💡 SQL(Structured Query Language)
- Sequel이란 언어의 시초
- 표준 질의어로 채택되어 널리 쓰이는 관계형 질의언어
- 관계대수나 관계해석은 확실한 이론적 배경을 제공하나 상용으로 쓰이기에는 어렵고 적절 X → SQL 사용
SQL 의 구성 : DDL & DML
DDL(데이터 정의(Definition) 언어)
- 데이터 저장 구조를 명시
- 테이블 스키마의 생성, 기본키 외래키 설정,정의, 수정, 삭제
DML(데이터 조작(Manipulation) 언어)
- 사용자가 데이터를 접근하고 조작할 수 있게 하는 언어
- 레코드의 검색, 삽입, 삭제, 수정
DDL (데이터 정의 언어)
테이블 생성
create table department
(
dept_id varchar2(10),
dept_name varchar2(20) not null,
office varchar2(20),
constraint pk_department primary key(dept_id)
);
//constraint pk_department primary key(dept_id)
//제약조건을 지정.
//이 테이블의 **기본 키(primary key)**는 dept_id 컬럼.
//pk_department라는 제약조건 이름을 부여함.
//나중에 이 제약조건을 수정하거나 삭제할 때 이 이름을 사용 가능.create table student
(
stu_id varchar2(10),
resident_id varchar2(14) not null,
name varchar2(10) not null,
year int,
address varchar2(10),
dept_id varchar2(10),
constraint pk_student primary key(stu_id),
constraint fk_student foreign key(dept_id) references department(dept_id)
);
// constraint fk_student foreign key(dept_id) references department(dept_id)
- dept_id는 외래 키(foreign key).
- 외래 키는 다른 테이블의 기본 키를 참조함.
- 여기서는 department 테이블의 dept_id를 참조.
- 즉, student 테이블의 dept_id 값은 반드시 department 테이블에 존재하는 값이어야 함.
- 제약조건 이름: fk_student
테이블 삭제
drop table <테이블 이름>- 다른 테이블에서 외래키로 참조되는 경우 삭제할 수 없음
테이블 수정
// 필드 추가
alter table <테이블 이름> add <추가할 필드>
alter table student add age int
// 필드 삭제
alter table <테이블 이름> drop column <삭제할 필드>
alter table student drop column age표준 SQL과 오라클의 데이터 타입
| 분류 | 표준 SQL | 오라클 | 설명 |
|---|---|---|---|
| 문자 | char(n) | char(n) | 길이가 n byte인 고정길이 문자열 오라클: 최대 2000byte까지 지정 가능 |
varchar(n) | varchar2(n) | 최대 길이 n byte의 가변길이 문자열 오라클: 최대 4000byte까지 지정 가능 | |
| 숫자 | int | int | 정수형 |
float | float | 부동 소수형 | |
| 날짜 | date | date | 년, 월, 일을 갖는 날짜형 오라클의 기본 형식: 'yy/mm/dd' |
| 시간 | time | (미지원) | (표준 SQL의 시간 타입, 오라클에는 직접적 지원 없음) |
timestamp | timestamp | 년, 월, 일, 시, 분, 초를 갖는 날짜시간형 |
DML (데이터 조작 언어)
레코드 삽입
insert into department(dept_it, dept_name, office)
values('920', '컴퓨터공학과', '201호')
insert into department
values ('923', '산업공학과', '207호')- 필드 이름을 명령문에 나열할 경우, 테이블 생성할 때 지정한 순서와 달라도 됨
레코드 수정
- 모든 레코드에 대한 수정 적용시
where 절생략 가능
update <테이블 이름> set <수정 내역> where <조건>
// student 테이블의 모든 학생들의 학년을 하나씩 증가
update student set year = year + 1
update professor set 지위 ='교수', number = '923' where name = '고희석'
레코드 삭제
- where절에 지정된 조건을 만족하는 레코드들 삭제
- where 절 생략 시 모든 레코드 삭제
- 모든 레코드들이 삭제되어도 테이블은 삭제 X
- 외래키로 사용되는 필드에 대해 데이터를 삽입할 때
delete from <테이블 이름> where <조건>
delete from professor where name='김태석'레코드 검색
select <필드리스트>
from <테이블리스트>
where <조건>
//중복된 레코드를 제거 -> distinct
select distinct address from student
//select 절에 필드이름 외 산술식이나 상수 사용 가능
select name, 2012-year_emp
from professor
//컴퓨터공학과 3학년 학생들의 학번 검색
select student.stu_id
from student, department
where student.dept_id = department.dept_id and
student.year = 3 and
department.dept_name='컴퓨터공학과'COMMIT
- 대부분의 DBMS는 명령어를 실행하면 변경 결과를 즉시 데이터베이스에 반영하지 않고 가지고 있다가
COMMIT명령을 내리면 그때 영구적으로 데이터베이스에 반영 - 취소 불가능
COMMIT전에는ROLLBACK으로 작업 취소가능set autocommit on→ 자동 커밋
집계함수
- count, sum, avg, max, min
select절과having절에서만 가능- sum, avg는 숫자형 데이터 타입을 갖는 필드에서만 가능
COUNT
NULL은 계산에서 제외- 단,
count *→ 레코드 수 계산
count(distinct<필드이름>) // 서로 구별되는 값의 개수
ORDER BY
- 정렬
SELECT문 맨 마지막에- asc, desc
SELECT name, student_id
from student
where year=3 or year=4
order by name,stu_id // 학심 이름으로 오름차순 정렬, 같은 이름은 stu_id로 정렬GROUP BY
- select 절에 집계함수가 사용될 경우 다른 필드는 select 절에 사용할 수가 없음
- ⇒
GROUP BY사용해야함 !! - Null속성도 그룹화
select ename, max(sal) from emp // ⚠️에러발생
// 부서별 최고 금여
select deptno, max(sal) from emp group by deptno
//deptno별 레코드 개수 출력
select deptno, count(*)
from student
group by deptno
select dname, count(*), avg(sal), max(sal), min(sal)
from emp e, delt d
where e.deptno = d.deptno
group by dnameHaving
- 그룹에 대한 조건 명시
- group 에 대한 조건은 where 절에 사용할 수 없음 ! → having 절 이용
select dept_name, count(*), avg(2012-year_emp), max(2012-year_emp)
from professor p, department d
where d.dept_id = p.dept_id and avg(2012-year_emp)>=10 //⚠️에러발생
group by dept_name
//올바른 표현식
select dept_name, count(*), avg(2012-year_emp), max(2012-year_emp)
from professor p, department d
where d.dept_id = p.dept_id
group by dept_name
having avg(2012-year_emp)>=10💡SQL 실행 순서
from → where → group by → having → select → distinct → order by → rownum
where, having, group by 절을 모두 함께 사용할 경우
1. where 절에 명시된 조건을 만족하는 레코드들 검색
2. group by 절에 명시된 필드값이 서로 일치하는 레코드들끼리 그룹지어 집계함수 적용
3. 집계함수 적용한 결과들 중 having절을 만족하는 결과만 출력
Like 연산자
- 문자열에 대해서는 일부분만 일치하는 경우를 찾아야할 때 사용
- = 대신
like연산자 사용
//student 테이블에서 김씨 성을 가진 학생들을 찾아라
select * from student where name like '김%'재명명 연산
<원래 이름> as < 새로운 이름>- as 생략 가능
- Oracle에서 컬럼(속성) 은 as 사용가능, 테이블 별칭은 as키워드 사용X
- 실제 테이블 이름이 수정되거나 필드 이름이 바뀌는 것은 X
- 질의를 처리하는 과정 동안만 일시적
// ♦️ 테이블 재명명
student 테이블과 department 테이블을 조인하여 학생들의 이름과 소속 학과 이름 검색
select s.name, d.dept_name
from student s, department d
where s.dept_id = d.dept_id
// ♦️ 필드의 재명명
student name 이름, position 직위, 2012-year_emp 재직연수 from professorNULL 처리
is null,is not null산술 표현식(+, - ,* ,/)의 결과는 입력값중 하나라도 null인 경우 null그룹함수(sum, avg, min, max)는 NULL 무시count는 일반적으로 NULL이 아닌 값을 세지만,COUNT(*)는 NULL 상관없이 전체 행의 수를 리턴
SELECT stu_id
FROM takes
WHERE grade <> 'A+'; // 👉🏻<> : 오라클에서의 같지 않다
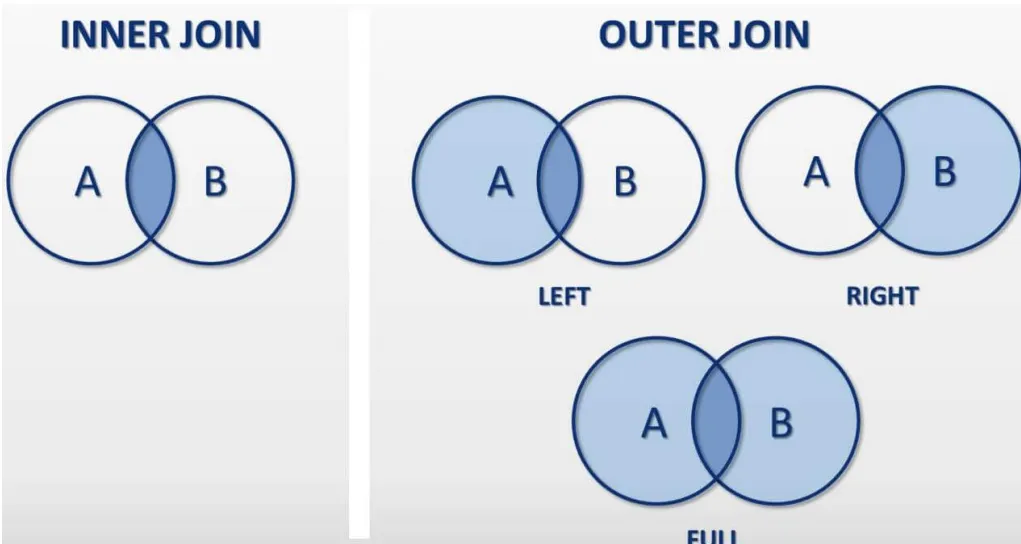
-> grade 의 필드 값이 널인 레코드에 대해서는 질의 결과에 포함 XInner Join
- 일반 조인(equi-join)과 의미가 동일
//형식
select <컬럼명>
from <테이블1> (inner) join <테이블2>
on table1.컬렴명 = table2.컬럼명
select <컬럼명>
from <테이블1> (inner) join <테이블2>
using 같은 컬럼명Natural Join(자연조인)
- 두 테이블 간의 동일한 이름을 갖는 모든 칼럼들에 대해 equi(=) join
- 두 테이블에 동일한 이름의 컬럼이 있을 때만 동작 !
select name, stu_id, dept_name
from student natural join departmentOuter Join
select title, credit, year, semester
from course left outer join class
using (course_id)
select title, credit, year, semester
from course left outer join class
on (course.course_id = class.course_id)
select title, credit, year, semester
from course, class
where course.course_id = class.course_id (+) //left outer join
select title, credit, year, semester
from course, class
where course.course_id (+) = class.course_id //right outer join- where 절에서 기준이 되는 테이블 반대 테이블 조건 컬럼 뒤에 (+)를 붙힘
- Left outer : 오른쪽
- Right outer : 왼쪽
- full outer join : 양쪽 테이블에서 서로 일치하는 레코드가 없을 경우, 해당 레코드들도 결과 테이블에 포함시키며 나머지 필드에 대해서는 모두
NULL삽입
카티션 프로덕트
- FROM 테이블1,테이블2
- FROM 테이블1 CROSS JOIN 테이블2
무결성
- Intefrity constraints (무결성 제약 조건)
- not null, unique,…
UNIQUE
- 기본키와 UNIQUE 모두 특정 속성에 중복된 값이 저장되는 것을 방지
- 차이점은 기본키 : NULL 값 X , UNIQUE : NULL 값 가능
- 기본키 = NOT NULL + UNIQUE
create table univ (
univ_name varchar(20),
tel char(12),
UNIQUE(univ_name)String operation
concat(): 문자열 연결- 오라클에서는 오직 두개의 인수만 가능
||: concat 연산자select name || ‘,’ || dept_name→ name,dept_name 출력
upper(),lower(): 대문자, 소문자로 변환length(): 문자열 길이substr(문자열, 1, 5): 1부터 5번째 글자의 문자열 추출
