아파치 스파크란 : What is Apache Spark

통합 컴퓨팅 엔진이며 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합
스파크는 가장 활발하게 개발되고 있는 병렬 처리 오픈소스 엔진,
빅데이터에 관심 있는 여러 개발자와 데이터 사이언티스트에게 표준 도구가 되어감
스파크 지원 언어:
- 파이썬
- 자바
- 스칼라
- R
단일 노트북 환경부터 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행 가능
=> 단일 노트북부터 엄청난 규모의 클러스터로 확장 가능
1. 아파치 스파크의 핵심요소
1) 통합
스파크의 목표: 빅데이터 애플리케이션 개발에 필요한 통합 플랫폼을 제공
통합이라는 단어는 스파크의 핵심 목표
간단한 데이터 읽기에서부터 SQL 처리, 머신러닝 그리고 스트림 처리에 이르기까지 다양한 데이터 분석 작업을 같은 연산 엔진과 일관성 있는 API로 수행할 수 있도록 설계
스파크의 이러한 개발 사상은 현실 세계의 데이터 분석이 다양한 처리 유형과 라이브러리를 결합해 수행된다는 통찰에서 비롯
기존의 데이터 분석 작업을 더 쉽고 효율적으로 수행
-
일관성 있는 조합형 API를 제공
작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션 가능 -
직접 스파크 기반의 라이브러를 만들기 가능
API는 애플리케이션에서 다른 라이브러리의 기능을 조합해 더욱 성능을 발휘할 수 있도록 설계
예를 들어 SQL 쿼리로 데이터를 읽고 ML 라이브러리로 머신러닝 모델을 평가해야 할 경우
스파크 엔진은 이 두 단계를 하나로 병합하고 데이터를 한 번만 조회할 수 있게 함
스파크는 통합 엔진을 제공하며 빠르게 빅데이터 분석 업무의 표준이 됨
시간이 지나면서 스파크는 더 많은 처리 유형을 지원하기 위해 자체 API를 확장해나가고 있으며
스파크 프로젝트 개발자들은 통합 엔진을 더욱 정교하게 다듬고 있음
2) 컴퓨팅 엔진
스파크는 저장소 시스템의 데이터를 연산하는 역할만 수행할 뿐
영구 저장소 역할은 수행하지 않음
그 대신 클라우드 기반의 저장소 지원
- Azure Storage
- Amazon S3
- Apache Hadoop(분산 파일 시스템)
- Apache Cassandra(키-벨류 저장소)
- Apache Kafka(메시지 전달 시스템)
데이터 이동은 높은 비용을 유발
스파크는 데이터 저장 위치에 상관없이 처리에 집중
또한 사용자 API는 서로 다른 저장소 시스템을 매우 유사하게 볼 수 있도록 제작
따라서 애플리케이션은 데이터가 저장된 위치를 신경 쓰지 않음
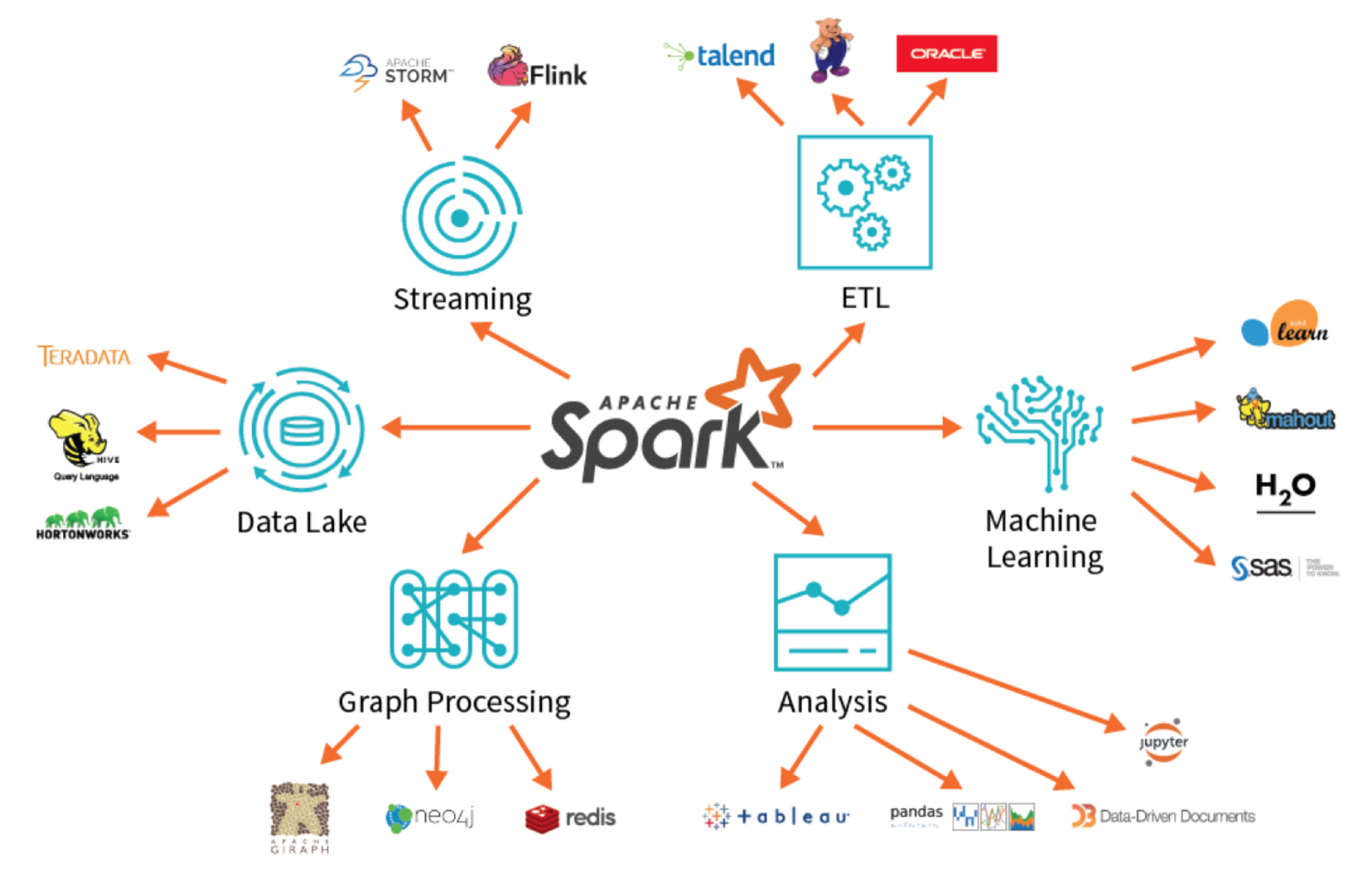
3) 라이브러리
스파크 컴포넌트는 데이터 분석 작업에 필요한 통합 API를 제공하는 통합 엔진 기반의 자체 라이브러리
스파크는 엔진에서 제공하는 라이브러리
- 표준 라이브러리
- 오픈소스 커뮤니티의 서드파티 패키지 형태로 제공하는 다양한 외부 라이브러리
스파크의 표준 라이브러리는 여러 오픈소스 프로젝트의 집합체
- 스파크 SQL과 구조화된 데이터를 제공하는 스파크 SQL
- 머신러닝을 지원하는 MLlib
- 스트림 처리 기능을 제공하는 스파크 스트리밍
- 구조적 스트리밍(Structured Stream)
- 그래프 분석 엔진인 GraphX 라이브러리
외부 라이브러리 목록
https://spark-packages.org
2. 스파크의 등장 배경
1) 경제적 요인 변화로 인해
프로세서의 성능 향상에 힘입어 빠르게 성장하였고
그 결과 애플리케이션은 코드를 수정하지 않아도 자연스럽게 빨라졌음
2) 대규모 애플리케이션은 이런 경향에 맞춰 만들어졌으며
대부분의 시스템은 단일 프로세서에서만 실행되도록 설계
3) 하드웨어의 한계를 보고
애플리케이션의 성능 향상을 위해 병렬 처리가 필요하며
스파크와 같은 새로운 프로그래밍 모델의 세상이 유망해질 것임을 암시
4) 데이터를 저장하는데 드는 비용은 14개월마다 절반으로 줄어들고
데이터 수집하는 비용은 계속해서 저렴해지고 정밀도는 개선
결과적으로 데이터 수집 비용은 극히 저렴해졌지만,
데이터는 클러스터에서 처리해야 할 만큼 거대해졌음
게다가 지난 50년간 개발된 소프트웨어는 더는 성능이 향상되지 않았고
데이터 처리 애플리케이션에 적용한 프로그래밍 모델도 더는 힘을 발휘하지 못함
따라서 새로운 프로그래밍 모델이 필요해졌고 문제를 해결하기 위해 아파치 스파크가 탄생
3. 스파크의 현재와 미래
수년 전에 공개된 스파크는 꾸준한 인기를 얻고 있으며
활용 사례가 늘어나고 있음
스파크 생태계의 여러 신규 프로젝트는 스파크의 영역을 꾸준히 넓혀나가고 있음
2016년에는 고수준 스트리밍 엔진인 Structured Stream을 소개
이 기술은 우버나 넷플릭스 같은 기술 회사뿐만 아니라 NASA, CREN 같은 연구소에서 거대한 규모의 데이터셋을 처리하기 위해 사용
스파크가 여전히 빠르게 성장하고 있다는 점을 고려하면
빅데이터 분석을 수행하는 기업의 핵심 기술일 것이라 예상 가능
Stop chasing the money and start chasing the passion.
Tony Hsieh
돈 쫓는 것 멈추고 열정 쫓기 시작하라.
토니 셰이
