
Git이란
버전 관리 시스템 (VCS : Version Control System)
버전 관리 시스템: 파일 변화를 시간에 따라 기록했다가 나중에 특정 시점의 버전을 다시 꺼내올 수 있는 시스템
버전 관리는 쉽게 말해서 변경 내용에 대한 히스토리를 기록하는 것과 같다고 생각하면 된다.
흔히 디자이너의 최종파일 이라고 하는 짤을 보게 되면

어떠한 수정 사항이 생길 때마다 다시 작업해서 새로운 파일을 남겨두고 하는걸 볼 수 있다..(디자이너분들 화이팅!!)
저런 것 또한 이름만 제대로 붙이면 (날짜라던가 수정사항에 대한 내용이라던가..) 버전 관리를 한 것과 같을 수 있다!
버전 관리 시스템을 사용하면!
- 각 파일을 이전 상태로 되돌릴 수 있다.
- 시간에 따라 수정 내용을 비교해볼 수 있다.
- 어떤 사람이 작성한 것인지도 알 수 있다.
- 파일을 잃어버리거나 잘못 수정했을 때도 쉽게 복구 가능하다.
git에서는 commit 하는 시점 자체를 하나의 버전으로 생각해서 commit 자체를 버전으로 보면 된다.
이것을 버전관리, 형상 관리라고도 한다.
(엄밀히 말하면 형상 관리 안에 버전 관리가 포함된다.)
Git의 History!
최초의 버전관리, 로컬 버전 관리 (로컬VCS)
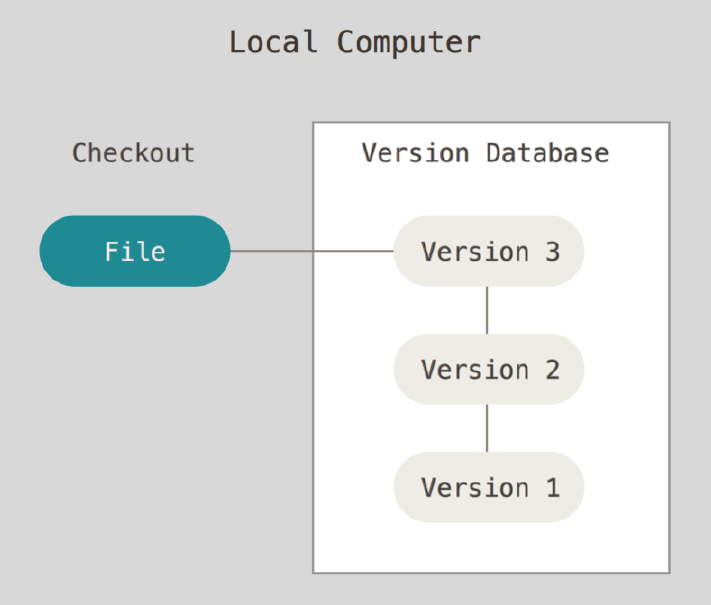
각자의 로컬 컴퓨터에 각자 버전을 구분할 수 있도록 파일의 변경 사항을 관리
이전에는 각자 컴퓨터에 자신만의 규칙으로 버전 관리를 해서 파일을 관리했다.
가장 쉬운 방법이긴 하지만 버전이 높아질 수록 보관해야하는 파일이 많아지기도 하고, 실수로 폴더를 지워버리거나 파일명을 제대로 남기지 않는다던가 하는 문제점이 생길 수 있다.
개발자들은 로컬 VCS 도구를 만들었는데, 이 로컬 VCS는 간단한 데이터베이스를 사용하여 파일의 변경 정보를 관리할 수 있게 했다.
많이 쓰는 VCS 도구 중에 RCS(Revision Control System)라고 부르는 것이 있는데 오늘날까지도 아직 많은 회사가 사용하고 있다고 한다.
협업하자! 중앙집중식 버전 관리! (CVCS : Central VCS)
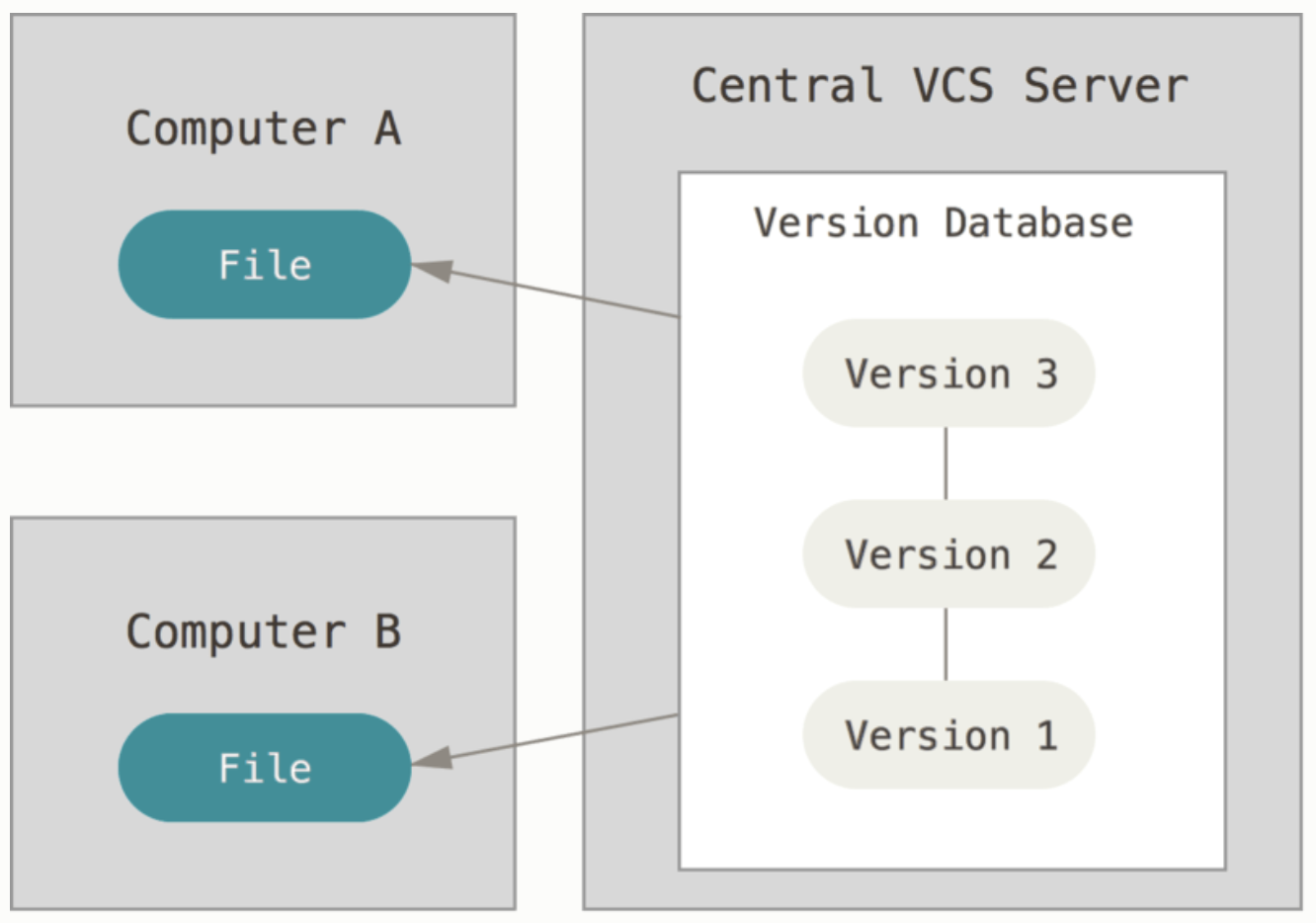
파일을 관리하는 서버가 별도로 있고 클라이언트가 중앙 서버에서 파일을 받아서 사용
로컬 버전 관리를 하다가 좀 더 개선해야할 상황이 생기게 되었다.
프로젝트를 진행하다보면 개발자 혼자 진행하는 것이 아니라 다른 개발자들과 협업하며 작업하는 것이 대부분일텐데, 로컬 VCS로 버전관리를 하는 상황에서 다른 개발자와 작업한 내용을 합칠 때..!
서로 각자의 로컬에 버전 관리를 했기 때문에 직접 만나서 각자의 파일을 비교하며 합칠 수 밖에 없는 굉장히 비효율적인 방법밖에 없다..
위와 같은 문제점을 해결하기 위해 CVCS가 개발되었다.
CVCS는 중앙에 하나의 서버를 두고 파일을 관리하는 서버로 사용하는 것이다.
개발자들은 그 서버에 업로드를 하고, 다운받기도 하면서 로컬 VCS를 사용할 때보다는 훨씬 쉽게
협업도 하고 버전 관리도 할 수 있게 되었다.
하지만 중앙 집중식 버전 관리에도 단점이 있는데 서버에 문제가 발생한 경우이다.
commit을 하려면 서버에서 한번 다운받고 해야하는데 서버에 연결을 할 수 없는 상황이면
commit 자체도 할 수 없기 때문이다. (git 기준 commit)
때문에 서버에 문제가 생긴 상황에서는 다른 사람과 협업도 할 수 없고 사람들이 하는 일을 백업할 방법도 없다.
그리고 중앙 데이터베이스가 있는 하드디스크에 문제가 생기면 프로젝트의 모든 히스토리를 잃는다..(끔찍)
git 바로 이전 세대에서 굉장히 많이 사용된 SVN이 대표적인 중앙 집중식 버전 관리 시스템이다.
SVN(SubVersion)?
프로젝트 소스는 SVN 서버(trunk)에 위치하고 자신의 로컬에 그 소스를 다운 받아(update) 수정 및 추가 후
다시 업로드(commit)하는 방식으로 사용된다.
- 보통 대부분의 기능을 완성해놓고 소스를 중앙 저장소에 commit
- commit의 의미 자체가 중앙 저장소에 해당 기능을 공개한다는 의미
- 개발자가 자신만의 version history를 가질 수 없다
- commit한 내용에 오류가 있을 시 다른 개발자에게 바로 영향을 끼치게 됨지금의 git의 형태, 분산 버전 관리 (DVCS : Distribution VCS)
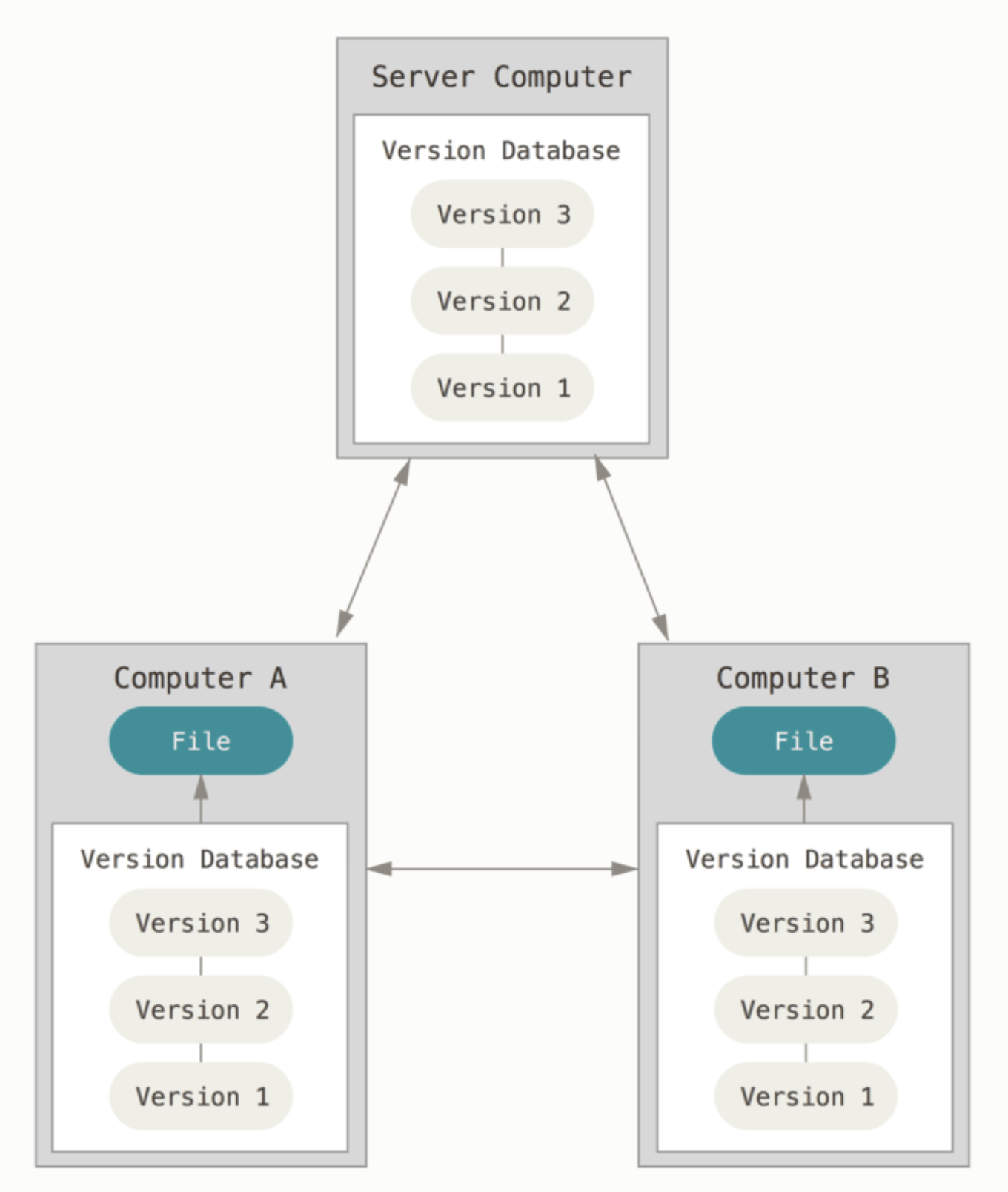
서버에서도, 로컬에서도 똑같이 버전 관리 가능. 저장소를 히스토리와 더불어 전부 복제!
서버에 문제가 있을 때 사용하지 못하는 CVCS에서 한단계 업그레이드된 것이 바로 DVCS, 분산 버전 관리이다.
서버에도 우리가 원격으로 변경 사항들을 넣을 수 있지만 로컬에서도 똑같이 버전 관리를 할 수 있다.
DVCS에서의 클라이언트는 단순히 파일의 마지막 스냅샷을 checkout하는 것이 아니라 저장소를 히스토리와 더불어 전부 복제한다.
소스코드를 여러 개발 pc와 저장소에 분산시켜서 관리하기 때문에 중앙 서버에 문제가 생겨도
로컬 저장소에 commit할 수 있고, 로컬 저장소들을 이용해 중앙 저장소의 복원도 가능하다!
Git의 탄생배경
간단하게 탄생 배경에 대해 알아보자면~
Linux Kernel Team에서 버전관리를 로컬로 하고 있었는데
2002년 래리 맥보이라는 미국 프로그래머가 버전관리를 좀 더 쉽게 할 수 있게 해주는 BitKeeper라는 것을 개발해서 Linux팀도 BitKeeper를 도입해 사용하고 있었다.
2005년이 되자 래리 맥보이는 무료로 제공하던 BitKeeper의 유료화를 선언하고,
편하게 쓰고 있던 Linux팀은 직접 버전 관리를 할 수 있는 것을 만들게 됐다고 한다..
그래서 만들어낸 것이 바로 git!!
리누스 토르발스라는 리눅스를 만든 개발자가 git도 만들었다는 사실..(역시 천재는 천재)
Git의 특징과 CVCS와의 차이
데이터를 다루는 방법
CVCS
CVCS는 각 파일의 변화를 시간순으로 관리하면서 파일들의 집합을 관리한다.
보통 델타 기반 버전관리 시스템이라고 한다.
델타(delta)?
"두 시점의 스냅샷을 비교하면 델타를 얻을 수 있다" 라고 말하는 것 보면
"델타"란 "수정된 내용"의 의미로 쓰는 것 같다..
델타 = diff 인듯!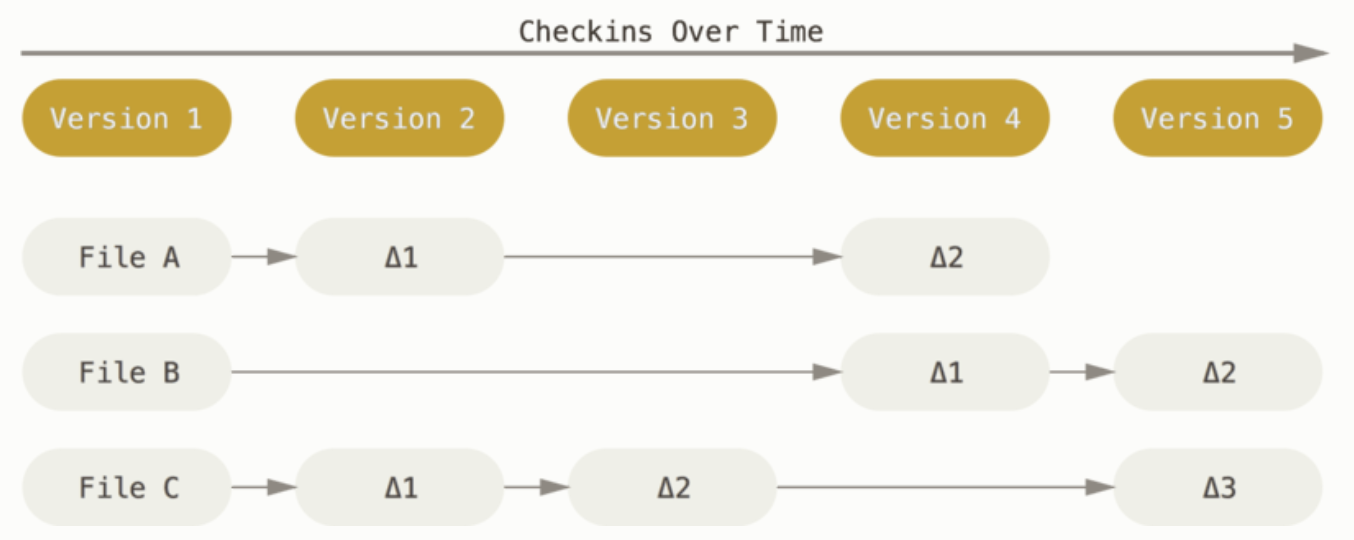
Git (DVCS)
Git은 데이터를 파일 시스템 스냅샵의 연속으로 취급하고 크기가 아주 작다.
commit하거나 프로젝트의 상태를 저장할 때마다 파일이 존재하는 그 순간을 중요하게 여긴다.
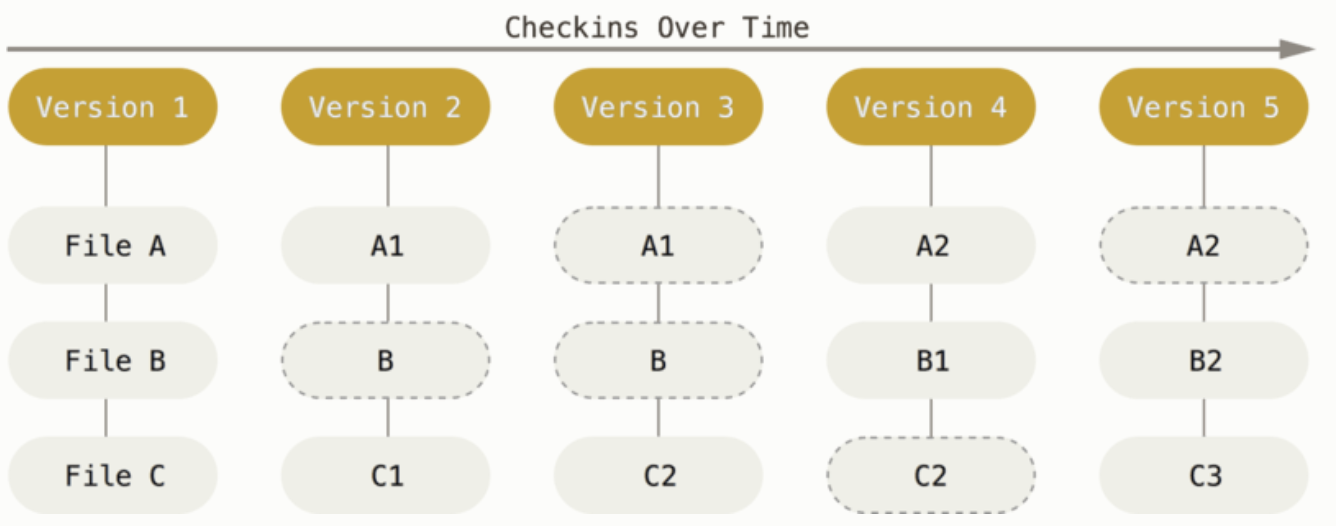
파일이 달라지지 않았으면 성능을 위해 파일을 새로 저장하지 않고, 이전 상태의 파일에 대한 링크만 저장한다.
스냅샷(snapshot)?
특정 시점에서 파일, 폴더 또는 워크스페이스의 상태를 의미.
git에서 스냅샷의 의미는 commit 했을 당시의 시점의 상태를 의미한다.
델타 기반 버전관리보다 git이 더 빠르다고 하는데
"수정한 것"만 저장하는게 더 빠를 것 같지만 "수정한 것"을 추출하기 위해 필요한 과정이 있는데
git은 현재 상태를 그대로, commit 당시의 스냅샷을 저장하기 때문에 더 빠르다고 한다.거의 모든 명령을 로컬에서 실행
Git은 CVCS와 다르게 거의 모든 명령을 로컬에서 실행 (로컬 파일과 데이터만 사용)하기 때문에
네트워크에 있는 다른 저장소가 필요없다.
원격 서버와 동기화(pull, push..)하는 순간을 제외하곤 로컬 디스크에 모든 정보를 가지고 처리하기 때문에
모든 명령이 빠르게 실행 가능하며, 오프라인 환경에서의 작업도 가능하다.
git의 무결성
데이터를 저장하기 전에 항상 체크섬을 구하고 그 체크섬으로 데이터를 관리한다.
체크섬은 Git에서 사용하는 가장 기본적인(Atomic) 데이터 단위이자 Git의 기본 철학이다.
체크섬은 SHA-1 해시를 사용해 만들어지고 만들어진 체크섬은 40자 길이의 16진수 문자열이다.
ex) 24b9da6552252987aa493b52f8696cd6d3b00373
체크섬은 해당 커밋의 고유 번호라고 생각하면 된다!
무결성?
데이터의 정확성과 일관성을 유지하고 보증하는 것을 가리킴SVN과의 차이
SVN (CVCS)
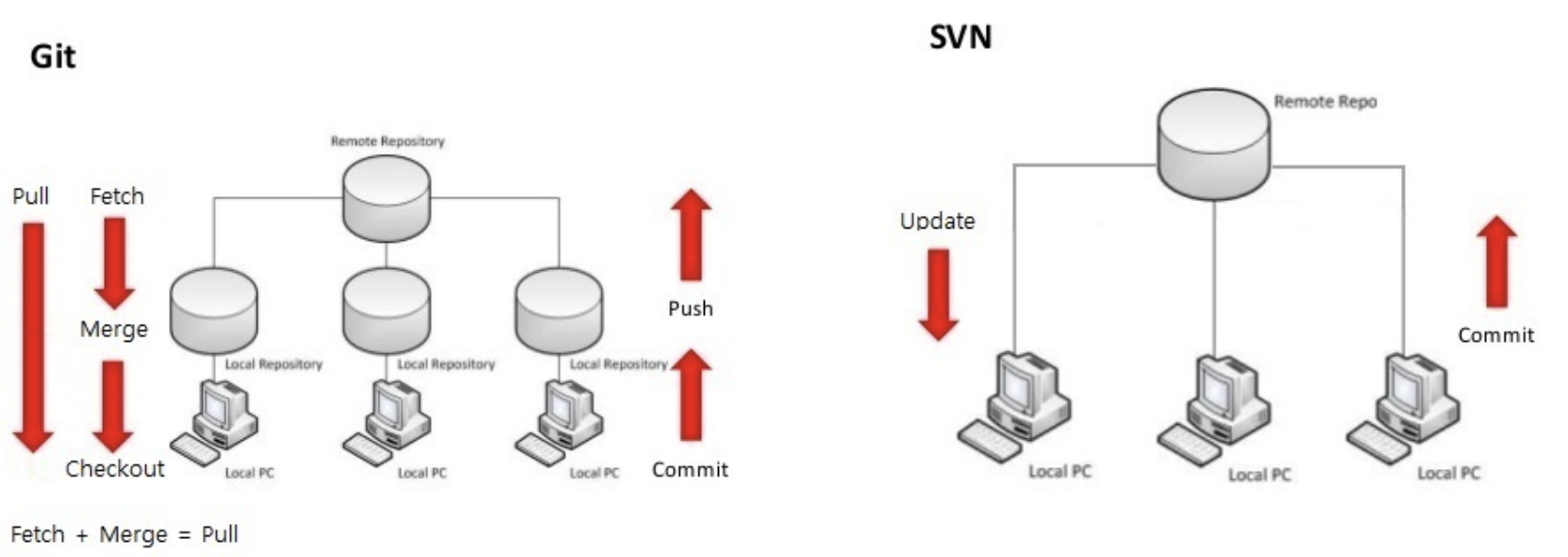
- 내 로컬 pc에서 commit을 하면 바로 중앙저장소에 반영.
- 모든 사람이 중앙 서버에 있는 자료를 받아오고 내가 commit을 하는 순간 모든 사람에게 공유가 됨.
만약 두 사람이 하나의 파일을 동시에 수정하고 commit하는 경우 충돌날 가능성이 높음.
Git (DVCS)
- 내 로컬 pc에서 commit을 하면 로컬 저장소에 반영이 되고 로컬 저장소에서 push를 하면 원격 저장소에 반영이 됨.
- 내가 한 작업물을 원격 저장소에 올리려면 우선 로컬 pc에서 작업 내용을 commit하여 로컬 저장소에 반영한 후,
원격 저장소에서 fetch로 로컬 저장소로 마스터 파일을 받아와서 충돌이 나지 않게 merge를 이용해 합친 다음,
로컬 저장소의 내용을 push하여 원격 저장소에 올리면 그때 다른 사람들에게 작업 내용이 공유됨.
출처
- git 공식 문서
- 팀장님의 완벽한(ㅎㅎ) 발표 자료