keyword
jupyter를 이용한 파이썬 환경설정
1. EDA - 서울시 CCTV 현황
분석 데이터 읽기, Pandas기초 - Series, DataFrame
Jupyter를 이용한 파이썬 환경설정
-
miniconda 설치 : 최소한의 기능만 갖고 있어서 빠른 설치 가능,
window, Mac(intel), Mac(M1) 지원
설치 후 터미널 실행 - Mac : cmd+space"터미널" 또는 "terminal" 검색 후 엔터, Windows : "Anaconda Prompt(miniconda3)" 실행
Mac(intel), Mac(M1) 사용자는 Homebrew 설치하기 -
conda가상환경
-
env(가상환경) 생성
-
conda 버전 확인
버전확인 : conda --version 입력
버전이 다르다면? conda update conda를 입력해서 업데이트 실행 -
conda 환경 생성
: 환경마다 다른 모듈 버전 생성 가능
conda create -n ds_study python=3.8 ( conda create 명령으로 -n 이름은 ds_study python으로 하고, 버전은 3.8로 하라) -
가상환경 활성화
: conda activate ds_study 또는 source activate ds_study를 치면 (base) 에서 (ds_study)로 변환됨 -
가상환경 비활성화 : conda deactivate
-
가상환경 목록: conda env list
-
가상환경 삭제: conda env remove -n name
-
-
Jupyter Notebook 및 패키지(Package)설치
- Jupyter Notebook
: 웹브라우저에서 직접 코드를 테스트할 수 있는 환경 제공,
conda install jupyter(가상환경 활성화 상태인지 확인) - 패키지 설치
conda install ipython
conda install matplotlib
conda install seaborn
conda install pandas
conda install sklearn
conda install xlrd
- Jupyter Notebook
-
matplotlib 한글 문제 해결
matplotlib : 그래프 그리는 도구, 기본 폰트가 영어라서 한글을 쓰기위해서는 별도 설정이 필요함
1) 내 컴퓨터에서 한글이 지원되는 폰트 확인하기
2) 폰트 이름을 알아낸 후, 설정
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib import rc
rc("font", family="Malgun Gothic")
plt.title("데이터사이언스")Analysis Seoul CCTV
목표 : 서울시 인구대비 CCTV 현황을 시각화하여 인구대비 CCTV가 적은구, 많은 구를 파악해보는 것
데이터 읽기
import pandas as pd
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8")
# ..: 현재폴더의 상위폴더로 이동
# encoding="utf-8" : 파일을 불러올때, 한글 파일이 깨질때 써줌
CCTV_Seoul.head()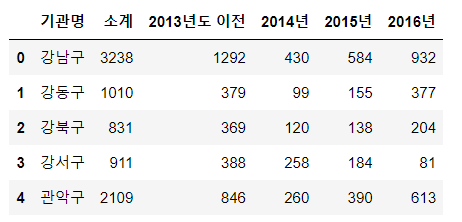
CCTV_Seoul.head(3)
# head(n): n = index index3까지 상위3개 출력
CCTV_Seoul.tail()
#tail() 데이터 끝에서부터 5개를 보여줌
in: CCTV_Seoul.columns
#컬럼을 리스트 형태로 반환
out: Index(['기관명', '소계', '2013년도 이전', '2014년', '2015년', '2016년'], dtype='object')
in: CCTV_Seoul.columns[0]
out: '기관명'
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
#rename(): 이름변경 columns[0]을 구별로 변경,
#inplace=True: 변경된 값을 바로 저장하기 위함
CCTV_Seoul.head()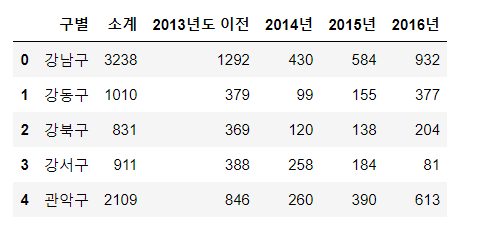
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N"
)
pop_Seoul.head()
# 특정 값들만 가져오고 싶을때 옵션을 걸어주는 것,
header = 2 index 2번째부터, 컬럼은 B,D,G,J,N만 불러옴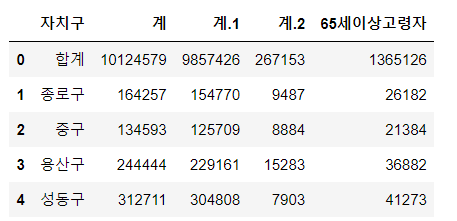
pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자",
},
inplace=True,
)
pop_Seoul.head()
#특정 컬럼의 이름을 바꾸는 것(rename)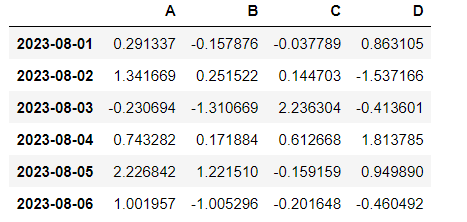
Pandas 기초
- python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
Series
- index와 value로 이루어져 있다
- 한 가지 데이터 타입만 가질 수 있다
import pandas as pd
import numpy as np
#pandas는 통상 pd, numpy는 통상 npin: pd.Series([1, 2, 3, 4])
out:
0 1
1 2
2 3
3 4
dtype: int64
pd.Series([1, 2, 3, 4], dtype=float64) #에러발생함
pd.Series([1, 2, 3, 4], dtype=np.float64)
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
#string type 데이터
pd.Series([1, 2, 3, 4], dtype=str)
0 1
1 2
2 3
3 4
dtype: object
pd.Series(np.array([1, 2, 3]))
0 1
1 2
2 3
dtype: int32
#dic type 데이터
pd.Series({"Key":"Value"})
Key Value
dtype: object
#하나라도 문자형이면 문자형으로 나옴
data = pd.Series([1, 2, 3, 4, "5"])
data
0 1
1 2
2 3
3 4
4 5
dtype: object
data = pd.Series([1, 2, 3, 4])
data
0 1
1 2
2 3
3 4
dtype: int64
#data를 2로 나눈 값
data % 2
0 1
1 0
2 1
3 0
dtype: int64날짜 데이터
#pd.data_range(문자열형태 날짜데이터, 원하는 일수)
dates = pd.date_range("20230801", periods=6)
dates
DatetimeIndex(['2023-08-01', '2023-08-02', '2023-08-03', '2023-08-04',
'2023-08-05', '2023-08-06'],
dtype='datetime64[ns]', freq='D')DataFrame
- pd.Series()
- index, value
- pd.DataFrame()
- index,value,column
# 표준정규분포에서 샘플링한 난수 생성
data = np.random.randn(6, 4)
data
array([[ 0.29133731, -0.15787604, -0.03778902, 0.86310544],
[ 1.3416686 , 0.25152215, 0.14470338, -1.53716571],
[-0.23069397, -1.31066902, 2.2363036 , -0.41360068],
[ 0.74328246, 0.17188411, 0.61266769, 1.81378486],
[ 2.22684167, 1.22150957, -0.15915924, 0.94989002],
[ 1.0019574 , -1.00529617, -0.20164775, -0.46049181]])
df = pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"])
df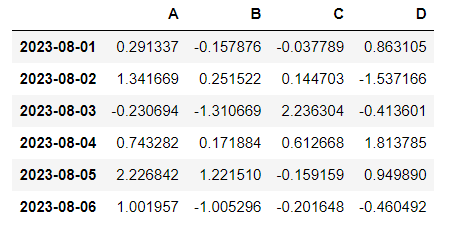
데이터 프레임 정보 탐색
- df.head() : 가진 데이터 중 상위 5개 데이터 보여줌
- df.tail() : 끝에서 5개 데이터, 갯수도 파악 가능
- df.index : 리스트 형태로 인덱스의 값 반환
- df.columns : 리스트 형태로 컬럼 값 반환
- df.values : 리스트 형태로 모든 데이터 값 반환
- df.info() : 데이터 프레임의 기본 정보 확인
- df.describe() : 데이터 프레임의 기술통계 정보 확인
데이터 정렬
- sort_values() : 특정 컬럼(열)을 기준으로 데이터 정렬
df.sort_values(by="B", ascending=False, inplace=True)
#by="B" B컬럼을 기준으로 데이터 정렬
#기본은 오름차순 정렬, 내림차순은 False값 주면 됨데이터 선택
# 한 개 컬럼 선택
df["A"]
#컬럼명이 문자인 경우에만 가능, 숫자는 안됨
df.A
df = pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"])
df
#A,B,C,D 컬럼 선택
#두 개 이상 컬럼 선택
df[["A","B"]]offset index
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함
#index 0부터 2까지
df[0:3]
#0801부터 0804까지(이름이라서 마지막도 포함)
df["20230801":"20230804"]- loc : location
- index 이름으로 특정 행, 열을 선택
#index는 전부, 컬럼은 A,B만 가져옴
df.loc[:, ["A","B"]]
#index는 20230802~20230804까지, 컬럼은 A,D만
df.loc["20230802":"20230804", ["A","D"]]
#index는 20230802~20230804일까지, A부터 D까지
df.loc["20230802":"20230804", "A":"D"]
#index 20230802, 컬럼 A,B값만
df.loc["20230802", ["A", "B"]]- iloc : inter location
컴퓨터가 인식하는 인덱스 값으로 선택(첫번째가 0)
#컴퓨터 인덱스로 3행인 값만
df.iloc[3]
#컴퓨터 인덱스로 3행2열 값만
df.iloc[3,2]
#컴퓨터 인덱스로 3~4행, 0~1열 값만
df.iloc[3:5, 0:2]
#컴퓨터 인덱스로 1,2,4행 0,2열 값만
df.iloc[[1, 2, 4], [0, 2]]
#컴퓨터 인덱스로 전체 행에서 1~2열 값만
df.iloc[:, 1:3]condition
# A 칼럼에서 0보다 큰 숫자(양수)만 선택
df["A"] > 0
#boolean type으로 결과 나옴
2023-08-01 True
2023-08-02 True
2023-08-03 False
2023-08-04 True
2023-08-05 True
2023-08-06 True
Freq: D, Name: A, dtype: bool
# 위 결과를 한번 더 df에 씌워주면(마스킹해줌) 해당 조건을 만족하는 데이터 출력
df[df["A"] > 0]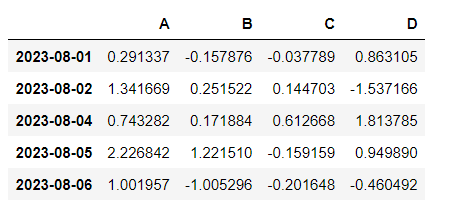
df[df > 0]
#전체값에서 0보다 큰 값을 출력하는데, 0보다 작은값은 NaN(Not a Number: 데이터가 없다)으로 나옴컬럼추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
df["E"] = ["one", "one", "two", "tree", "four", "six"]
df
#데이터 길이에 맞지 않게 컬럼 내용을 넣으면 에러발생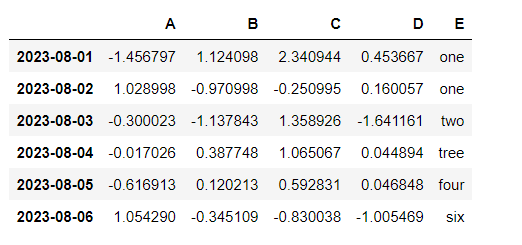
- isin()
특정 요소가 있는지 확인
boolean type으로 나옴
df["E"].isin(["two"])
2023-08-01 False
2023-08-02 False
2023-08-03 True
2023-08-04 False
2023-08-05 False
2023-08-06 False
Freq: D, Name: E, dtype: bool
df["E"].isin(["two", "five", "three"])
2023-08-01 False
2023-08-02 False
2023-08-03 True
2023-08-04 False
2023-08-05 False
2023-08-06 False
Freq: D, Name: E, dtype: bool
df[df["E"].isin(["two", "five", "three"])]
#위 결과를 df로 마스킹 하면 True값 결과만 나옴
특정 컬럼 제거
- del
- drop(
[지우고 싶은 컬럼명], axis=0(기본,가로) or axis=1(세로)
)
del df["E"]
df
#세로줄 D컬럼 삭제
df.drop(["D"], axis=1)
#가로줄 20230801 삭제
df.drop(["20230801"])apply()
- 데이터프레임에 일괄적으로 함수기능을 적용해주는 메서드
df["A"].apply("sum") #덧셈
df["A"].apply("mean") #평균
df["A"].apply("min"),df["A"].apply("max") #최솟값, 최댓값
df[["A", "D"]].apply(sum) #여러개 컬럼에서 적용
df["A"].apply(np.sum) #np에서 쓰는 덧셈
#양수/음수 판단 함수
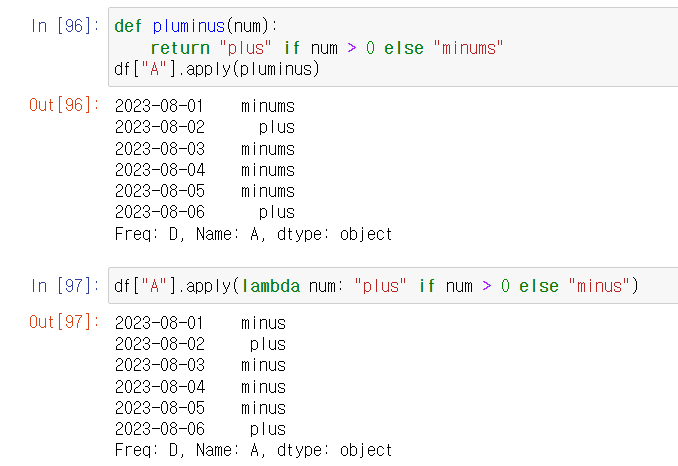
def pluminus(num):
return "plus" if num > 0 else "minums"
df["A"].apply(pluminus)
#람다함수 활용
#람다함수 : 이름이 없는 함수. 1번만 사용하는 재활용성이 없는 함수에 유용
df["A"].apply(lambda num: "plus" if num > 0 else "minus")