
01.31 월
참고강의 - 백기선님의 더 자바, 애플리케이션을 테스트하는 다양한 방법
✏️ JUnit 테스트 인스턴스
JUnit은 테스트 순서가 정해져있는게 아니기 때문에 테스트 메서드마다 클래스 인스턴스를 새로 만들어서 실행함(해시 값을 찍어 확인해 보면 서로 다른 인스턴스) -> 의존성을 줄이기 위해
변경 방법이 JUnit5에 생김
클래스 당 인스턴스를 하나만 만들어서 공유하는 방법이 생김
@DisplayNameGeneration(DisplayNameGenerator.ReplaceUnderscores.class)
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
class StudyTest {
// 클래스당 테스트 인스턴스를 만들면 static일 필요 없음
@BeforeAll
void beforeall() {System.out.println("before all");}
int value = 1;
@FastTest
@DisplayName("스터디 만들기 fast")
void create_new_study() {
System.out.println(value++);
Study actual = new Study(value++);
}
}
- JUnit은 테스트 메소드 마다 테스트 인스턴스를 새로 만든다
- 이것이 기본 전략
- 테스트 메소드를 독립적으로 실행하여 예상치 못한 부작용을 방지하기 위함
- 이 전략을 JUnit 5에서 변경할 수 있다
- @TestInstance(Lifecycle.PER_CLASS)
- 테스트 클래스당 인스턴스를 하나만 만들어 사용한다
- 경우에 따라, 테스트 간에 공유하는 모든 상태를 @BeforeEach 또는 @AfterEach에서 초기화 할 필요가 있다.
- @BeforeAll과 @AfterAll을 인스턴스 메소드 또는 인터페이스에 정의한 default 메소드로 정의할 수도 있다.
✏️ 테스트 순서
테스트 순서는 내부적으로 정해진 순서가 있긴함. 하지만 내부 구성 로직에 따라 순서는 바뀔 수 있으므로 이 순서에 의존하면 안됨.
- 제대로 된 유닛 테스트를 작성했다면 다른 단위 테스트와 독립적으로 실행이 가능해야함 -> 서로간 의존성이 없어야 함 -> 순서에 의존하면 안됨
하지만 경우에 따라서 시나리오 테스트 등.. 인스턴스를 하나만 만들어서 공유해서 사용하기도 해야함
특정 순서대로 테스트를 실행하고 싶을 때, 테스트 메소드를 원하는 순서에 따라 실행하도록 @TestInstance(Lifecycle.PER_CLASS)와 함께 @TestMethodOrder를 사용할 수 있다.
- MethodOrderer 구현체를 설정
- 기본 구현체
- Alphanumeric
- OrderAnnoation
- Random
@DisplayNameGeneration(DisplayNameGenerator.ReplaceUnderscores.class)
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
class StudyTest {
int value = 1;
@Order(2)
@FastTest
@DisplayName("스터디 만들기 fast")
void create_new_study() {
System.out.println(value++);
Study actual = new Study(value++); // 항상 1임 -> 테스트 매서드마다 클래스 인스턴스를 새로 만들기 때문 -> 테스트 마다 의존성을 줄이기 위해
}
@Order(1)
@Test
@DisplayName("스터디 만들기 slow")
@Tag("slow")
void create_new_study_again() {
System.out.println("create1");
}
}slow가 fast보다 먼저 실행됨
✏️ junit-platform.properties
JUnit 설정 파일로, 클래스패스 루트 (src/test/resources/)에 넣어두면 적용된다.
테스트 인스턴스 라이프사이클 설정
junit.jupiter.testinstance.lifecycle.default = per_class
확장팩 자동 감지 기능
junit.jupiter.extensions.autodetection.enabled = true
@Disabled 무시하고 실행하기
junit.jupiter.conditions.deactivate = org.junit.*DisabledCondition
테스트 이름 표기 전략 설정
junit.jupiter.displayname.generator.default = \
org.junit.jupiter.api.DisplayNameGenerator$ReplaceUnderscores
02.01 화
참고강의 - 백기선님의 더 자바, 애플리케이션을 테스트하는 다양한 방법
✏️ Mockito 소개
- Mock: 진짜 객체와 비슷하게 동작하지만 프로그래머가 직접 그 객체의 행동을 관리하는 객체.
- Mockito: Mock 객체를 쉽게 만들고 관리하고 검증할 수 있는 방법을 제공한다.

✏️ Mockito 객체 만들기
스프링부트 2.2+ 프로젝트 생성시 spring-boot-starter-test에서 자동으로 Mockito 추가해줌
Mockito는 특정한 클래스나 인터페이스의 가짜 객체를 만들어 주는 것
다음 세 가지만 알면 Mock을 활용한 테스트를 쉽게 작성할 수 있다
(1) Mock을 만드는 방법
(2) Mock이 어떻게 동작해야 하는지 관리하는 방법
(3) Mock의 행동을 검증하는 방법
Mockito.mock() 메소드로 만드는 방법
MemberService memberService = mock(MemberService.class);
StudyRepository studyRepository = mock(StudyRepository.class);
@Mock 애노테이션으로 만드는 방법
- JUnit 5 extension으로 MockitoExtension을 사용해야 한다.
- 필드
- 메소드 매개변수
@ExtendWith(MockitoExtension.class)
class StudyServiceTest {
@Mock MemberService memberService;
@Mock StudyRepository studyRepository;
예제 코드
@ExtendWith(MockitoExtension.class)
class StudyServiceTest {
@Test
void createStudyService(@Mock MemberService memberservice, @Mock StudyRepository studyRepository) {
Optional<Member> optional = memberService.findById(1L);
StudyService studyService = new StudyService(memberService, studyRepository);
assertNotNull(studyService);
}
}✏️ Mock 객체 Stubbing
@ExtendWith(MockitoExtension.class)
class StudyServiceTest {
@Test
void createStudyService(@Mock MemberService memberservice, @Mock StudyRepository studyRepository) {
StudyService studyService = new StudyService(memberService, studyRepository);
assertNotNull(studyService);
Member member = new Member();
member.setId(1L);
member.setEmail("dbfgml980413@gmail.com");
when(memberService.findById(1L)).thenReturn(Optional.of(member));
Study study = new Study(10, "java");
Optional<Member> findById = memberService.findById(1L);
assertEquals("dbfgml980413@gmail.com", findById.get().getEmail());
//studyService.createNewStudy(1L, study);
}
}모든 Mock 객체의 행동
- Null을 리턴한다. (Optional 타입은 Optional.empty 리턴)
- Primitive 타입은 기본 Primitive 값
- 콜렉션은 비어있는 콜렉션
- Void 메소드는 예외를 던지지 않고 아무런 일도 발생하지 않는다.
Mock 객체를 조작해서
- 특정한 매개변수를 받은 경우 특정한 값을 리턴하거나 예외를 던지도록 만들 수 있다
- Void 메소드 특정 매개변수를 받거나 호출된 경우 예외를 발생 시킬 수 있다
- 메소드가 동일한 매개변수로 여러번 호출될 때 각기 다르게 행동하도록 조작할 수도 있다
✏️ BDD 스타일 API
BDD
: 애플리케이션이 어떻게 “행동”해야 하는지에 대한 공통된 이해를 구성하는 방법으로, TDD에서 창안했다.
행동에 대한 스펙
- Title
- Narrative
- As a/ I want /so that- Acceptance criteria
- Given/When/Then
Mockito는 BddMockito라는 클래스를 통해 BDD 스타일의 API를 제공한다.
When -> Given
given(memberService.findById(1L)).willReturn(Optional.of(member));
given(studyRepository.save(study)).willReturn(study);
Verify -> Then
then(memberService).should(times(1)).notify(study);
then(memberService).shouldHaveNoMoreInteractions();
02.02 수
알고리즘 기본 문제부터 다지기 시작~~!
✏️ 람다 함수
람다 함수란? 익명의 함수다.
기본 함수와 람다를 활용한 코드의 예시로 비교해보자
함수로 만든 경우
def plus_one(x):
return x + 1
print(plus_one(1))람다 활용
plus_two = lambda x: x+2
print(plus_two(1))람다 함수는 내장 함수의 인자로 활용될 때 굉장히 효율적임
-> 보통 sort()에서 사용
예시)
def plus_one(x):
return x + 1
a[1, 2, 3]
print(list(map(plus_one, a)))
# 람다 활용
print(list(map(lambda x: x+1, a)))✏️ round()
python 반올림 함수 round()는 round_half_even 방식을 택한다.
-> round_half_even = 짝수쪽으로 근사값을 해버린다.
-> round_half_up = 0.5를 넘어가면 큰수로 반올림 해버린다.
a = 4.500
print(round(a)) // 4 출력
a = 4.5111
print(round(a)) // 5 출력
a = 5.5000
print(round(a)) // 6 출력
해결법
간단하게 0.5를 더한 후 int로 바꾸면 된다
a = 67.5
a = a + 0.5
a = int(a)
print(a)
✏️ 예제들
간단한 문제들을 풀어보았다.
1-1. K번째 약수
from sys import stdin
n, k = map(int, stdin.readline().split())
cnt = 0
for i in range(1, n+1):
if n % i == 0:
cnt += 1
if cnt == k:
print(i)
break
else:
print(-1)1-2. K번째 수
# K번째 수
from sys import stdin
T = int(stdin.readline())
for t in range(T):
n, s, e, k = map(int, stdin.readline().split())
nums = list(map(int, stdin.readline().split()))
nums = nums[s-1:e]
nums.sort()
print("#%d %d" %(t+1, nums[k-1]))1-3. K번째 큰 수
# K번째 큰 수
from sys import stdin
n, k = map(int, stdin.readline().split())
cards = list(map(int, stdin.readline().split()))
res = set()
for i in range(n):
for j in range(i+1, n):
for m in range(j+1, n):
res.add(cards[i] + cards[j] + cards[m])
res = list(res)
res.sort(reverse=True)
print(res[k-1])1-4. 대표값
- enumerate()는 리스트의 인덱스값과 실제 값을 쌍으로 대응해주는 메서드
from sys import stdin
n = int(stdin.readline())
a = list(map(int, stdin.readline().split()))
ave = round(sum(a)/n)
min = 2147000000
for idx, x in enumerate(a):
tmp = abs(x - ave)
if tmp < min:
min = tmp
score = x
res = idx + 1
elif tmp == min:
if x > score:
score = x
res = idx + 1
print(ave, res)1-5. 정다면체
from sys import stdin
n, m = map(int, stdin.readline())
cnt = [0] * (n+m+3)
max = -2147000000
for i in range(1, n+1):
for j in range(1, m+1):
cnt[i+j] += 1
for i in range(n+m+1):
if cnt[i] > max:
max = cnt[i]
for i in range(n+m+1):
if cnt[i] == max:
print(i, end=' ')1-6. 자릿수의 합
from sys import stdin
n = int(stdin.readline())
a = list(map(int, stdin.readline().split()))
# def digit_sum(x):
# sum = 0
# while x > 0:
# sum += x%10
# x = x//10
def digit_sum(x):
sum = 0
for i in str(x):
sum += int(i)
return sum
max = -2147000000
for x in a:
total = digit_sum(x)
if total > max:
max = total
res = x
print(res)✏️ 에라토스테네스 체
체 = 걸러낸다는표현으로 2부터 n까지 for문을 돌면서 해당 i번째 수의 배수들을 방문표시함으로써 배수들을 걸러냄 (= 소수만 구할 수 있음)
from sys import stdin
n = int(stdin.readline())
ch = [0] * (n+1)
cnt = 0
for i in range(2, n+1):
if ch[i] == 0:
cnt += 1
for j in range(i, n+1, i):
ch[j] = 1
print(cnt)✏️ 뒤집은 소수
자연수를 뒤집은 후 그 수가 소수인지 판별하는 문제
# 뒤집은 소수
from sys import stdin
def reverse(x):
res = 0
while x > 0:
t = x % 10
res = res * 10 + t
x = x // 10
return res
def isPrime(x):
if x == 1:
return False
for i in range(2, x//2 + 1):
if x % i == 0:
return False
else:
return True
n = int(stdin.readline())
a = list(map(int, stdin.readline().split()))
for x in a:
tmp = reverse(x)
if isPrime(tmp):
print(tmp, end=' ')✏️ 점수 계산
[문제 링크] https://www.acmicpc.net/problem/2506
from sys import stdin
n = int(stdin.readline())
a = list(map(int, stdin.readline().split()))
sum = 0
cnt = 0
for x in a:
if x == 1:
cnt += 1
sum += cnt
else:
cnt = 0
print(sum)02.03 목
알고리즘 문제를 풀며 딕셔너리 서브 클래스 2개와 extend()메서드에 대해 정리해보았습니다.
✏️ defaultdict
defaultdict()는 딕셔너리를 만드는 dict클래스의 서브 클래스입니다.
기본 딕셔너리에서 존재하지 않는 키를 조회할 경우 KeyError가 발생합니다.
하지만 defaultdict는 존재하지 않는 키를 조회하면 에러가 나는 것이 아니라 해당 키에 대해 인자로 주어진 기본값을 딕셔너리값의 초기값으로 지정할 수 있습니다.
int, list, set 등으로 초기화 할 수 있기 때문에 이를 잘 활용하면 매우 수월하게 코드를 짤 수 있습니다.
예시
from collections import defaultdict
node = defaultdict(list)
node[1] = ['우리집', '강아지']
node[2] = ['두부']
print(node)
print(node[3])
print(node)
// 결과
defaultdict(<class 'list'>, {1: ['우리집', '강아지'], 2: ['두부']})
[]
defaultdict(<class 'list'>, {1: ['우리집', '강아지'], 2: ['두부'], 3: []})보면 3이라는 key가 node 딕셔너리에 없지만, 에러를 내보내지 않고 빈 리스트로 초기화 된 것을 확인하 ㄹ수 있습니다! 참고로 int로 초기화를 하면 node[3]은 0으로 초기화가 됩니다.
✏️ Counter
python collections모듈의 Counter 클래스를 사용하면 리스트 해당 원소가 리스트 내에서 몇개로 구성되어 있는지 확인할 수 있습니다. 문자열도 가능합니다.
예시 코드로 확인해보겠습니다.
from collections import Counter
counter = Counter('HelloWorld')
print(counter)
// 결과
Counter({'l': 3, 'o': 2, 'H': 1, 'e': 1, 'W': 1, 'r': 1, 'd': 1})리스트 예시
from collections import Counter
test_list = ['우리집', '강아지', '두부', '두부', '개껌을', '좋아해', '개껌을', '두부']
counter = Counter(test_list)
print(counter.most_common(2))
// 결과
[('두부', 3), ('개껌을', 2)]갯수가 많은 순서로 출력을 해줄 수도 있지만 most_common 메서드를 활용하면 갯수가 많은 순으로 원하는 갯수많은 list로 리턴받을 수 있습니다. 위 예시는 가장 원소 갯수가 많았던 두개를 뽑아낸 코드입니다.
다양한 연산도 실행할 수 있습니다.
subtract 예시
from collections import Counter
c = Counter(a=4, b=2, c=0, d=-1)
d = Counter(a=1, b=2, c=3, d=4)
c.subtract(d)
print(c)
// 결과
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -5})✏️ list append() vs extend()
[참고 블로그] https://m.blog.naver.com/wideeyed/221541104629
파이썬 리스트에 원소를 추가하는 방법은 append(x)와 extend(iterable)가 있고 두 함수의 차이점을 알아보겠습니다.
list.append(x)는 리스트 마지막에 x 원소 1개를 그대로 넣는 것이고
list.extend(iterable)는 리스트 끝에 가장 바깥쪽 iterable의 모든 항목을 넣습니다.
append()
a = ['우리집', '두부']
b = ['개껌을', '좋아해']
a.append(b)
print(a)
//결과
['우리집', '두부', ['개껌을', '좋아해']]extend()
a = ['우리집', '두부']
b = ['개껌을', '좋아해']
a.extend(b)
print(a)
//결과
['우리집', '두부', '개껌을', '좋아해']문자열일 경우
a = ['우리집', '두부']
b = '돼지야'
a.extend(b)
print(a)
//결과
['우리집', '두부', '돼', '지', '야']2차원 리스트일 경우
a = ['우리집', '두부']
b = [['그래서', '돼지야']]
a.extend(b)
print(a)
//결과
['우리집', '두부', ['그래서', '돼지야']]02.04 금
탐색 & 시뮬레이션과 관련한 문제 풀이를 진행했다
✏️ 회문 문자열 검사
# 회문 문자열 검사
from sys import stdin
n = int(stdin.readline())
for i in range(n):
s = stdin.readline()
s = s.upper() # 문자열 대문자화
size = len(s)
# for j in range(size//2):
# if s[j] != s[-1-j]:
# print("#%d NO" %(i+1))
# break
# else:
# print("#%d YES" %(i+1))
if s == s[::-1]:
print("#%d YES" %(i+1))
else:
print("#%d No" %(i+1))
✏️ 숫자만 추출
- isdigit() : 정말 숫자를 다 찾음 (ex 2의 제곱)
- isdecimal() : 0~9까지의 숫자만 찾아줌
# 숫자만 추출
from sys import stdin
s = stdin.readline()
res = 0
for x in s:
if x.isdecimal():
res = res * 10 + int(x)
print(res)
cnt = 0
for i in range(1, res+1):
if res % i == 0:
cnt += 1
print(cnt)✏️ 카드 역배치
# 카드 역배치
from sys import stdin
a = list(range(21))
for _ in range(10):
s, e = map(int, stdin.readline())
for i in range((e-s+1)//2):
a[s+i], a[e-i] = a[e-i], a[s+i] # 스와프
a.pop(0)
for x in a:
print(x, end=' ')✏️ 두 리스트 합치기
[시간복잡도 비교]
sort() = NlogN 퀵정렬
정렬이 이미 되어져 있는 것을 활용하면: N
-> 데이터가 커질 수록 굉장히 큰 차이임
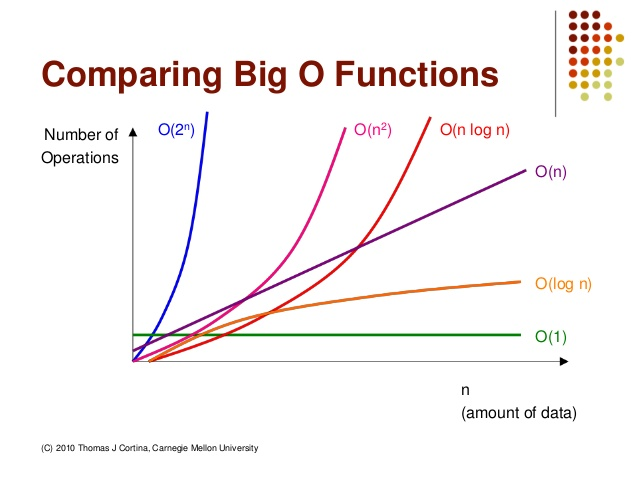
# 두 리스트 합치기
from sys import stdin
n = int(stdin.readline())
a = list(map(int, stdin.readline()))
m = int(stdin.readline())
b = list(map(int, stdin.readline()))
p1 = p2 = 0
c = []
while p1 < n and p2 < m:
if a[p1] <= b[p2]:
c.append(a[p1])
p1 += 1
else:
c.append(b[p2])
p2 += 1
if p1 < n:
c = c + a[p1:]
if p2 < m:
c = c + b[p2:]
for x in c:
print(x, end=' ')✏️ 수들의 합
# 수들의 합
from sys import stdin
n, m = map(int, stdin.readline().split())
a = list(map(int, stdin.readline()))
lt = 0
rt = 1
total = a[0]
cnt = 0
while True:
if total < m:
if rt < n:
total += a[rt]
rt += 1
else:
break
elif total == m:
cnt += 1
total -= a[lt]
lt += 1
else:
total -= a[lt]
lt += 1
print(cnt)✏️ 격자판 최대합
# 격자판 최대합
from sys import stdin
n = int(stdin.readline())
a = [list(map(int, stdin.readline())) for _ in range(n)]
largest = -2147000000
for i in range(n):
sum1 = sum2 = 0
for j in range(n):
sum1 += a[i][j]
sum2 += a[j][i]
if sum1 > largest:
largest = sum1
if sum2 > largest:
largest = sum2
sum1 = sum2 = 0
for i in range(n):
sum1 += a[i][i]
sum2 += a[i][n-i-1]
if sum1 > largest:
largest = sum1
if sum2 > largest:
largest = sum2
print(largest)