Spring Batch
큰 단위의 작업을 일괄처리
대부분 처리량이 많고 비 실시간성 처리에 사용
-> 대용량 데이터 계산, 정산, 통계, 데이터베이스, 변환...
컴퓨터 자원 최대로 활용
-> 컴퓨터 자원 사용이 낮은 시간대 배치 처리 or 배치만 처리 위해 사용자가 사용하지 않는 또 다른 컴퓨터 자원 사용
스케줄러와 같은 시스템에 의해 실행되는 대상
-> ex) 오전 10시에 배치 실행... / crontab, jenkins...
Spring Batch는 배치를 처리하기 위해 Spring Framework 기반 기술
Spring에서 지원하는 기술 적용 가능.
비교적 간단한 작업(Tasklet) 단위 처리 or 대량 묶음(Chunk) 단위 처리
실행 단위 -> Job / Step
@Bean
public Job helloJob(){
return jobBuilderFactory.get("helloJob") // 잡 이름 설정 - name은 스프링 배치를 실행할 수 있는 key
.incrementer(new RunIdIncrementer()) // Job이 실행될 때 마다, 파라미터 아이디 자동생성
.start() // job 실행시 최초로 실행할 지점 설정
.build();Job은 실행단위를 구분할 수 있는 incrementer와 job의 이름, step을 설정.
@Bean
public Step helloStep(){ // step -> job 의 실행단위. 1개의 Job 은 1개 이상의 step 을 가질 수 있다.
return stepBuilderFactory.get("helloStep") //
.tasklet((contribution, chunkContext) -> { // step의 실행단위. step의 실행단위는 tasklet / chunk 기반 두개가 존재.
log.info("hello spring batch");
return RepeatStatus.FINISHED;
}).build();
}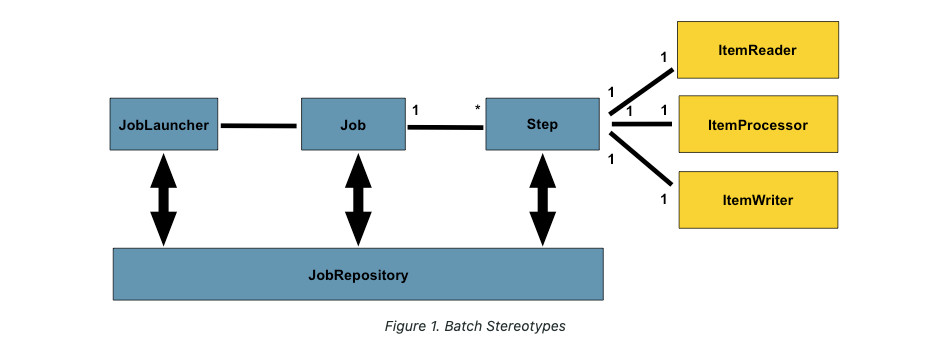
- Spring batch는 Job type의 bean이 생성되면, JobLauncher 객체에 의해 Job 실행.
Job은 Step에 실행 - JobRepository -> DB or Memory에 Spring batch가 실행할 수 있도록 배치의 메타데이터를 관리.
Job
- Job = JobLauncher에 의해 실행
- Job = 배치의 실행단위
- Job = N개의 Step 실행, 흐름(Flow) 관리.
ex) A Step 실행 후 조건에 따라 B Step or C Step 실행 설정.
Step
- Step = Job의 세부 실행 단위. N개가 등록되어 실행됨.
Step의 실행단위
Chunk 기반 - 하나의 큰 덩어리를 n개씩 나눠 실행
-> ItemReader, ItemProcessor, ItemWriter
** 여기서 Item은 배치 처리 대상 객체 의미.
ItemReader?
배치대상의 리더를 만들거나 읽을 수 있다.
배치 처리 대상 객체를 읽어 ItemProcessor or ItemWriter에 전달
ex) 파일 or DB에서 데이터를 읽음
ItemProcessor?
ItemReader에서 읽은 것들을 가공하거나 필터링 할 수 있다.
필수값은 아님. 하지만 명확한 책임을 나눌 수 있어 사용.
input 객체를 output 객체로 filtering or processing 해 ItemWriter에 전달.
ex) ItemReader에서 읽은 데이터 수정 or ItemWriter 대상인지 filtering.
ItemProcessor -> Optional함
ItemProcessor가 하는 일을 ItemReader or ItemWriter가 대신 할 수 있다.
ItemWriter?
배치 처리 데이터 최종 처리. 정상 데이터를 만들어 DB에 insert나 update.. 아니면 알림을 보낼수도 있다.
배치 처리 대상 객체 처리
ex) DB update or 처리 대상 사용자에게 알림
Task 기반 - 하나의 작업 기반으로 실행
Spring batch 테이블 구조와 이해
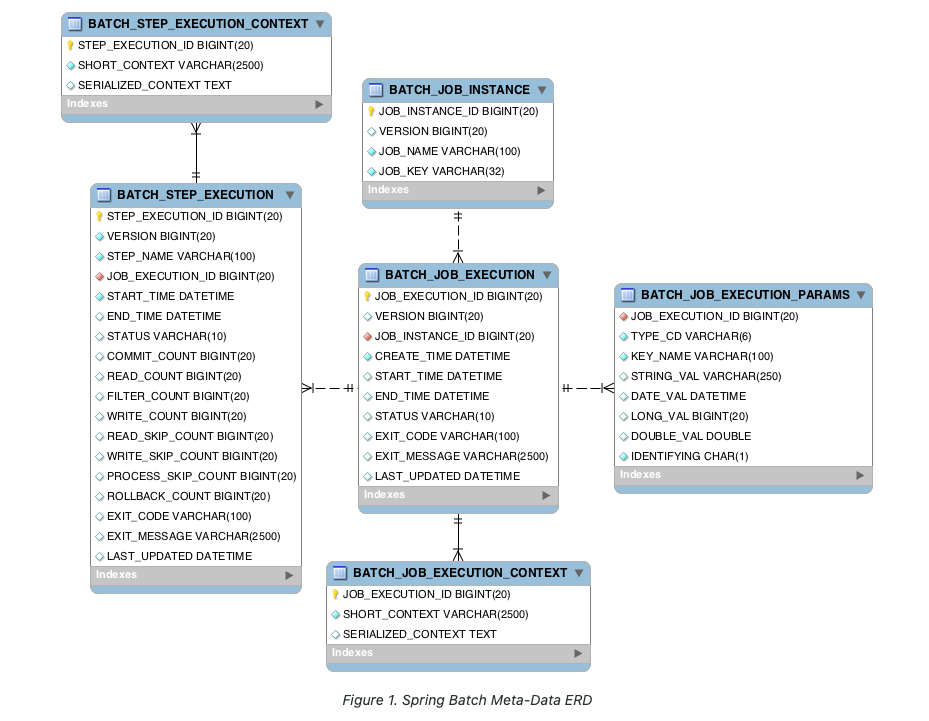
배치 실행을 위한 메타 데이터가 저장되는 테이블
BATCH_JOB_INSTANCE
- Job이 실행되며 생성되는 최상위 계층 테이블
- job_name과 job_key를 기준으로 하나의 row가 생성, 같은 job_name, job_key가 저장될 수 X
- job_key는 BATCH_JOB_EXECUTION_PARAMS에 저장되는 Parameter를 나열해 암호화해 저장
- JobInstance와 매핑
BATCH_JOB_EXECUTION
- Job이 실행되는 동안 시작/종료 시간, job 상태 관리
- JobExecution과 매핑
BATCH_JOB_EXECUTION_PARAMS
- Job을 실행하기 위해 주입된 parameter 정보 저장
- JobParameters와 매핑
BATCH_JOB_EXECUTION_CONTEXT
- Job이 실행되며 공유해야할 데이터를 직렬화해 저장
- ExecutionContext와 매핑
BATCH_STEP_EXECUTION
- Step이 실행되는 동안 필요한 데이터 or 실행된 결과 저장
- StepExecution과 매핑
BATCH_STEP_EXECUTION_CONTEXT
- Step이 실행되며 공유해야할 데이터를 직렬화해 저장
- ExecutionContext와 매핑
ExecutionContext?
-> Job과 Step의 context를 모두 매핑
meta table의 script 위치?
spring-batch-core/org.springframework/batch/core/* 에 위치
-> spring batch를 실행하고 관리하기 위한 테이블
JobInstance
생성기준?
JobParameters 중복 여부에 따라 생성
다른 parameter로 Job 실행 -> JobInstance 생성
같은 parameter로 Job 실행 -> 이미 생성된 JobInstance 실행
JobExecution은 항상 새롭게 생성
ex)
처음 Job 실행 시 date parameter가 1월 1일로 실행 -> 1번 JobInstance 생성
다음 Job 실행 시 date parameter가 1월 2일로 실행 -> 2번 JobInstance 생성
* 다음 Job 실행 시 date parameter가 1월 2일로 실행 -> 2번 JobInstance 재실행
-> 이때 Job이 재실행 대상이 아닌 경우 에러 발생
Job을 항상 새로운 JobInstance가 실행될 수 있도록 RunIdIncrementer 제공
-> RunIdIncrementer는 항상 다른 run.id를 Parameter로 설정
데이터 공유 ExecutionContext 이해
JobExecutionContext 는 Job 내에서만 데이터 공유
StepExecutionContext 는 Step 내에서만 데이터 공유
Batch를 처리할 수 있는 방법
Tasklet을 사용한 Task 기반 처리
-
배치 처리 과정이 비교적 쉬운 경우 쉽게 사용
-
대량 처리를 하는 경우 더 복잡
-
하나의 큰 덩어리를 여러 덩어리로 나누어 처리하기 부적합
Chunk를 사용한 chunk(덩어리) 기반 처리
-
ItemReader, ItemProcessor, ItemWriter 의 관계 이해 필요
-
대량 처리를 하는 경우 Tasklet보다 비교적 쉽게 구현
-
ex) 10000개 데이터 중 1000개씩 10개의 덩어리로 수행
-> 이걸 Tasklet으로 처리 시 10000개를 한번에 처리 or 수동으로 1000개씩 분할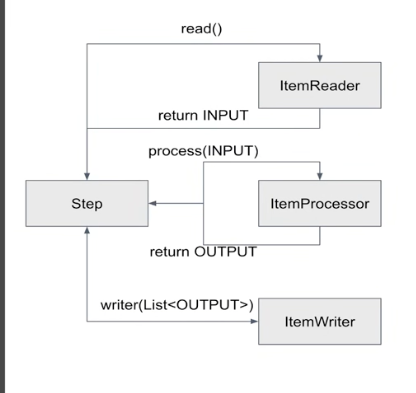chunk 기반의 Step 종료 시점은
reader에서 null을 return 할 때 까지 Step 반복<INPUT,OUTPUT>chunk(int) * reder에서 INPUT을 return * processor에서 INPUT을 받아 processing 후 OUTPUT을 return > INPUT, OUTPUT은 같은 타입일 수 있다. * writer에서 List<OUTPUT>을 받아 write
JobParameters의 이해
JobParameters의 객체를 직접 사용하는 방법 / Spring에서 제공하는 EL 이용하는 방법
- 배치를 실행에 필요한 값을 parameter를 통해 외부에서 주입
- JobParameters는 외부에서 주입된 parameter를 관리하는 객체
- parameter를 JobParameters와 Spring EL(Expression Language)로 접근
- String parameter = jobParameters.getstring(key, defaultValue);- @Value("#{jobParameters[key]}")
@JobScope / @StepScope 이해
spring의 scope는 bean의 lifecycle을 설정.
spring의 기본 scope는 싱글톤
애플리케이션이 실행되는 시점에 생성, 종료되는 시점에 소멸
- @Scope - 어떤 시점에 bean을 생성/소멸 시킬 지 bean의 lifecycle 설정
- @JobScope - job 실행 시점에 생성/소멸 -> Step에 선언
- @StepScope - step 실행 시점에 생성/소멸
-> Tasklet, Chunk(ItemReader, ItemProcessor, ItemWriter) 에 선언 - @Scope("job") == @JobScope
- @Scope("step") == @StepScope
- Job과 Step 라이프사이클에 의해 생성되어 Thread safe하게 작동
- @Value("#{jobParameters[key]}")를 사용하기 위해
@JobScope / @StepScope 는 필수
