분류 알고리즘
분류Classification은 학습 데이터로 주어진 데이터를 통한 모델 생성 후 예측하는 것
분류 알고리즘 종류
-
나이브 베이즈(Naive Bayes)
: 베이즈(Bayes)통계와 생성 모델 기반
-
로지스틱 회귀(Logistic Regressrion)
: 독립변수와 종속변수의 선형 관계성 기반
-
결정 트리(Decision Tree)
: 데이터 균일도에 따른 규칙 기반
-
서포트 벡터 머신(Support Vector Machine)
: 개별 클래스 간 최대 분류 마진 찾기
-
최소 근접(Nearest Neighbor)
: 근접 거리를 기준하는 알고리즘
-
심층 연결 기반의 신경망(Neural Network)
-
앙상블(Ensemble)
: 서로 다른(또는 같은) 머신러닝 알고리즘을 결합한 것
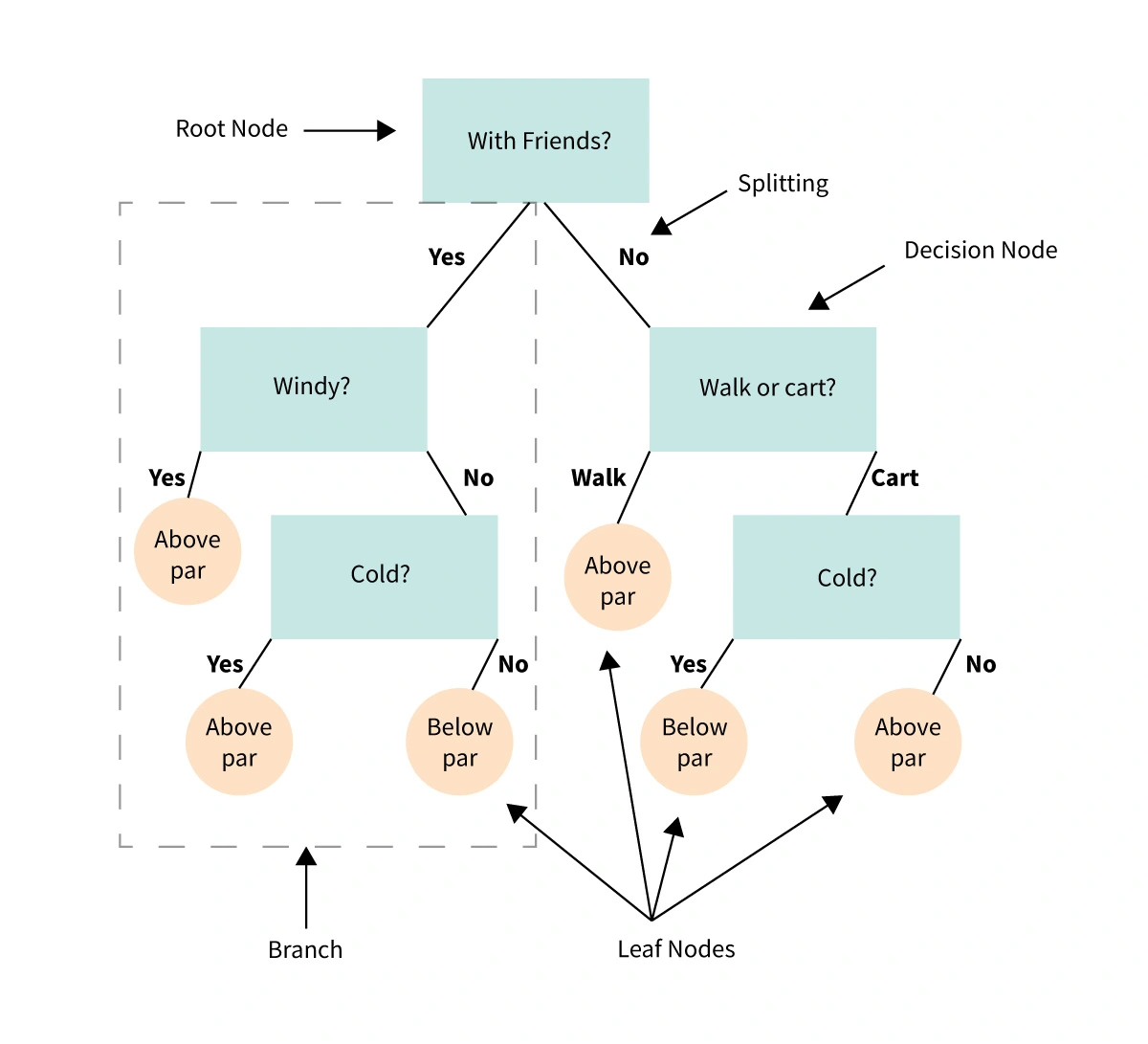
결정 트리 : Decision Tree
: 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 분류 규칙을 만드는 것 (if, else ...)
=> 데이터의 어떤 기준인가가 성능에 영향을 미침
매우 쉽고 유연하게 적용될 수 있는 알고리즘이다.
데이터의 스케일링이나 정규화 등의 사전 가공의 영향이 적다.
하지만 성능 향상을 위한 복잡한 규칙 구조응 지니고,
이로 인해 과적합(overfiting)이 발생해 예측 성능 저하가 가능하다
앙상블 기법에서는 오히려 장점이 된다.
앙상블의 특징: 여러 개의 약한 학습기를 결합해 확률적 보안과 오류를 업데이트 하며 향상
=> 결정트리는 오히려 도움이 됨
균일도 기반 규칙 조건
-
정보 이득(Imformation Gain)
: 데이터 혼잡도를 낮추는 방법으로 분할 (1-엔트로피 지수) -
지니 계수
: 불평등 지수 (낮을 수록 균일도가 높음)
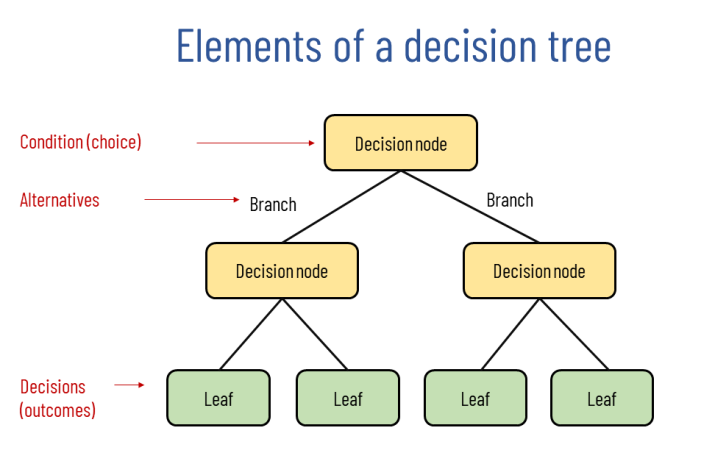
결정 트리의 규칙 노드 생성 프로세스
-
데이터 집합의 모든 아이템이 같은 분류에 속하는지 확인
-
리프 노드로 만들어서 분류 결정 (if)
-
데이터를 분할하는데 가장 좋은 속성과 분할 기준 찾기 (규칙 조건 활용)
-
해당 속성과 분할 기준으로 분할하여 규칙 브랜치 노드 생성
-
Recursive를 통해 모든 데이터 집합의 분류가 결정될 때까지 수행
장점:
- 쉽다, 직관적이다.
- 데이터 사전 가공 영향도가 적다
단점:
- 과적함이 발생할 가능성이 높다. (트리 크기 사전 제한 튜닝 필요)
주요 파라미터, 시각화 모듈
-
max_depth
트리의 최대 깊이를 규정
디폴트는 min_sample_split보다 작아질 때까지 계속 깊이 증가 -
max_feature (과제)
최적의 분할을 위해 고려할 최대 피처 개수
디폴트틑 모든 피처 사용 -
min_samples_split (과제)
노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합 제어
디폴트 2, 작게 설정할수록 과적합 가능성 증가 -
min_samples_leaf (과제)
밑단 노드(Leaf)가 되기 위한 최소한의 샘플 데이터 수
과적합 제어 용도 -
max_leaf_nodes
말단 노드(Leaf)의 최대 개수
시각화 모듈
-
Graphviz 실행 파일 설치
-
Graphviz 파이썬 래퍼 모듈 설치
-
OS 환경변수 구성
Life is from the inside out. When you shift on the inside, life shifts on the outside.
Kamal Ravikant
인생은 내면으로부터 나온다. 당신이 내면을 바꿀 때, 삶은 외부로 바뀐다.
카말 라비칸트
