0. Overview
EKS 클러스터를 아래와 같이 구성하고 프로비저닝하였다. (eksctl)
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: eks-demo
region: ap-northeast-2
version: "1.33"
vpc:
cidr: 10.1.0.0/16
nat:
gateway: Single
managedNodeGroups:
- name: ng-1
instanceType: t2.micro
desiredCapacity: 1
privateNetworking: false
iam:
withAddonPolicies:
ebs: true예전에 만들고 클러스터만 생성해보고 바로 종료했던지라 문제를 알 수 없었으나, 최근에 이것저것 해보면서 문제가 발견되었다.
Istio Operator를 설치하는데 이상하게 오래걸려 모든 파드를 조회해보니 CoreDNS 파드가 Pending 상태인 것을 확인할 수 있었다.
> kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
istio-system istiod-6f88b778cf-p6rw2 0/1 Pending 0 3m28s
kube-system aws-node-s7ffb 2/2 Running 0 5m4s
kube-system coredns-c844dd74d-82czn 0/1 Pending 0 8m31s
kube-system coredns-c844dd74d-n7pm4 0/1 Pending 0 8m31s
kube-system kube-proxy-gjld8 1/1 Running 0 5m4s
kube-system metrics-server-67b599888d-646ng 1/1 Running 0 8m33s
kube-system metrics-server-67b599888d-zldc8 1/1 Running 0 8m33s뜬금없이 CoreDNS가 동작을 안하는 것이 이상해서 describe로 상세한 상태를 확인해보니 아래와 같은 에러 메시지가 나타났다.
> kubectl describe -n kube-system pod/coredns-c844dd74d-82czn
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 8m56s default-scheduler no nodes available to schedule pods
Warning FailedScheduling 8m51s (x2 over 8m54s) default-scheduler no nodes available to schedule pods
Warning FailedScheduling 5m11s default-scheduler 0/1 nodes are available: 1 Too many pods. preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod.FailedScheduling, Too many pods. 라고 한다.
1. Too many pods ?
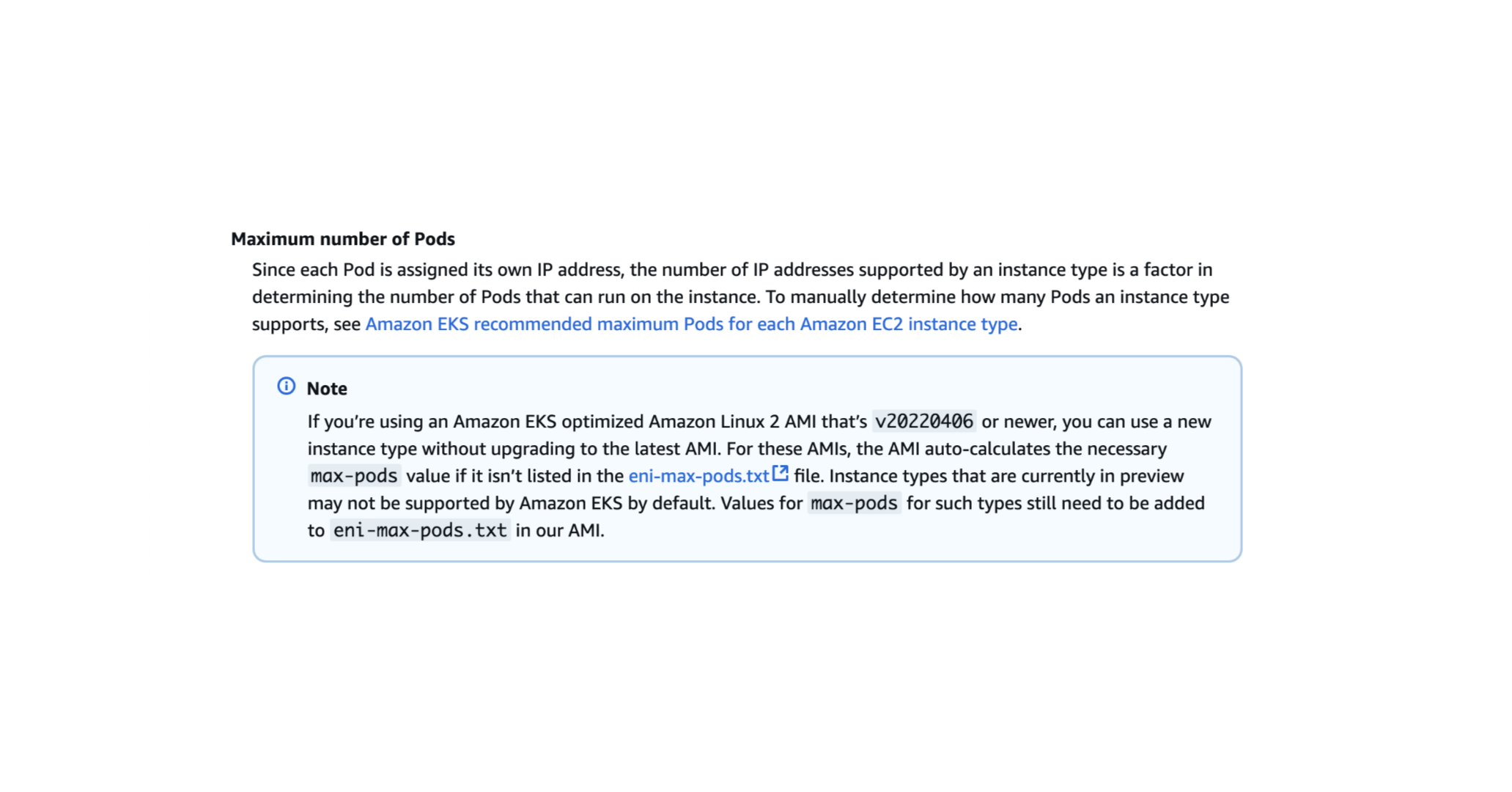
찾아보니 AWS EKS 공식 문서에 관련 내용이 있었다.
https://docs.aws.amazon.com/eks/latest/userguide/choosing-instance-type.html

EC2 노드 인스턴스 타입 별로 스케줄링이 가능한 파드의 수가 정해져 있는 것이다.
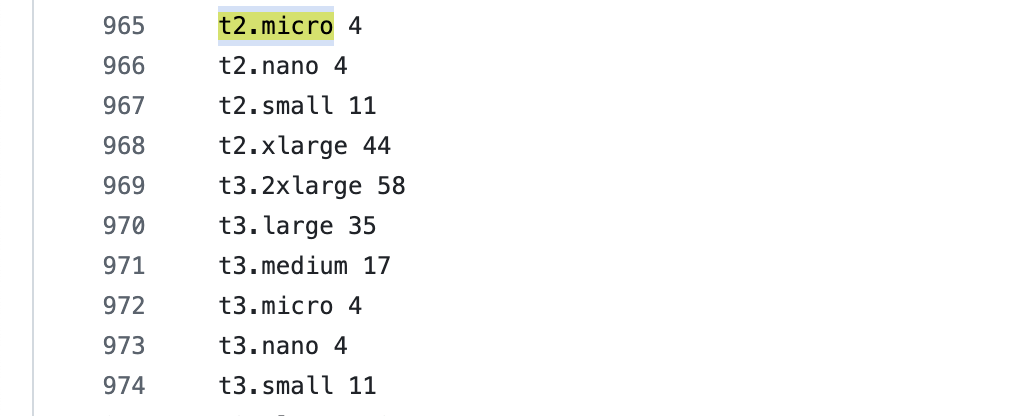
eni-max-pods.txt 내용에 따르면 t2.micro의 스케줄링 가능한 최대 파드 수는 4개라고 한다.
이유는 인스턴스 타입 별로 붙을 수 있는 ENI 수의 제한이 있고, 파드 또한 ENI에 연결되어 프라이빗 IP를 가지기 때문이다.
아래의 명령어를 통해 그 제한을 확인해보자.
> aws ec2 describe-instance-types \
--filters "Name=instance-type,Values=t3.medium" \
--query "InstanceTypes[].{ \
Type: InstanceType, \
MaxENI: NetworkInfo.MaximumNetworkInterfaces, \
IPv4addr: NetworkInfo.Ipv4AddressesPerInterface}" \
--output table
-------------------------------------
| DescribeInstanceTypes |
+----------+----------+-------------+
| IPv4addr | MaxENI | Type |
+----------+----------+-------------+
| 6 | 3 | t3.medium |
+----------+----------+-------------+MaximumNetworkInterfaces는 해당 인스턴스에 붙을 수 있는 ENI의 개수 제한, 그리고 Ipv4AddressesPerInterface는 그 ENI 별로 할당 가능한 IP 제한을 나타낸다.
이 중 IP 하나는 노드의 IP, 그리고 추가적으로 2개의 여유분을 주며 ENI 별로 Primary IP 하나는 파드에 할당 할 수 없기 때문에 아래와 같이 계산할 수 있다.
maxPods = (NumberOfENI * (IPv4AddrPerENI - 1)) + 2예시로 t3.medium의 최대 파드는 3 * (6 - 1) + 2 = 17로 계산될 수 있다.
2. Troubleshooting
해결 방법은 간단하다.
- 노드의 수(desiredCapacity)를 늘린다. (자동으로 적절하게 스케줄링 됨)
- 높은 성능의 인스턴스 타입을 사용한다.
두 방법 모두 비용적인 요소를 고려하거나 Cluster AutoScaling 등을 통해 오토스케일링 하는 등의 솔루션이 필요할 듯 하다.
필자는 간단하게 테스트 용도로 t3.medium을 하나만 프로비저닝 하도록 수정하였다.
managedNodeGroups:
- name: ng-1
instanceType: t3.medium