결론
Q. 무슨 문제라고 그게?
A. DB에서 데이터를 로딩할 때,
1개의 쿼리로 N개의 A객체들을 로딩했더니 A객체들이 직접 참조하고 있는 B객체도 로딩해야 해서 추가로 N개의 쿼리가 더 나가는 일이 있어.
이때 DB 쿼리가 지나치게 많이 발생해서 문제가 돼.
Q. 그게 왜 문젠데?
A. DB 쿼리 하나에 0.001초(굉장히 빠른 편)밖에 안 걸린다고 해도 쿼리 1000개당 +1초씩이야. 실제 운영에 쓰이는 DB라면 이 문제를 방치할 경우 수천, 수만 개의 쿼리가 발생할 걸.
웹 페이지 하나 로딩하는 데 몇 초씩 걸려 봐. 오우 ㅅ..
Q. 어떤 상황에서 발생해?
A.
일대다관계에서일쪽 객체와다쪽 객체를 함께 로딩해야 하는 경우,일쪽 객체부터 조회할 때,다객체에 대한 참조가EAGER- 발생 (미발생하는 경우도 있긴 했으나..)다객체에 대한 참조가LAZY- 발생
다객체(연관 관계의 주인)부터 조회할 때,일객체에 대한 참조가EAGER- 미발생 (join된 하나의 쿼리만 실행됨)
그러나 JPQL을 써서다객체만 조회하면 발생. (일객체를 로딩하기 위한 N개의 쿼리가 추가적으로 실행됨)일객체에 대한 참조가LAZY- 발생
참고
실무에서는 모든 연관 관계에 지연 로딩(LAZY)을 사용해라.
즉시 로딩(EAGER)은 예상치 못한 쿼리가 나갈 수 있다.실무에서 EAGER는 그냥 없다고 생각하시는 것이 더 좋습니다.
- 김영한, 우아한형제들
Q. 어떻게 해결해?
A.
N쪽 객체에서1쪽 객체에 대한 참조를EAGER로 바꾸거나1쪽 객체를 로딩할 때 fetch join으로N쪽 객체까지 한꺼번에 로딩하면 되긴 하는데- 조회할 때랑 수정할 때랑 로딩 범위가 다를 수도 있고..
- 복잡하니까 도메인 주도 설계에 따라 직접 참조를 최소화하는 게 좋은 것 같아. 한꺼번에 로딩할 단위로 묶으면서 나누는 거랄까.
어떻게 문제가 발생하는가
상황
아래 코드를 보면 Team이 Member 다수를 직접 참조하고 있어.
// Team.kt
@Entity
class Team(
val name: String,
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(name = "member")
val members: List<Member>,
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long = 0L
)(값, 엔티티 구분은 일단 제쳐두자)
위 코드에선 예제를 단순화하기 위해
EAGER로 해 뒀는데
Team,EAGER인지LAZY인지는 상관 없어!
뭐든 시점이 다를 뿐 쿼리가 나가는 개수는 결국 같기 때문이야.
(ManyToOne에서EAGER인 경우에는 left outer join된 쿼리가 나가서 N+1 문제가 없긴 해)
// Member.kt
@Embeddable
class Member(
@Column
val name: String
)// TeamRepository.kt
interface TeamRepository : JpaRepository<Team, Long>문제 발생
자, 주문 목록 조회 요청이 들어왔다고 해 보자.
그럼 Order를 읽어야겠지.
// TeamRepositoryTest.kt
@DataJpaTest
class TeamRepositoryTest {
@Autowired
lateinit var teamRepository: TeamRepository
@PersistenceContext
lateinit var em: EntityManager
@Test
fun `N+1문제를 발생시켜 본다`() {
teamRepository.save(Team("A팀", listOf(Member("김씨"), Member("조씨"))))
teamRepository.save(Team("B팀", listOf(Member("이씨"), Member("유씨"))))
teamRepository.save(Team("C팀", listOf(Member("박씨"), Member("손씨"))))
em.flush() // 이 테스트에서 Member를 insert하기 위함
em.clear() // 새로 select해 오도록 하기 위함
teamRepository.findAll()
}
}위 코드를 실행하면 먼저 아래와 같은 쿼리가 한 개 날아가.
select
team0_.id as id1_26_,
team0_.name as name2_26_
from
team team0_"N+1 문제"에서 "1"이 의미하는 게 이 한 개의 쿼리야.
쿼리 결과 Team을 N개 읽어 와.
그러고 나서,
Team이 직접 참조하고 있는 Member들도 읽어오기 위해,
앞서 읽어 온 N개의 Team 각각의 id로 아래와 같은 쿼리가 1개씩 날아가.
select
members0_.team_id as team_id5_17_0_,
members0_.name as name3_17_0_
from
member members0_
where
members0_.team_id=?그럼 위 쿼리가 총 N개.
"N+1 문제"에서 "N"이 의미하는 게 바로 이 N개의 쿼리야.
결과적으로, 한 트랜잭션에서 1+N개의 쿼리를 실행하는 거지.
해결
1. 페치 조인(Fetch Join)
// TeamRepository.kt
interface TeamRepository : JpaRepository<Team, Long> {
@Query("select t from Team t join fetch t.members")
override fun findAll(): List<Team>
}아래와 같이 JOIN을 이용한 하나의 쿼리로 Member와 함께 Team들을 읽어서 전부 영속성 컨텍스트에 올린다.
select
team0_.id as id1_26_,
team0_.name as name2_26_,
members1_.team_id as team_id5_17_0__,
members1_.name as name3_17_0__
from
team team0_
inner join
member members1_
on team0_.id=members1_.team_id
join fetch가 아닌 그냥join을 쓰면 위 쿼리와 달리select에members1_.~들이 없을 거야. 이건Member를 영속성 컨텍스트에 올려 두지 않는다는 뜻이고, 그럼Member를 위해 따로 또 쿼리를 날려야 해.
그러나 다른 문제가 생긴다
teamRepository.findAll()의 반환값을 보면 뭔가 좀 이상해. A, B, C 세 팀만 만들었는데 6개나 나온단 말이야.
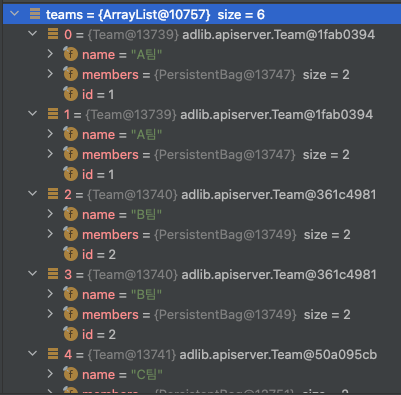
팀이 중복된 거야!
JOIN을 하면 대충 아래와 같은 결과가 나올 텐데, 이걸 JPA를 통해 객체로 변환하면서 생기는 문제야.
| team_id | team_name | member_name |
|---|---|---|
| 1 | A팀 | 김씨 |
| 1 | A팀 | 조씨 |
| 2 | B팀 | 이씨 |
| 2 | B팀 | 유씨 |
| 3 | C팀 | 박씨 |
| 3 | C팀 | 손씨 |
해결
- 코틀린 컬렉션의
distinct()함수 사용
teamRepository.findAll().distinct()
또는
- JPQL에
distinct추가
@Query("select distinct t from Team t join fetch t.members")
1번은 매번 호출해야 하는데 깜빡할 수도 있어서 2번이 나아 보여.
