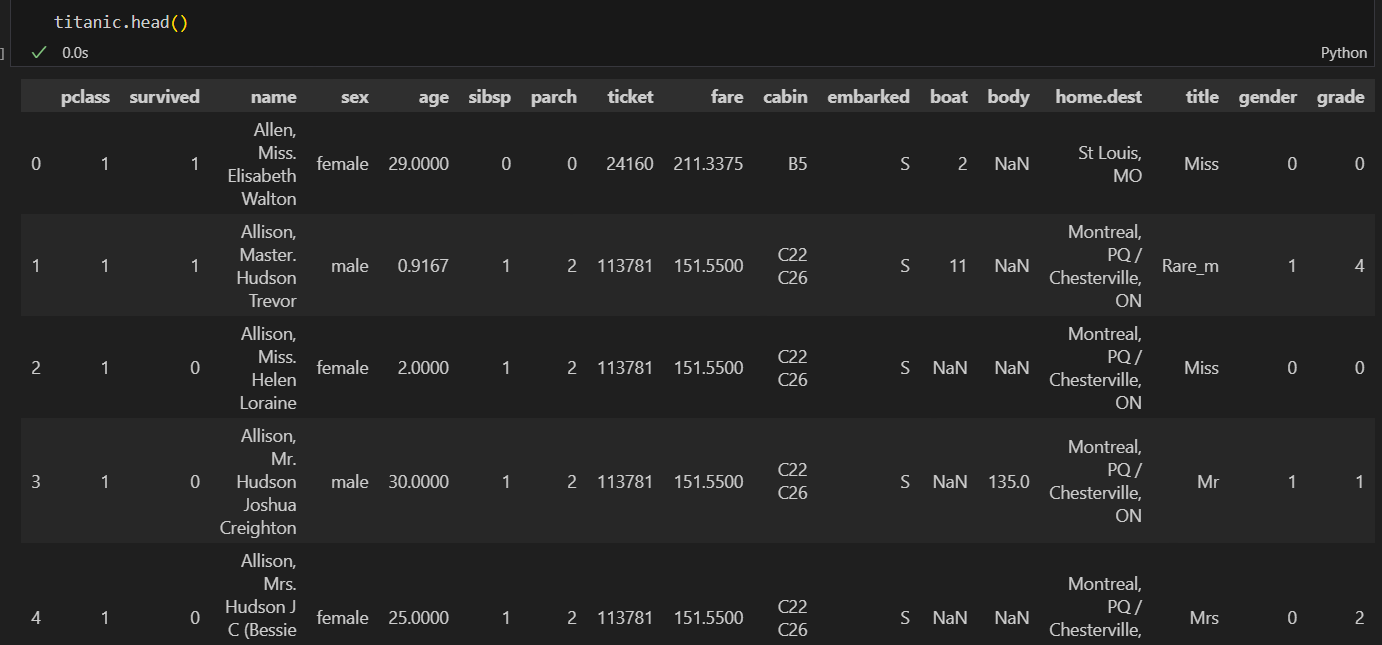
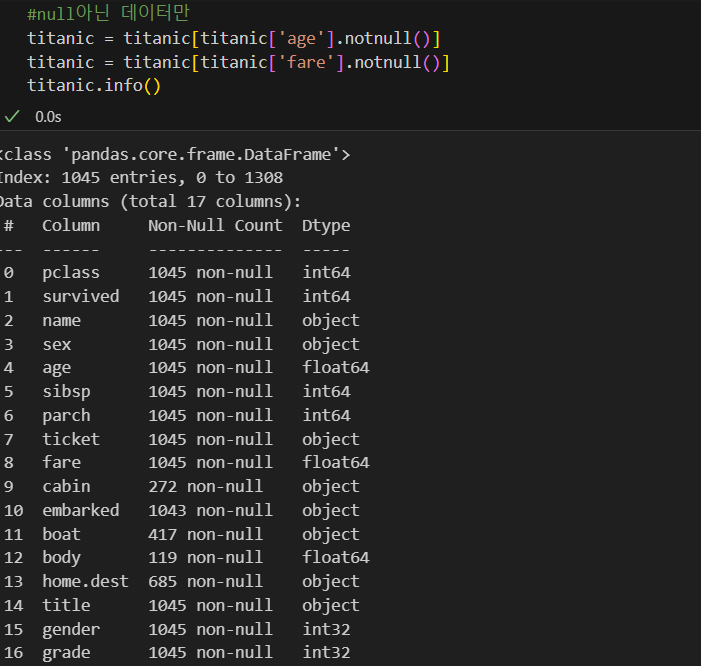
#데이터 나누기
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender', 'grade']].astype('float')
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
#pca 적용 준비
from sklearn.decomposition import PCA
def get_pca_data(ss_data,n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca
def get_pd_from_pca(pca_data, col_num):
cols = ['pca_'+str(n) for n in range(col_num)]
return pd.DataFrame(pca_data, columns=cols)
import numpy as np
def print_variance_ratio(pca, only_sum=False):
if only_sum==False:
print('variance_ration : ', pca.explained_variance_ratio_)
print('sum of variance_ratio : ', np.sum(pca.explained_variance_ratio_))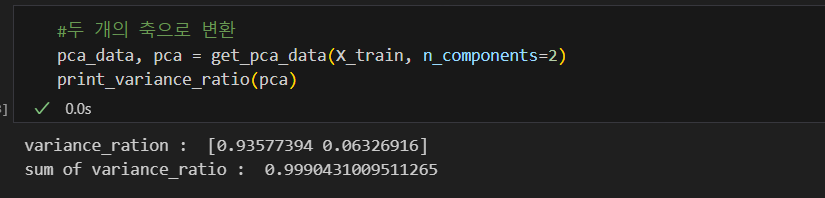
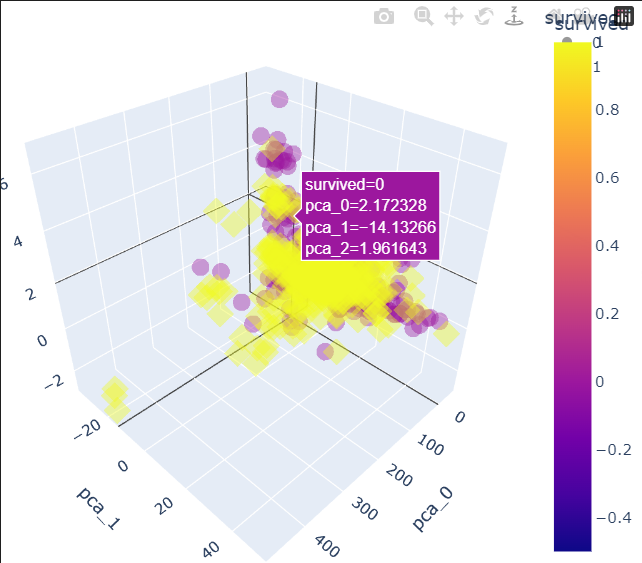
#그려보면
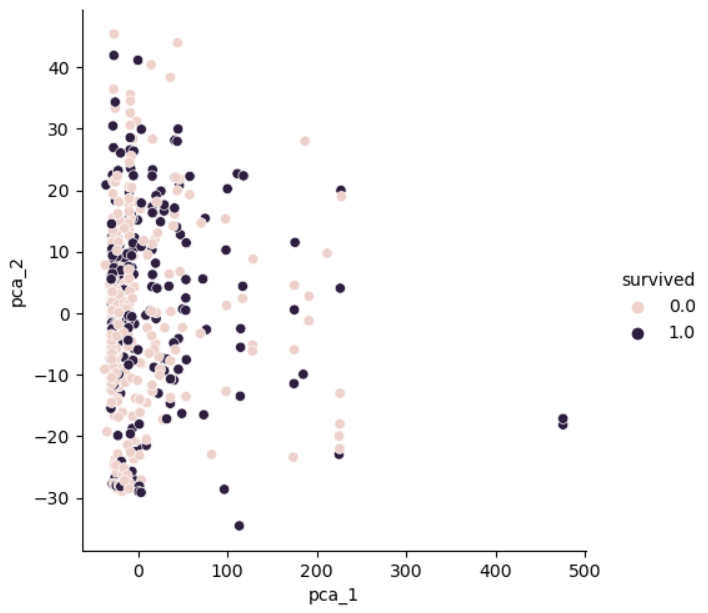
import seaborn as sns
pca_columns = ['pca_1', 'pca_2']
pca_pd = pd.DataFrame(pca_data, columns=pca_columns)
pca_pd['survived'] = y_train
sns.pairplot(pca_pd, hue='survived', height=5, x_vars=['pca_1'], y_vars=['pca_2']);