문제 설명
자카드 유사도는 원소의 중복을 허용하는 다중집합에 대해서 확장할 수 있다. 다중집합 A는 원소 "1"을 3개 가지고 있고, 다중집합 B는 원소 "1"을 5개 가지고 있다고 하자. 이 다중집합의 교집합 A ∩ B는 원소 "1"을 min(3, 5)인 3개, 합집합 A ∪ B는 원소 "1"을 max(3, 5)인 5개 가지게 된다. 다중집합 A = {1, 1, 2, 2, 3}, 다중집합 B = {1, 2, 2, 4, 5}라고 하면, 교집합 A ∩ B = {1, 2, 2}, 합집합 A ∪ B = {1, 1, 2, 2, 3, 4, 5}가 되므로, 자카드 유사도 J(A, B) = 3/7, 약 0.42가 된다.
이를 이용하여 문자열 사이의 유사도를 계산하는데 이용할 수 있다. 문자열 "FRANCE"와 "FRENCH"가 주어졌을 때, 이를 두 글자씩 끊어서 다중집합을 만들 수 있다. 각각 {FR, RA, AN, NC, CE}, {FR, RE, EN, NC, CH}가 되며, 교집합은 {FR, NC}, 합집합은 {FR, RA, AN, NC, CE, RE, EN, CH}가 되므로, 두 문자열 사이의 자카드 유사도 J("FRANCE", "FRENCH") = 2/8 = 0.25가 된다.
풀이
그냥 단순 구현 문제 였다.
나는 생각보다 코드가 길어졌는데 다른 사람의 풀이를 보니까 엄청 짧은 것을 보고 놀랐다.
나는 Dictionary 자료구조를 통해 Hash로 풀었는데 다른 사람들은 모두 count를 써서 한결 깔끔해진 것 같다(+ List Comprehension 사용 여부)
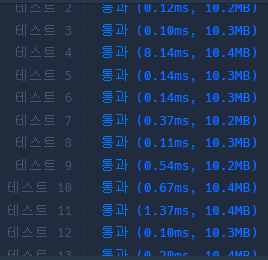
하지만 효율성 부분에서 비교해보니 Dictionary로 푼 것이 압도적으로 좋다. 코드가 간결한 것도 중요하지만 효율성도 중요하니까 ^8^
내코드
def solution(str1, str2):
answer,inter,union = 0,0,0
dic1,dic2 = {}, {}
str1,str2 = str1.lower(), str2.lower()
for i in range(len(str1)-1):
temp = str1[i] +str1[i+1]
if not temp.isalpha(): continue
if temp in dic1: dic1[temp] += 1
else: dic1[temp] = 1
for i in range(len(str2)-1):
temp = str2[i] +str2[i+1]
if not temp.isalpha(): continue
if temp in dic2: dic2[temp] += 1
else: dic2[temp] = 1
setInter = set(dic1) & set(dic2)
for s in setInter:
inter += min(dic1[s],dic2[s])
union += max(dic1[s],dic2[s])
setSD = set(dic1) ^ set(dic2)
for s in setSD:
if s in dic1: union += dic1[s]
else: union += dic2[s]
return int((inter / union) * 65536) if union != 0 else 65536효율성
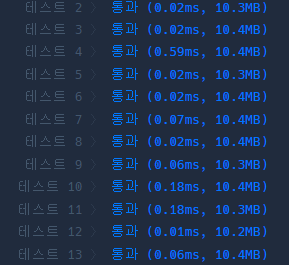
다른 사람의 풀이(프로그래머스)
import re
import math
def solution(str1, str2):
str1 = [str1[i:i+2].lower() for i in range(0, len(str1)-1) if not re.findall('[^a-zA-Z]+', str1[i:i+2])]
str2 = [str2[i:i+2].lower() for i in range(0, len(str2)-1) if not re.findall('[^a-zA-Z]+', str2[i:i+2])]
gyo = set(str1) & set(str2)
hap = set(str1) | set(str2)
if len(hap) == 0 :
return 65536
gyo_sum = sum([min(str1.count(gg), str2.count(gg)) for gg in gyo])
hap_sum = sum([max(str1.count(hh), str2.count(hh)) for hh in hap])
return math.floor((gyo_sum/hap_sum)*65536)효율성