
이번 주차부터는 Spring Boot에서 가장 중요하다고 느껴지는 JPA를 본격적으로 학습했다.
단순히 CRUD를 구현하는 것을 넘어서
객체와 데이터베이스를 어떻게 연결하고 관리하는지에 대한 흐름을 이해할 수 있었고
실제로 연관관계 매핑과 API 구현까지 진행해보며 JPA의 동작 방식을 조금 더 체감할 수 있었다.
바로 6주차 스터디 개념 정리랑 미션 내용 정리해보겠습니다 ~!
1. 객체 지향과 RDB의 패러다임 차이
자바는 객체 중심으로 데이터를 관리하지만, 데이터베이스는 테이블 중심으로 데이터를 저장한다.
이 과정에서 객체 ↔ 테이블 변환 작업이 반복되며 패러다임 불일치가 발생한다.
예를 들어 JDBC만 사용할 경우:
- 직접 SQL 작성
- 객체와 테이블 매핑
- CRUD 반복 작업
등을 개발자가 모두 처리해야 한다.
이 문제를 해결하기 위해 등장한 것이 JPA이다.
2. JPA란?
JPA(Java Persistence API)는 자바 ORM 기술의 표준 인터페이스이다.
객체와 데이터베이스 테이블을 자동으로 매핑해주며, 반복적인 SQL 작성을 줄여준다.
대표 구현체:
- Hibernate
- JPA의 핵심 장점:
- 객체 중심 개발 가능
- 생산성 증가
- 유지보수 편리
- SQL 자동 생성
3. 영속성 컨텍스트(Persistence Context)
JPA의 핵심 개념 중 하나로, 엔티티를 관리하는 논리적 공간이다.
주요 기능:
- 1차 캐시
- 변경 감지(Dirty Checking)
- 쓰기 지연 SQL 저장소
- 지연 로딩
1차 캐시
같은 엔티티를 다시 조회할 경우 DB가 아닌 캐시에서 조회한다.
→ 불필요한 SQL 감소
변경 감지(Dirty Checking)
엔티티 값을 수정하면 JPA가 변경 사항을 자동으로 감지한다.
member.setName("UMC");별도의 update 쿼리를 작성하지 않아도 commit 시점에 UPDATE SQL이 실행된다.
4. flush와 commit 차이
flush
- 변경 내용을 DB에 반영
- 트랜잭션은 유지됨
commit
- flush 이후 최종 저장
- 트랜잭션 종료
즉:
flush → SQL 반영
commit → 최종 확정5. 연관관계 매핑
JPA에서는 객체 간 관계를 어노테이션으로 표현한다.
대표 어노테이션:
@ManyToOne@OneToMany@OneToOne
예시:
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;6. 즉시 로딩 vs 지연 로딩
즉시 로딩(EAGER)
연관 객체를 함께 조회한다.
장점:
- 바로 사용 가능
단점:
- 불필요한 조회 발생 가능
- N+1 문제 발생 위험
지연 로딩(LAZY)
실제로 사용할 때 조회한다.
장점:
- 성능 최적화에 유리
- 실무에서 많이 사용
7. N+1 문제
연관 데이터를 조회하는 과정에서 불필요한 쿼리가 반복 실행되는 문제이다.
예시:
- 회원 목록 조회 1번
- 회원마다 게시글 조회 N번
→ 총 N+1번 SQL 실행 : 성능 저하의 주요 원인이 된다.
8. JPQL
JPQL은 엔티티 객체를 대상으로 작성하는 객체 지향 쿼리 언어이다.
SQL과 유사하지만 테이블이 아닌 엔티티 기준으로 동작한다.
@Query("SELECT m FROM Member m WHERE m.name = :name")9. Fetch Join과 @EntityGraph
Fetch Join
연관 엔티티를 한 번의 쿼리로 함께 조회하는 기능
→ N+1 문제 해결에 사용
@EntityGraph
Fetch Join을 어노테이션 기반으로 편리하게 사용하는 방식
@EntityGraph(attributePaths = {"orders"})Repository 메서드와 함께 사용할 수 있어 코드가 간결함
이번주차 과제
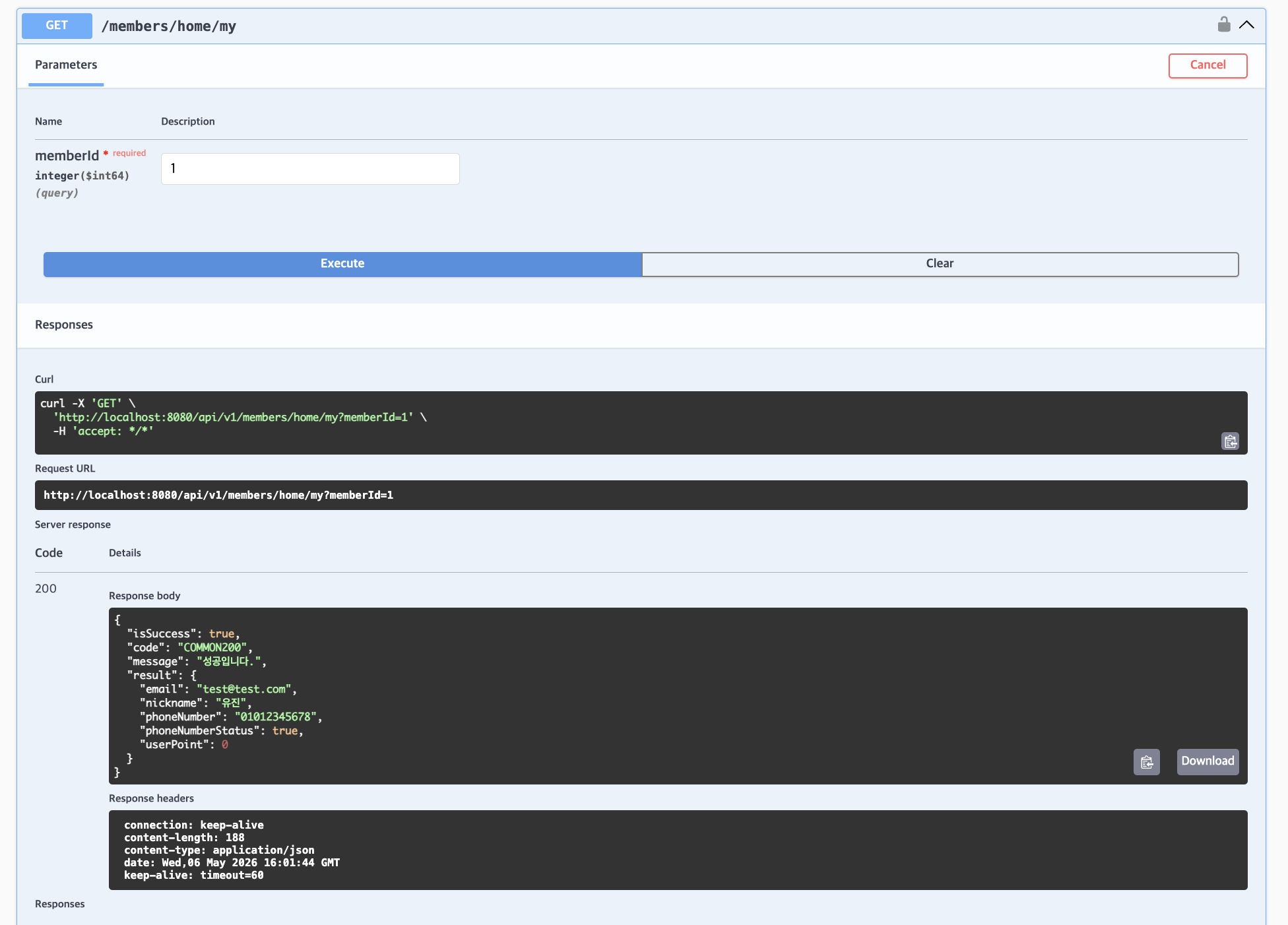
미션 1) 마이페이지 조회 API 구현
GET /members/home/my
- memberId를 기반으로 사용자 정보 조회하도록 memberId params 추가
- 사용자 이름, 이메일, 포인트 반환
- 실행결과
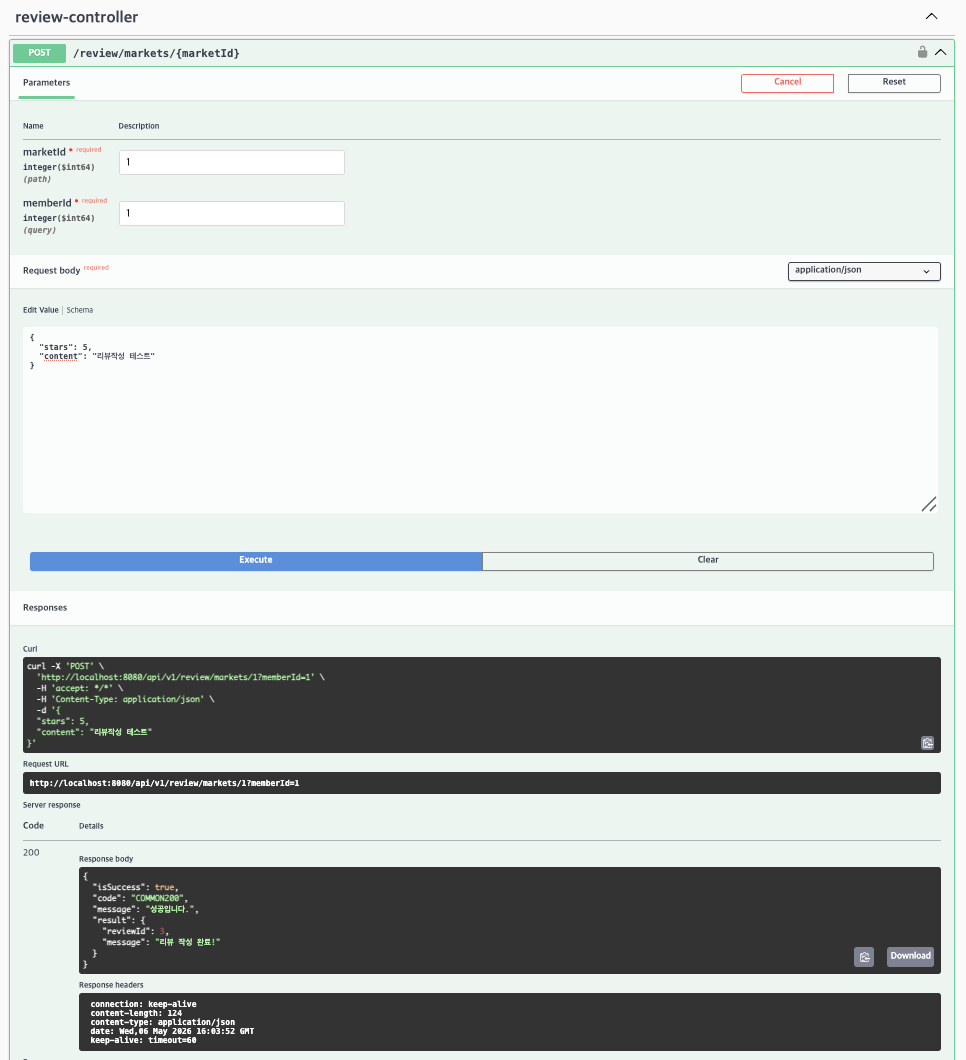
미션 2) 리뷰 작성 API 구현
POST /review/markets/{marketId}
- memberId와 marketId를 기반으로 리뷰 작성 기능 구현
- 리뷰 저장 후 reviewId 및 성공 메시지 반환
- 실행결과
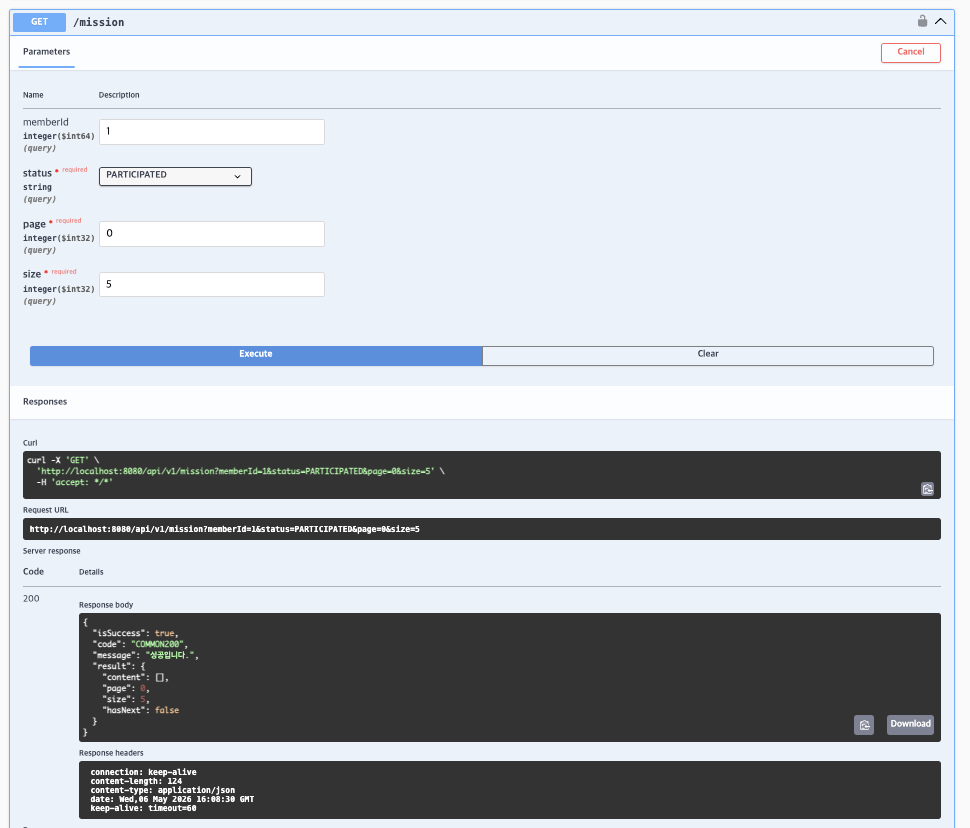
미션 3) 진행중 / 완료 미션 조회 API 구현
GET /mission
- memberId와 ParticipatedStatus(CHALLENGING / COMPLETE)를 기반으로 참여 미션 목록 조회
Pageable기반 페이징 처리 구현@query+ JOIN FETCH를 사용하여 Mission 연관 데이터 조회
@query + JOIN FETCH를 사용하여 Mission 연관 데이터 조회
@Query("""
SELECT p
FROM Participate p
JOIN FETCH p.mission m
WHERE p.member.id = :memberId
AND p.status = :status
""")- 실행 결과
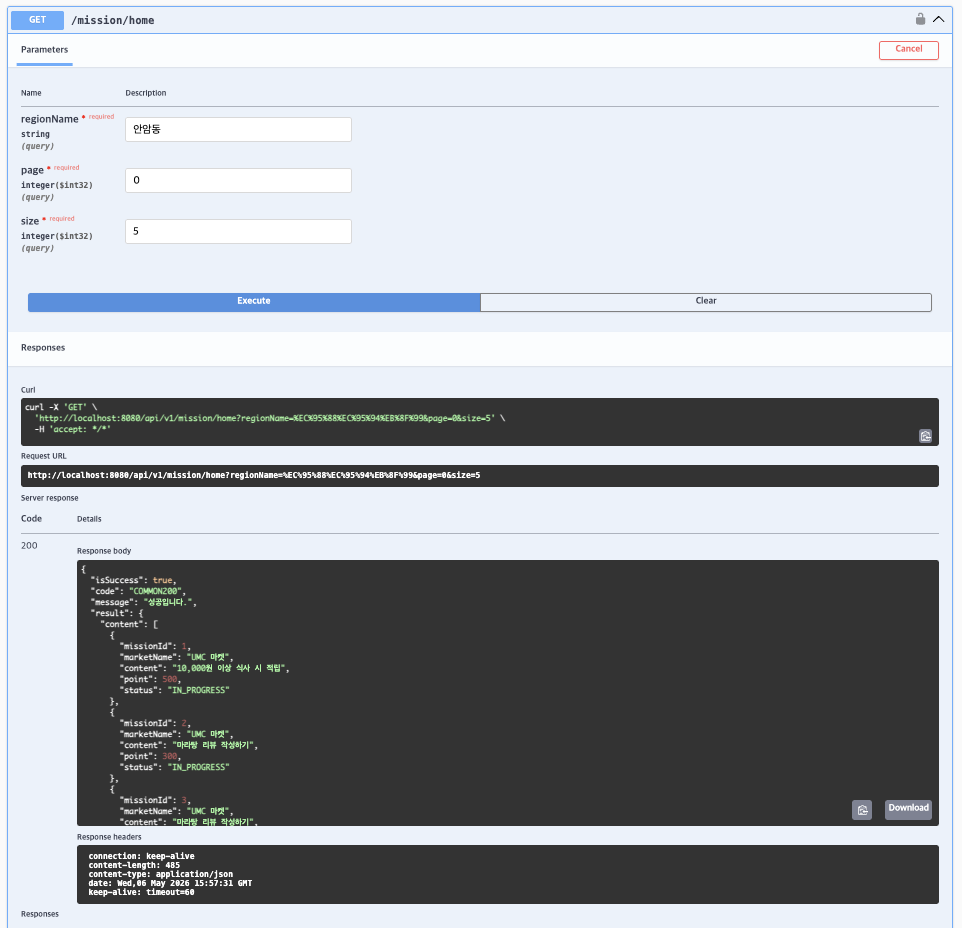
미션 4) 홈 화면 지역별 진행 중인 미션 조회 API 구현
GET /mission/home
- regionName 기반으로 특정 지역의 진행중(
IN_PROGRESS) 미션 목록 조회 Pageable기반 페이징 처리 구현@query+ JOIN FETCH를 사용하여 Market, Region 연관 데이터 조회
@Query("""
SELECT m FROM Mission m
JOIN FETCH m.market mk
JOIN FETCH mk.region r WHERE r.name = :regionName
AND m.missionStatus = :status
""")- 실행결과
6주차 스터디 느낀점
이번 주차를 통해 JPA가 단순히 SQL을 대신 작성해주는 기술이 아니라,
객체 중심으로 개발할 수 있도록 도와주는 ORM 기술이라는 점을 이해할 수 있었다.
특히 연관관계 매핑과 지연 로딩, Fetch Join을 직접 적용해보며
성능 최적화 관점에서도 많은 고민이 필요한 기술이라는 점을 느꼈고
앞으로는 단순 기능 구현을 넘어
쿼리 최적화와 객체 그래프 탐색 흐름까지 함께 고려하며 개발하는 연습을 해야겠다고 생각했습니다 .
