SSR의 장단점 및 SEO에 강한 이유를 들여다보다
들어가며
전 직장에서 웹스토어 프로젝트를 제안하고 실행에 옮긴 적이 있다. 그런데 구글이나 야후에서 상품을 검색해보면 최상단은 언제나처럼 Amazon, Ebay 등의 굴지의 회사 사이트들이 차지하고 우리 회사 사이트는 스크롤을 저 밑에까지 내려야만 간신히 보이는 것이 아닌가? 이 문제로 인해 초반 유니크한 접속자의 숫자가 매우 저조해서 고민했던 기억이 있다.
SEO는 막상 현실로 닥치면 그 중요성이 상상 이상이다. 경쟁사보다 눈에 띄는지, 저 아래에 묻혀있는지로 고객의 선택을 좌지우지하고 운명이 갈린다. 쿠팡의 상품이 단 몇십원차이로 최저가 상품의 위치가 바뀌니 판매자들이 가격조정에 사활을 거는 것도 당연한 이치일 것이다. 웹스토어 관리를 통해서 일상속에서 너무나 가볍게 여겨지던 검색과 클릭이 회사 입장에서는 얼마나 간절한 것인지 깨달을 수 있었다.
이러한 SEO에 강점을 가진 SSR의 이야기가 계속해서 들려왔었는데 최근 감사하게도 기업과제를 통해 Next.js 프레임워크에 실제로 도전해볼 계기가 생겼다. SSR을 이용한 웹구현을 처음으로 접함에 따라 기본적인 특성과 원리들을 자세히 조사해 기록해본다.
SSR(Server Side Rendering)은 새로운 개념이 아니다.
 🔺 추억의 웹사이트
🔺 추억의 웹사이트
SSR은 최근 새로 생긴 방식이 아니다.
내가 초등학생때 웹서핑을 했을 때는 페이지를 이동할 때마다 전체가 깜빡이면서 느릿느릿 그려졌었는데 이러한 전통적인 방식이 다름아닌 SSR(Server Side Rendering)이다.
이 시기의 전통적 솔루션에서는, PHP 서버가 모든 것을 컴파일하고 데이터까지 포함해 완전해진 HTML 페이지를 클라이언트에게 전달했다. 이는 빠르고 효과적일 수 있었지만 다른 경로로 이동할 때마다 서버는 모든 작업을 다시 반복해야한다. 파일을 가져오고 컴파일하고 HTML을 전달하고 모든 CSS와 JS가 입혀지는 페이지를 온전히 로드할 때까지 몇백 밀리세컨드에서 길게는 수어초가 걸렸다.
그러나 당시 개인 컴퓨터의 사양은 좋지 않았던 반면 서버 컴퓨터의 사양은 월등히 좋았기 때문에 서버에 이러한 일련의 렌더과정을 모두 위임하는 것은 적합한 방식이었다.
이후 점점 개인 컴퓨터가 감당할 수 있는 연산이 복잡해지고,단순 하이퍼링크 클릭을 넘어선 스무스하고 동적인 웹 인터렉션이 점점 보편화되면서 CSR이 기존의 SSR방식을 밀어내고 우위를 차지하게 되었다.
CSR의 단점, 그리고 SSR이 다시 주목받다.
CSR는 서버가 렌더한 페이지를 전송받아 보여주지 않고, HTML의 root자리 위에서 JS를 통해 스스로 웹사이트를 렌더한다. 즉슨, 서버로부터 js로직을 초기에 모두 다운받아야만 동작을 할 수 있게 되는 데 이것이 CSR의 치명적 단점으로 작용한다. js의 번들은 적절히 분할 최적화되어 있지 않은 이상 한꺼번에 받기 부담스러운 크기일 수 밖에 없고, 이는 초기 구동시간이 길어지는 결과로 이어진다.
따라서 개발자들은 SSR을 다시금 주목하게 되었다. 사용자가 보고자하는 페이지만을 렌더하기에 효율적이며 그 페이지와 관련된 코드와 상태만이 전송된다. 이들이 부트스트랩되는 동안 사용자는 서버에서 렌더된 페이지를 바라보면서 이탈을 덜 하게 된다. 그러나 리액트같은 현대적 프레임워크를 이용해 SSR를 편리하게 구현하기란 쉽지 않은 일이었다.
Next.js, Gatsby는 이 문제점을 해결해주었다. React와 결합되어있기 때문에 프론트엔드 개발자가 익숙한 방식으로 인터페이스를 신속히 작성할 수 있고, 또한 브라우저에 로드시킨 후 순차적으로 js를 렌더하는 hydration기능을 지원한다.
빠른 초기구동 속도를 자랑하는 SSR의 장점과 리액트를 이용한 UX, DX 경험을 동시에 만족시키며 두 마리 토끼를 잡았다.
SEO 측면에서 SSR이 나은 진짜 이유
흔히 SPA에서는 텅 빈 HTML만이 렌더되고 JS 런타임 시 메타데이터가 생성되기 때문에 SEO가 어렵다고 회자되나, 구글 웹 크롤러는 JS에 기반한 메타데이터 크롤링이 가능하다. 2023년 1분기 전 세계 검색 시장의 85%는 구글이 차지하고 있는 실정이다.
따라서 CSR으로는 SEO 성능이 매우 떨어지는 것처럼 말하는 것은 비약 또는 오해라고 볼 수도 있겠다.
다만 SSR이 CSR보다 SEO측면에서 성능이 여전히 나은이유는 따로 있다. 구글봇은 빠르게 로드되는 페이지를 우선적으로 상위에 표시하기 때문이다.
자연스럽게 로드 속도가 빠른 페이지는 검색 결과에서 더 높은 순위를 차지하게 되고 여기서 SSR가 차별점을 가지게 된다고 볼 수 있다. 구글봇은 검색결과에 무엇을 표시할지 결정할 때 페이지의 HTML 색인을 생성하고 Google에서 사용할 수 있는 리소스가 있을 때 이를 JavaScript로 렌더한다. 따라서 CSR을 사용하는 경우 웹사이트 렌더링을 Googlebot에 의존하게 된다고 볼 수 있다. SSR을 사용하면 Google은 완전히 렌더링된 페이지를 크롤링하여 모든 콘텐츠 색인을 생성한다.
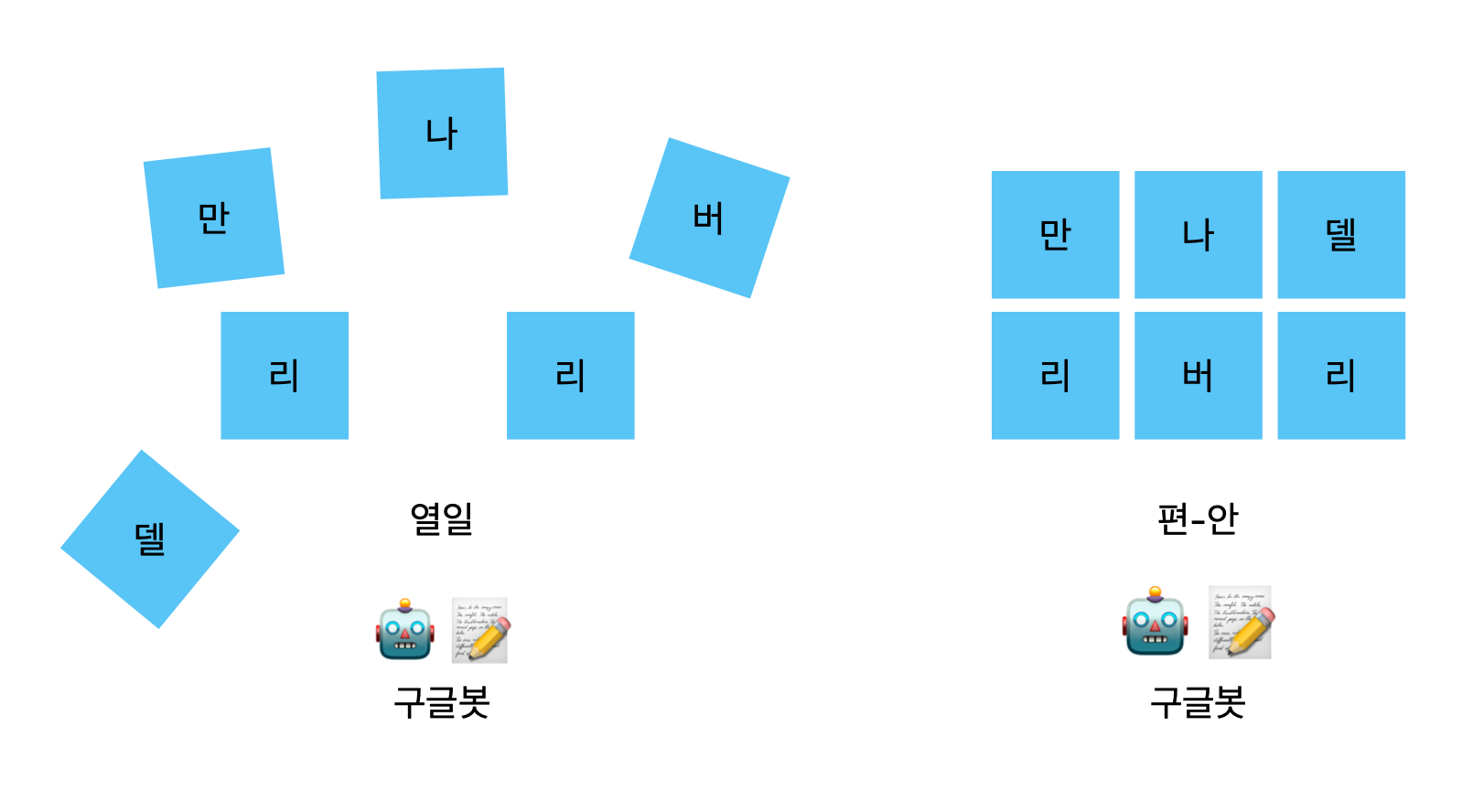 🔺 이는 곧 SSR을 사용하면 구글봇이 모든 콘텐츠를 더 빠르게 검토할 수 있으므로 검색결과에 표시될 가능성이 더 높아짐을 뜻한다.
🔺 이는 곧 SSR을 사용하면 구글봇이 모든 콘텐츠를 더 빠르게 검토할 수 있으므로 검색결과에 표시될 가능성이 더 높아짐을 뜻한다.
소셜미디어에 웹사이트를 공유할 때 흔히 볼 수 있는 "카드"의 경우 일반적으로 웹 사이트에서 메타 태그를 스크랩하여 생성한다. 웹페이지의 어떤 JavaScript도 실행하지 않을 것이기 때문에 런타임에 메타 태그를 변경하는 CSR의 경우 정확한 내용의 카드가 만들어지기 어렵다. HTML가 서버 측에서 미리 생성되어야 하는 상황이기에 여기서도 SSR는 빛을 발한다.
다만 CSR 기반 웹사이트에 대해서도 점점 크롤링과 스크랩 알고리즘이 발전하고 있는 추세라고 한다. 특정 SNS의 카드가 메타태그를 담은 모습으로 잘 만들어지는 지 등은 실험을 통해 확인하는 것이 반드시 필요할 것 같다.
그렇다면 SSR의 단점은 뭘까?
😵💫 서버와 통신을 거쳐서 페이지를 로드하기 때문에 깜빡이는 블링킹 이슈가 발생한다.
😵💫 TTV(👀 Time To View)와 TTI(👆 Time To Interact) 간의 차이로 인한 초기먹통문제가 발생한다.
혹은 FCP(First Contentful Paint)와 TTI(Time To Interact)와의 간극이라고도 말할 수 있다. 이는 사용자가 실제로 페이지를 사용할 수 있을 때까지의 시간을 의미한다.
초기 페이지를 가져와 interactive하게 만드는 과정을 hydration이라고 하는데, hydration되기 전 타이밍에 유저가 재빨리 클릭등을 시도한다면, 원하던 반응을 볼 수 없어 혼란스러워할 가능성이 있다.
😵💫 많은 유저가 접속하면 서버의 과부하 위험이 높아진다.
렌더링 책임이 서버에 위임되기 때문에 이는 당연한 결과이다.
😵💫 비용이 증가한다.
서버가 수행하는 작업의 비중이 증가하면서 서비스 제공자의 서버 유지비용이 상승한다.
참고:
https://www.infoworld.com/article/3686649/server-side-rendering-is-having-a-moment.html
https://www.infoworld.com/article/3661810/reactive-javascript-the-evolution-of-front-end-architecture.html
