Python with MySQL
설치
가상환경을 활성화 한 후, mysql driver 설치
conda activate ds_study
pip install mysql-connector-python설치 확인
import mysql.connector MySQL 접속 코드
변수명 = mysql.connector.connect(
host = "hostname",
user = "username",
password = "password"
)local database 연결
local = mysql.connector.connect(
host = "localhost",
user = "root",
password = "******",
database = "zerobase" # 특정 데이터베이스로 연결
)
local.close() #사용이 끝나면 close()를 해야함AWS RDS(database-1) 연결
remote = mysql.connector.connect(
host = "엔드포인트",
port = 3306,
user = "admin",
password = "******",
database = "zerobase" # 특정 데이터베이스로 연결
)
remote.close() #사용이 끝나면 close()를 해야함쿼리를 실행하기 위한 코드
import mysql.connector
#db 연결
mydb = mysql.connector.connect(
host = "hostname",
user = "username",
password = "password",
database = "databasename"
)
mycursor = mydb.cursor() #cursor 생성
mycursor.execute(<query>) # execute() : 커서가 쿼리를 실행테이블 생성하는 쿼리를 실행하는 코드
#db 연결
remote = mysql.connector.connect(
host = "엔드포인트",
port = 3306,
user = "admin",
password = "******",
database = "zerobase" # 특정 데이터베이스로 연결
)
cur = remote.cursor() #커서 생성
cur.execute("CREATE TABLE sql_file (id int, filename varchar(16))") #커서가 쿼리 실행
remote.close() SQL File을 실행하기 위한 코드
기본형태
import mysql.connector
#db 연결
mydb = mysql.connector.connect(
host = "hostname",
user = "username",
password = "password",
database = "databasename"
)
mycursor = mydb.cursor() #커서 생성
sql = open("filename.sql").read() #open 함수를 써서 쿼리 생성, 파일을 열어서 읽어오도록 함
mycursor.execute(sql) #커서를 통해 sql을 실행하면 sql 파일에 있는 쿼리 실행
# file 내에 쿼리가 여러개 존재하는 경우, multi=True 옵션 추가
mydb.close()Execute SQL File 예제 1
testl03.sql을 생성하고, 파일 실행
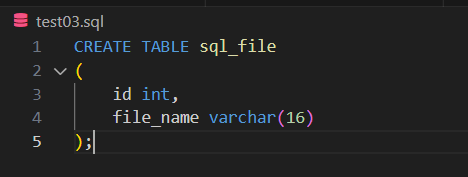
#db 생성
remote = mysql.connector.connect(
host = "엔드포인트",
port = 3306,
user = "admin",
password = "******",
database = "zerobase"
)
cur = remote.cursor() #커서 생성
sql = open("test03.sql").read() #쿼리 생성
cur.execute(sql) #쿼리 실행
remote.close()Execute SQL File 예제 2
SQL File 내에 쿼리가 여러개 존재하는 경우
test04.sql을 생성하고, 실행
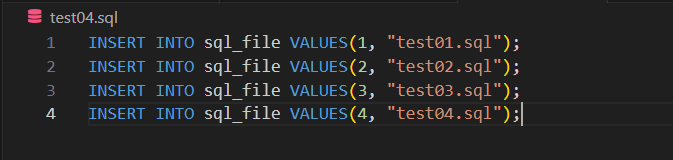
#db 연결
remote = mysql.connector.connect(
host = "엔드포인트",
port = 3306,
user = "admin",
password = "******",
database = "zerobase"
)
cur = remote.cursor() #커서생성
sql = open("test04.sql").read() #쿼리생성
for result_iterator in cur.execute(sql, multi=True): #쿼리실행, 여러번 실행된 것을 받아와서
if result_iterator.with_rows: #결과 값이 여러개인 경우
print(result_iterator.fetchall()) #결과를 모두 출력
else:
print(result_iterator.statement) #검색 결과가 아닌경우 statement출력
remote.commit() #commit()해야 db에 적용됨
remote.close()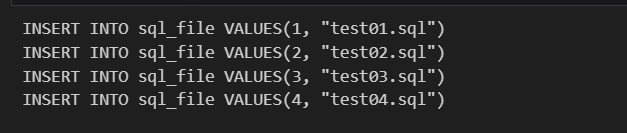
결과확인
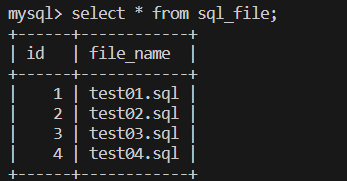
Fetch All
실행쿼리가 아닌 조회하는 select문을 실행한 경우,
데이터를 가져온다. 이런 데이터가 있는 경우 fetchall을 써서 변수에 담아서 출력하면 그 데이터를 볼 수 있다. 바로 출력하면 한꺼번에, for문을 돌리면 row마다 찍힌다.
mycursor.execute(<query>)
result = mycursor.fetchall()
for data in result:
print(data)Python with CSV
큰 데이터들 있는 csv,exel 파일을 db에 넣고 쿼리를 해보고 싶을 때, 한번에 넣을 수 있는 방법이 mysql에 있다 workbench나 명령어로 넣을 수 있지만, encoding이 맞지 않으면 fail이 많이 발생한다.
그러나 파이썬으로는 간단하게 해결가능하다.
지난 시간에 만들어 둔 police_station 테이블(name, address)에 police_station.csv 파일에 있는 데이터를 넣는다.
먼저, police_station.csv 파일을 읽어보자.
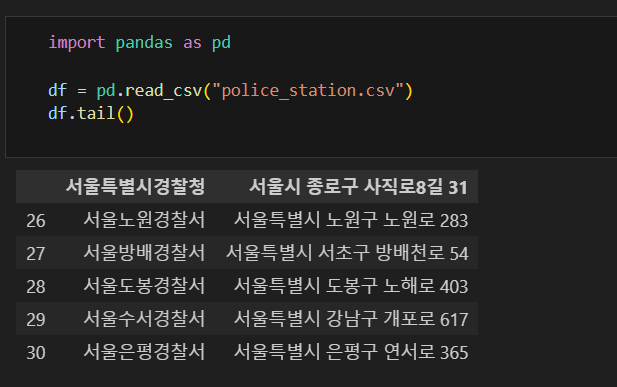
테이블에 넣기 전 db인 제로베이스에 연결
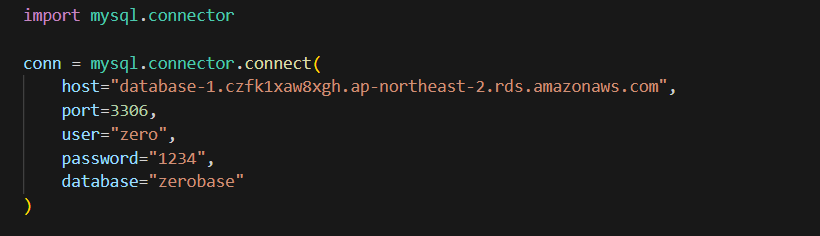
읽어올 양이 많은 경우 커서에 buffered=True 옵션 추가
cursor = conn.cursor(buffered=True)
쿼리생성
sql = "insert into police_station values(%s,%s)"
2개의 값을 str 값으로 받기 위해서 %s,%s
반복문을 쓰기 위해 쿼리는 하나만 만들었다.
mysql.connector execute 공식문서
https://dev.mysql.com/doc/connector-python/en/connector-python-api-mysqlcursor-execute.html
for i,row in df.iterrows():
cursor.execute(sql,tuple(row)) #tuple(row)를 sql에 대입
print(tuple(row)) #sql에 들어갈 tuple(row)를 하나씩 출력
conn.commit()
#반복문으로 실행한 것이 바로 db에 적용되지 않고, commit() 하는 순간 적용됨
#commit()을 반복문 안에 넣으면 반복중 오류가 나더라도 오류 전까지는 db에 적용됨, 반복문 안에 있지 않으면 오류가 나면 db에는 아무것도 적용 안됨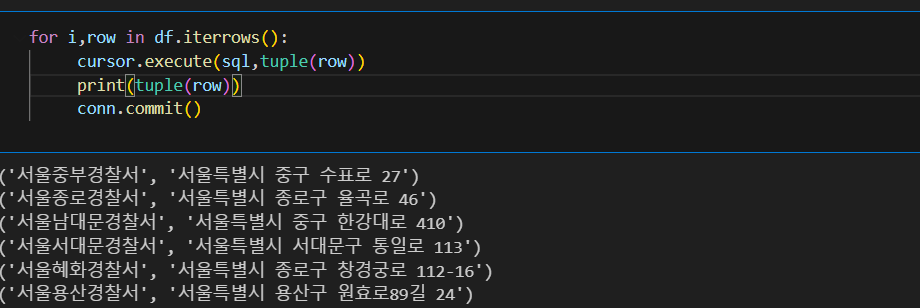
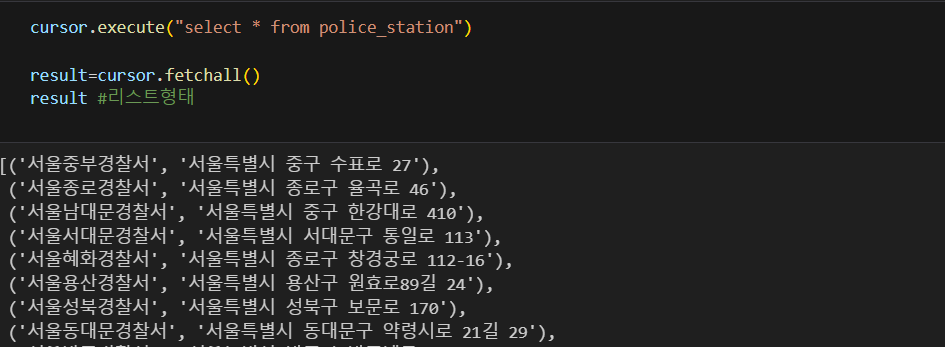
코드로 결과 확인
#아래 쿼리때문에 버퍼옵션을 줬음
cursor.execute("select * from police_station")
result=cursor.fetchall()
result #리스트 형태테이블에 잘 들어갔다면 아래처럼 출력된다.
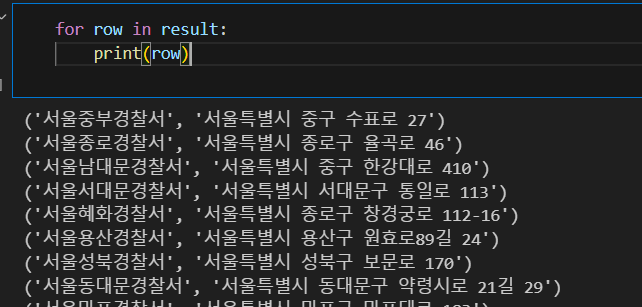
CSV 파일을 읽었을 때, 한글이 깨지는 경우
encoding='euc-kr' 옵션 주기
Pytho with CSV 예제
crime_status 테이블에 2020_crime.csv 데이터를 입력하는 코드 작성
먼저, 2020_crime.csv 읽어오기
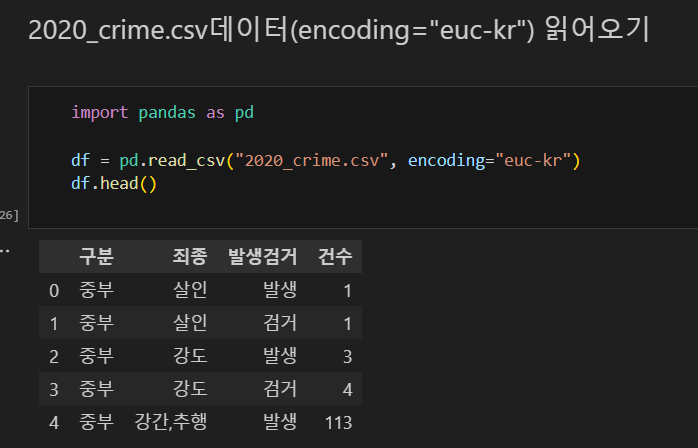
db 연결
import mysql.connector
conn = mysql.connector.connect(
host = "엔드포인트",
port = 3306,
user = "zero",
password = "*******" #zero유저 생성할때 설정한 비번
database = "zerobase"
)insert 쿼리 생성
sql = "insert into crime_status values ('2020', %s, %s, %s, %s)" #년도 값은 파일에 없으므로 직접 넣어줌
cursor = conn.cursor(buffered=True) #검색결과를 보기위해 버퍼옵션 추가테이블에 잘 들어갔다면 아래처럼 출력 된다.
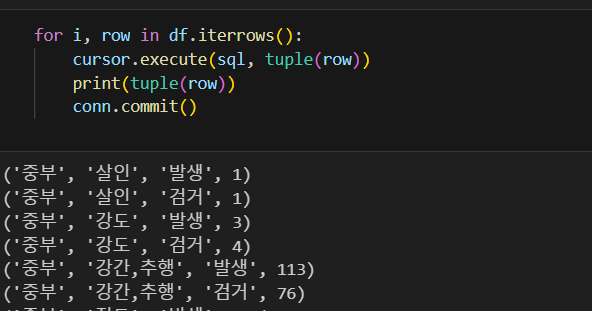
tail로 총 개수 확인
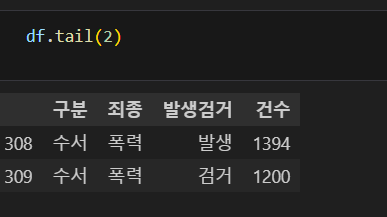
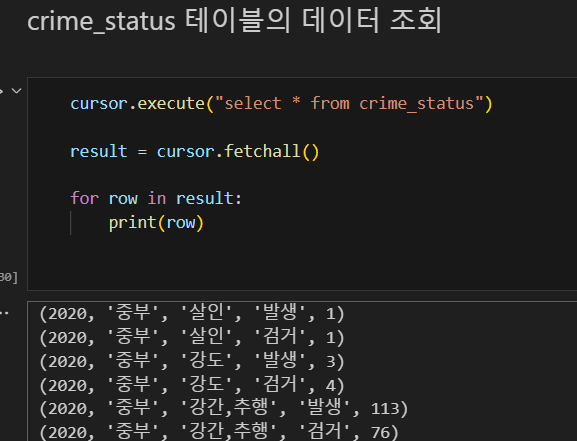
쿼리로 결과 확인
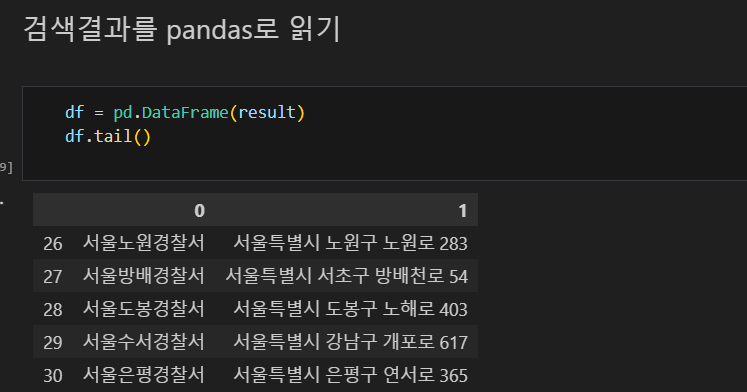
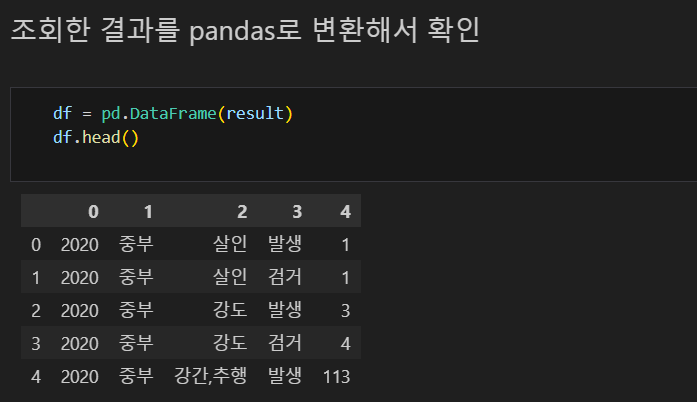
조회한 결과를 pandas로 변환해서 확인
실습
1. AWS RDS (database-1) zerobase에 접속
import mysql.connector
conn = mysql.connector.connect(
host = "",
port = 3306,
user = "zero",
password = "1234",
database = "zerobase"
)
2.CCTV Table 생성
#테이블 컬럼을 지정하기 위해 데이터 불러오기
import pandas as pd
df = pd.read_csv("Seoul_CCTV.csv", encoding="utf-8")
df.head(2)
cur = conn.cursor(buffered=True)
sql = "CREATE TABLE cctv (기관명 varchar(8), 소계 int, 2013년도이전 int, 2014년 int, 2015년 int, 2016년 int)"
cur.execute(sql)
3.csv파일을 pandas로 읽어오기
import pandas as pd
df = pd.read_csv("Seoul_CCTV.csv", encoding="utf-8")
df.head(2)
4. 데이터를 cctv 테이블에 insert
#쿼리 생성
sql = "insert into cctv values( %s, %s, %s, %s, %s, %s)"
cursor = conn.cursor(buffered=True)
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
5. cctv 테이블의 데이터 조회하여 확인
cursor.execute("select * from cctv")
result = cursor.fetchall()
for row in result:
print(row)
6. 조회된 데이터를 pandas로 변환하여 출력
import pandas as pd
df = pd.DataFrame(result)
df.head()