
OpenAI에서 발표한 오디오, 시각, 텍스트를 실시간으로 추론할 수 있는 새로운 모델인 GPT-4o에 대해 알아보자.
| gpt-4o : https://openai.com/index/hello-gpt-4o/
1. GPT-4o 란?
GPT-4o의 o는 전체를 아우른다는 뜻의 ‘옴니(Omni)’에서 가져왔다.
입력으로 텍스트, 오디오, 이미지를 넣으면 텍스트, 오디오, 이미지의 모든 조합을 출력으로 생성할 수 있다.
응답 속도가 빨라져서 사람과 거의 비슷하게 소통할 수 있게 되었다. 특히 기존 모델에 비해 시각 및 오디오 이해 능력이 좋아졌다.
영어의 경우 GPT-4 터보 성능과 비슷하며, 비영어권 언어의 경우 성능이 크게 향상되었다.
2. 음성 모드 지연시간 축소
이전의 모델들의 음성모드 경우에서는 평균 2.8초(GPT-3.5)와 5.4초(GPT-4)의 지연 시간이 있었다.
음성 모드는 세 개의 개별 모델로 구성된 파이프라인으로 구성된다.
- 단순 모델이 오디오를 텍스트로 변환
- GPT-3.5 또는 GPT-4가 텍스트를 받아 텍스트를 출력
- 단순 모델이 해당 텍스트를 다시 오디오로 변환
이 과정에서 중간에 잃어버리는 정보가 많아 음색, 화자, 배경음, 웃음, 노래 등 감정 표현을 출력할 수 없었다.
GPT-4o는 새로운 단일 모드로 입출력이 동일한 신경망에서 처리되어 소리, 시각, 청각 모두 같은 모델에서 처리해 맥락을 따로 학습시키지 않고도 자연스러운 답변이 가능하다.
최소 232밀리초, 평균 320밀리초 만에 오디오 입력에 응답할 수 있다.
3. 모델의 성능
GPT-4o API의 경우 기존의 GPT-4 Turbo보다 2배 빠르고, 2배 저렴하게 사용이 가능하다.
또한 기존 벤치마크에서 측정한 결과, GPT-4o는 텍스트, 추론 및 코딩 인텔리전스에서 GPT-4 터보 수준의 성능을 달성하는 동시에 다국어, 오디오 및 시각 기능에서 새로운 최고 워터마크를 기록했다.
한국어 또한 성능이 많이 좋아졌으며, 처리하는데 필요한 토큰의 수가 1.7배 감소하였다.(45개에서 27개로)
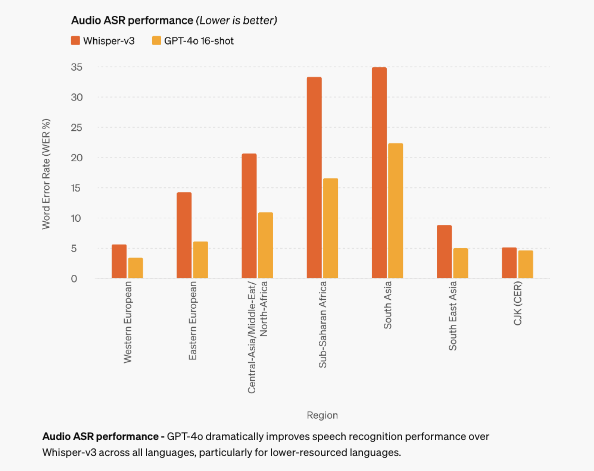
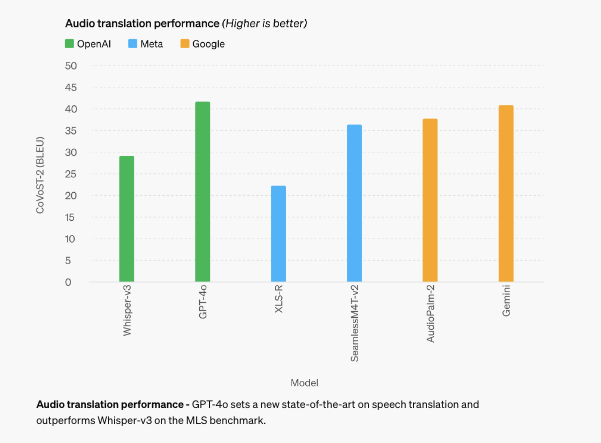
결론
- 기존 모델들보다 응답 속도가 향상됨.
- API의 경우 기존의 GPT-4 Turbo보다 2배 빠르고, 2배 저렴하게 사용이 가능
- GPT-4o 무료로 공개(plus 사용자의 경우 5배 많은 질문 가능)
- 하나의 새로운 모델을 엔드투엔드로 훈련시켜 모든 입력과 출력을 동일한 신경망으로 처리하여 자연스러운 답변 생성이 가능
- 비영어권에서 큰 성능의 향상이 있었으며, 한국어 또한 성능이 향상됨.(토큰의 수 1.7배 감소)

이해하기 쉬운 설명 감사합니다ㅏ!