0. 개요 및 서론
한달전 프로젝트를 하나 진행하려고 eBPF를 얕게 공부했었다. 이를 바탕으로 Observability 도구를 제작해보려고 했던건데, 아래와 같은 문제를 가지고 적절한 솔루션이 필요했기 때문이다.
- 인프라에서 Prometheus를 통한 L7(HTTP/HTTPS) Monitoring 솔루션을 구축하기 위해 애플리케이션에서 OpenMetrics 엔드포인트를 지원해야 하였으나 이를 지원하지 않았음
- Node Exporter를 사용하려고 해도 애플리케이션에서 제공하는 정보가 없음
- Istio + Envoy Sidecar와 같은 Service Mesh 솔루션을 도입하기엔 불필요한 오버헤드가 너무 큼
- 마찬가지로 오버헤드 문제와 인프라 특성상에 있어 Nginx 또는 HAProxy와 같은 리버스 프록시를 도입할 수 없었음
- 가능하다면 오버헤드가 거의 없고 뛰어난 성능의 솔루션이 필요함
최종적으로 마지막 사항까지 고려하여 eBPF 기반의 Observability 도구 또는 CNI 플러그인을 사용하기로 하였다. (미리 스포하자면 자체적인 eBPF 개발을 포기하고 Cilium CNI 및 Envoy Proxy 등을 도입하는 방식을 택하였다.)
1. 그냥 iptables 기반 CNI를 쓰면 안될까?
전통적인 Kubernetes 네트워킹 환경에서는 CNI 플러그인 자체의 Data Path, kube-proxy의 Service 처리, NetworkPolicy 구현 방식이 서로 결합되어 동작하는 경우가 많다.
특히 kube-proxy는 iptables 또는 IPVS를 사용해 Service 트래픽을 처리해왔고, Calico CNI 또는 Flannel CNI 등의 많은 CNI가 NetworkPolicy Enforcement 또는 라우팅 구현에서 Linux Kernel의 Netfilter(iptables 또는 IPVS) 기반에 크게 의존해왔다.
하지만 이는 대규모 인프라 환경에선 복잡하고 L3/L4 계층을 넘어서 확장하기 어렵다는 단점이 있다. 즉 iptables는 기본적으로 L3/L4 기반의 매칭을 제공하며, L7 수준의 세부 분석은 프록시나 별도의 L7 처리 계층이 필요하다.
또한 Kubernetes와 같이 대규모 컨테이너 오케스트레이션 환경에서 컨테이너 IP가 수시로 변경되는 컨테이너의 특성은 iptables에서 비효율적으로 작용하여 많은 불필요한 리소스를 소모할 수 있다.
2. BPF(Berkeley Packet Filter)
위와 같은 문제와 한계를 해결하기 위해 Linux에선 꽤나 재미있는 기능을 제공한다. 그 기능이 바로 BPF(Berkeley Packet Filter)인데, 이는 네트워크 캡처 및 필터링을 Linux의 User Space가 아닌 Kernel Space에서 직접 필터링하고 모니터링할 수 있다.
때문에 불필요한 패킷을 User Space로 복사하지 않고 tcpdump와 같은 패킷 분석 도구나 일부 방화벽 프로그램 등이 BPF를 이용하여 매우 효율적으로 동작할 수 있다.
기존의 BPF는 단순히 네트워킹과 관련된 동작을 위해 사용되는 기술이였고, 이 때문에 Packet Filter라는 이름도 붙었지만 Kernel 내부에서 안전하게 사용자 정의 로직을 실행할 수 있는 확장 메커니즘을 제공한다는 장점으로 꾸준히 발전되어 왔다.
출처: https://www.brendangregg.com/blog/2019-07-15/bpf-performance-tools-book.html
Kernel Space에서 동작하는 BPF 프로그램은 내부적으로 Bytecode로 구성되며 Kernel에서 해당 Bytecode를 실행하는 VM을 가진다.
Linux Kernel의 규모가 엄청나게 커지고 Kernel에 새로운 기능을 추가한다고 해도 이를 Stable 버전으로 릴리즈되기 몇 년 이상 소요될 수 있다.
때문에 Kernal에 새로운 기능을 추가하는 것이 아닌 BPF 프로그램을 Bytecode로 작성하여 Kernel 내 Virtual Machine으로 동작시키는 것이다. (Bytecode는 JIT 컴파일링을 통해 빠르게 실행된다.)
3. eBPF(extended Berkeley Packet Filter)
이러한 BPF의 큰 장점을 바탕으로 BPF Virtual Machine 레지스터의 확장, Stack 도입, 그리고 User Space 프로그램와 Kernel Space BPF 프로그램 간의 데이터 전송을 위한 Map 등을 도입하며 확장한 eBPF(extended Berkeley Packet Filter)가 등장하였다.
기존의 BPF는 eBPF와 헷갈리지 않도록 classic BPF, cBPF라고 명명하기도 한다. cBPF를 포함하여 eBPF의 동작 과정은 공식 홈페이지에서 매우 상세하게 확인해볼 수 있다.
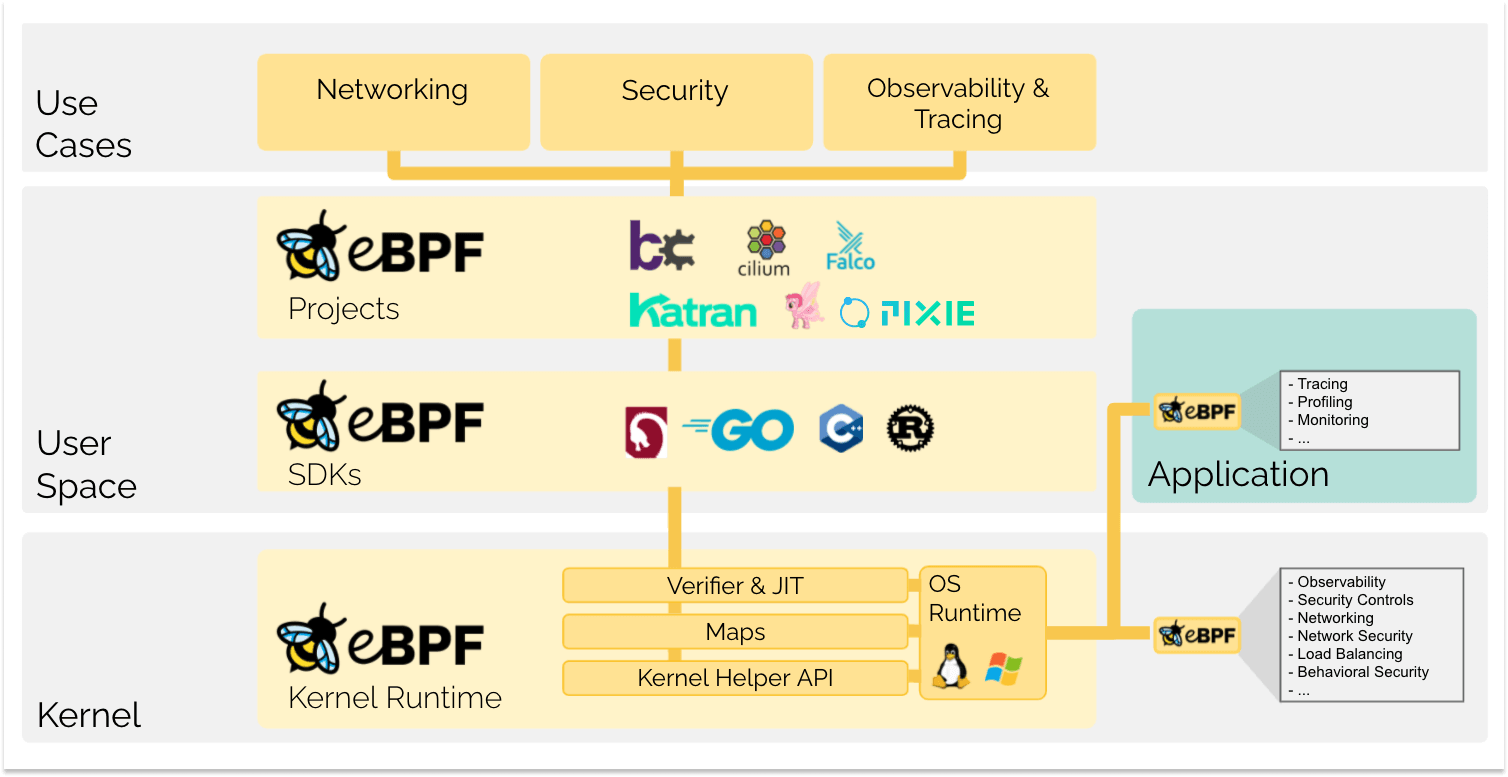
User Space에선 C/C++, Rust, Go 등으로 작성된 SDK로 프로그램을 개발하고 cBPF/eBPF 프로그램을 BCC(BPF Compiler Collection) 또는 bpftrace 등의 툴킷을 사용하여 컴파일할 수 있다.
한가지 다루지 않은 요소가 Verifier인데, 아무래도 Kernel Space에서 동작해야 하는 BPF 프로그램 특성상 무한 루프, Dangling Pointer, Panic/크래시 등이 발생하지 않도록 방지하고 위험 요소가 발견되면 Kernel Load를 제한한다.
eBPF에 대한 내용은 링크된 eBPF 홈페이지나 아래의 블로그를 참조하면 좋을 듯 싶다.
이러한 eBPF 기술을 사용하는 가장 유명한 Kubernetes CNI 플러그인이 바로 Cilium CNI이지 않을까 싶다. Calico나 Flannel CNI의 경우 앞선 iptables/IPVS를 기반으로 하는 반면 Cilium은 Kernel Space의 eBPF 프로그램을 로드하여 네트워킹 및 Advanced NetworkPolicy를 지원한다. (필요시 NetworkPolicy Only로 Cilium을 구성할 수 있다.)
다만 Calico 및 Flannel 등의 CNI에서도 eBPF 기반의 기능 요소가 있지만 전통적인 방향으로 고려한다.
Cilium을 비롯한 eBPF 기반의 도구나 CNI 사용에 있어 가장 큰 문제는 높은 러닝 커브와 디버깅의 어려움, 그리고 eBPF를 지원하는 Linux Kernel에 대한 의존성 문제가 있다. Cilium은 공식적으로 최소 Linux Kernel 5.4 이상 또는 5.10 이상을 권장한다.
만약 운영체제에서 eBPF를 지원하지 않거나 로컬 클러스터에서 실습해야할 경우 eBPF를 지원하는 컴퓨팅 리소스를 빌리거나 WSL2나 Lima와 같은 가상 머신을 이용하는 것도 좋은 방법이다.
필자의 경우 MacOS를 사용하는데 이는 eBPF를 지원하지 않는다. 때문에 Lima를 통해 Ubuntu 가상 머신을 실행하고 eBPF 프로그램을 개발하였다. MacOS를 위한 WSL2라고 생각하면 편하다.
eBPF를 지원하는지와 Kernel 버전을 확인하기 위해 아래의 명령어를 사용할 수 있다.
ky0422@lima-default:/Users/user$ uname -r 6.17.0-8-generic ky0422@lima-default:/Users/user$ grep CONFIG_BPF /boot/config-$(uname -r) CONFIG_BPF=y CONFIG_BPF_SYSCALL=y CONFIG_BPF_JIT=y CONFIG_BPF_JIT_ALWAYS_ON=y CONFIG_BPF_JIT_DEFAULT_ON=y CONFIG_BPF_UNPRIV_DEFAULT_OFF=y # CONFIG_BPF_PRELOAD is not set CONFIG_BPF_LSM=y CONFIG_BPF_STREAM_PARSER=y CONFIG_BPF_EVENTS=y CONFIG_BPF_KPROBE_OVERRIDE=ybpftool은 eBPF 프로그램을 관리하는 표준적인 도구로, 이를 통해서도 확인해볼 수 있다.
sudo bpftool feature probe sudo bpftrace -e 'BEGIN { printf("working\n"); exit(); }' # 또는 eBPF 프로그램 동작 여부 확인

4. CNI 대신 전용 eBPF 기반 Agent 개발??
사실 팀에서 운영하려던 프로젝트 자체가 EKS 환경의 VPC CNI에 큰 불만족은 없었고, CNI를 VPC CNI로 유지하는 방향이 적절하다고 합의까지된 상태였다.
다시 0. 개요 및 서론 이야기로 돌아와, 그래서 필자는 eBPF 기반의 L7(일단은 HTTP/HTTPS Only) Observability 도구를 "직접" 개발해보려고 시도하였다.
이 프로젝트의 기획하면서 가져가는 Moto와 철학은 다음과 같았다.
- eBPF 기반으로 매우 가벼워야한다. 메모리 사용률은 많아봤자 20MB 내외여야한다.
- Sidecar-less 성격을 가져야한다. Istio Sidecar 방식을 고려하지 않은 이유이기도 하며, 정확히는 Istio 자체의 운영 오버헤드를 원치 않았기 떄문이긴 하다.
- Cardinality-Safe한 라우트 정규화 기능이 포함되어있어야 한다. 이는
GET /posts/{id}와 같이 카디널리티가 무한에 가까울 경우 Prometheus가 수집하는 데이터의 양이 비대해진다. 이를 위해 앞서GET /posts/{id}와 같이 정규화시키는 기능이 필요하다. - 복잡한 구성 과정을 지양한다.
그 밖에도 여러 이유가 있었지만, 대표적으로 위와 같은 이유에서 직접 개발해보려고 하였다.
Kernel Hook을 어디에?
Linux Kernal의 Networking 과정에 있어 eBPF Hook을 걸 수 있는 여러 포인트가 존재한다. eBPF 기반의 Observability/Networking 도구는 어느 포인트에 Hook을 걸지에 따라 성격과 성능 모두에 영향을 끼친다.
아래의 순서는 대략적인 네트워크 패킷의 흐름에 따라 Low Level(Kernel Space)에서 High Level(User Space) 순서로 작성하였다.
XDP (eXpress Data Path)
xDS(.. Discovery Service)랑 헷갈리면 안된다. xDS는 본래 Envoy에서 복잡한 구성을 직접 구성 파일로 작성하지 않고 Control Plane인 Istio에서 받아와 동적으로 관리하기 위한 프로토콜 아키텍처다.
xDS 자체적으로 하나의 프로토콜은 아니고, 여러 API(LDS, RDS, CDS, EDS 등)의 API 집합을 의미한다. 각각 Listener, Router, Cluster, Endpoint 접두사를 의미하며 Istio의 컨트롤 플레인(Istiod)이 바로 그 xDS 서버 역할을 하게 된다.
아래의 두 자료를 참조하면 좋을 듯 싶다. 특히나 Alice_k106님이 작성하신 게시글들을 보면 값어치 있는 Cloud, Container, Kubernetes 등의 관련 지식을 많이 얻어갈 수 있다.
XDP(eXpress Data Path)는 Linux Kernel에서 NIC 바로 앞 단계(NIC 드라이버 수준)에 위치하여 매우 빠르고 패킷 Drop(XDP_DROP)시 발생하는 오버헤드가 거의 없다. (Kernel이 패킷을 위해 메모리(sk_buff=SKB)를 할당하기도 전에 동작)
이 때문에 DDoS 방어나 Early Filtering이 필요한 경우 고려해볼 수 있다. (이 중에서도 Offload mode, Native mode, Generic mode 등이 있지만 설명하진 않겠다.)
하지만 NIC 전 단계에서 Hook을 걸기 때문에 TCP State/Connection 및 Payload Parsing에 제한적이고 디버깅의 어려움, NIC 드라이버 의존성 등의 단점이 있다.
Observability 도구를 직접 제작해보는 입장에서 빠르면 좋겠지만 XDP는 제한적인 기능과 디버깅의 어려움 등으로 고려하지 않기로 하였다.
TC (Traffic Control)
NIC 뒤에 위치하고 Ingress/Egress 지점에 위치하여 XDP보단 느릴 수 있으나 여전히 빠른 성능과 Ingress/Egress, NAT, Routing 등의 여러 기능을 사용할 수 있기 때문에 L3/L4 Networking에 있어 가장 적절하다.
sk_buff(SKB) 구조체에 접근할 수 있다는게 가장 큰 장점이지만, 마찬가지로 우리가 원하는 L7 Observability 도구를 구현하기엔 한계가 있는 편이다.
물론 직접 HTTP/HTTPS 트래픽만 걸러 Payload를 파싱할 수 있겠지만 HTTPS 트래픽의 경우 TLS Termination 이후 분석할 수 있다. 이 문제는 추후 다뤄보겠다.
cgroup Hook, Socket 레벨 Hook 등
그리고 Pod 또는 Process 단위로 제어가 가능한, 즉 Socket Connection 시점에 제어가 가능한 cgroup Hook이 존재하지만 패킷 전체의 흐름을 보거나 Low level 제어엔 어려움이 있다.
Socket 레벨의 Hook은 Connection Aware 상태일때 해당 Connection에 대한 세부적인 조작을 다뤄야할 경우 고려해볼 수 있다.
kprobe / tracepoint (Kernel Space)
이는 Kernel 내부에의 모든 함수를 추적할 수 있고 Observability에 있어 매우 적절하고 디버깅, 분석에 매우 강력하지만 이에 따른 성능상의 오버헤드와 Kernel에 영향이 클 수 있다. 하지만 이 또한 우리가 원하는 L7 Path Observability엔 적절하지 않을 수 있다.
LSM(Linux Security Module)
이 자체로 넓은 주제라 직접 찾아보면 좋겠다. LSM은 보안 제어에 있어 매우 강력하고 파일, 프로세스, 네트워킹까지 통제할 수 있는 Hook 위치이다.
다만 이는 우리가 원하는 네트워킹 Hook과는 거리가 멀 수 있다. 사실 이걸 글 내용에 적을까 말까 생각하기도 했음..
uprobe / uretprobe (User Space)
이제부터 User Space로 애플리케이션 내부를 추적한다거나 라이브러리/함수 레벨의 분석 등을 구현할 수 있다.
하지만 필자가 추구하는 방향과는 다른 듯 싶었고, 때문에 필자는 Hook을 SKB를 다룰 수 있는 TC(Traffic Control)에 걸기로 하였다.
답정너) Hook 대신 Tracepoint로..
필자가 TC에 Hook을 걸고 __sk_buff 컨텍스트를 직접 받은 뒤 Verifier가 이해할 수 있도록 Bounds Check 후 파싱, 그리고 TC_ACT_OK, TC_ACT_SHOT과 같은 Action 코드를 기반으로 처리 결과를 돌려주는 방식으로 구현했었다.
하지만 사실 필자의 상황에선 더 좋은 방법이 있는데, Tracepoint는 Kernel이 특정 위치에서 이벤트를 발생시킨다고 미리 정의해둔 Hook 포인트이다.
Tracepoint 방식은 더 안정적이고 Attach가 간단하며 Verifier의 제약도 상대적으로 덜 받는 등 더 적절할 수 있다. 다만 패킷을 Drop한다거나 Datapath에 영향을 주는건 불가능한데 단순한/일반적인 Observability 도구에서 그런건 요구하지 않는다.
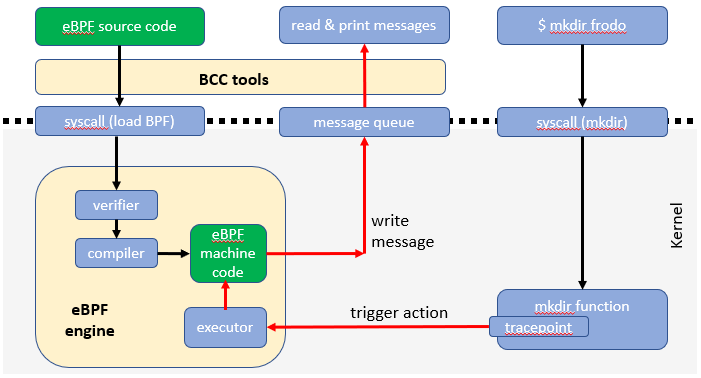
출처: https://bowers.github.io/eBPF-Hello-World
Tracepoint는 안정적인 Kernel 정적 추적 지점을 제공한다면 Kprobe는 Kernel 내 모든 함수에 동작으로 부착이 가능한 Hook 기술이다.
자유도는 당연히 Kprobe가 더 높겠지만 버전 변경시 함수의 시그니처가 변경되는 등의 경우가 발생한다면 동작하지 않을 수 있다.
필자는
tracepoint/net/netif_receive_skb라는 Tracepoint를 이용하기로 하였다.
구현하기: (Kernel Space) eBPF Program
Kernel Space의 eBPF VM에 적재될 eBPF 프로그램은 전통적으로 C 언어로 개발할 수 있으며 (사실상 표준인) libbpf를 사용할 수 있다. 이후 Clang이나 LLVM을 통해 eBPF Bytecode를 생성할 수 있다.
Rust에선 aya-rs를 사용하면 무려 Clang이나 LLVM에 의존하지 않고 libc 크레이트에만 의존하여 Rust Compiler만으로 eBPF Bytecode를 생성할 수 있다. 물론 그 외에도 여러 언어에서 많은 라이브러리/크레이트로 제공하고 있고, 이에 대한 대표적인 것들은 아래의 링크에서 확인해볼 수 있다.
필자는 생태계가 넓고 자료가 가장 많은 C언어로 MVP를 작성해보았다. 이에 대해선 아래의 웹 페이지에서 많이 참고하였다. eBPF에 대한 다양한 기술과 내용을 포함하고 있으니 관심있다면 전부 읽어보도록 하자.
개발 환경 설정하기
앞서 설명하였듯 필자는 MacOS를 사용하기 때문에 Lima를 통해 eBPF를 지원하는 Linux Kernel 및 Ubuntu 가상 머신을 실행하였다.
sudo apt update
sudo apt install -y clang llvm libbpf-dev libelf-dev bpftool build-essential linux-tools-common linux-tools-generic
clang --version
bpftool version환경에 따라 다르겠지만 아래와 같은 vmlinux, 관련 헤더 등이 포함되어있어야 한다.
ls /sys/kernel/btf/vmlinux
ls /usr/include/*/asm/types.h
# if not exist, sudo apt install linux-headers-$(uname -r)코드를 작성하기 전 아래와 같은 Makefile을 작성해두었다. bpftool btf dump file /sys/kernel/btf/vmlinux format c 명령어를 통해 vmlinux 헤더 파일을 가져올 수 있는데, 해당 라이브러리가 필요하니 초반에 make vmlinux를 실행하도록 하자.
CLANG := clang
BPF_CLANG := clang
ARCH := $(shell uname -m)
KARCH := $(shell uname -m | sed -e 's/x86_64/x86/' -e 's/aarch64/arm64/')
BUILD_DIR := .build
VMLINUX_DIR := headers
VMLINUX_H := $(VMLINUX_DIR)/vmlinux.h
INCLUDES := -I. -I$(VMLINUX_DIR) -I/usr/include/$(ARCH)-linux-gnu
BPF_CFLAGS := -O2 -g -target bpf $(INCLUDES) -D__TARGET_ARCH_$(KARCH)
USER_CFLAGS := -O2 -g
LIBS := -lbpf -lelf
TARGET := test
BPF_OBJ := $(BUILD_DIR)/$(TARGET).ebpf.o
BIN := $(BUILD_DIR)/$(TARGET)
all: $(BIN)
vmlinux: $(VMLINUX_H)
$(VMLINUX_H):
mkdir -p $(VMLINUX_DIR)
bpftool btf dump file /sys/kernel/btf/vmlinux format c > $(VMLINUX_H)
$(BPF_OBJ): $(TARGET).ebpf.c
mkdir -p $(BUILD_DIR)
$(BPF_CLANG) $(BPF_CFLAGS) -c $< -o $@
$(BIN): $(TARGET).c $(BPF_OBJ)
mkdir -p $(BUILD_DIR)
$(CLANG) $(USER_CFLAGS) $< -o $@ $(LIBS)
clean:
rm -rf $(BUILD_DIR)
.PHONY: all clean vmlinux이후 test.c(User Space)와 test.ebpf.c(Kernel Space) 프로그램을 작성하여 make로 빌드하면 된다.
test.ebpf.c
#include "vmlinux.h"
#include <bpf/bpf_endian.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define ETH_P_IP 0x0800
struct event {
__u64 ts_ns;
__u32 len;
__u16 proto;
__u8 is_ip;
__u8 _pad[1];
__u8 saddr[4];
__u8 daddr[4];
};
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(__u32));
__uint(value_size, sizeof(__u32));
__uint(max_entries, 128);
} events SEC(".maps");
struct trace_event_raw_netif_receive_skb {
__u16 common_type;
__u8 common_flags;
__u8 common_preempt_count;
__s32 common_pid;
__u64 skbaddr;
__u32 len;
__u32 __data_loc_name;
};
SEC("tracepoint/net/netif_receive_skb")
int handle_recv(struct trace_event_raw_netif_receive_skb *ctx)
{
struct event e = {};
void *data = NULL;
struct sk_buff *skb = (struct sk_buff *)ctx->skbaddr;
e.ts_ns = bpf_ktime_get_ns();
e.len = ctx->len;
e.proto = BPF_CORE_READ(skb, protocol);
if (e.proto == bpf_htons(ETH_P_IP)) {
struct iphdr iph;
data = (void *)BPF_CORE_READ(skb, data);
if (data && bpf_probe_read_kernel(&iph, sizeof(iph), data) == 0) {
__builtin_memcpy(e.saddr, &iph.saddr, sizeof(e.saddr));
__builtin_memcpy(e.daddr, &iph.daddr, sizeof(e.daddr));
e.is_ip = 1;
}
}
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &e, sizeof(e));
return 0;
}
char LICENSE[] SEC("license") = "GPL";eBPF 성격에 따라 Kernel과 같이 GPLv2를 요구할 수 있는데, 이건 직접 찾아보길 바란다.
위 코드는 tracepoint/net/netif_receive_skb Tracepoint에 붙어서 패킷 길이와 프로토콜을 읽고, 이더넷 프로토콜이 IPv4(0x0800)라면 SKB에서 IP 헤더를 읽는다.
그리고 Source/Destination IPv4 주소를 꺼내 그 결과를 Perf Event로 User Space 애플리케이션으로 전달한다. (Map을 쓰긴 하지만, 고속 스트리밍을 위해 Perf Event Map을 사용한다.)
이 포스팅의 주제가 eBPF 프로그램 개발은 아니기 때문에 빠르게 넘어가겠다.
구현하기: (User Space) Application
이는 User Space에서 동작하는 애플리케이션으로, eBPF 프로그램(.build/test.ebpf.o ELF)을 Kernel(eBPF VM)에 적재하고 Perf Event를 읽어 출력하는 프로그램이다.
test.c
#include <arpa/inet.h>
#include <errno.h>
#include <signal.h>
#include <stdio.h>
#include <sys/resource.h>
#include <unistd.h>
#include <bpf/libbpf.h>
#include <linux/types.h>
struct event {
__u64 ts_ns;
__u32 len;
__u16 proto;
__u8 is_ip;
__u8 _pad[1];
__u8 saddr[4];
__u8 daddr[4];
};
static volatile sig_atomic_t exiting;
static void handle_sig(int sig)
{
(void)sig;
exiting = 1;
}
static void handle_event(void *ctx, int cpu, void *data, __u32 data_sz)
{
struct event *e = data;
char src[INET_ADDRSTRLEN] = "-";
char dst[INET_ADDRSTRLEN] = "-";
struct in_addr saddr = {0};
struct in_addr daddr = {0};
(void)ctx;
(void)cpu;
(void)data_sz;
if (e->is_ip) {
__builtin_memcpy(&saddr, e->saddr, sizeof(saddr));
__builtin_memcpy(&daddr, e->daddr, sizeof(daddr));
inet_ntop(AF_INET, &saddr, src, sizeof(src));
inet_ntop(AF_INET, &daddr, dst, sizeof(dst));
}
printf("len=%u proto=0x%04x %s -> %s\n", e->len, ntohs(e->proto), src, dst);
}
static void handle_lost(void *ctx, int cpu, __u64 lost_cnt)
{
(void)ctx;
(void)cpu;
fprintf(stderr, "lost %llu events\n", (unsigned long long)lost_cnt);
}
int main()
{
struct bpf_object *obj = NULL;
struct bpf_program *prog = NULL;
struct bpf_link *link = NULL;
struct bpf_map *map = NULL;
struct perf_buffer *pb = NULL;
int map_fd;
struct rlimit rlim = {RLIM_INFINITY, RLIM_INFINITY};
signal(SIGINT, handle_sig);
signal(SIGTERM, handle_sig);
if (setrlimit(RLIMIT_MEMLOCK, &rlim)) {
fprintf(stderr, "failed to set rlimit\n");
return 1;
}
obj = bpf_object__open_file(".build/test.ebpf.o", NULL);
if (!obj) {
fprintf(stderr, "failed to open bpf object\n");
return 1;
}
if (bpf_object__load(obj)) {
fprintf(stderr, "failed to load bpf object\n");
return 1;
}
prog = bpf_object__find_program_by_name(obj, "handle_recv");
if (!prog) {
fprintf(stderr, "failed to find program\n");
return 1;
}
link = bpf_program__attach_tracepoint(prog, "net", "netif_receive_skb");
if (!link) {
fprintf(stderr, "failed to attach kprobe\n");
return 1;
}
map = bpf_object__find_map_by_name(obj, "events");
if (!map) {
fprintf(stderr, "failed to find events map\n");
return 1;
}
map_fd = bpf_map__fd(map);
pb = perf_buffer__new(map_fd, 8, handle_event, handle_lost, NULL, NULL);
if (!pb) {
fprintf(stderr, "failed to create perf buffer\n");
return 1;
}
printf("program loaded and attached\n");
while (!exiting) {
int err = perf_buffer__poll(pb, 100);
if (err < 0 && err != -EINTR) {
fprintf(stderr, "perf buffer poll failed: %d\n", err);
break;
}
}
perf_buffer__free(pb);
bpf_link__destroy(link);
bpf_object__close(obj);
return 0;
}마찬가지로 코드 설명이 이 포스팅의 주제는 아니기 때문에 넘어가고, 위 코드를 make를 통해 컴파일하고 User Space 프로그램을 실행하면 eBPF 프로그램이 적재되어 동작한다.
프로그램이 실행중인 상태에서 아래와 같이 Ping을 날려보겠다.
ping -c 1 1.1.1.1
ping -c 1 google.comprogram loaded and attached
len=84 proto=0x0800 1.1.1.1 -> 192.168.5.15
len=67 proto=0x0800 127.0.0.1 -> 127.0.0.53
len=67 proto=0x0800 127.0.0.1 -> 127.0.0.53
len=56 proto=0x0800 192.168.5.2 -> 192.168.5.15
len=56 proto=0x0800 192.168.5.2 -> 192.168.5.15
len=67 proto=0x0800 127.0.0.53 -> 127.0.0.1
len=212 proto=0x0800 192.168.5.2 -> 192.168.5.15
len=212 proto=0x0800 192.168.5.2 -> 192.168.5.15
len=163 proto=0x0800 127.0.0.53 -> 127.0.0.1
len=84 proto=0x0800 142.251.118.113 -> 192.168.5.15
len=85 proto=0x0800 127.0.0.1 -> 127.0.0.53
len=74 proto=0x0800 192.168.5.2 -> 192.168.5.15
len=85 proto=0x0800 127.0.0.53 -> 127.0.0.1그럼 위와 같이 IPv4 트래픽에 대한 Source/Destination IP가 나오게 되며 해당 패킷의 길이 또한 출력되는 모습을 볼 수 있다.
그런데 아무리 MVP 수준의 프로토타입이라고 해도 직접 만든 L7 Observability 도구라고 하기엔 너무나도 무색한데, 필자가 eBPF 프로그램을 개발하면서 현타와 살짝 왔기 때문이다.
eBPF 개발은 사실상 포기 선언.
지금까지의 내용을 모두 읽어보았다면 느껴졌겠지만, eBPF에 대한 기술적인 내용을 다루는게 아닌 약간의 뻘짓을 했다는 것을 알 수 있을 것이다.
필자가 한가지 간과하고 있던게, HTTPS 트래픽의 경우 TLS Termination을 어떻게 처리하냐이다. 이를 eBPF Observability 도구에서 TLS Termination을 해주지 않는 이상 암호화된 페이로드를 해석할 수 없을 것이다.
이와 별개로 eBPF 개발을 해보면서 자료가 그리 많은 편은 아닌지라 Linux Kernel을 직접 뜯어보는 정도의 개발 난이도를 가지고 있었고, 이를 따로 공부해야 했었다. 물론 이를 따로 공부할 시간은 없었다...
아무튼 이러한 문제로 eBPF 기반의 L7 Observability 도구 개발은 최종적으로 포기하기로 하였다. 그래서 이에 대한 대안을 찾아야했고, 건들지 않기로 VPC CNI를 eBPF 기반의 Cilium CNI로, L7 Proxy를 Node Level에 두는 방식으로 Envoy를 도입하기로 하였다.

5. Cilium CNI
Cilium CNI는 앞서 설명한 Linux Kernel의 eBPF 기반 고성능 Kubernetes CNI 플러그인이다.
기존 Calico 등의 iptables/IPVS 방식의 한계를 완화하고 eBPF를 통한 Pod 간 통신/라우팅(Data Path), Network Policy Enforcement Engine 등을 Kernel Space에서 처리할 수 있고, Observability는 eBPF 기반 Kernel 이벤트와 User Space 컴포넌트(Hubble 등)의 조합으로 제공된다.
한가지 특이사항은 Cilium은 IP 주소 기반이 아닌 Pod ID, Label을 통한 Network Policy 적용과 L7 등의 정밀한 Policy를 적용할 수 있다는 것이다. (Pod의 Label을 기반으로 고유한 Security Identity를 생성하고, eBPF Map에 등록하여 Enforce하는 방식이다.)
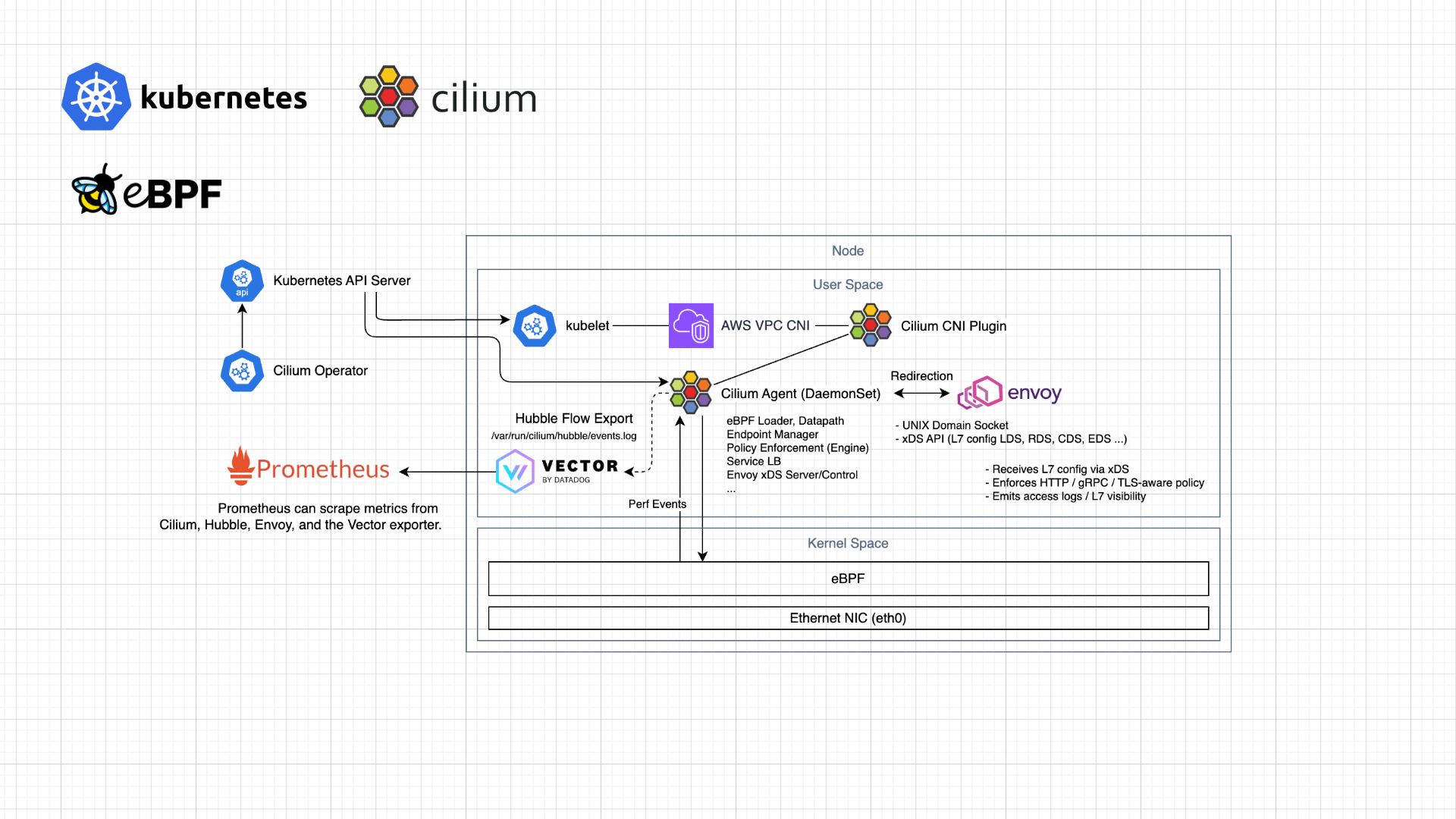
또한 Hubble이라는 네트워크 트래픽을 실시간으로 관찰, 분석 및 시각화하는 분산형 Observability 플랫폼을 가지고있으며 Kernel 레벨에서 디버깅 및 트레이싱을 지원한다.
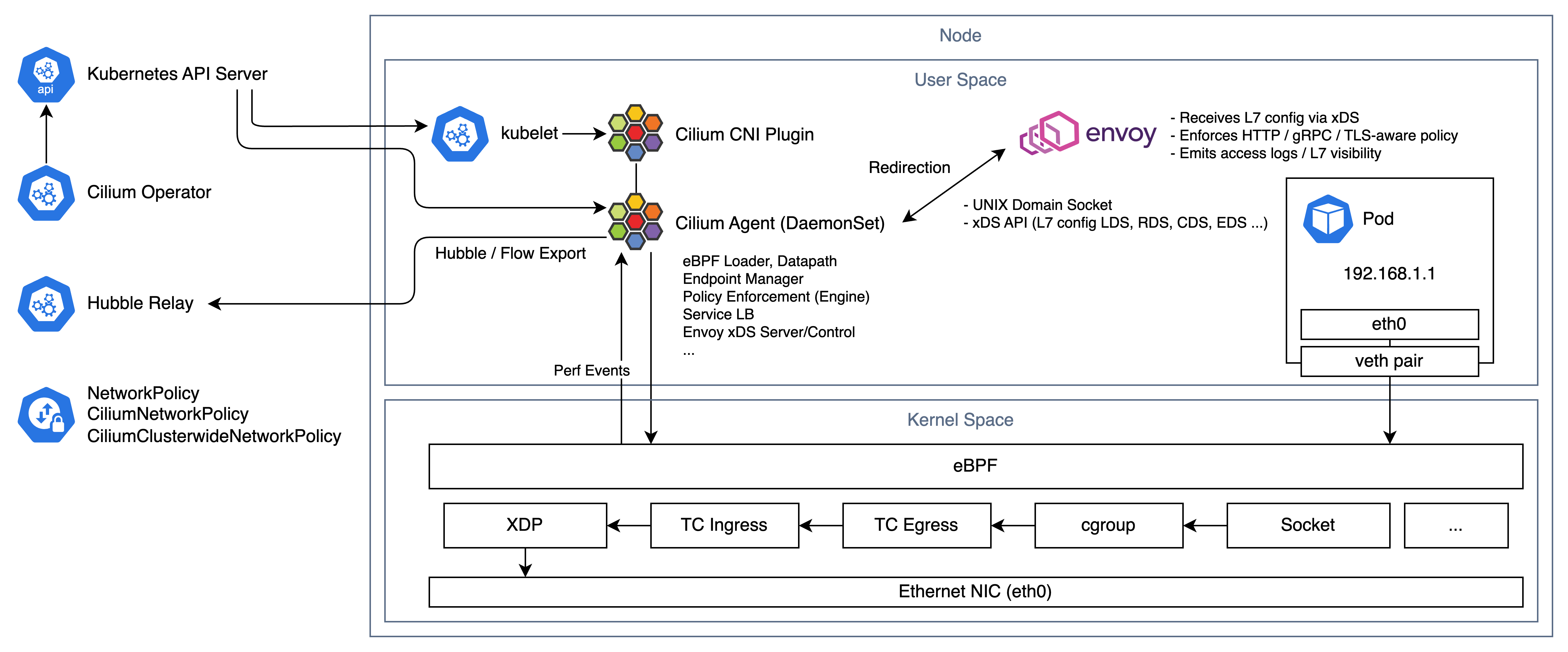
CNI에서 통신 방식에 따라 Overlay 방식과 Native Routing으로 나뉠 수 있다.
전자는 VXLAN/Geneve 기반의 Encapsulation 및 터널링 방식으로 네트워크를 가상화하며 대표적으로 Calico CNI, Flannel CNI가 존재한다.
후자는 Encapsulation하지 않고 Pod IP를 Node에서 직접 라우팅하고 터널링이 없어 고성능을 제공하지만 이에 따라 복잡해질 수 있다.
이 방식은 터널링 없이 라우팅 테이블 기반으로 직접 통신하며, Cilium과 같은 경우 eBPF 기반 Data Path를 활용해 이를 최적화할 수 있다. AWS VPC CNI 또한 이러한 Native Routing 방식을 따른다.
클라우드 네이티브와의 통합성은 Native Routing 방식이 더 적절하고, 필자도 이러한 점으로 EKS 환경에서 Cilium을 도입하기로 하였다.
VPC CNI를 어떻게 두는가.
Cilium CNI를 도입한다는 얘기는 어떻게보면 기존 VPC CNI를 완전히 대체한다는 의미로 해석될 수 있다. 하지만 VPC CNI를 완전히 제거할 필요는 없고, 어떻게 운영하느냐에 따라 장단점이 발생한다.
- VPC CNI 유지 + Cilium CNI Policy Only 모드
- VPC CNI 유지 + Cilium CNI Chaining 모드
- VPC CNI 제거 + Cilium CNI Full 모드
설명에서 유추할 수 있듯이 첫번째 모드는 NetworkPolicy Enforcement에 대한 Engine만 구성하는 방법이다. eBPF 기반의 Cilium CNI에서 NetworkPolicy는 앞서 설명하였듯 Pod ID를 기반으로 세부적으로 구성할 수 있기 때문에 좋은 선택이 될 수 있다.
하지만 필자가 원하고자 하는건 아니기 때문에 앞 2개의 모드에 대해 다뤄보고자 한다.
Cilium CNI Chaining Mode
EKS 환경에서 VPC CNI는 네트워크 라우팅과 같은 주요 기능 외에도 Pod IP를 할당하는 역할도 수행한다. 앞서 설명하였듯 VPC CNI 또한 Native Routing 방식으로 VPC CIDR 대역을 사용하며 IPAM를 기반으로 할당한다.
Cilium CNI Chaining은 이와 같이 Cloud Provider(AWS VPC CNI 등)가 Pod IP 할당과 기본 네트워크 구성을 유지한 상태에서, Cilium이 eBPF 기반으로 Network Policy Enforcement, 트래픽 처리, Observability 기능 등을 추가로 수행하는 방식이다.
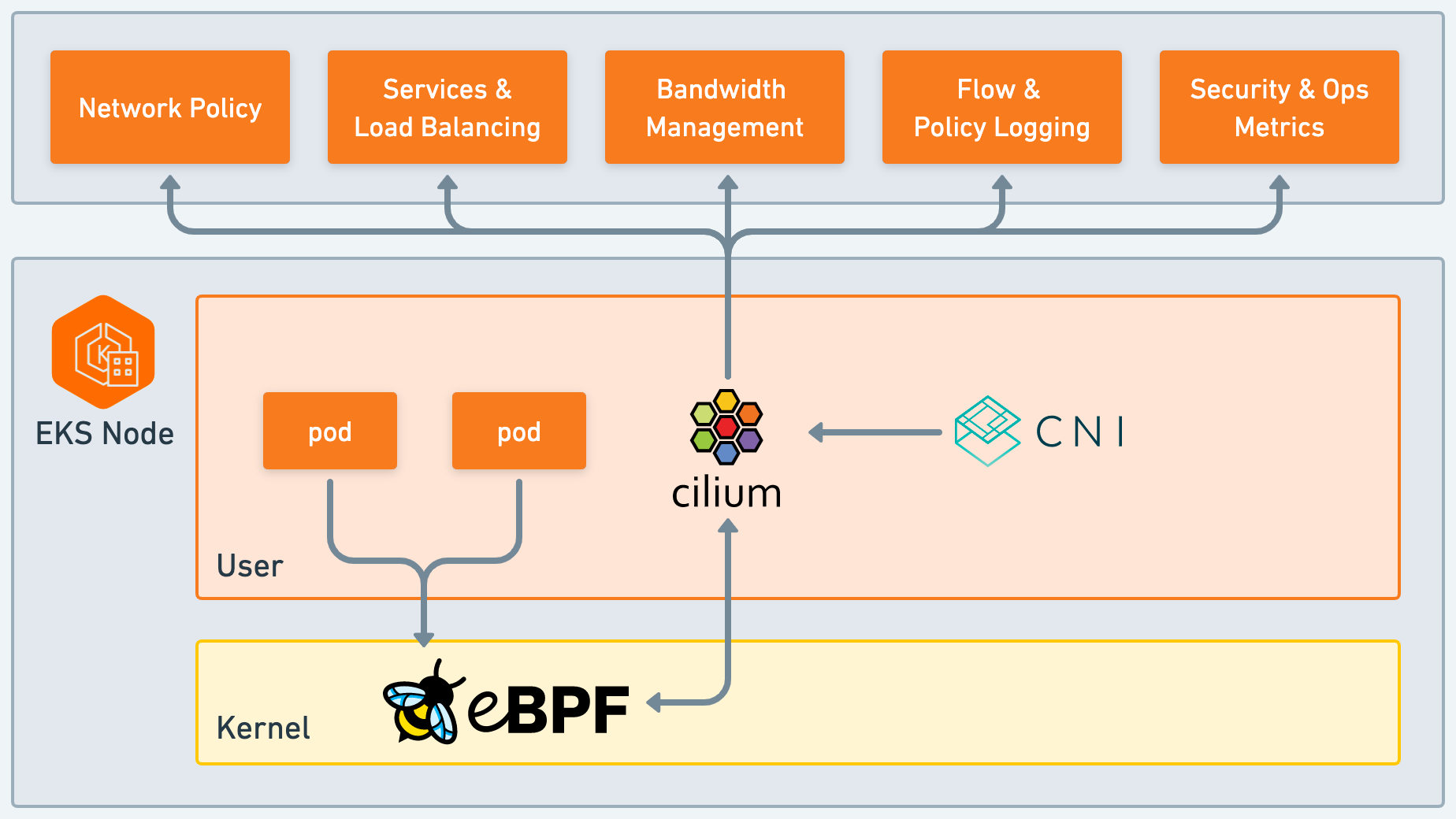
출처: https://docs.cilium.io/en/stable/installation/cni-chaining-aws-cni
Cilium CNI Full Mode
이 모드는 Pod IP 할당과 네트워킹 등 모두 Cilium에 위임하는 방식으로 VPC CNI를 완전히 제거하여 Cilium이 네트워크 스택 전체를 담당하도록 할 수 있다.
eBPF 기반 Data Path를 통해 패킷 전달과 NetworkPolicy Enforcement를 수행할 수 있으며, kube-proxy 대체가 가능하기 때문에 성능 최적화에 기여할 수 있다.
다만 AWS 네이티브 통합 방식을 일부 포기해야하고, 기존 IPAM 방식을 통한 VPC CNI Pod IP 할당을 직접 처리해야한다. 이는 Overlay 방식 또는 ENI IPAM 방식을 선택할 수 있고 크게 아래와 같이 구성할 수 있다.
- AWS ENI IPAM
- Cluster Scope IPAM
- Multi-Pool IPAM
- Kubernetes Host-Scope IPAM
- CRD-Backend IPAM
이에 대해서 내용은 Cilium 문서에서 자세히 다루고있다. 필자가 모든 방식을 사용해본 것도 아니고 일부는 공부가 더 필요하기 때문에 설명하는 것은 무리라고 판단했다. 대신 아래의 문서로 대체한다.
간단하게 정리하면 AWS ENI IPAM은 VPC에서 직접 할당 가능한 IP를 사용하는 방식이고, Cluster Scope, Multi-Pool, Host-Scope IPAM은 클러스터 내부 CIDR을 기반으로 Pod IP를 할당하는 방식이다. 마지막으로 CRD-Backend IPAM은 외부에서 개별 IP를 직접 주입하는 특수한 방식이다.
다만 이러한 IPAM 방식과 Overlay/Native Routing 여부는 별개의 개념이며, 실제 Data Path가 Overlay인지 Native Routing 인지는 네트워크 구성에 따라 달라진다.
VPC CNI 방식의 큰 단점이 ENI에서 나타나는 Pod IP 부족일텐데, 물론 Prefix Delegation를 활성화하면 할당 가능한 IP가 증가할 수 있지만 여전히 근본적인 문제는 존재한다.
Cilium Full 모드(혹은 Overlay)에서 AWS ENI IPAM을 제외한 방식을 선택하는 것이 도움이 될 수 있지만, 앞서 설명하였듯 AWS 네이티브 통합과의 트레이드오프가 발생할 수 있다.
그래서?
팀에서(정확히는 필자가) 최종적으로 Cilium CNI를 도입하는데 Pod IP 할당 방식을 AWS VPC CNI IPAM으로 유지하고, 라우팅 및 로드밸런싱, NetworkPolicy Enforce 등만 Cilium CNI를 사용하는 Chaining 방식을 선택하기로 하였다.
물론 기존 VPC CNI도 AWS VPC Native Routing 방식을 사용하기 때문에 큰 불편함은 느끼지 못하였으나, 필자가 직면한 문제의 근본적인 원인은 네트워킹 Observability이기 때문에 이러한 선택을 하였다.
늘 함께하는, Envoy Proxy.
하지만 Cilium CNI는 L3/L4 위주의 네트워킹을 제공하지, 우리가 진정 원하는 L7 제어나 Observability 요소를 제공하지 않는다.
때문에 일반적으로 Node-wide 형태로 DaemonSet으로 배포되는 Envoy Proxy를 두고 L7 트래픽을 Redirect해서 Envoy Proxy를 거치도록 구성할 수 있다.

Envoy는 고성능 L3/L4/L7 Proxy로, MSA 아키텍처 및 서비스 메시의 대표적인 Istio에서 Sidecar 방식으로 자주 선택되는 Proxy이기도 하다.
Cilium에서도 L7 트래픽을 보다 효과적으로 처리하기 위해 Envoy Proxy를 사용할 수 있다.
이 경우 Istio의 서비스 메시 모델이 아닌지라 굳이 Pod 단위로 Sidecar Proxy를 관리할 이유도 없고, 이미 eBPF가 Kernel에서 트래픽을 잡고있기 때문에 Sidecar 방식의 Proxy를 둘 필요도 없다. (정확하게는 Pod 단위 Proxy가 가져오는 운영 복잡도와 운영시 오버헤드를 피하기 위함이다.)
필자의 주 목적인 L7 Observability 또한 이를 통해 구성이 가능하다. Hubble Relay와 Envoy가 직접 통신하는 방식은 아니고, 중간에 Cilium Agent가 개입하는 방식이다.
Cilium과 Envoy에 대한 설명은 대충 여기서 마무리하고, 이제부터 EKS 클러스터를 프로비저닝하여 직접 Cilium CNI 및 Envoy Proxy, Hubble, Prometheus 등을 배포해보겠다.
6. Cilium + Envoy 도입해보기 (PoC)
최대한 Best Practices를 지향하지만 그 설치 과정에 있어선 개인적인 방식을 사용할 수 있다. 이 점을 참고하여 적절하게 각자의 환경에 맞도록 설치하면 된다.
이 포스팅에서 구성해볼 아키텍처는 아래와 같다. Cilium CNI는 VPC CNI와 Chaining 할 것이다.
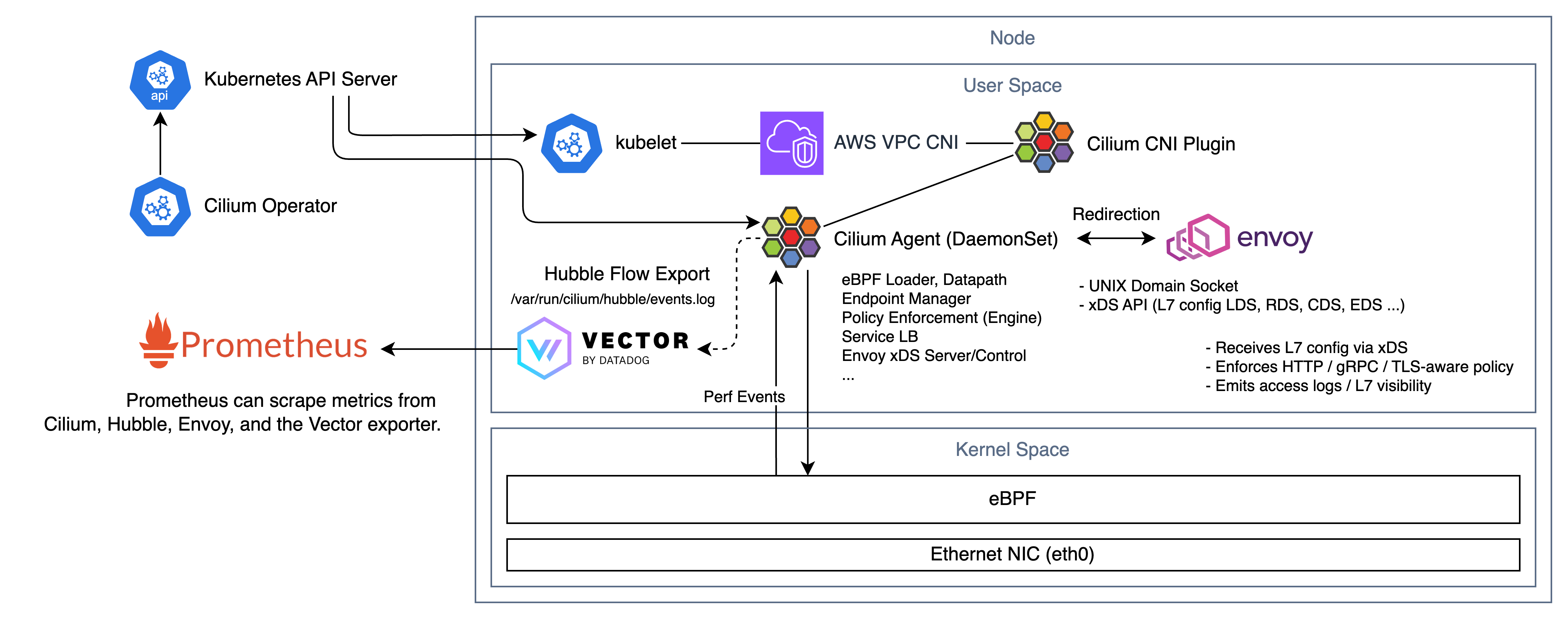
여기서 앞서 설명한 gRPC를 통해 통신하는 Hubble Relay를 사용하진 않을 것인데, 대신 간단하게 Hubble Flow Export를 통해 로그 파일로 저장한다.
이후 이를 Datadog Vector에서 수집하여 Cardinality 정규화를 거쳐 Prometheus Metrics를 노출한다.
EKS Cluster
EKS 클러스터는 eksctl을 사용하도록 하겠다. PoC를 위한 최소한의 인스턴스 유형과 노드 수를 가지고있으니 프로덕션에선 권장하지 않는다.
eksctl create cluster -f eks-cluster.yaml# eks-cluster.yaml
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: cilium-poc
region: ap-northeast-2
version: "1.35"
iam:
withOIDC: true
managedNodeGroups:
- name: ng-poc
instanceType: t3.medium
desiredCapacity: 1
minSize: 1
maxSize: 2
addons:
- name: vpc-cni
version: latest
- name: coredns
version: latest
- name: kube-proxy
version: latest실습에 있어 Pods Limit가 뜨면 워커 노드 수를 2개로 늘리면 되고, 표준 지원이 되는 버전을 추천한다. 필자는 Kubernetes 1.35를 사용하겠다.
Prometheus
Cilium 설치 전 Prometheus CRD 사용을 위한 Prometheus Stack을 Helm Chart로 설치하겠다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
-f prometheus-values.yaml# prometheus-values.yaml
grafana:
enabled: false
alertmanager:
enabled: false
kubeStateMetrics:
enabled: false
nodeExporter:
enabled: false
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelector:
matchLabels:
release: kube-prometheus-stack
serviceMonitorNamespaceSelector:
matchLabels:
monitoring: "enabled"
podMonitorSelectorNilUsesHelmValues: false
podMonitorSelector:
matchLabels:
release: kube-prometheus-stackCilium
다음으로 Helm을 통해 Cilium을 설치해보겠다. Cilium Helm Chart에서 Envoy Proxy, Hubble을 포함하기 때문에 이를 통해 설치해주겠다. Prometheus Enabled는 Cilium, Envoy 등에 대한 자체적인 Prometheus Metrics를 노출하기 위함이다.
helm repo add cilium https://helm.cilium.io/
helm repo update
helm install cilium cilium/cilium \
--namespace kube-system \
--version 1.19.2 \
-f cilium-values.yaml# cilium-values.yaml
cni:
chainingMode: aws-cni
exclusive: false
routingMode: native
enableIPv4Masquerade: false
kubeProxyReplacement: false
prometheus:
enabled: true
serviceMonitor:
enabled: true
labels:
release: kube-prometheus-stack
operator:
prometheus:
enabled: true
serviceMonitor:
enabled: true
labels:
release: kube-prometheus-stack
# Envoy as DaemonSet (node-wide)
envoy:
enabled: true
prometheus:
enabled: true
serviceMonitor:
enabled: true
labels:
release: kube-prometheus-stack
# Hubble + Flow Export
hubble:
enabled: true
relay:
enabled: false
ui:
enabled: false
export:
static:
enabled: true
filePath: /var/run/cilium/hubble/events.log
metrics:
enableOpenMetrics: true
enabled:
- httpV2:exemplars=true;labelsContext=source_namespace,source_workload,destination_namespace,destination_workload,traffic_direction
serviceMonitor:
enabled: true
labels:
release: kube-prometheus-stackHubble Relay/UI는 비활성화 해뒀는데, 필요시 활성화하는 등 적절하게 수정하자.
cni.chainingMode: aws-cni 및 cni.exclusive: false 옵션은 VPC CNI가 먼저 IPAM을 담당하고 Cilium이 뒤에서 eBPF Data Path 등을 붙이는 Chaining 모드 설정이다. 후자는 Cilium CNI가 독점하지 않게하기 위한 옵션이다.
또한 VPC CNI가 기본 라우팅을 담당하므로 Cilium CNI에선 Native Routing + Masquerade 비활성화가 일반적이다. (routingMode: native, enableIPv4Masquerade: false)
Hubble Flow Export + ServiceMonitor
Hubble Flow Export 파일을 읽고 경로를 정규화하여 Prometheus Metrics를 만드는 핵심적인 파이프라인으로, 이때 Vector DaemonSet 및 구성 파일이 적용된다.
# hubble-flow-metrics.yaml
apiVersion: v1
kind: Namespace
metadata:
name: observability
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: hubble-flow-metrics
namespace: observability
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: hubble-flow-metrics
rules:
- apiGroups: [""]
resources: ["pods", "namespaces", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: hubble-flow-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: hubble-flow-metrics
subjects:
- kind: ServiceAccount
name: hubble-flow-metrics
namespace: observability
---
apiVersion: v1
kind: ConfigMap
metadata:
name: hubble-flow-metrics-config
namespace: observability
data:
vector.toml: |
[sources.hubble_flows]
type = "file"
include = ["/var/run/cilium/hubble/events.log"]
read_from = "end"
[transforms.flow_json]
type = "remap"
inputs = ["hubble_flows"]
source = '''
. = parse_json!(.message)
'''
[transforms.http_only]
type = "filter"
inputs = ["flow_json"]
condition = 'exists(.flow.l7.http)'
[transforms.normalize_http]
type = "remap"
inputs = ["http_only"]
source = '''
http = .flow.l7.http
url = ""
url, err = to_string(http.url)
if err != null { url = "" }
path = url
parsed, err = parse_url(url)
if err == null && parsed.path != null {
path = parsed.path
}
path = split!(path, "?")[0]
path = split!(path, "#")[0]
if path == "" { path = "/" }
path = to_string(path)
path = replace(path, r'/[0-9]+', "/{id}")
path = replace(path, r'/[0-9a-fA-F-]{8,}', "/{id}")
.method = to_string(http.method) ?? "UNKNOWN"
.path_norm = path
.status_code = to_int(http.code) ?? 0
.status_class = if .status_code > 0 { to_string((.status_code / 100) * 100) } else { "0" }
.count = 1
'''
[transforms.log_to_metric]
type = "log_to_metric"
inputs = ["normalize_http"]
metrics = [
{ type = "counter", name = "l7_http_requests_total", field = "count", tags = { method = "{{method}}", path = "{{path_norm}}", status_class = "{{status_class}}" } }
]
[sinks.prometheus]
type = "prometheus_exporter"
inputs = ["log_to_metric"]
address = "0.0.0.0:9598"
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: hubble-flow-metrics
namespace: observability
labels:
app: hubble-flow-metrics
spec:
selector:
matchLabels:
app: hubble-flow-metrics
template:
metadata:
labels:
app: hubble-flow-metrics
spec:
serviceAccountName: hubble-flow-metrics
tolerations:
- operator: Exists
containers:
- name: vector
image: timberio/vector:0.38.0-alpine
args: ["-c", "/etc/vector/vector.toml"]
ports:
- name: prom
containerPort: 9598
volumeMounts:
- name: config
mountPath: /etc/vector
- name: hubble-export
mountPath: /var/run/cilium/hubble
readOnly: true
volumes:
- name: config
configMap:
name: hubble-flow-metrics-config
- name: hubble-export
hostPath:
path: /var/run/cilium/hubble
type: DirectoryOrCreate
---
apiVersion: v1
kind: Service
metadata:
name: hubble-flow-metrics
namespace: observability
labels:
app: hubble-flow-metrics
spec:
selector:
app: hubble-flow-metrics
ports:
- name: prom
port: 9598
targetPort: promVector에선 Vector Remap Language(VRL)이라는 DSL이 사용되는데, Cardinality-Safe한 정규화 기능을 구현하기 위함이다. 이제 /posts/30과 같이 ID가 포함되어있을 경우 /posts/{id}로 정규화된다.
다만 위 코드는 필자가 대충 작성해온 PoC 정도의 코드이고, 프로덕션 환경에선 더욱 더 개선하여 사용하길 바란다.
# hubble-flow-metrics-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: hubble-flow-metrics
namespace: observability
labels:
release: kube-prometheus-stack
spec:
selector:
matchLabels:
app: hubble-flow-metrics
namespaceSelector:
matchNames:
- observability
endpoints:
- port: prom
interval: 15s마지막으로 Prometheus가 Vector Exporter를 수집하도록 ServiceMonitor를 구성한다.
kubectl apply -f hubble-flow-metrics.yaml
kubectl apply -f hubble-flow-metrics-servicemonitor.yamlDemo Application
# app.yaml
apiVersion: v1
kind: Namespace
metadata:
name: poc
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: poc-app
namespace: poc
spec:
replicas: 2
selector:
matchLabels:
app: poc-app
template:
metadata:
labels:
app: poc-app
spec:
containers:
- name: httpbin
image: kennethreitz/httpbin
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: poc-app
namespace: poc
spec:
selector:
app: poc-app
ports:
- name: http
port: 8080
targetPort: 80필자는 예시로 kennethreitz/httpbin 이미지를 사용했는데, /anything/* 요청에 대해 200을 응답하니 추후 테스트시 참고하길 바란다.
CiliumNetworkPolicy L7 Visibility
Cilium에서 기본적으로 아무런 Network Policy가 없다면 L7 Envoy Proxy가 붙지 않는다. 때문에 Allow All L7 Policy(CiliumNetworkPolicy CRD)를 줘서 Envoy Proxy를 경유하도록 하는 목적이다.
# cnp-l7-visibility.yaml
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: l7-visibility
namespace: poc
spec:
endpointSelector:
matchLabels:
app: poc-app
ingress:
- fromEndpoints:
- {}
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: ".*"
path: "/.*"Testing
여기까지 문제 없이 적용되었다면 아래의 명령어로 Cilium CNI Chaining이 잘 되었는지 등을 확인해보자.
kubectl -n kube-system exec ds/cilium -- cilium status | grep "CNI Chaining"
kubectl -n kube-system exec ds/cilium -- cat /host/etc/cni/net.d/05-cilium.conflist전자는 Chaining 모드 확인, 후자는 CNI Plugin 구성 확인이다.
CNI Chaining: aws-cni{
"cniVersion": "0.4.0",
"name": "aws-cni",
"disableCheck": true,
"plugins": [
{
"name": "aws-cni",
"type": "aws-cni",
"vethPrefix": "eni",
"mtu": "9001",
"podSGEnforcingMode": "strict",
"pluginLogFile": "/var/log/aws-routed-eni/plugin.log",
"pluginLogLevel": "DEBUG",
"capabilities": {
"io.kubernetes.cri.pod-annotations": true
}
},
{
"name": "egress-cni",
"type": "egress-cni",
"mtu": "9001",
"enabled": "false",
"randomizeSNAT": "prng",
"nodeIP": "",
"ipam": {
"type": "host-local",
"ranges": [
[
{
"subnet": "fd00::ac:00/118"
}
]
],
"routes": [
{
"dst": "::/0"
}
],
"dataDir": "/run/cni/v4pd/egress-v6-ipam"
},
"pluginLogFile": "/var/log/aws-routed-eni/egress-v6-plugin.log",
"pluginLogLevel": "DEBUG"
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
},
"snat": true
},
{
"type": "cilium-cni",
"chaining-mode": "aws-cni",
"enable-debug": false,
"log-file": "/var/run/cilium/cilium-cni.log"
}
]
}위와 같이 구성이 되었다면 잘 Chaining된 것이다. 이제 Envoy L7과 Hubble Flow Export가 동작하는지 아래의 명령어로 확인해보자.
> kubectl -n kube-system exec ds/cilium -- ls -l /var/run/cilium/hubble/events.log
> kubectl -n kube-system exec ds/cilium -- tail -n 5 /var/run/cilium/hubble/events.log
-rw-r--r--. 1 root root 1294404 Mar 26 02:35 /var/run/cilium/hubble/events.log
{"flow":{"time":"2026-03-26T02:35:29.114383229Z","uuid":"56dced30-2f83-4c15-9370-cd7ab1e1e048","emitter":{"name":"Hubble","version":"1.19.2+g3977f6a1"},"verdict":"FORWARDED","ethernet":{"source":"1a:82:0b:a0:bd:95","destination":"c6:4e:da:5e:31:bb"},"IP":{"source":"192.168.85.176","destination":"192.168.95.3","ipVersion":"IPv4"},"l4":{"TCP":{"source_port":41012,"destination_port":8181,"flags":{"ACK":true}}},"source":{"identity":1,"labels":["reserved:host"]},"destination":{"ID":2570,"identity":54686,"cluster_name":"default","namespace":"kube-system","labels":["k8s:eks.amazonaws.com/component=coredns","k8s:io.cilium.k8s.namespace.labels.kubernetes.io/metadata.name=kube-system","k8s:io.cilium.k8s.policy.cluster=default","k8s:io.cilium.k8s.policy.serviceaccount=coredns","k8s:io.kubernetes.pod.namespace=kube-system","k8s:k8s-app=kube-dns"],"pod_name":"coredns-69b5896d49-9zh67","workloads":[{"name":"coredns","kind":"Deployment"}]},"Type":"L3_L4","node_name":"ip-192-168-85-176.ap-northeast-2.compute.internal","node_labels":["alpha.eksctl.io/cluster-name=cilium-poc","alpha.eksctl.io/nodegroup-name=ng-poc","beta.kubernetes.io/arch=amd64","beta.kubernetes.io/instance-type=t3.medium","beta.kubernetes.io/os=linux","eks.amazonaws.com/capacityType=ON_DEMAND","eks.amazonaws.com/nodegroup-image=ami-013c8233b9e7c0812","eks.amazonaws.com/nodegroup=ng-poc","eks.amazonaws.com/sourceLaunchTemplateId=lt-0bc224f77a464550b","eks.amazonaws.com/sourceLaunchTemplateVersion=1","failure-domain.beta.kubernetes.io/region=ap-northeast-2","failure-domain.beta.kubernetes.io/zone=ap-northeast-2c","k8s.io/cloud-provider-aws=529fc8a9de23b77095f82c3f10b3de38","kubernetes.io/arch=amd64","kubernetes.io/hostname=ip-192-168-85-176.ap-northeast-2.compute.internal","kubernetes.io/os=linux","node.kubernetes.io/instance-type=t3.medium","topology.k8s.aws/zone-id=apne2-az3","topology.kubernetes.io/region=ap-northeast-2","topology.kubernetes.io/zone=ap-northeast-2c"],"event_type":{"type":4},"traffic_direction":"EGRESS","trace_observation_point":"TO_ENDPOINT","trace_reason":"ESTABLISHED","is_reply":false,"interface":{"index":15,"name":"eni3e06f27d75b"},"Summary":"TCP Flags: ACK"},"node_name":"ip-192-168-85-176.ap-northeast-2.compute.internal","time":"2026-03-26T02:35:29.114383229Z"}
... (생략)
> kubectl -n kube-system exec ds/cilium -- cilium status | sed -n '1,120p' | grep 'redirect'
Proxy Status: OK, ip 10.0.0.4, 2 redirects active on ports 10000-20000, Envoy: external위와 같이 Hubble Export가 잘 찍히면 Envoy Proxy 및 Hubble Exporter가 동작중이라는 것을 확인해볼 수 있다.
이제 트래픽을 보내보는데, Path 정규화가 동작하는지 확인을 위해 아래와 같이 카디널리티가 존재하는 경로로 테스트해본다.
kubectl -n poc run curl --image=curlimages/curl:8.5.0 -it --rm -- \
curl -s http://poc-app.poc.svc.cluster.local:8080/anything/users/30
kubectl -n poc run curl --image=curlimages/curl:8.5.0 -it --rm -- \
curl -s http://poc-app.poc.svc.cluster.local:8080/anything/users/31이후 Prometheus Dashboard로 접속하여 PromQL을 통해 질의해보겠다.
# 일부 환경에 따라 다를 수 있음.
kubectl -n monitoring port-forward svc/kube-prometheus-stack-prometheus 9090:9090아래의 PromQL은 응답 코드가 0이 아닌 경우 정규화된 Path, Method 및응답 코드가 집계된다.
네트워크 문제가 있을 경우 응답 코드에 0이 찍힐 수 있다.
sum(l7_http_requests_total{status_class!="0"}) by (path, method, status_class)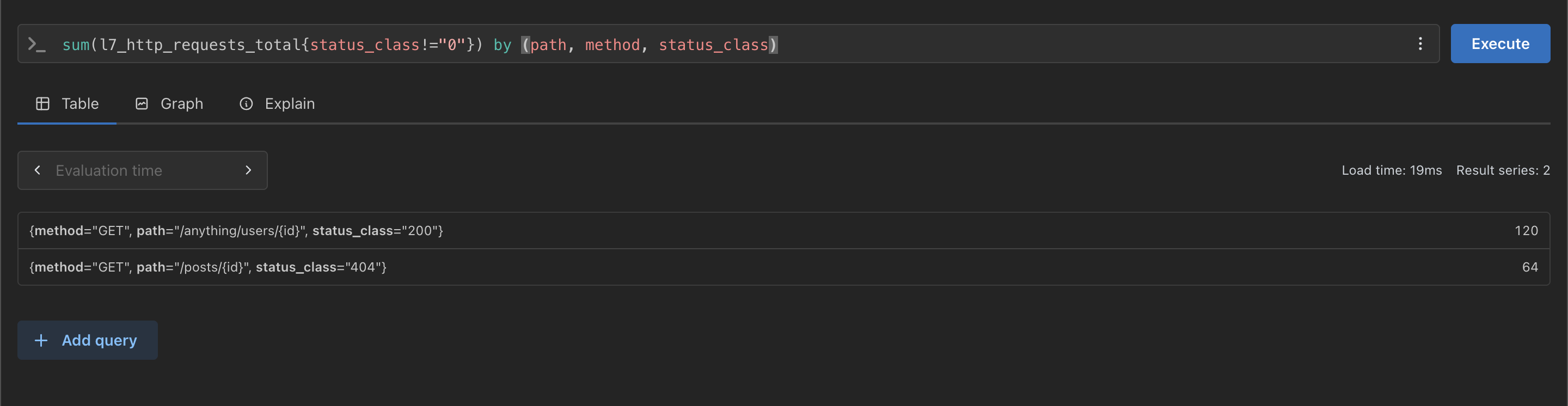
이 외에도 아래와 같은 PromQL을 작성하고 활용해볼 수 있을 것이다. 이 포스팅에선 Grafana까지 연동하여 실습하는 과정은 생략하겠다.
누적 접근 횟수
sum(l7_http_requests_total) by (path)응답 코드별 누적
sum(l7_http_requests_total) by (path, status_class)최근 5분 증가량
sum(increase(l7_http_requests_total[5m])) by (path, method, status_class)rate, 트래픽 지속 발생 시
sum(rate(l7_http_requests_total[1m])) by (path, method, status_class)status_class=0 제외 (응답 완료 기준)
sum(increase(l7_http_requests_total{status_class!="0"}[5m])) by (path, method)이상으로 eBPF 기반의 Cilium CNI 및 VPC CNI를 Chaining하고 Envoy 및 Hubble/Vector를 통해 Observability까지 구성해보았다.
Cilium은 이 외에도 다양한 eBPF 기반의 기능들이 있고, Cilium Network Policy Enforcement Engine 또한 매우 강력한 기능이기 때문에 클라우드 네이티브를 생각하고 있다면 Cilium CNI를 도입해보는 것은 좋은 선택일 것이다.
