KTB 3기 클라우드 과정에서 진행한 개인 커뮤니티 프로젝트의 최종 배포 과정을 정리한 글입니다.
개발을 진행하면서 단일 EC2 배포 → Docker 구성 → HTTPS 적용 → CI/CD까지 단계적으로 경험해 왔지만,
여러 문제를 겪으며 지금까지의 구조로는 한계가 있다는 것을 자연스럽게 느끼게 되었습니다.
이번 글에서는 그동안의 배포 시리즈에서 다뤘던 내용들이 왜 실제 운영 환경에서는 충분하지 않았는지, 그리고 그런 문제들을 해결하기 위해 최종적으로 어떤 네트워크 아키텍처를 설계하게 되었는지 그 흐름을 중심으로 기록해보려고 합니다.
기존 단일 EC2 아키텍처의 한계
1️⃣ 단일 EC2 환경은 언제든 “단일 장애점(SPOF)”이 된다
서비스가 커지든 안 커지든, 서버가 한 대뿐이라는 사실 자체가 위험 요소라고 생각했습니다.
EC2가 재부팅되거나 장애가 나면? → 전체 서비스 중단
배포 중 잠깐이라도 서비스가 내려가면? → 사용자 경험 저하
트래픽이 일시적으로 늘어나면? → 서버가 감당하지 못하고 지연 발생
저의 커뮤니티(Closet Lounge)는 로그인, 게시물 작성, 이미지 업로드 등 상태 기반 기능이 많기 때문에 안정성이 특히 중요했습니다. 그래서 우선적으로 프론트엔드(정적 페이지)와 백엔드(API 서버)를 분리하여 각각 별도의 EC2로 운영하는 구조로 전환했습니다.
또한 BE/FE 서버를 분리해두면 이후에 Auto Scaling Group을 적용하여 서버 수를 자동으로 늘리거나 줄일 수 있는 기반도 마련됩니다.
ASG는 인스턴스가 여러 대일 때 의미가 있으므로, 다중 EC2 구조로 바꾸는 것은 확장성과 안정성을 위한 필수 선행 단계라고 판단했습니다.
이렇게 분리함으로써,
-
특정 서버 장애 시 전체 서비스가 함께 죽지 않도록 하고
-
배포 시에도 한쪽 서비스만 점진적으로 교체할 수 있으며
-
향후 트래픽 증가 시 백엔드나 프론트 중 필요한 부분만 확장할 수 있는 구조
를 갖출 수 있게 되었습니다.
EC2 MySQL → RDS로 전환한 이유
초기에는 MySQL을 EC2 내부에 설치해 사용했지만, 프론트/백엔드 서버를 분리하고 인프라가 확장되면서 DB를 EC2 안에 그대로 두는 방식은 점점 비효율적이라는 생각이 들었습니다.
EC2에 직접 설치한 MySQL은 겉보기엔 비용이 저렴해 보이지만,
-
백업, 복구, 모니터링, 보안 패치
-
장애 대응, 스토리지 관리
-
확장성 확보
이 모든 작업을 개발자가 직접 맡아야 하기 때문에 운영 부담이 지나치게 큽니다.
반면 Amazon RDS는 관리형 서비스로서 대부분의 운영 작업을 AWS가 자동으로 처리해줍니다.
또한 RDS의 Multi-AZ 구성은 하나의 AZ에서 장애가 발생해도 자동으로 다른 AZ의 대기 인스턴스로 Failover를 수행해 서비스 중단 시간을 최소화할 수 있습니다.
이러한 이유로, 비용 대비 운영 효율성과 안정성이 훨씬 높은 RDS로 전환하는 것이 맞는 선택이라고 판단했습니다.
2️⃣ HTTPS — 인증서를 어디에서, 어떻게 관리할 것인가?
초기에는 단일 EC2였기 때문에, Nginx를 직접 설치하고 Reverse Proxy + SSL 설정까지 모두 수동으로 구성했었습니다. 하지만 구조가 단일 서버 → 다중 EC2 아키텍처로 확장되면서, 더 이상 Nginx가 최선의 선택이 아닌것 같다는 생각이 들었습니다.
이후까지 고려하면, SSL 인증서와 트래픽 분배 로직을 모두 EC2 내부의 Nginx에 두는 것은 장기적으로 유지하기 어려운 구조라고 판단했습니다.
앞으로 Auto Scaling, 서버 증설, 무중단 배포 같은 운영 요소를 적용하게 되면, 로드밸런서 자체도 자동화와 확장성을 지원해야 하기 때문입니다.
그래서 장기적으로는 AWS에서 제공하는 ELB(Elastic Load Balancing) 를 사용하는 것이 더 안정적이고 운영 효율적이라고 판단했습니다.
ELB는 트래픽 분배, SSL 인증서 관리(ACM), 자동 헬스 체크, Auto Scaling 연동까지 모두 AWS가 처리해 주기 때문입니다.
ELB중에서도 ALB는 L7 기반, URL·경로·호스트 기반 라우팅 지원합니다.
저의 서비스 구조가 아래와 같이 되어있어 요청 URL의 경로에 따라 서로 다른 서버로 트래픽을 보내야 했기때문에 ALB를 선택했습니다.
/ → 프론트엔드(정적 페이지)
/api → 백엔드(Spring Boot API)
결국 HTTPS 환경에서 가장 중요한 것은 아래와 같습니다.
-
인증서를 안전하게 관리할 수 있는지
-
갱신이 자동화되는지
-
서버 확장 시 인증서 설정을 반복하지 않아도 되는지
Nginx에 인증서를 올려두는 방식은 서버가 늘어날수록 관리 비용이 증가하지만, ALB는 ACM(AWS Certificate Manager) 를 통해 인증서를 한 번만 등록하면
모든 인스턴스 앞단에서 일관되게 HTTPS → HTTP Termination을 수행할 수 있습니다.
즉, HTTPS 통신의 책임을 애플리케이션 서버가 아니라 로드밸런서 레벨에서 전부 해결할 수 있어 ALB가 HTTPS 운영 측면에서도 가장 적합한 선택이라는 결론에 도달했습니다.
‘현실적인’ AWS 아키텍처 구축
이번 프로젝트에서 목표는 처음부터 복잡하고 과한 아키텍처를 구성하는 것이 아니라,
- 개인 프로젝트의 운영 부담을 줄이면서도
- 서비스가 커졌을 때 확장할 여지를 남겨두고
- 장애나 배포 문제로 서비스가 중단되지 않도록 안정성을 확보
하는 ‘현실적인 아키텍처’ 를 만드는 것이었습니다.
또한, 네트워크 구성 자체를 처음부터 직접 설계해보는 경험이었기 때문에,
불필요하게 많은 기술 요소를 한 번에 도입하면 오히려 이해와 운영 난도가 과도하게 올라갈 것이라고 판단했습니다.
즉, 지금 단계에서는 “완벽한 실무 환경”보다 “내가 이해하고 통제할 수 있는 범위”를 기반으로 구축하는 것이 더 중요하다고 생각했습니다.
이러한 이유로, 복잡한 구성 대신 학습·운영·확장성 간 균형이 맞는 아키텍처를 선택하게 되었습니다.
1️⃣ Private 서브넷을 사용하지 않은 이유 — 과도한 복잡도 방지
“보안을 위해 BE는 private subnet에 둔다”라고 알려져 있지만, 지금 제 프로젝트 상황에서는 public이 더 현실적인 선택이었습니다.
public subnet이라고 외부에서 마음대로 접속할 수 있는 게 아니기도 하고,
앞단에 이미 ALB가 있고, EC2는 Security Group으로 보호되고 있습니다.
실무 환경에서는 보통 BE EC2와 RDS를 Private Subnet에 두고,
NAT Gateway를 통해 외부로 나갈 수 있도록 구성합니다.
하지만, 처음 네트워크 구성을 직접 설계하는 입장에서는
너무 많은 요소를 한 번에 도입하는 것이 오히려 이해를 방해할 수 있다고 느꼈습니다. 특히 NAT Gateway는 발생하는 과금이 꽤 크기도하고, 네트워크가 복잡해 질것 같아서 사용하지 않았습니다.
NAT Gateway 대신에
-
NAT Instance를 직접 만들어 사용하거나 -
Bastion Host를 따로 구성해 SSH를Private Subnet에서만 허용하는 방식
등 Private 구성을 구현하는 다양한 방법이 있다는 것도 알고 있지만,
이런 구성들을 사용하면 네트워크 다이어그램은 더 복잡해지고,
Security Group 규칙과 라우팅 관리 포인트 역시 늘어나게 됩니다.
현재 프로젝트에서는 복잡하지만 이상적인 구조를 당장 구현하는 것보다는,
전체 흐름을 명확히 이해하고 안정적으로 운영할 수 있는 최소 구성이
첫 아키텍처로는 더 적합하다고 느꼈기 때문에 보안 요구 사항도 “필요한 최소한의 제약을 지키는 수준”이면 충분하다고 생각했습니다.
그래서 이번에는 네트워크 구조를 단순하게 가져가기로 결정했습니다.
즉, 보안은 SG로 충분히 통제하고, NAT 비용을 줄이며 CI/CD와 외부 통신을 위해 Public Subnet이 현재 프로젝트에서는 최적이라고 판단했습니다.
2️⃣ 파일 저장소 S3를 사용하는 이유
초기 단일 EC2에서는 이미지 파일을 EC2 내부 디스크에 저장할 수도 있었지만,
다중 EC2로 확장되는 순간 다음과 같은 문제가 발생합니다.
-
각
EC2마다 스토리지가 달라져 이미지 동기화가 안됨 -
서버가 교체되거나
Auto Scaling으로 새 인스턴스가 생성되면 기존 이미지가 사라짐 -
디스크 용량 관리가 필요하며 장애 시 데이터 손실 가능성 존재
S3는 이런 문제를 한 번에 해결해줍니다.
파일이 EC2와 완전히 분리되기 때문에 인스턴스 교체와 무관하게 유지되고, 전 세계 어디서나 동일한 URL로 접근 가능합니다.
비용도 EC2 EBS 대비 저렴하고 확장도 불필요하며, 이후 CloudFront 등을 붙이면 글로벌 캐싱도 가능합니다.
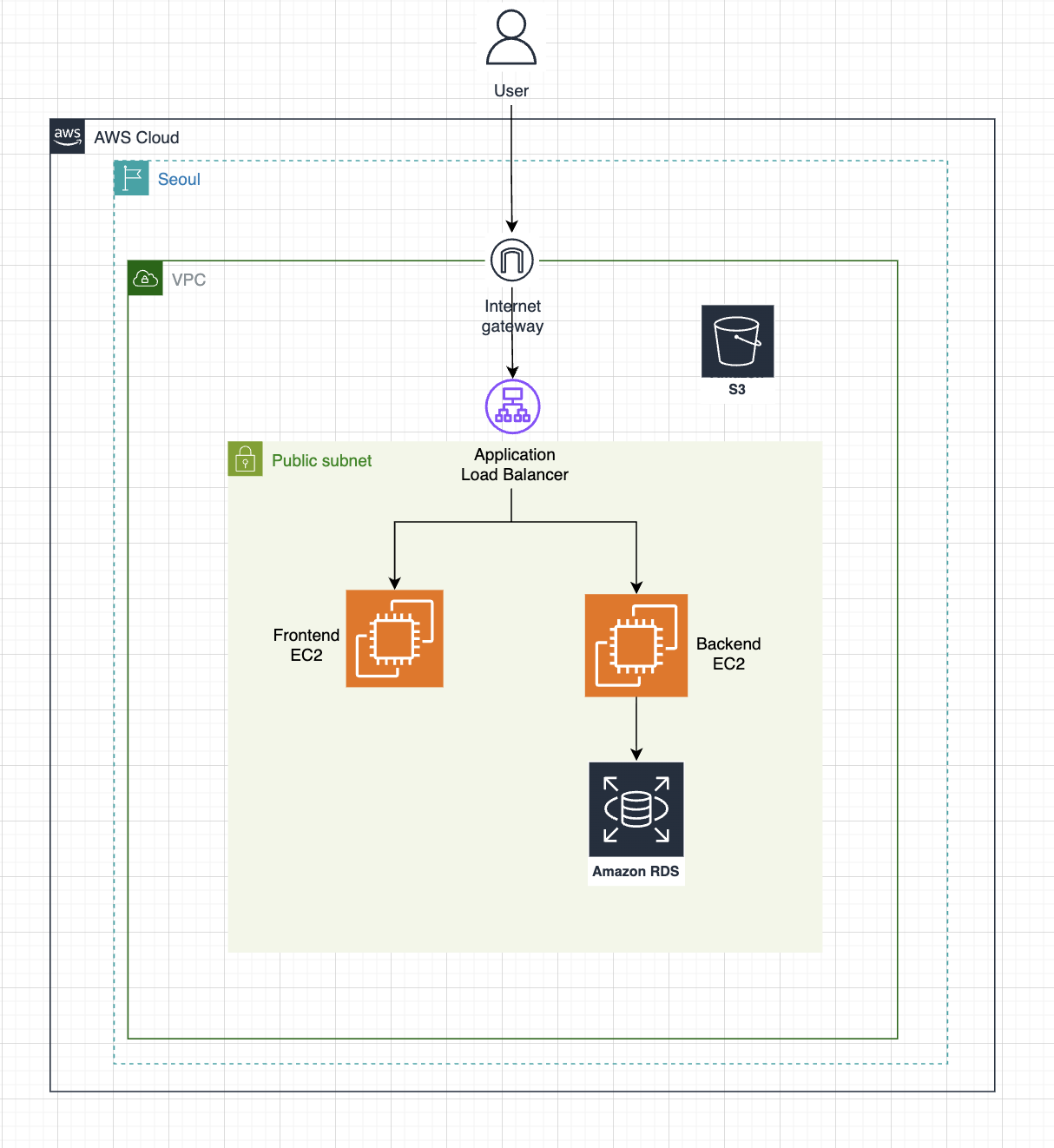
🌐 최종 네트워크 구성도
이 프로젝트에서 설계한 최종 아키텍처는 아래와 같습니다.
단일
EC2에서 시작해, 다중EC2+ALB+RDS+S3조합으로 확장된 구조입니다.
처음부터 과한 분산 시스템을 구축하기보다, 학습·운영·확장성 사이의 균형을 맞춘 최소 아키텍처를 만드는 것에 집중했습니다.
현재 구성은 아래와 같은 성격을 가집니다:
-
Frontend / Backend
EC2분리 → SPOF 제거 & 운영 용이성 향상 -
RDS로 DB 운영 부담 제거 → 안정성 확보 -
S3로 파일 저장 분리 → 인스턴스 교체/스케일링과 완전 분리 -
ALB로HTTPS인증서 일원화 + URL 기반 라우팅 적용 -
모든 리소스는
Public Subnet에 있지만 SG 최소 권한으로 안정성 확보
이 구조는 단순하지만 실제 서비스 아키텍처의 핵심 요소를 모두 갖추었다고 생각합니다. 그리고 무엇보다 중요한 점은, 이 상태 그대로도 언제든 다음과 같은 방향으로 자연스러운 확장이 가능한 상태입니다.
-
서비스 규모가 커지면 →
ASG로 확장 -
트래픽 증가 시 →
ALB가 자동 분배 -
DB 부하 증가 시 →
RDSRead Replica 추가 -
파일 트래픽 증가 시 →
S3+CloudFront적용 -
보안 요구가 늘면 →
Private Subnet단계로 전환 -
로그 중앙화 및 Observability 도입 →
CloudWatch,OpenSearch적용
🔥 트러블 슈팅
프로젝트를 최종 아키텍처로 전환하는 과정에서 여러 문제들이 발생했고, 이를 해결하면서 인프라 전반에 대해 더 깊이 이해할 수 있었습니다. 주요 이슈들은 아래와 같습니다.
1️⃣ FE/BE Docker 컨테이너는 정상 실행되는데 화면이 열리지 않는 문제
다중 EC2 환경으로 전환한 뒤, 각 서버에서 docker compose up을 실행하면 컨테이너는 정상적으로 떠 있었지만 정작 브라우저에서 접속이 되지 않는 문제가 발생했습니다.
원인을 확인해보니, 기존에는 하나의 docker-compose 내부에서 FE/BE 컨테이너가 내부 네트워크로 통신했기 때문에 포트를 외부로 노출할 필요가 없었습니다.
하지만, EC2를 완전히 분리한 이후에는 프론트(3000) / 백엔드(8080) 각각의 포트를 외부로 매핑해야 했는데 이 설정이 누락되어 있었습니다.
해결: 각
EC2의docker-compose파일에ports:설정을 추가하여 문제를 해결했습니다.
2️⃣ ALB DNS로는 정상 접속되지만, 도메인 접속 시 502가 발생한 문제
ALB DNS로 접속하면 서비스가 정상적으로 동작했지만,
연결한 도메인으로 접속할 경우 502 Bad Gateway 오류가 발생했습니다.
원인은 ALB의 기본 헬스체크 포트가 80인데 실제 애플리케이션은 3000(프론트) / 8080(백엔드) 에서 동작하고 있었기 때문에
헬스체크가 모두 실패하며 Target Group이 “비정상” 상태로 분류되고 있었습니다.
헬스체크가 실패하면 ALB는 해당 서버로 트래픽을 전달하지 않기 때문에 도메인 접속이 되지 않았던 것입니다.
해결: 각
Target Group의 헬스체크 포트를 서비스 포트(3000, 8080)로 변경하여 정상 등록되도록 수정했습니다.
3️⃣ HTTPS에서는 프론트는 열리는데 백엔드 API만 502가 발생한 문제
HTTPS 적용 후 프론트엔드는 정상적으로 열렸지만, 백엔드 API 요청만 502가 발생하는 문제가 있었습니다.
문제는 백엔드 Target Group의 프로토콜이 HTTPS로 설정되어 있었다는 점이었습니다.
이 경우 ALB에서 받은 HTTPS 패킷이 그대로 백엔드(Tomcat)로 전달되는데, Tomcat은 이미 ALB에서 복호화된 HTTP를 기대하기 때문에 해당 패킷을 파싱하지 못합니다.
해결:
HTTP/HTTPS리스너 모두 동일한 라우팅 규칙을 갖도록 설정해 아래와 같이 지정했습니다./api/* → Backend(HTTP 8080) / → Frontend(HTTP 3000)즉,
ALB에서HTTPS를 Termination하고 백엔드에는HTTP로 전달하도록 정리하니 문제 없이 동작했습니다.
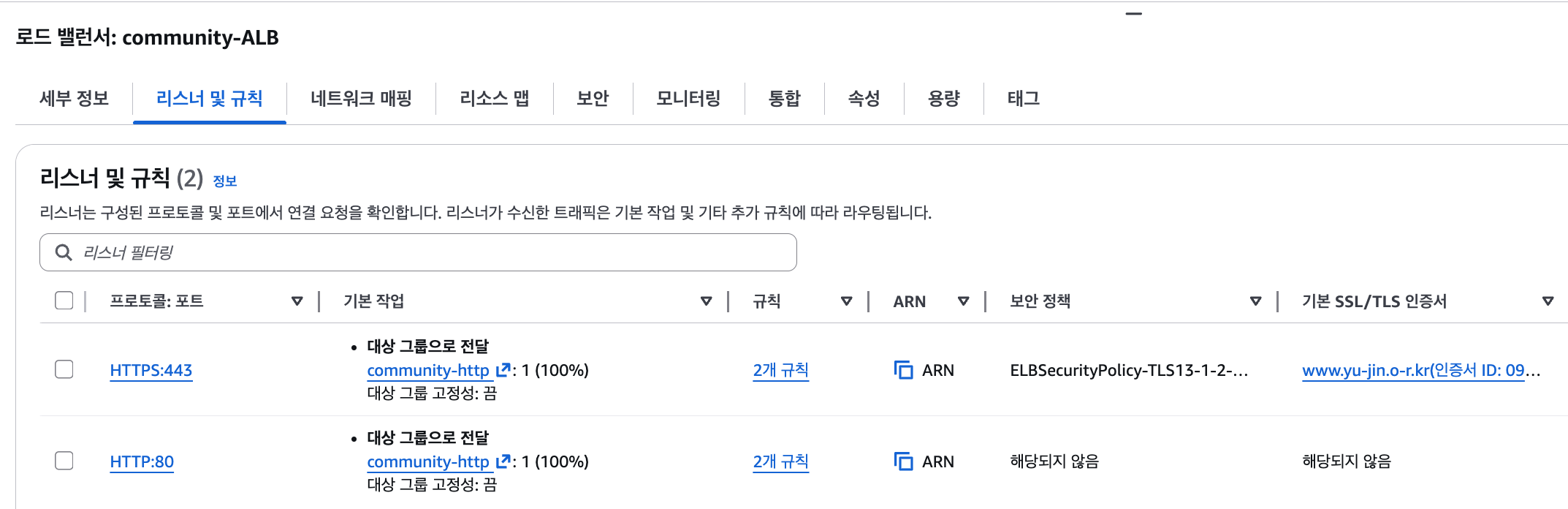
4️⃣ RDS 연결 오류: Public Key Retrieval is not allowed
백엔드에서 RDS로 연결을 시도할 때
Public Key Retrieval is not allowed 오류가 발생했습니다.
MySQL 8.x의 기본 인증 방식인 caching_sha2_password를 사용할 경우,
클라이언트가 서버의 public key를 자동으로 요청하도록 허용해야 하는데
해당 옵션이 빠져 있었고, .env.prod에 저장된 DB 계정 정보도 일부 잘못되어 있는 상태였습니다.
해결 : application.yml의 datasource URL에 allowPublicKeyRetrieval=true 옵션을 추가하고,
.env.prod의 DB 접속 정보를 RDS 계정으로 수정하여 정상 연결을 확인했습니다.
▶️ 최종 배포 결과 확인하기
📝 회고
이번 프로젝트는 12주 동안 진행된 KTB 클라우드 과정의 개인 프로젝트였고,
개발부터 배포, 처음부터 끝까지 직접 설계해본 첫 경험이었습니다.
새롭게 시도해보는 기술들이 많아서 시간도 많이 들었고,
“왜 이렇게 설계해야 하는가?”라는 질문에 스스로 답하기 위해
수많은 시행착오를 겪으며 구조를 계속 다듬어갔습니다.
처음부터 과한 인프라를 짜기보다는,
필요할 때 점진적으로 확장할 수 있는 구조를 스스로 이해하고 설계했다는 점이
이번 프로젝트에서 가장 큰 의미라고 생각합니다.
돌이켜보면, 단순히 동작하는 서비스를 만들었다기보다
스스로 고민하고 결정한 아키텍처를 구축했다는 점에서 큰 성장을 이룬것 같습니다.
아직 보완하고 싶은 부분도 많지만, 이번 경험이 앞으로의 프로젝트에서
더 깊이 있는 설계와 안정적인 운영을 할 수 있는 기반이 될 것이라고 생각합니다.
앞으로 진행될 부하 테스트와 팀 프로젝트에서는 이번에 설계한 최소 아키텍처를 기반으로 더 안정적이고 실무에 가까운 네트워크 구성을 시도해볼 계획입니다.
