Spark's Function : 스파크의 기능
스파크의 라이브러리는 그래프 분석, 머신러닝 그리고 스트리밍 등 다양한 작업을 지원
컴퓨팅 및 스토리지 시스템과의 통합을 돕는 역할
이아직 다루지 않은 API와 주요 라이브러리 그리고 스파크가 제공하는 다양한 기능을 소개
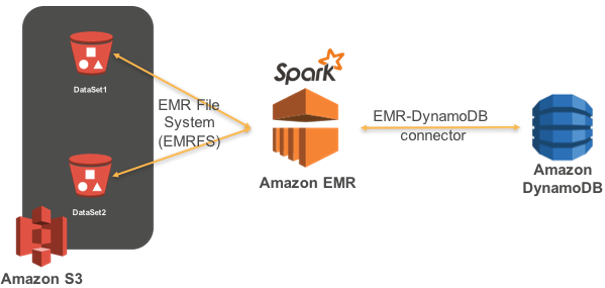
1. 운영용 애플리케이션 실행하기
spark-submit 명령을 사용해 대화형 셸에서 개발한 프로그램을 운영용 애플리케이션으로 쉽게 전환 가능
Spark-submit 명령은 애플리케이션 코드를 클러스터에 전송해 실행시키는 역할
클러스터에 제출된 애플리케이션은 작업이 종료되거나 에러가 발생할 때까지 실행
스파크 애플리케이션은 Standlone, Mesos, YARN 클러스터 매니저를 이용해 실행
Spark-submit 명령에 애플리케이션 실행해 필요한 자원과 실행 방식 그리고 다양한 옵션을 지정 가능
사용자는 스파크가 지원하는 프로그래밍 언어로 애플리케이션을 개발한 다음 실행 가능
가장 간단한 방법은 로컬 머신에서 애플리케이션을 실행
2. Dataset: 타입 안전성을 제공하는 구조적 API
Dataset은 자바와 스칼라의 정적 데이터 타입에 맞는 코드, 즉 정적 타입 코드를 지원하기 위해 고안된 스파크의 구조적 API
Dataset은 타입 안전성을 지원하며 동적 타입 언어인 파이썬과 R에서는 사용할 없음
Dataframe은 다양한 데이터 타입의 테이블형 데이터를 보관할 수 있는 Row 타입의 객체로 구성된 분산 컬랙션
Dataset API는 Dartaframe의 레코드를 사용자가 자바나 스칼라로 정의한 클래스에 할당
자바의 ArrayList 또는 스칼라의 Seq 객체 등의 고정 타입형 컬렉션으로 다룰 수 있는 기능을 제공
Dataset API는 타입 안전성을 지원하므로 초기화에 사용한 클래스 대신 다른 클래스를 사용해 접근할 수 없음
따라서 Dataset API는 다수의 소프트웨어 엔지니어가 잘 정의된 인터페이스로 상호작용하는 대규모 애플리케이션을 개발하는 데 특히 유용
Dataset 클래스(자바에서는 Dataset, 스칼라에서는 Dataset[T]로 표기한다.)는 내부 객체의 데이터 타입을 매개변수로 사용합
스파크 2.0 버전에서는 자바의 JavaBean 패턴과 스칼라의 케이스 클래스 유형으로 정의된 클래스를 지원
스파크는 이러한 타입을 제한적으로 사용할 수밖에 없음
그 이유는 자동으로 타입 T를 분석한 다음 Dataset의 표 형식 데이터에 적합한 스키마를 생성해야 하기 때문
Dataset은 필요한 경우에 선택적으로 선택적으로 사용할 수 있다는 장점이 있습니다. 이는 타입 안전성을 보장하는 코드에서 저수준 API를 사용할 수 있으며, 고수준 API의 SQL를 사용해 빠른 분석을 할 수 있게 합니다. 다른 장점으로는 collect 메소드나 take 메소드를 호출하면 Dataframe을 구성하는 Row 타입의 객체가 아닌 Dataset에 매개변수로 지정한 타입의 객체를 반환한다는 겁니다. 따라서 코드 변경 없이 타입 안전성을 보장할 수 있으며 로컬이나 분산 클러스터 환경에서 데이터를 안전하게 다룰 수 있습니다.
- 구조적 스트리밍
구조적 스트리밍은 스파크 2.2 버전에서 안정화된 스트림 처리용 고수준 API입니다. 구조적 스트리밍을 사용하면 구조적 API로 개발된 배치 모드의 연산을 스트리밍 방식으로 실행할 수 있으며, 지연 시간을 줄이고 증분 처리할 수 있습니다. 구조적 스트리밍은 배치처리용 코드를 일부 수정하여 스트리밍 처리를 수행하고 값을 빠르게 얻을 수 있다는 장점이 존재합니다. 또한 프로토타입을 배치 잡으로 개발한 다음 스트리밍 잡으로 변환할 수 있으므로 개념 잡기가 수월합니다.
스파크가 데이터를 처리하는 시점이 아닌 이벤트 시간에 따라 윈도우를 구성하는 방식에 주목할 필요가 있습니다. 이 방식은 사용하며 ㄴ기존 스파크 스트리밍의 단점을 구조적 스트리밍으로 보완할 수 있습니다.
- 머신러닝과 고급 분석
스파크가 인기 있는 이유는 내장된 머신러닝 알고리즘 라이브러리인 MLlib을 사용해 대규모 머신러닝을 수행할 수 있기 때문입니다. MLlib을 사용하면 대용량 데이터를 대상으로 전처리(preprocessing), 멍잉(munging), 모델 학습(model tarining), 및 예측(prediction)을 할 수 있습니다. 또한 구조적 스트리밍에서 예측하고자 할 때도 MLlib에서 학습시킨 다양한 예측 모델을 사용할 수 있습니다. 스파크는 분류(classification)부터 회귀(regression), 군집화(clustering) 그리고 딥러닝(deep learning)에 이르기까지 머신러닝과 관련된 정교한 API를 제공합니다.
- 저수준 API
스파크는 RDD를 통해 자바와 파이썬 객체를 다루는 데 필요한 다양한 기본 기능(저수준 API)을 제공합니다. 그리고 스파크의 거의 모든 기능은 RDD를 기반으로 만들어졌습니다. Dataframe 연산도 RDD를 기반으로 만들어졌으며 편리하고 매우 효율적인 분산 처리를 위해 저수준 명령으로 컴파일됩니다. 원시 데이터를 읽거나 다루는 용도로 RDD를 이용해 파티션과 같은 물리적 실행 특성을 결정할 수 있으므로 Dataframe보다 더 세밀한 제어를 할 수 있습니다.
RDD는 스칼라뿐만 아니라 파이썬에서도 사용할 수 있습니다. 하지만 두 언어의 RDD가 동일하진 않습니다. 언어와 관계없이 동일한 실행 특성을 제공하는 Dataframe API와는 다르게 RDD는 세부 구현 방식에서 차이를 보입니다. 낮은 버전의 스파크 코드를 계속해서 사용해야하는 상황이 아니라면 RDD를 사용해 스파크 코드를 작성할 필요는 없습니다. 최신 버전의 스파크에서는 기본적으로 RDD를 사용하지 않지만, 비정형 데이터나 정제되지 않은 원시 데이터를 처리해야 한다면 RDD를 사용해야 합니다.
- SparkR
SparkR은 스파크를 R 언어로 사용하기 위한 기능입니다. SparkR은 스파크가 지원하는 모든 언어에 적용된 원칙을 동일하게 따르고 있습니다. SparkR을 사용하려면 SparkR를 설치하고 코드를 실행하면 됩니다. R 사용자는 magrittr의 pipe 연산자와 같은 R 라이브러리를 사용해 스파크 트랜스포메이션 과정을 R과 유사하게 만들 수 있습니다. 이 특징을 잘 활용하면 정교한 플로팅(plotting) 작업을 지원하는 ggplot과 같은 라이브러리를 손쉽게 사용할 수 있습니다.
- 스파크의 에코시스템과 패키지
스파크가 자랑하는 최고 장점은 커뮤니티가 만들어낸 패키지 에코시스템과 다양한 기능입니다. 이러한 기능 중 일부는 스파크 코어 프로젝트에 포함되어 널리 사용되고 있습니다. 2017년 기준 300여 개 이상의 패키지가 존재하며 계속해서 늘어나고 있습니다.
