
언어 모델 : Language Model
단어 시퀀스에 확률을 할당(assign) 하는 일을 하는 모델
ex) 이전 단어들이 주어졌을 때 다음 단어를 예측
1. 필요한 이유
a. 기계 번역(Machine Translation):
P(나는 버스를 탔다) > P(나는 버스를 태운다)
: 언어 모델은 두 문장을 비교하여 **좌측의 문장**의 확률이 더 높다고 판단한
b. 오타 교정(Spell Correction):
P(선생님이 교실로 달려갔다) > P(선생님이 교실로 잘려갔다)
: 언어 모델은 두 문장을 비교하여 **좌측의 문장**의 확률이 더 높다고 판단
c. 음성 인식(Speech Recognition):
P(나는 메롱을 먹는다) > P(나는 메론을 먹는다)
: 언어 모델은 두 문장을 비교하여 **우측의 문장**의 확률이 더 높다고 판단언어 모델은 위와 같이 확률을 통해 보다 적절한 문장을 판단
2. 주어진 이전 단어들로부터 다음 단어 예측하기
A. 단어 시퀀스의 확률:
하나의 단어를 w, 단어 시퀀스를 대문자 W라고 한다면, n개의 단어가 등장하는 단어 시퀀스 W의 확률은
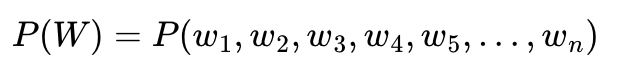
B. 다음 단어 등장 확률:
n-1개의 단어가 나열된 상태에서 n번째 단어의 확률은
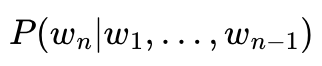
3. 언어 모델의 간단한 직관
앞에 어떤 단어들이 나왔는지 고려하여 다음 단어를 예측하고 가장 높은 확률의 단어를 선택하는 것
비행기를 타려고 공항을 갔는데 지각을 하는 바람에 비행기를 [?]
[?] = '놓쳤다'4. 검색 엔진에서의 언어 모델의 예
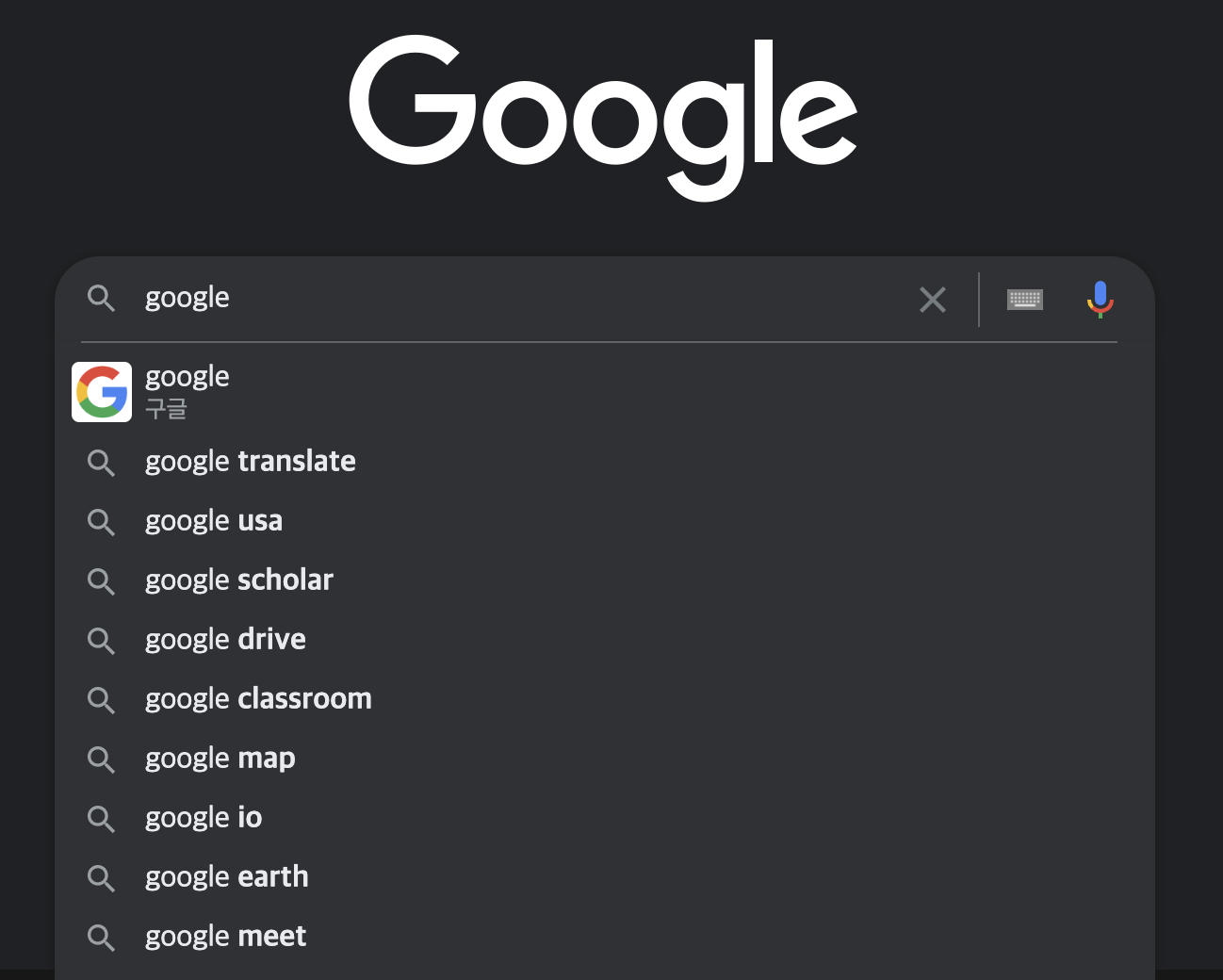
당신의 시간이 헛되지 않는 글이 되겠습니다.
I'll write something that won't waste your time.

원하는 것을 창조하고 창조한 것을 의미있게 사용하자