예약 관련 서비스 사이드 프로젝트를 진행하던 중에 동시 요청으로 인한 예약 문제를 해결해야 하는 상황이 발생했다.
동시성 문제를 해결하기 위해 여러 가지 방법을 고민했고, 최종적으로 락을 활용하기로 했다.
락 중에서도 배타락(X Lock)과 Named Lock 둘 중 한 가지를 사용하려 했고 두 방식 모두 적용해 본 뒤 장단점을 비교해 보고자 했다.
문제 상황
필자의 프로젝트에서 예약 서비스는 연립 부등식을 이용해서 날짜 내의 예약건을 조회하고 가장 많은 예약 수를 반환하여 전체 방 개수에서 빼어 남은 방을 계산하는 방식을 이용하고 있었다. 그리고 남은 방이 있다면 예약을 새롭게 생성하는 형태였다.
그렇기 때문에 동시성 이슈는 예약 트랜잭션이 동작하는 도중에 다른 트랜잭션이 예약 내역을 조회하게 되어, 새롭게 생성되는 예약이 반영되지 않아 발생하는 문제였다.
필자는 하나의 트랜잭션이 동작하는 동안 다른 예약 트랜잭션이 동작하지 않거나(Named Lock) 조회하지 않으면(Exclusive Lock) 될 거라고 생각했기에, 배타락과 Named Lock 모두 제대로 동작할 거라고 예상했다.
실제 동작
필자는 적용하기 쉬운 배타락을 먼저 적용해 보았다.
쿼리에 FOR UPDATE만 추가하면 되는 문제였기 때문에 금방 적용해 볼 수 있었다.
@Query(value = """
SELECT *
FROM Reservation r
WHERE r.room_id = :roomId
AND r.reservation_status = 'RESERVE'
AND (:newStartDate < r.end_date AND :newEndDate > r.start_date)
FOR UPDATE
""", nativeQuery = true)
List<Reservation> reservationsInDateRangeByRoomIdWithLock(
@Param("roomId") Long roomId,
@Param("newStartDate") LocalDate newStartDate,
@Param("newEndDate") LocalDate newEndDate);
위와 같은 쿼리를 작성했고, Jmeter를 이용해서 동시에 1000개의 요청을 1초에 걸쳐 두 번 보내 보았다.
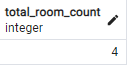
총 방의 개수는 4개이기 때문에 예약 건 또한 4개가 발생해야 한다.

하지만 실제 예약 건 수는 10개 였다. ( 아마도 스레드 개수만큼 생성된 것으로 사료됨 )
어째서 이런 문제가 발생했는지 필자는 어리둥절했다.
FOR UPDATE를 사용하면 X Lock이 걸리면서 S Lock과 X Lock을 얻지 못 하게 막기 때문에 락이 없는 일반 SELECT문을 제외하고는 조회를 못 하게 막을 거라고 예상했기 때문이다.
동시에 요청이 오더라도 조회에서 막히니 X Lock이 풀릴 때마다 순차적으로 진행될 거라고 생각했다.
가정
필자는 X Lock을 가져간 트랜잭션이 수행 도중 INSERT를 발생시키더라도 이후 트랜잭션에서 조회가 발생하면 당연히 반영되어 있을 것이라고 생각했다.
하지만 실제로는 그렇지 못 했고, 한참을 고민하다 FOR UPDATE를 상세 조회만을 막는 것이라고 가정해 보았다.
조회 자체를 막는 개념이 아니고 실제 데이터의 상세 조회를 막는다는 것이다.
이 가정법이 맞다면 데이터가 조회되지 않는 이유가 설명되었다.
필자의 생각을 그림으로 정리해 보았다. 정확히는 상세 조회를 막는 개념이라기 보다는 LOCK의 동작 원리를 표현했다.
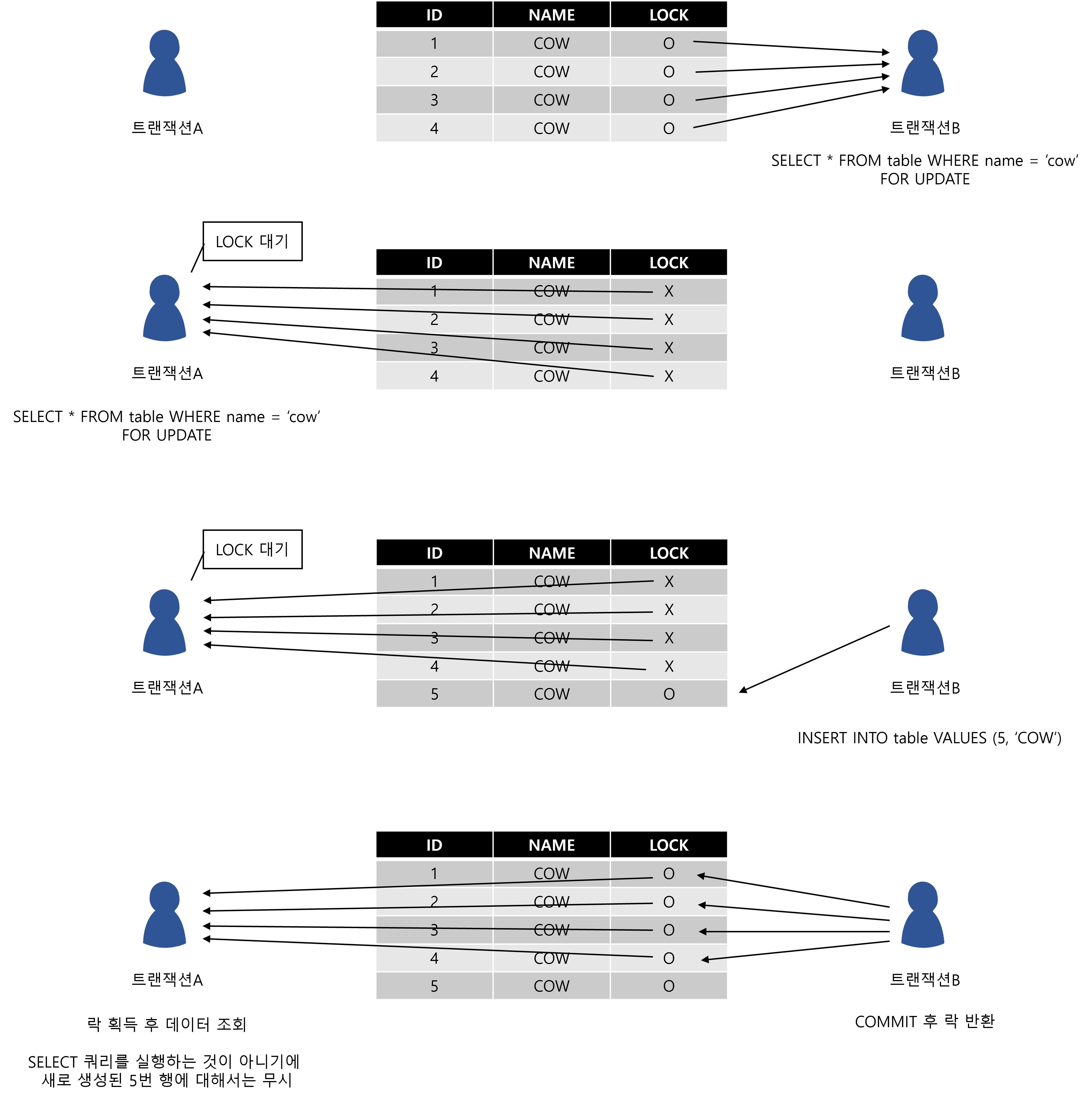
Record Lock은 행에 걸리는 락이기 때문에 조회 자체를 막을 방법은 쉽지 않을 것이라고 판단했다.
일단 조회 쿼리를 수행한 후에 실제 데이터가 조회되면 락이 있는지 확인하고 없다면 락을 획득하기 까지 기다리도록 구현되어 있지 않을까 싶었다.
위의 문제 상황에서 동시에 여러 요청을 보내었고, 각 트랜잭션에서 조회된 행에 대해 락을 얻기 위해 대기할 뿐 SELECT문은 이미 시작된 상태라는 것이다.
그렇기 때문에 락을 얻는 트랜잭션에서 데이터가 아무리 추가되어도 전혀 반영되지 않는다는 것이다.
PostgreSQL 공식문서를 보면 이러한 내용이 있었다.
Read Committed is the default isolation level in PostgreSQL. When a transaction uses this isolation level, a SELECT query (without a FOR UPDATE/SHARE clause) sees only data committed before the query began
SELECT FOR UPDATE, and SELECT FOR SHARE commands behave the same as SELECT in terms of searching for target rows: they will only find target rows that were committed as of the command start time. However, such a target row might have already been updated (or deleted or locked) by another concurrent transaction by the time it is found. In this case, the would-be updater will wait for the first updating transaction to commit or roll back (if it is still in progress). If the first updater rolls back, then its effects are negated and the second updater can proceed with updating the originally found row. If the first updater commits, the second updater will ignore the row if the first updater deleted it, otherwise it will attempt to apply its operation to the updated version of the row. The search condition of the command (the WHERE clause) is re-evaluated to see if the updated version of the row still matches the search condition. If so, the second updater proceeds with its operation using the updated version of the row. In the case of SELECT FOR UPDATE and SELECT FOR SHARE, this means it is the updated version of the row that is locked and returned to the client.
Read Committed 격리수준에서는 SELECT쿼리(FOR UPDATE/SHARE를 사용하지 않은)는 쿼리가 시작되기 이전의 데이터 상태만을 조회한다.
이는 쉽게 생각하면 한 번 쿼리가 시작되면 그 동안에 발생한 커밋 내역은 반영되지 않는다는 것이다.
( 다음 조회 쿼리가 시작되기 전에 커밋된다면 그 때는 내역에 반영된다. 하나의 트랜잭션 내에서 각각의 조회 쿼리 시점이 중요 )
하지만 이는 FOR UPDATE와 FOR SHARE를 사용하지 않았을 때의 이야기이다.
그래서 밑에 내용을 보았지만 UPDATE된 데이터와 DELETE된 데이터는 락에 의해 최신 상태의 데이터가 반영된다고 되어 있지만 INSERT에 대한 내용은 따로 없다.
필자의 가정대로라도 이미 조회한 데이터는 UPDATE와 DELETE되어도 관리가 가능하지만 INSERT는 새롭게 조회 쿼리를 날리지 않는 이상 조회가 불가능하다.
그렇기 때문에 FOR UPDATE는 새롭게 INSERT되는 데이터는 고려하지 못 하는 것이 아닐까 싶었다.
만약 필자의 가정이 맞고 실제로 DB가 저런 형태로 동작한다면 왜 X LOCK으로 동시성 문제가 해결되지 않았는지는 이해할 수 있다.
하지만 필자는 여기서 끝나지 않고 성능적 측면을 고려하여 검증을 해보기로 했다.
확인
필자의 가정대로 트랜잭션들이 Lock을 획득하기 위해 기다리고 있는 것일 뿐이고, 이미 데이터의 조회가 완료된 상태라면 조회 쿼리 자체를 막는 상황 보다 성능이 훨등히 높아야 한다.
FOR UPDATE를 사용하는 로직에 N번의 동시 요청을 여러개 보낼 경우 실제 조회 속도는 (하나의 요청당 걸리는 시간 * N) 보다 빨라야 할 것이다.
확인해 보기 위해 아무 조회 로직에 FOR UPDATE 구문을 추가한 것과 하지 않은 것, 두 가지 방식으로 500번의 동시 요청을 보내 보았다.
사용한 쿼리는 DB에서의 실행 속도는 약 0.075초 정도이다.
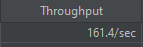
SELECT FOR UPDATE 방식
일반 SELECT 방식
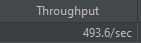
SELECT FOR UPDATE 방식이 일반 SELECT에 비해 약 330TPS가 차이났다.
정말 큰 차이이지만 트랜잭션이 조회 자체를 막아서 순차적으로 하나씩 실행되었다면 나올 수 없는 수치이다.
단순 계산으로만 생각해 보아도 0.075초가 걸리는 쿼리를 500번 순차적으로 수행하면 약 32.5초는 걸려야 한다.
요청 처리를 위한 오버헤드를 고려해도 평균 10TPS 정도가 나와야 정상이라는 소리다.
결론
FOR UPDATE를 통해 record에 락이 걸리면 다른 트랜잭션은 쿼리 자체는 수행하지만 조회한 데이터의 락을 대기하는 개념이지 않을까 한다.
( 필자가 개인적으로 가정하고 실험해서 내린 결론일 뿐이다. 잘못된 부분이 있다면 지적해 주면 좋을 것 같다. )
그렇다면 배타락은 언제 사용하는 게 좋을까?
배타락이 위와 같이 동작하기 때문에 INSERT와 함께 사용하는 것은 좋지 않은 것 같다. 조회 시점의 데이터 수가 반영되기 때문이다.
INSERT가 아닌 정말 UPDATE(또는 DELETE)를 이용한 동시성 문제를 해결할 때 사용하는 것이 좋을 듯 하다.
지금 보면 FOR UPDATE 라는 단어에 참 걸맞는 원리인 것 같다.. UPDATE를 위한 Lock이지 INSERT를 위한 Lock이 아니다...
