
부캠을 다닐 때 적었던 복사에 관한 이야기를 적었던 기억이 있다.
그런데 최근에 프로토타입을 공부하면서, 복사라는 것이 프로토타입 체인에 관련이 되어있다는 이야기를 듣게 됐다.
그래서 좀 찾아보다가 도무지 모르겠어가지고 일단 책을 기반으로 작성을 하면서 어디서 관련이 있는지 찾아보려고 한다.
근데 JS가 다른 프로그래밍 언어다르게 프로토타입이라는 것을 사용하다보니 다른 부분이 있는데
이것을 설명을 한 후에 복사에 대한 이야기가 진행될 예정입니다.
JS의 데이터타입
JS에는 총 8개의 데이터타입이 존재하는데, 이것은 값의 종류를 이야기한다.
모든 값에는 타입이 존재하는데 크게는 원시타입, 객체타입 두개로 분류를 할 수 있다.
- 원시 타입
- 숫자 타입 (number)
- 문자열 타입 (string)
- 불리언 타입 (boolean)
- undefined 타입
- null 타입
- 심볼 타입 (symbol)
- 큰숫자 타입 (bigint) <- ES11에 추가됐다. 2020년도
- 객체 타입
- 객체, 배열, 함수 (object)
보통 이러한 데이터타입은 왜 존재하는지 깊게 생각을 해보지 않았을 가능성이 높다.
야 너두? 나두
왜냐하면 자바스크립트는 값을 메모리에 직접 할당하지 않아도 되는 고수준 언어이고
타입을 지정하지 않아도 자기가 알아서 지정하고 얼렁뚱땅 굴러가는 인터프리터(동적)언어이기 때문이다.

C언어의 지옥같은 포인터 를 몰라도, 자바스크립트가 알아서 다 처리해준다.
하지만 그럼에도 불구하고 원시타입과 객체타입으로 나눠져있다.
그리고 자바스크립트는 프로토타입의 객체지향 언어로 객체가 중심인 언어 라는 것을 잊으면 안된다.
데이터타입이 존재하는 이유
그렇다면 왜 존재하냐? 라고 생각을 할 수 있는데, 그 이유는 담기는 타입마다 크기가 다르기 때문이다.
컴퓨터 읽을 수 있는 것은 0과 1 이진법으로 구성이 되어있는데
숫자 1과 문자열 '1'을 어떻게 구분을 하는 것인가? 라는 생각을 해봤다면 그것이 데이터타입이 존재하는 이유다.
또한 데이터를 저장할 때, 메모리에 얼마나 공간이 필요한지도 알아야한다.
과거의 C언어를 배울때 기억을 끄집어내려고 했는데 기억이 다 훼손되서 그림으로 찾아왔다(....)

https://github.com/Kyeongan/data-type-in-c
내 기억으로는 short, int, long 모두 정수형으로 기억하는데 정의하는 타입이 다르다.
그리고 문자열과 정수형이 필요한 데이터의 용량도 다르다.
이러한 이유때문에 데이터 타입은 필연적으로 존재할 수 밖에 없다.
포인터가 없어서 다행이지 진짜 있었으면 정말 아
그래서 책에는 아래와 같게 필요한 이유를 정의해놨다.
- 값을 저장할 때 확보해야 하는 메모리 공간의 크기를 결정하기 위해
- 값을 참조할 때 한 번에 읽어 들여야 할 메모리 공간의 크기를 결정하기 위해
- 메모리에서 읽어 들인 2진수를 어떻게 해석할지 결정하기 위해
그렇다면 왜 존재하는지 알았으니, 원시 타입과 객체 타입이 어떤 차이가 있는지 알아보자.
타입 별 메모리 할당 비교
일단 자바스크립트에는 두가지 타입이 존재하고 값을 저장하는 것에 차이가 존재한다.
- 원시 타입
- 원시타입 같은 경우에는 변경이 불가능한 값이다.
바꿀 수 있지 않나요? 라고 물어볼 수 있을텐데, 조금 개념이 다르다. - 원시타입같은 경우에는 생각을 해보면 값이 한개로 고정되어있다는 것을 알 수 있다.
이러한 값을 늘리는 것이 불가능하여, 변경이 불가능한 값이라고 이야기를 한다. - 그래서 원시 타입같은 경우에는 변수에 할당을 할 경우 확보한 메모리에 실제 값이 저장된다.
이러한 과정을 Pass by value라는 용어로 이야기한다. (값에 의한 전달)
- 원시타입 같은 경우에는 변경이 불가능한 값이다.

JS의 문자열은 유사 배열라서 인덱스로 값을 접근할 수 있다. 유사배열은 나중에 서술..
그렇지만 위의 사진처럼 0번의 원이라는 인덱스를 객으로 바꿨으나 적용되지 않은 모습을 볼 수 있다.
- 객체 타입
- 객체타입 같은 경우에는 변경이 가능한 값으로 이루어져있다.
객체의 키,값을 추가한다던가 클래스의 메소드를 추가, 삭제하는 값의 변동이 존재할 수 있다. - 그래서 객체 타입같은 경우에는 변수에 할당을 할 경우 참조 값이 저장된다.
이러한 과정을 Pass by reference라는 용어로 이야기한다. (참조에 의한 전달)
- 객체타입 같은 경우에는 변경이 가능한 값으로 이루어져있다.

모두가 알고있는 것처럼, 값이 변경되는 것을 확인할 수 있다.
왜 객체타입은 메모리에 참조만 하는걸까?
왜 원시타입은 값을 직접 메모리에 할당하는데 객체타입은 값을 메모리에 참조만 하는 것일까?
이것에 대한 정답은 확인이 되지 않고 있다(....)
그러게 어디를 참조하지...
뭐라고해야할까 이건 완전 근본을 생각하는 것이라 그런지는 모르겠지만
어떤식으로 검색을 해봐야할지 잘 모르겠다..
하지만 이러한 정보까지는 찾을 수 있었다.
- Call by value(값에 의한 호출)
- 복사를 하여 값을 불러오기 때문에 값을 보존할 수 있다.
- Call by reference(참조에 의한 호출)
- 복사를 하지 않고 직접 참조로 불러오기 때문에 빠르다.
자료구조 중 해시테이블이 JS의 Object와 비슷한 관계에 있는데, 아마 그러한 영향이 있지 않나라고 생각한다.
(이 부분이 구조가 히든 클래스라는 것이 있다고 하는데, 공부를 해서 머리속에서 정리가 되면 추가 예정입니다.)
원시타입처럼 한개의 값만 넣는 것이 아니라 다양한 프로퍼티 혹은 메소드가 많기 때문에 데이터가 커지는데
이것을 값에 의한 호출로 이어진다면 메모리의 소비나 속도가 상당히 느려지기 때문에 참조호출을 하는 듯 하다.
그렇다면 이 글의 본론이였던 복사에 대해서 이야기를 해보려고 한다.
서론이 길었는데...... 길 수 밖에 없다(....)
복사
복사는 왜 하려고 하는 것일까? 기존의 값을 바탕으로 작업을 해야한다거나
코드의 재활용이 필요할 때 사용할 것 같다.
그럼 여기서 원시타입과 객체타입을 서로 복사했을 경우의 차이를 보려고 한다.
원시 타입의 복사와 메모리 할당

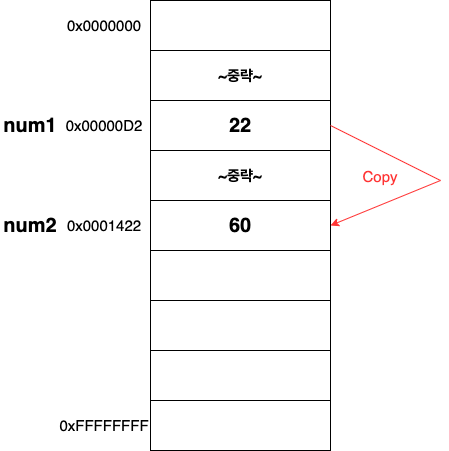
위의 사진을 보면 원시타입인 number을 상수에 선언한 후 대입으로 복사를 한 것을 볼 수 있다.
이 경우에는 원시타입은 메모리에 실제 값을 저장하기 때문에, 복사를 할 경우 새로운 메모리를 할당받게 되는 것이다.
그렇다면 객체 타입은 어떤 차이가 있는지 확인해보자.
객체 타입의 복사와 메모리 할당

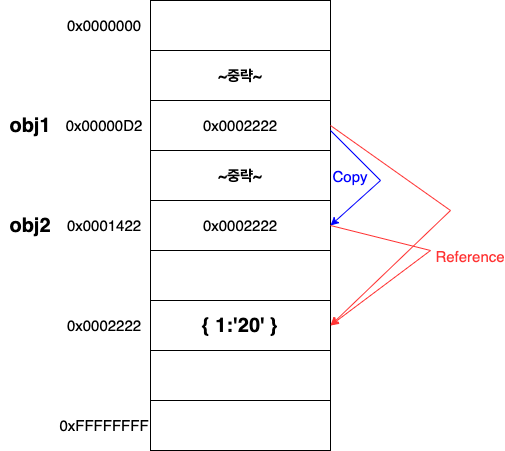
뭔가 원하는 것처럼 나오지 않았다는 것을 알 수 있다.
- obj1 이라는 변수가 메모리에 할당됨
- {1:"20"}이라는 값이 메모리에 할당됨
- obj1은 {1:"20"}이 할당된 메모리의 값을 참조함.
- obj2 라는 변수가 메모리에 할당됨
- obj1을 복사함
- 참조하고 있던 {1:"20"}의 값까지 고스란히 따라옴
이렇게 된다는 소리는 결국, 어디서든 해당 값에 영향을 줄 경우에 같이 바뀌는 것을 뜻한다.
아래의 코드를 한번 봐보자.
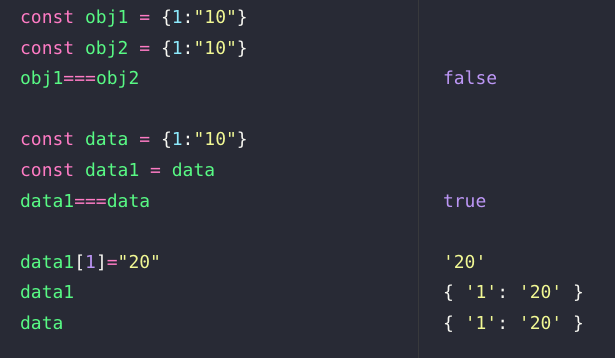
일단 미리 알아둬야하는 것이 있다.
객체를 생성한다는 것은 새로운 인스턴스를 생성하는 것이다.
그렇기 때문에 동일한 프로퍼티를 가지더라도 두개가 같을 수는 없다.
(세미 싱글톤패턴이라고 봐도 된다!)
그래서 위의 사진을 보면 따로따로 선언을 했지만, 값이 같은 객체는 서로가 다르다는 것을 표시해주고 있다.
하지만
복사를 한 것은 서로가 같다고 표시를 해주고 있는데, 이 말은 곧 인스턴스를 공유하고 있다는 의미다.
그렇기 때문에 data1의 프로퍼티가 변경되었는데 data의 값에도 영향을 간 것을 확인할 수 있다.
그렇다면 객체를 복사하기 위해서는 도대체 어떻게 해야할까?
그것의 정답은 얕은 복사(Shallow Copy)와 깊은 복사(Deep Copy)로 해결할 수 있다.
얕은 복사(Shallow Copy)
내가 알고 있는 것은 한 단계만 복사를 하는 것인데, 언어마다 사용하는 표현이 다른 것인지 차이가 좀 있는 것 같다.
여기서 설명되는 것은 한 단계만 복사하는 것을 의미한다.
얕은 복사는 한 단계만 복사를 한다, 즉 중첩되는 구문에서 사용을 할 경우 의미가 없다.
그렇지만 일반적으로는? 코딩테스트에서 깊은 복사를 요구하는 문제는 아직은 못봤던 것 같다.
얕은 복사를 구현하는 방법은 여러가지가 있는데
그중에 나는 ES6에서 추가된 스프레드 연산자를 제일 좋아하고, 명확해서 자주 쓰고 있다.
스프레드 연산자

객체라면 {...변수&상수} 배열이라면 [...변수&상수] 이렇게 사용을 할 수 있다.
그렇지만, 아까 이야기했던 것처럼 한 단계만 복사가 가능하다.
아래 사진을 봐보자.
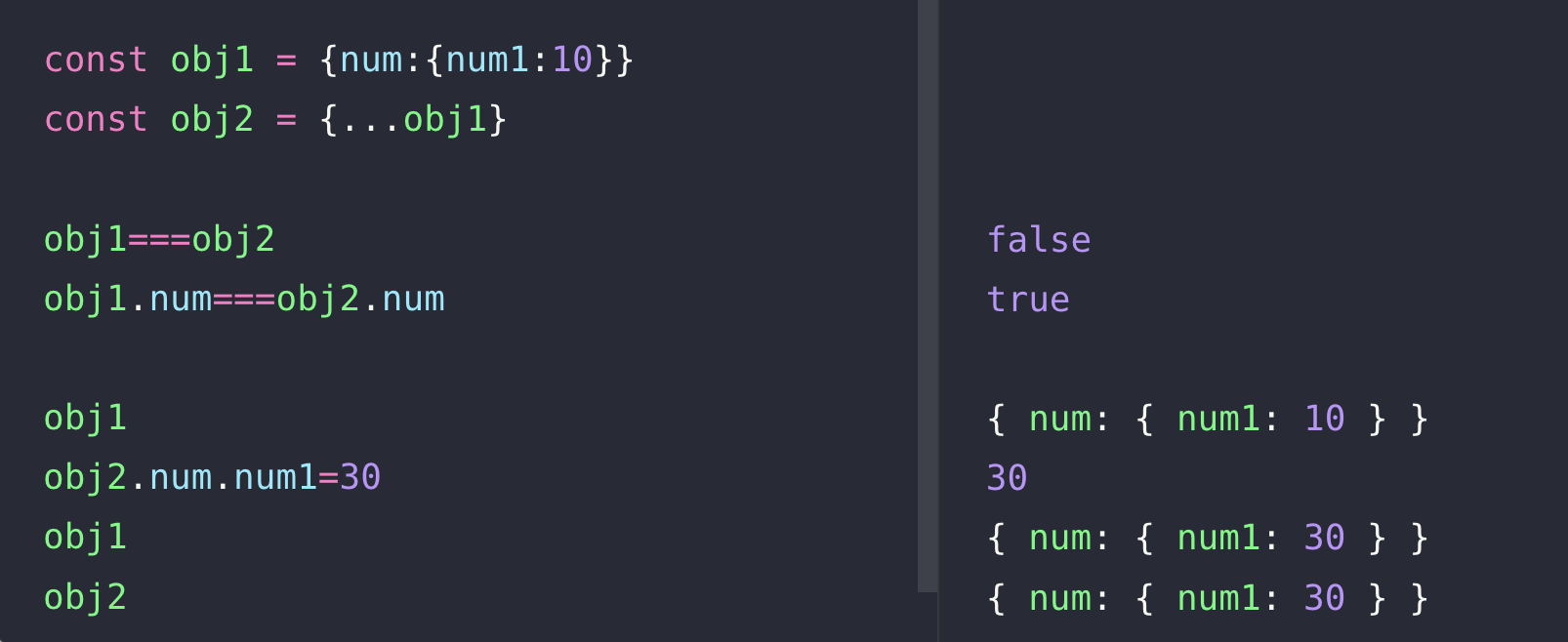
객체 속 객체의 구조로 되어있는 것을 스프레드 연산자로 얕은 복사를 했다.
이제는 obj1과 obj2가 서로 다른 인스턴스이기에 false가 나오는 것을 확인할 수 있는데
객체 속 객체인 obj1.num과 obj2.num의 인스턴스는 동일하다는 true값을 확인할 수 있다.
그래서 obj2.num.num1의 값을 바꾸자 obj1의 값 또한 변경되는 것을 볼 수 있는데
이러한 문제를 해결하기 위하여 깊은 복사(Deep Copy)라는 것을 사용한다.
여기서 잠깐! 왜 저런 일이 벌어지는지 살짝만 알아보고 가보자.
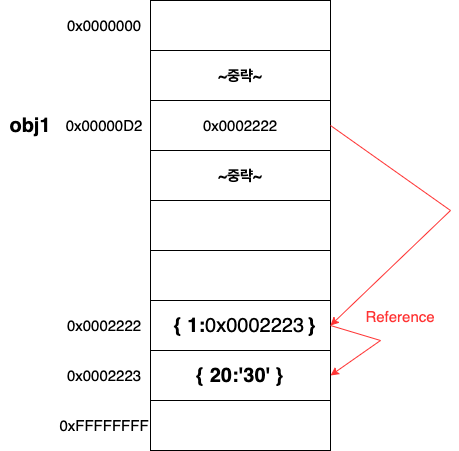
지금까지 내가 생각했던 것은 객체 속 객체가 있다고 하더라도, 그저 값으로 담겨있을 것이다. 라는 생각을 하고 있었다.
하지만 지금 이 글에서 나오는 것처럼 객체 속 객체의 복사가 원활하게 이루어지지 않는다는 것은
객체 속 객체는 그 자체로 새로운 레퍼런스를 가지고 있다.
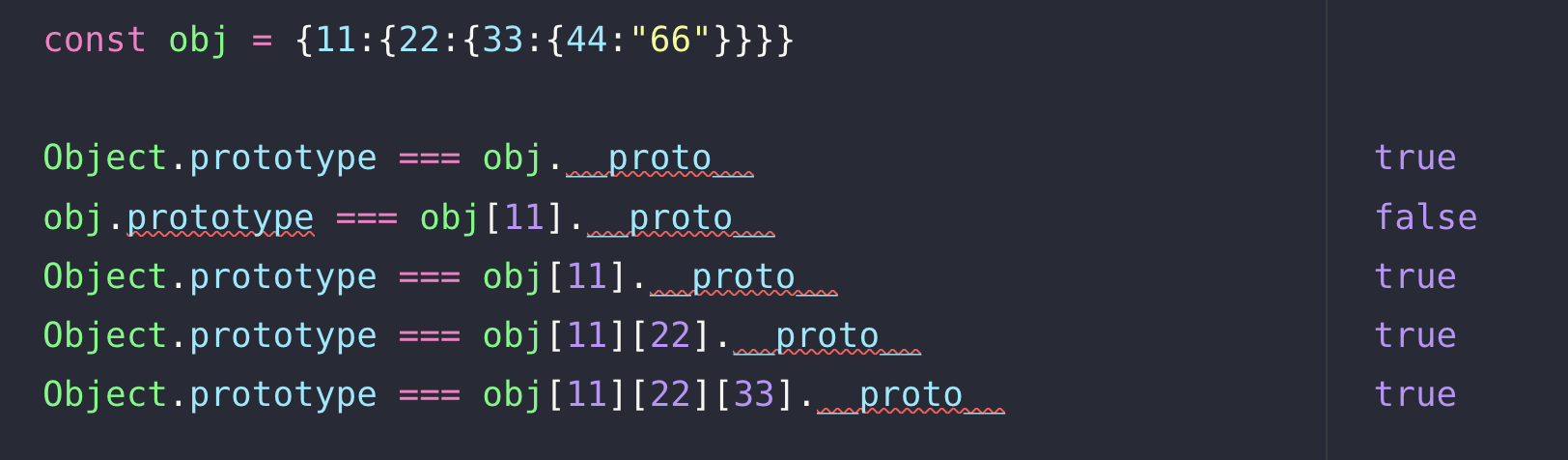
위의 코드를 보면 obj.prototype === obj[11].__proto__가 false인 것을 볼 수 있다.
하지만 그 외는 모두 true인 것을 볼 수 있는데
Object In Object는 서로 연관성이 전혀 없는 별개의 Object라는 것이다.
그렇기 때문에 각각 객체의 값은 새로운 메모리에 값을 할당하여 참조만 하기 때문에
한단계만 복사를 하는 얕은 복사에서는 이러한 것을 해결하지 못한다.
그럼 정말 깊은 복사를 알아보자.
깊은 복사(Deep Copy)
깊은 복사는 메모리를 참조하여 원본 객체를 복사하여 새로운 객체를 만들게 된다.
이것도 방법이 여러가지가 있는데, 3개정도만 소개를 해보려고 한다.
1. JSON.parse(JSON.stringify())
전통의 방식이라고 해야할지.. 효율이 제일 안좋지만 추가 라이브러리 없이 할 수 있는 방식이다.
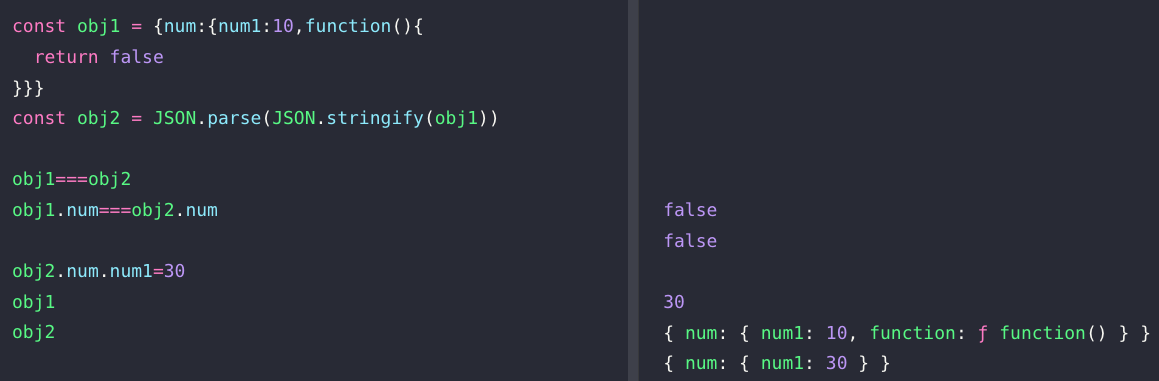
단점은 결과에서도 확인할 수 있지만, 함수가 날라가버린다는 문제가 발생한다.
2. lodash.cloneDeep()
다양한 기능을 가지고 있어서 많은 개발자들에게 사랑을 받는 로대시 라이브러리의 clondeDeep을 사용하는 방식이다.
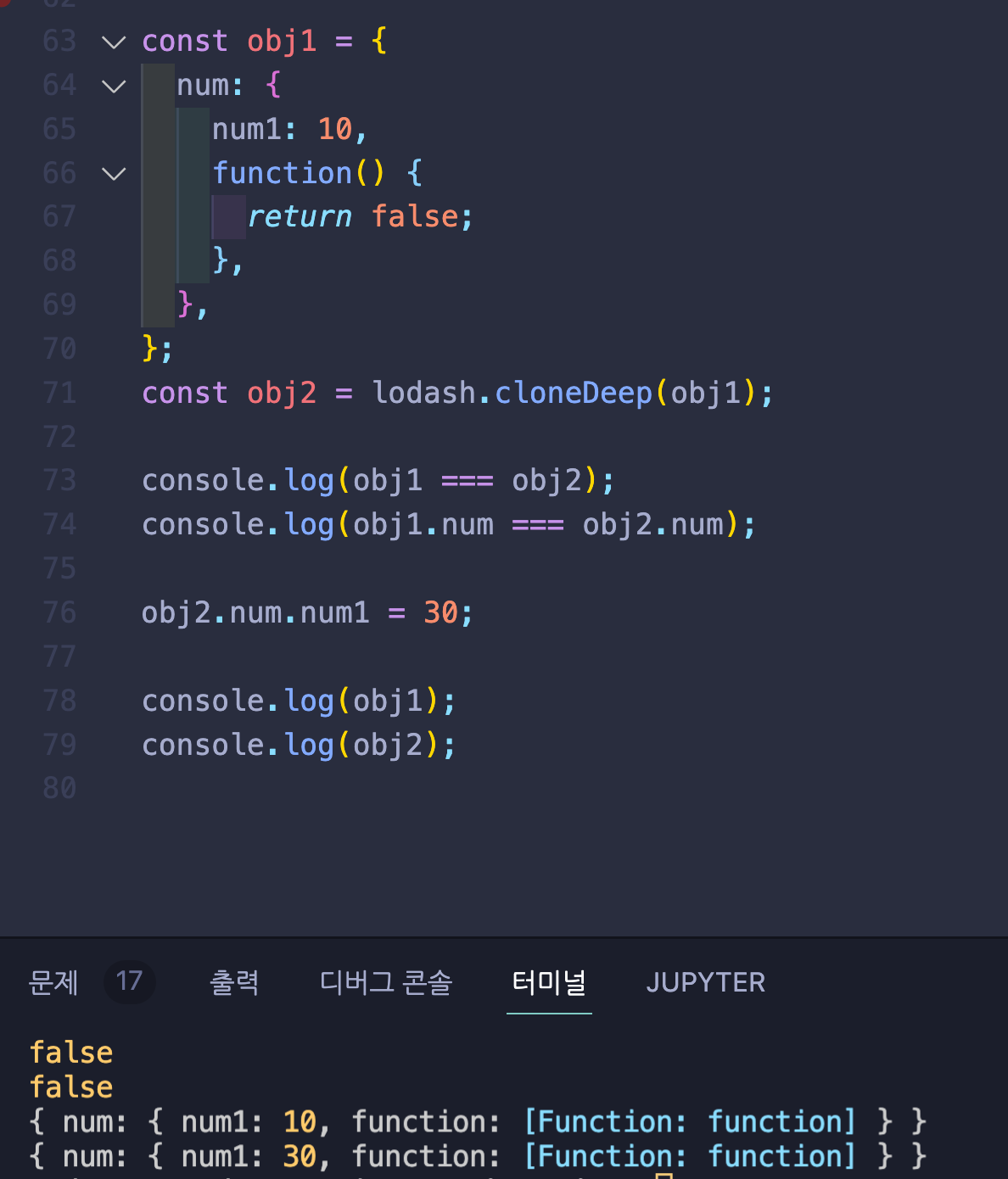
함수도 모두 복사가 되는 것을 확인할 수 있는데, 단점이라면 라이브러리를 설치해야한다. 라는 단점이 있다.
3. structuredClone()
깊은 복사를 할 수 있는 알고리즘이 적용되어있는 자체 메소드다. 아주 최근에 나온 듯 하다.(21년 말?)

문제는 얘는 함수가 들어가면 그냥 고장난다(.....)
복사시도 조차 못해서.... 라이브러리를 까는게 맞지 않을까~ 라는 생각이 든다.
이정도로 글을 마무리를 지어야할 것 같은데, 조금 아쉬운 마음이 드는 것은 사실이다.
일단 참조를 하는 레퍼런스는 힙에 담겨지고 그 외의 것들은 스택에 담긴다는 것을 보았는데
이 부분을 설명이라거나, 이해를 하려면 시간이 엄청 많이 걸려서 글에 담아내지 못했다.
그리고 조금 더 프로토타입과 연관지어서 글을 적어보고 싶었는데
프로토타입에 대한 공부가 아직은 모자라다보니 보면서도 이해가 가지 않아서 적지 않았다.
시간이 조금 더 흐른 후에 이 글도 보강작업을 해야할 것이라 생각한다.
그래도 3월 16일에 쓴 글에 비해서는 완전 성장한 글이 적히지 않았나 싶다 ㅋㅋ
https://velog.io/@yukina1418/%EB%B3%B5%EC%82%AC
추가, 수정이 필요한 내용이 있다면 언제든 댓글로 남겨주세요!
끗
참고한 & 보면 좋은 자료
Simple Explanation of Objects and Memory References in JavaScript
Deep-copying in JavaScript using structuredClone
V8 Heap Sandbox
V8의 히든 클래스 이야기
