0. Overview
인프라를 운영하면서 주기적으로 성능을 관찰하거나 다양한 문제에 직면하여 대응하기 위해 모니터링(Monitoring) 한다.
예를 들어 kubectl top nodes와 같은 경우에도 노드에 대한 메트릭(시간에 따라 측정되어 변화되는 데이터)을 확인할 수 있기 때문에 모니터링에 포함된다.
> kubectl top nodes
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
minikube 308m 3% 743Mi 18%0-1. Monitoring vs Observability
그런데 이러한 성능 메트릭만 확인하기엔 몇가지 문제가 있을 수 있다.
먼저 근본적으로 모니터링 도구는 상태(메트릭)만 제공하기 때문에, 만약 갑자기 CPU 사용률이 급등하거나 응답 속도가 느려졌으나 "왜" 그런지는 이러한 모니터링 도구로만 확인하기엔 어려움이 있다.
known unknowns, 즉 무슨 문제인지 알려져 있으나(known) 그 문제의 원인이나 이유를 알 수 없다. (unknowns)
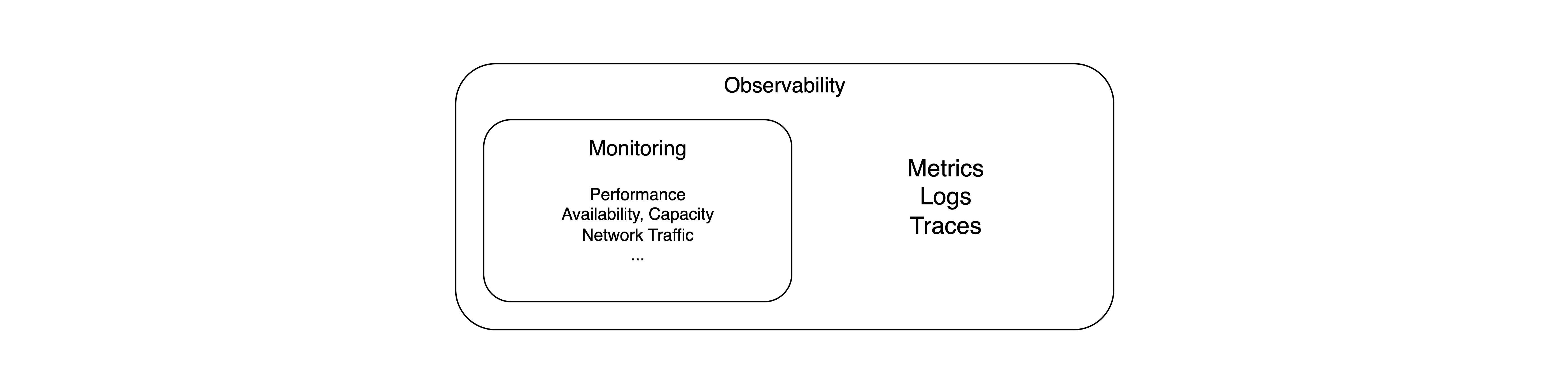
반면 Observability(관찰 가능성)은 모니터링을 포함하여 발견된 문제의 원인이나 이유를 파악하고 추론할 수 있으며, 즉 모니터링은 What과 When에 중점을 둔다면 Observability는 Why와 How에 중점을 두는 상위 개념이라 볼 수 있다.
0-2. Observability — Metrics, Logs, Traces
이러한 Observability엔 아래와 같은 3가지 요소가 포함된다.
- Metrics — 성능 지표와 같이 시간에 따라 측정되어 변화되는 데이터, 즉 메트릭을 의미함. Observability의 하위 개념인 모니터링이 주로 이에 해당됨. 대표적으로 이번 포스트의 주제인 Prometheus가 있음.
- Logs — 애플리케이션에서 발생한 이벤트 기록을 통해 원인을 분석하고 추적하며 이러한 로그를 중앙 집중화함. Fluent Bit나 Loki 등이 이에 해당됨.
- Traces — 애플리케이션의 Stack Trace처럼 인프라에서도 여러 서비스를 거치게 되는데, 이러한 특정 지점까지 도달하기 까지의 경로를 관찰하고 분석함. OpenTelemetry에 포함되기도 하고 Tempo와 같은 소프트웨어도 존재함.
0-3. Why Observability is Needed in Cloud Native?
과거의 모놀로식 아키텍처와 달리 현대의 서비스는 대개 클라우드 네이티브와 MSA 구조의 대중화로 수많은 마이크로 서비스와 수백~수천개의 컨테이너, 그리고 쿠버네티스 리소스나 클라우드 서비스가 서로 상호작용하여 최종적인 서비스로 동작한다.
이렇게 복잡해진 구조로 인해 단순히 CPU/메모리 사용률이나 네트워크 트래픽을 모니터링하는 것만으로는 인프라를 운영하면서 문제를 대응하기가 어려워졌고, 그러한 문제의 원인을 파악하기 위해 Observability(관찰 가능성)을 필요로 하게 된다.
1. Prometheus
Prometheus(프로메테우스)는 Observability의 Metrics를 중점으로 다루며, Pull Based로 노드나 애플리케이션에서 제공하는 /metrics 엔드포인트 등을 통해 메트릭(데이터)을 직접 Pull하여 수집하는 모니터링 도구이다.
쿠버네티스를 관리하는 CNCF(Cloud Native Computing Foundation)에서 관리하는 프로젝트 중 하나이며, Prometheus를 클라우드에서 완전 관리형으로 제공되는 AWS AMP(Amazon Managed Service for Prometheus)나 GCP에서 제공되는 완전 관리형 Prometheus 등이 있다.
메트릭을 수집하여 모니터링하는 것 외에도 Alerting Rule을 설정하여 웹훅이나 이메일, 또는 슬랙과 같은 메신저로 알림을 보내는 Alert Manager, 그리고 Cron Job 등의 일회성 작업이나 배치 작업, 또는 Pull로 메트릭을 직접 수집하기 어려운 경우 Pushgateway로 메트릭을 Push하고 Pushgateway를 Pull하여 메트릭을 수집할 있는 Pushgateway를 지원한다.
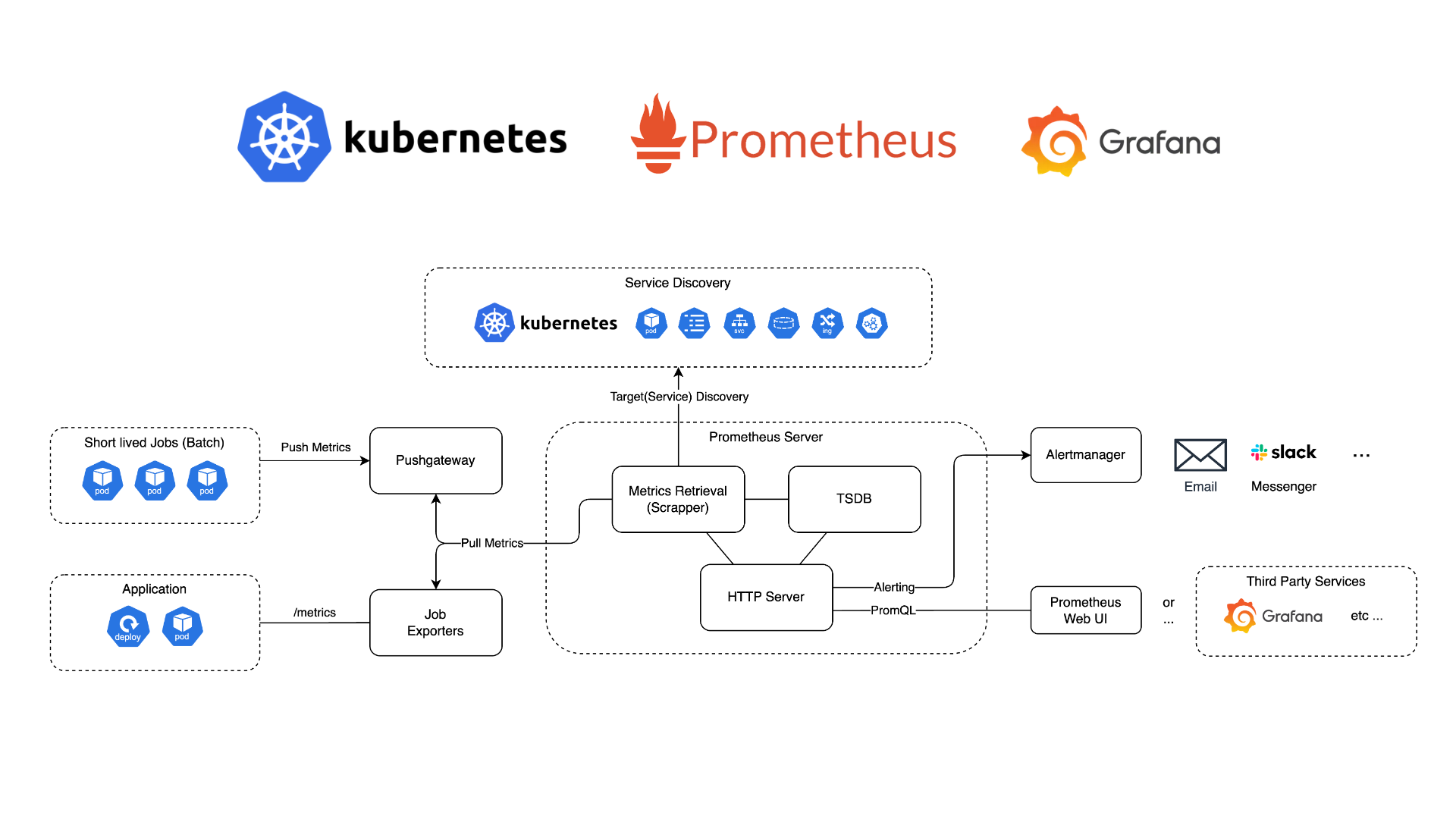
쿠버네티스에서 사용을 기준으로 한다면 Prometheus 아키텍처는 아래와 같다.
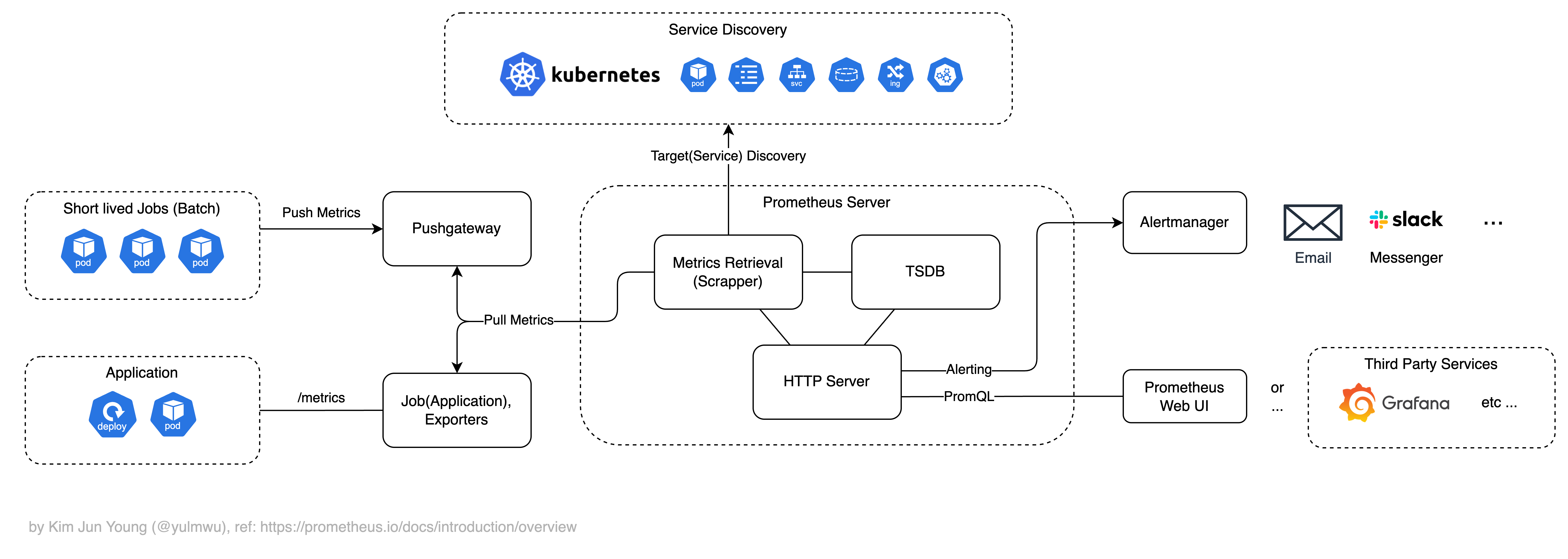
1-1. Service Discovery(SD)
쿠버네티스는 파드와 같이 Ephemeral(임시적) 리소스가 많기 때문에, Observability을 유지하기 위해선 이러한 리소스를 자동으로 디스커버리하고 감지할 수 있어야 한다.
Prometheus는 메트릭을 수집할, 디스커버리 될 대상을 아래와 같은 요소로 구성할 수 있다.
- File based SD — 지정된 JSON이나 YAML을 통해 대상을 주기적으로 업데이트함. 서비스 변경 사항을 파일로 관리할 수 있음.
- DNS SD — DNS SRV 쿼리를 통해 서비스의 엔드포인트를 찾고 업데이트함.
- Cloud Provider SD — AWS EC2, GCP 등의 클라우드에서 제공하는 API를 통해 인스턴스나 서비스를 찾고 대상을 업데이트함.
- Kubernetes SD — 쿠버네티스 환경에서 Operator를 통해 오브젝트나 서비스의 변화를 자동으로 감지하고 대상을 업데이트함.
- 그 외... (Consul, Eureka 등등)
만약 쿠버네티스 환경에서 Prometheus를 운영할 경우 Operator를 통해 유연하게 서비스를 디스커버리 할 수 있기 때문에 추후 예제에서도 Prometheus Operator를 설치하여 실습해보도록 하겠다.
1-2. Prometheus Server
Prometheus의 HTTP 서버로, 주요 기능은 구성된 스크랩 대상으로 부터 메트릭을 Pull 하고, 수집된 메트릭을 TSDB(Time Series Database)에 저장한다.
또한 조건에 따라 알림을 만들어 이메일이나 메신저, 웹훅 등을 호출할 수 있고(Alertmanager), HTTP API나 자체적인 웹 UI를 제공, 후술할 PromQL을 제공하여 Grafana와 같은 시각화 서비스와 연동할 수 있다.
쿠버네티스에선 Helm 등을 통해 Prometheus Server 및 Operator를 설치할 수 있다.
1-3. Targets — Exporter
서비스 디스커버리의 대상, 즉 메트릭을 수집(스크랩, Pull)할 대상은 크게 /metrics 엔드포인트를 제공하는 애플리케이션이나 Exporter, 그리고 Pushgateway가 있다.
/metrics 엔드포인트는 Prometheus에서 제공하는 언어 별 라이브러리/패키지 등으로 구현할 수 있고, Pushgateway와 함께 다음 차례에서 다뤄보겠다.
1-3-1. OpenMetrics
Prometheus는 메트릭 엔드포인트(
/metrics등, 커스텀 가능)를 통해 Pull하여 메트릭을 수집하도록 하는데, 이때 메트릭들을 아래와 같은 텍스트 기반의 포맷으로 구성한다.# HELP http_requests_total The total number of HTTP requests. # TYPE http_requests_total counter http_requests_total{method="post",code="200"} 1027 http_requests_total{method="post",code="400"} 3 # HELP cpu_usage System CPU usage > in percent. # TYPE cpu_usage gauge cpu_usage 72.5Prometheus는 처음엔 이러한 독자적인 포맷인 Prometheus Exposition Format을 사용하도록 하였는데, 여기에 네이밍 규칙 표준화, 추가적인 기능과
application/openmetrics-textMIME 타입 추가 등의 표준화된 포맷인 OpenMetrics를 만들고 표준으로 사용하게 되었다.
Exporter는 애플리케이션이나 시스템이 직접 Prometheus Exposition Format(이하 PEF)이나 OpenMetrics 포맷의 metrics 엔드포인트(/metrics 등)를 노출하지 못하는 경우, Exporter를 중간에 두어 Exporter가 메트릭을 수집, 그리고 OpenMetrics(이하 PEF 포함) 포맷의 엔드포인트를 노출하여 Prometheus가 Pull 할 수 있도록 한다.
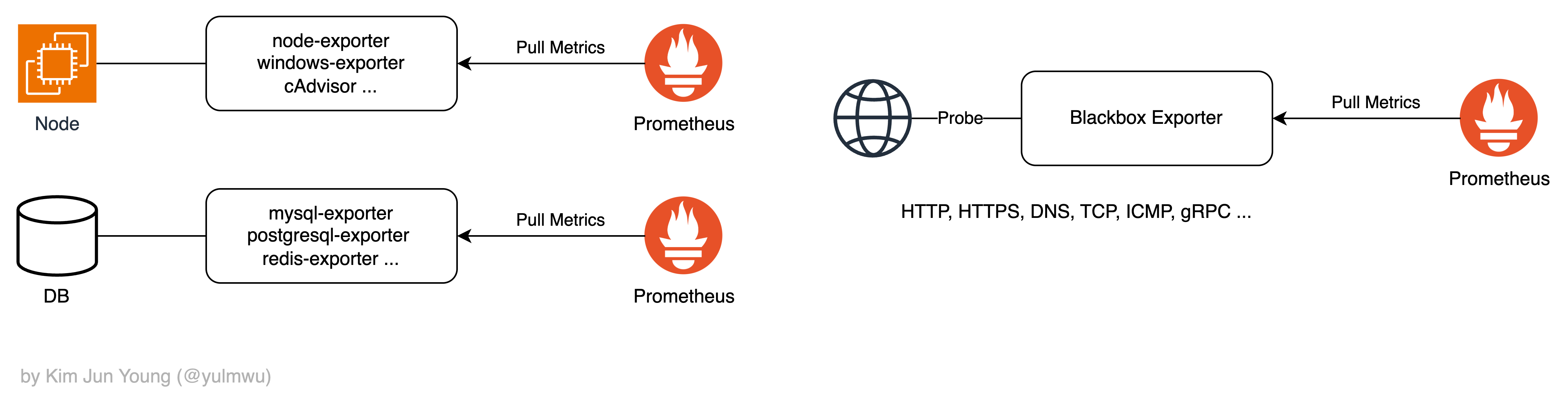
그러한 Exporter는 대상에 따라 대표적으로 노드의 메트릭을 수집하는 node-exporter(Linux/Unix 환경), windows-exporter(Windows 환경), cAdvisor(컨테이너), 그리고 DB의 메트릭을 수집하는 Exporter와 외부의 관점에서 가용성을 체크하기 위한 Blackbox Exporter 등이 있다.
예시의 노드나 DB 처럼 OpenMetrics 포맷의 엔드포인트를 노출하지 못하는 경우 Exporter를 통해 메트릭을 대신 수집하고 Exporter를 대상으로 Pull 하여 메트릭을 수집할 수 있다.
1-4. Targets — Pushgateway
Prometheus는 기본적으로 수집할 대상에 Pull을 통해 메트릭을 수집하도록 하는데 (Pull 모델), 짧게 실행되는 배치 작업이나 지속되지 않는 CronJob 등의 경우 Pull 모델을 사용하기가 어려울 수 있다.
예를 들어 어떠한 CronJob이 30초 동안만 실행되고 종료되는데, 만약 scrape_interval=30s로 설정한다면 스크랩 시 파드가 이미 종료되기 때문에 Pull을 하기가 어려울 수 있다.
이때 Pushgateway를 두고 대상(예시: CronJob)이 자신의 메트릭을 Pushgateway로 Push 한다면, Pushgateway는 메트릭을 임시로 보관하고 이후 Prometheus가 Pushgateway를 Pull 하여 메트릭을 수집하도록 한다.
때문에 많은 데이터가 짧은 시간에 처리되는 배치성 작업에도 유리할 수 있다.
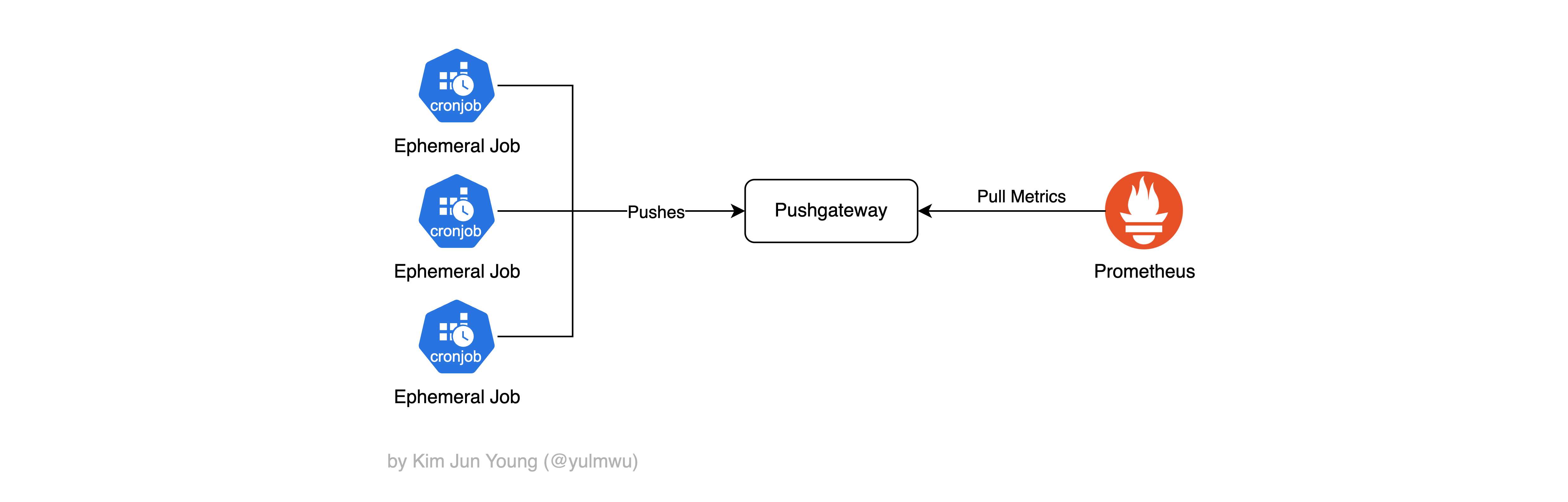
다만 Prometheus의 철학은 일정한 간격을 두고 대상을 Pull 하여 스크랩(수집)하는 Pull 모델이기 때문에 Pushgateway의 용도를 확실하게 하지 않고 남발할 경우 가용성 확인/유효성 관리의 어려움, 중복된 메트릭 등의 문제가 생길 수 있으니 Pushgateway는 임시적인(Ephemeral) 프로세스에 대한 예외적인 기능이라 생각하는 것이 좋다.
1-5. Targets — Prometheus Client Libraries (/metrics Endpoint)
마지막으로 애플리케이션에서 직접 OpenMetrics 포맷을 응답하는 /metrics 등의 엔드포인트를 직접 구현하고 Prometheus ServiceMonitor나 PodMonitor에 등록할 수 있다.
이때 OpenMetrics 포맷에 맞게 직접 구현해도 되지만 이에 대한 클라이언트 라이브러리를 지원한다.
자세한 공식 및 비공식 써드파티 라이브러리는 https://prometheus.io/docs/instrumenting/clientlibs 이곳을 참고하자.
추후 직접 실습해보도록 하겠다.
1-6. Alertmanager
Prometheus에선 Alertmanager를 통해 사용자가 지정한 조건, Alerting Rule을 구성하여 특정한 조건을 만족한다면 이메일이나 슬랙과 같은 메신저, 웹훅 등을 호출하여 알림을 보낼 수 있다.
정확하게 말하면 Prometheus의 Alerting Pipeline을 구성하는 요소로, Prometheus가 생성한 알림을 받아 집계, 필터링, 라우팅하는 역할이다.
중복된 알림을 제거하도록 하는 Deduplication, 같은 유형의 알림을 묶는 Grouping, 알림을 특정 대상(리시버)으로 전달하는 Routing 등의 기능이 있다.
이때 구성한 조건(Alerting Rule)은 일정 시간마다 평가하여 알림을 보내는데, 이를 Rule Evaluation이라고 한다.
추가적으로 자주 사용하는 PromQL을 미리 계산해서 별도의 Time Series 데이터로 저장하는 Recording Rule 또한 이때 평가된다.
1-7. PromQL
Prometheus는 메트릭을 저장할 때 TSDB에 저장하는데, 이때 TSDB의 데이터를 집계(Aggregate)하고 시각화하는 쿼리 언어가 PromQL이다.
Prometheus Web UI나 추후 다뤄볼 Grafana, 그리고 Alerting Rule 또한 모든 쿼리는 PromQL로 작성된다.
node_cpu_seconds_total{mode="idle"}1-7-1. Vector, Scalar Types
PromQL엔 크게 아래와 같은 데이터 타입이 존재한다.
- Instant Vector — 특정 시점(타임스템프)의 메트릭을 반환함
- Range Vector — 특정한 구간의 시점의 메트릭을 반환함
- Scalar — 단일 숫자(Float) 또는 문자열 등
예를 들어 Instant Vector는 아래와 같이 현재 시점의 모든 노드의 CPU 사용률을 가져오는 PromQL을 작성할 수 있다.
node_cpu_seconds_total{mode="user"}metric: node_cpu_seconds_total{cpu="0", instance="node1", job="node-exporter", mode="user"}
value: 25340.23
metric: node_cpu_seconds_total{cpu="1", instance="node1", job="node-exporter", mode="user"}
value: 26212.17
...다음으로 Range Vector는 Instant Vector 뒤에 셀렉터 []를 붙여 해당 범위 내의 데이터를 가져온다.
rate(node_cpu_seconds_total{mode="user"}[5m]) # 최근 5분간 CPU 사용률 증가량 계산이때 rate를 통해 초당 평균 증가율을 계산하고, 아래와 같은 결과를 얻을 수 있다.
metric: node_cpu_seconds_total{cpu="0", instance="node1", job="node-exporter", mode="user"}
value: 0.32
metric: node_cpu_seconds_total{cpu="1", instance="node1", job="node-exporter", mode="user"}
value: 0.28
...그리고 라벨(예제의 cpu, instance 등)은 아래와 같은 라벨 셀렉터를 통해 필터링 할 수 있다.
=— 정확한 일치,job="api"!=— 일치하지 않을 경우,job!="db"=~— 정규식 일치,job=~"dev.*"!~— 정규식이 일치하지 않을 경우,job!~"prod.*"
http_requests_total{method="GET", handler!="/metrics", job=~"api|web"}PromQL에 대한 문법은 본 포스팅에서 자세히 다루지 않을 예정이다.
1-7-2. Vector Functions
자세히 다루지는 않겠으나 몇가지 주요한 함수를 소개하겠다. 대부분의 함수는 Range Vector 타입에서 사용된다.
rate()— 해당 범위 내에서의 초당 평균 증가율을 구함.increase()— 범위 내에서의 총 증가량을 구함.avg_over_time()— 해당 구간의 평균을 구함.max_over_time()— 해당 구간의 최대값을 구함.min_over_time()— 해당 구간의 최소값을 구함.
예를 들어 아래와 같은 PromQL이 있다면
increase(http_requests_total{job="backend"}[1h])위 PromQL은 job 라벨이 backend인 메트릭 최근 1시간 동안 총 몇 개의 요청이 발생했는가를 나타낸다.
1-7-3. Aggregation & Grouping
추가적으로 PromQL은 백터 간 집계를 수행할 수 도 있는데, 즉 여러 메트릭을 하나의 값으로 합산하거나 평균을 낼 수 있다.
sum(rate(http_requests_total[5m]))위와 같은 PromQL은 최근 5분간 발생하였던 초당 HTTP 요청 수의 총합을 구한다.
또한 by 키워드를 통해 그룹화를 할 수 도 있는데, by나 without(특정 라벨을 제외하고 그룹화) 키워드를 통해 그룹화를 할 수 있다.
sum(rate(http_requests_total[5m])) by (job, method)즉 위 PromQL은 job과 method 조합별 요청 수를 나타낸다.
avg(rate(container_cpu_usage_seconds_total{image!=""}[5m])) by (namespace)마지막으로 위와 같은 PromQL은 namespace 별 컨테이너 CPU 사용량의 평균을 계산하는데, 이때 이미지가 없는 컨테이너(image!="")는 제외한다.
2. Grafana
Prometheus가 메트릭을 수집한다면, 이러한 메트릭을 시각화하고 쿼리 기반으로 Dashboards와 Alerts를 구성하는 도구 중 하나가 바로 Grafana이다. (사실상 Prometheus + Grafana가 표준)
메트릭 수집 서비스로 Prometheus 뿐만 아니라 Loki, Tempo 등의 다양한 Observability 백엔드를 하나의 UI에서 시각화 할 수 있는 대시보드 도구이다.
Grafana는 크게 아래와 같은 요소로 구성된다.
- Data Source — 이름 그대로 Grafana가 데이터를 가져올 수 있는 백엔드를 의미한다. 앞서 설명했듯이 Prometheus 뿐만 아니라 Loki, Tempo 등의 Observability 백엔드를 연결할 수 있다.
- Dashboard — 여러 개의 패널로 구성된 메트릭 시각화가 가능한 UI로, Panel은 Time Series 값이나 단일 값(Gauge 등), 테이블, 차트 등의 패널로 구성할 수 있다.
- Alerts and Notification Channels — Prometheus의 Alertmanager와 별개로 자체적인 Alerting 엔진이 내장되어 있고, 이 또한 조건을 기반으로 알림을 트리거한다. 그래고 Notification Channel로 슬랙(메신저), 이메일, 웹훅 등으로 알림을 보낼 수 있다.
또한 PromQL Query Editor를 통해 복잡한 PromQL을 작성하고 시각화 할 수 있다. 이 포스팅에선 Prometheus에 대해 자세히 다루고, Grafana는 시각화 도구로써 실습해보도록 하겠다.
3. Examples
이제 Prometheus와 Grafana를 설치해보고 실습해보며, 마지막으로 Prometheus 클라이언트 라이브러리를 통해 직접 OpenMetrics 포맷의 /metrics 엔드포인트를 구현하도록 해보겠다.
3-1. Installing Prometheus Stack (kube-prometheus-stack via Helm)
쿠버네티스에서 Helm을 통해 Prometheus를 사용할 때 Grafana, Alertmanager 등을 같이 사용하는 경우가 많기 때문에 Prometheus Stack에 포함되어 Helm을 통해 설치할 수 있다.
먼저 monitoring 네임스페이스를 만들고 그 위에 Prometheus Stack을 설치해보도록 하겠다.
kubectl create namespace monitoring
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--set grafana.service.type=NodePort \
--set prometheus.service.type=NodePortPrometheus와 Grafana의 서비스는 NodePort로 설정하여 Prometheus Stack을 설치하도록 한다.

설치가 완료되었다면 아래의 명령어를 통해 Prometheus와 Grafana의 포트를 확인해보고 대시보드에 접속해보자.

필자는 minikube 환경을 사용하고 있기 때문에 아래와 같은 명령어로 터널링을 해주겠다.
minikube service kube-prometheus-stack-prometheus -n monitoring
minikube service kube-prometheus-stack-grafana -n monitoring
첫번째 화면은 Prometheus에서 자체적으로 제공하는 UI로, 간단하게 PromQL 쿼리를 테스트 해볼 수 있다. 아래의 Grafana를 통해 더욱 더 자세하게 시각화를 해보겠다.
그 전에 유저 이름과 비밀번호를 넣어야 하는데, 기본 유저 이름은 admin, 비밀번호는 아래의 명령어를 통해 확인할 수 있다.
kubectl get secret -n monitoring kube-prometheus-stack-grafana \
-o jsonpath="{.data.admin-password}" | base64 --decode; echo
# 예시: l2R9we0tbQwUZ1vPQd44blfciWVp3BuArc151Ylf3-2. Grafana Practice: Building Dashboards with PromQL
로그인을 완료하였다면 아래와 같이 시작 화면이 나타나는 것을 볼 수 있다.
원래라면 Connections > Data Sources에서 데이터 소스를 추가해야 하지만 Prometheus Stack을 설치하면서 기본적으로 Prometheus와 연동되기 때문에 따로 설정해줄 필요는 없다.
혹여나 Prometheus 데이터 소스가 없다면 추가하면 된다.
다음으로, 왼쪽 사이드바 메뉴에서 Dashboards를 클릭, New Dashboard를 클릭한다.

다음으로 Add Visualization, Prometheus 데이터 소스를 선택하면 대시보드에 패널을 추가할 수 있는 UI가 나타난다.
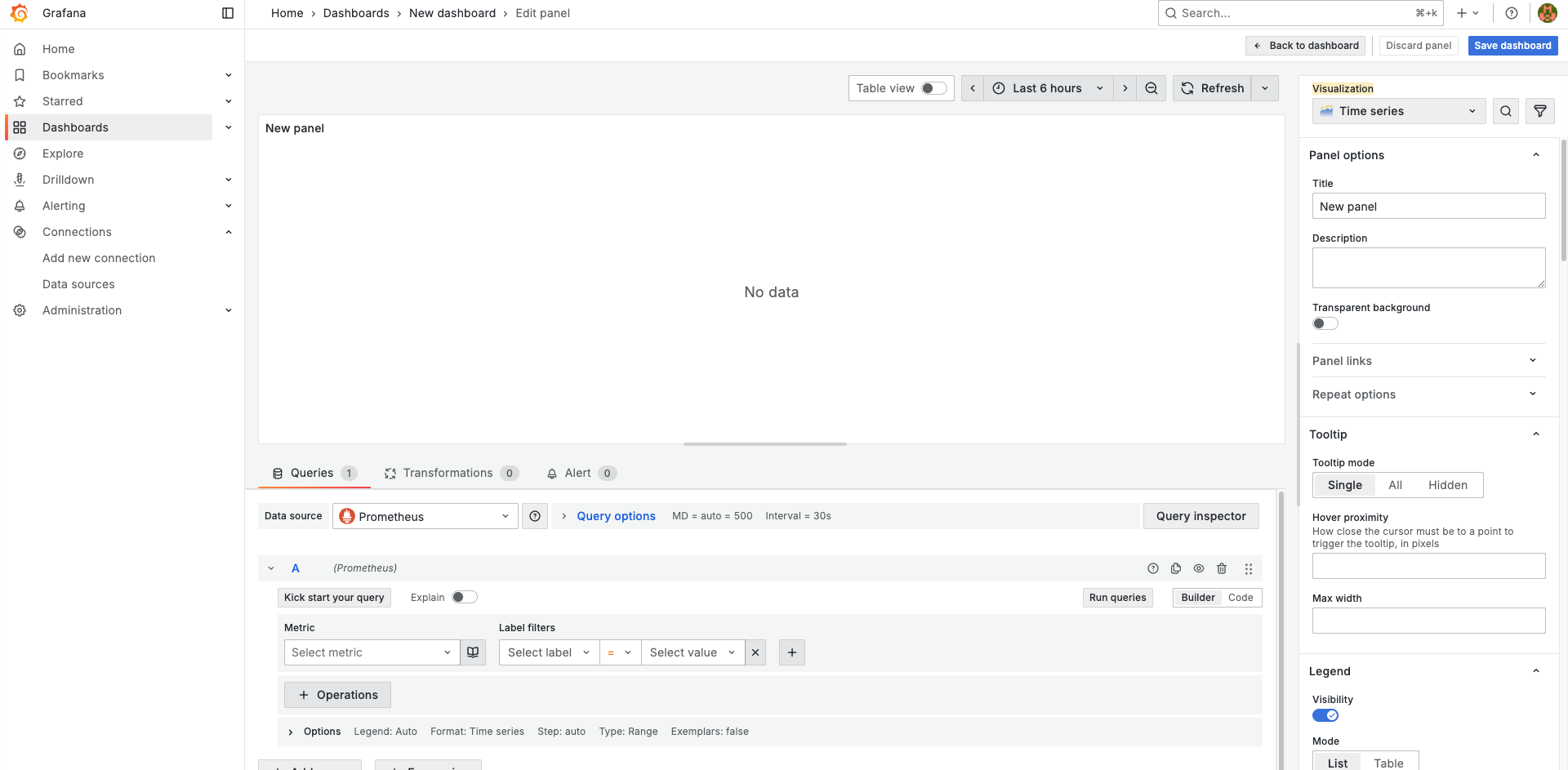
이제 하단의 Queries 탭에서 Builder가 아닌 Code를 선택하여 PromQL을 직접 작성하도록 한다.
그래고 아래의 PromQL을 추가하고 Run queries를 클릭해보자.
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)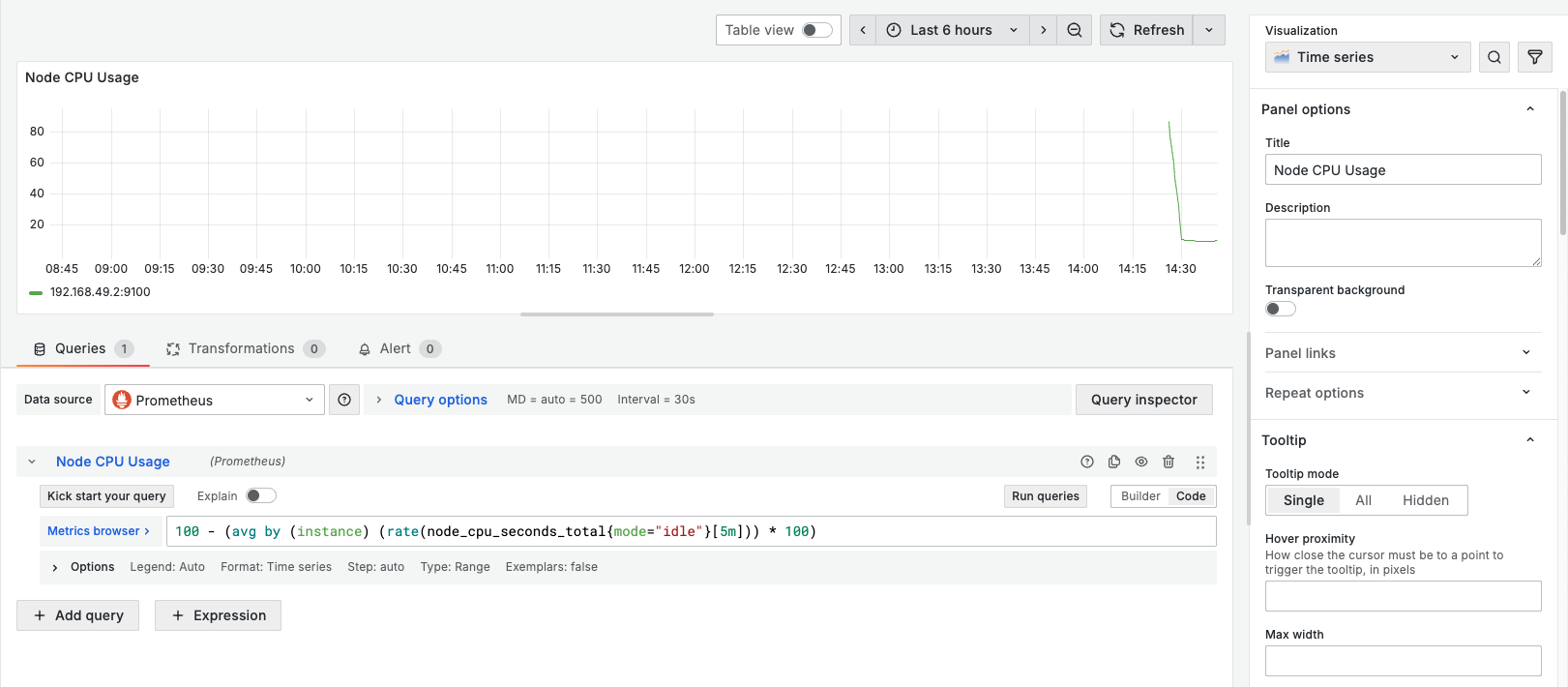
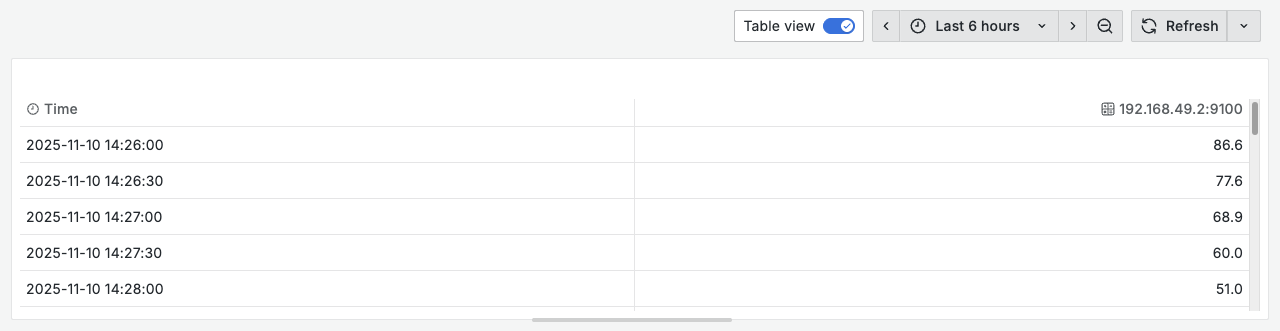
그러면 위 사진과 같이 노드의 CPU 사용률이 그래프로 나타나는 것을 볼 수 있다. 상단 메뉴의 Table view를 클릭하면 Timestamp 별로 데이터가 나타나는 것을 확인할 수 있다.
만약 그래프의 디자인을 변경하고 싶다면 오른쪽 패널(Visualization)에서 설정할 수 있다. 이는 상황에 따라 적절하게 사용하면 될 것이다.

대시보드 이름을 지정하고 저장하면 아래와 같이 방금 만들었던 패널(Visualization)이 나타나는 것을 볼 수 있다.
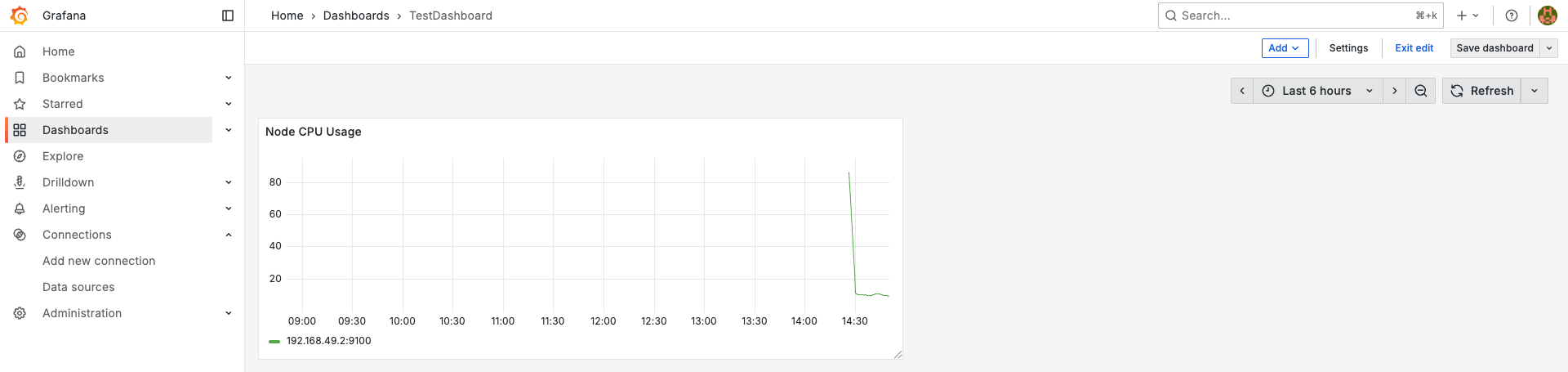
이제 직접 2개의 패널(Node Memory Usage, Pod Count)을 추가하고 아래의 쿼리를 넣어보자. Add > Visualization를 통해 추가할 수 있다.
# Node Memory Usage
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100
# Pod Count
count(kube_pod_info)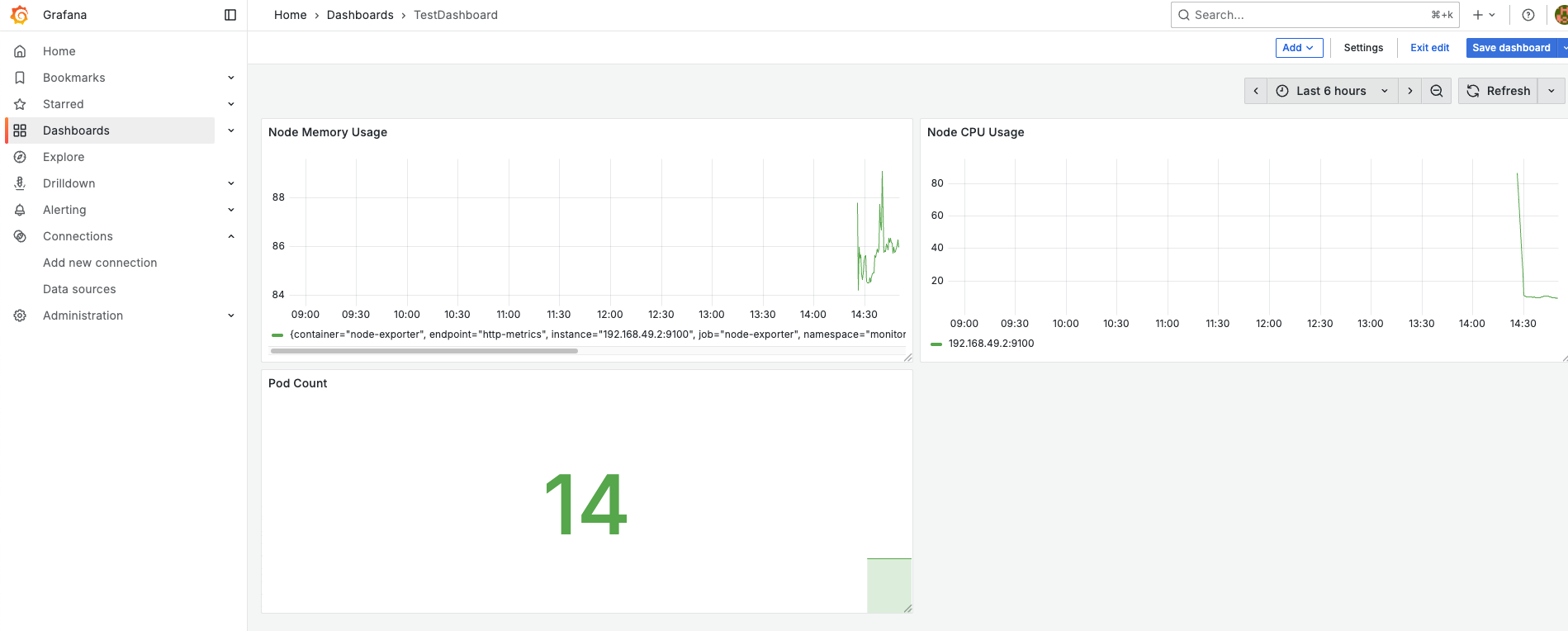
다음으로 Pod Count를 테스트해보기 위해 kubectl run nginx --image=nginx 명령어를 실행하여 파드를 하나 늘려보자.
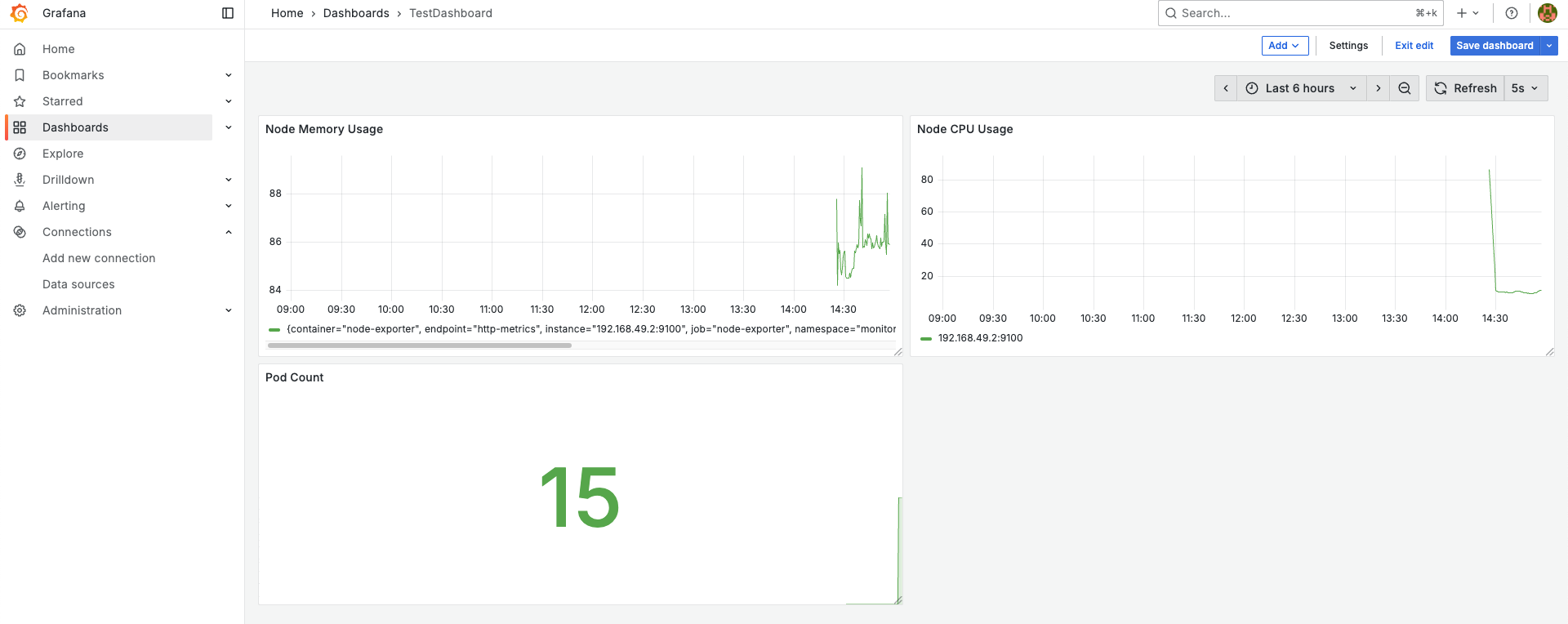
그럼 scrape_interval 주기로 업데이트 되는 것을 볼 수 있다. 참고로 scrape_interval는 아래와 같은 명령어로 확인해볼 수 있다. (파드 이름이 다를 수 있음)
> kubectl exec -it prometheus-kube-prometheus-stack-prometheus-0 -n monitoring -- \
cat /etc/prometheus/config_out/prometheus.env.yaml | grep scrape_interval
scrape_interval: 30s
scrape_interval: 10s
> kubectl exec -it prometheus-kube-prometheus-stack-prometheus-0 -n monitoring -- \
awk '/scrape_configs:/,0' /etc/prometheus/config_out/prometheus.env.yaml | grep -B2 -A5 "scrape_interval"
attach_metadata:
node: false
scrape_interval: 10s
metrics_path: /metrics/cadvisor
scheme: https
tls_config:
insecure_skip_verify: true
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt여기서 scrape_interval이 두개인 이유는 필자가 Minikube 노드를 구성할 때 minikube start --extra-config=kubelet.housekeeping-interval=10s 로 cAdvisor의 주기를 10초로 설정하였고, 때문에 cAdvisor의 scrape_interval만 10초로 설정된 것이다.
3-3. Prometheus Client Library: Express App Integration
이제 다음으로 Node.js Express 앱에서 Prometheus Client Library를 적용하여 OpenMetrics 엔드포인트(/metrics)를 구성해보겠다.
mkdir express-metrics && cd express-metrics
npm init -y
npm install express prom-client그리고 아래의 index.js와 Dockerfile을 작성하겠다.
const express = require('express')
const client = require('prom-client')
const app = express()
const register = new client.Registry()
client.collectDefaultMetrics({ register })
const httpRequestCounter = new client.Counter({
name: 'http_requests_total',
help: 'Total number of HTTP requests',
labelNames: ['method', 'route', 'status_code'],
})
register.registerMetric(httpRequestCounter)
app.get('/', (req, res) => {
httpRequestCounter.inc({ method: 'GET', route: '/', status_code: 200 })
res.send('Hello Metrics!')
})
app.get('/metrics', async (req, res) => {
res.set('Content-Type', register.contentType)
res.end(await register.metrics())
})
app.listen(8080, () => console.log(`Server running on port 8080`))FROM node:20-alpine
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 8080
CMD ["node", "index.js"]아래의 명령어로 빌드하고 Docker Hub에 업로드하자.
docker buildx build --platform linux/amd64,linux/arm64 \
-t <USERNAME>/prom-demo:latest --push .그리고 Express 앱을 로컬에서 실행하고 /metrics 엔드포인트에 접속해보자.
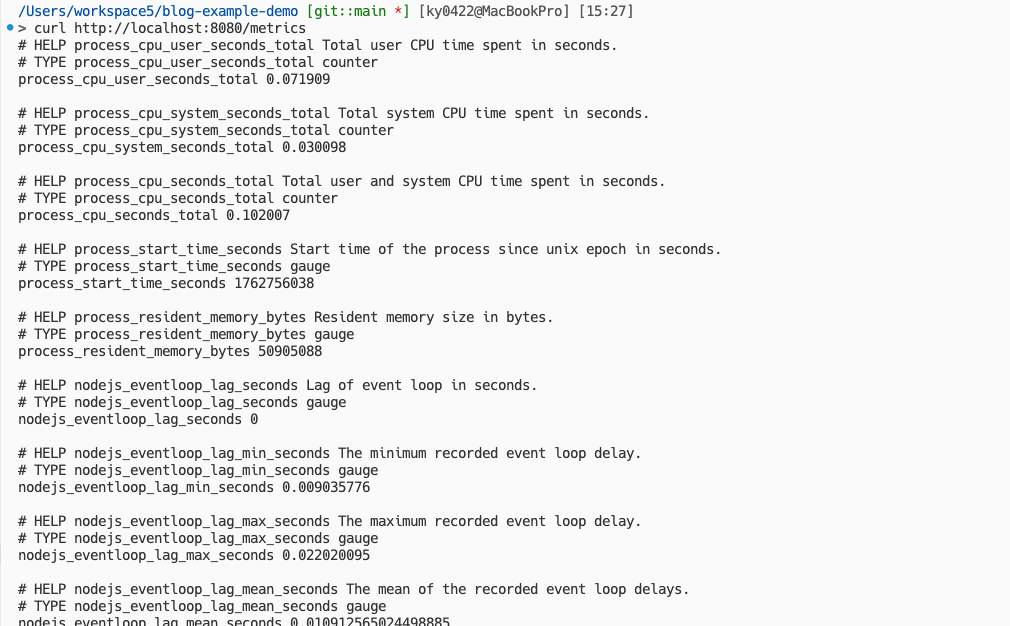
그럼 OpenMetrics 포맷의 /metrics 엔드포인트가 생긴 것을 볼 수 있다. (실제 환경에선 Nginx와 같은 서비스로 해당 엔드포인트를 가리거나 다른 프라이빗한 서비스에 엔드포인트 만드는 형태로 운영하면 된다.)
이제 아래와 같은 Deployment와 Prometheus CRD인 ServiceMonitor를 구성하자.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: express-app
labels:
app: express-app
spec:
replicas: 1
selector:
matchLabels:
app: express-app
template:
metadata:
labels:
app: express-app
spec:
containers:
- name: express-app
image: <USERNAME>/prometheus-test:latest
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: express-app
labels:
app: express-app
spec:
selector:
app: express-app
ports:
- name: http
port: 8080
targetPort: 8080# servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: express-app
labels:
release: kube-prometheus-stack
spec:
selector:
matchLabels:
app: express-app
endpoints:
- port: http
path: /metrics
interval: 10skubectl apply -f deployment.yaml -n monitoring
kubectl apply -f servicemonitor.yaml -n monitoring적용 후, exec 등으로 접속하여 / 카운트를 올려보자.
/app # curl -s localhost:8080 && echo && curl -s localhost:8080/metrics | grep 'http_requests_total'
Hello Metrics!
# HELP http_requests_total Total number of HTTP requests
# TYPE http_requests_total counter
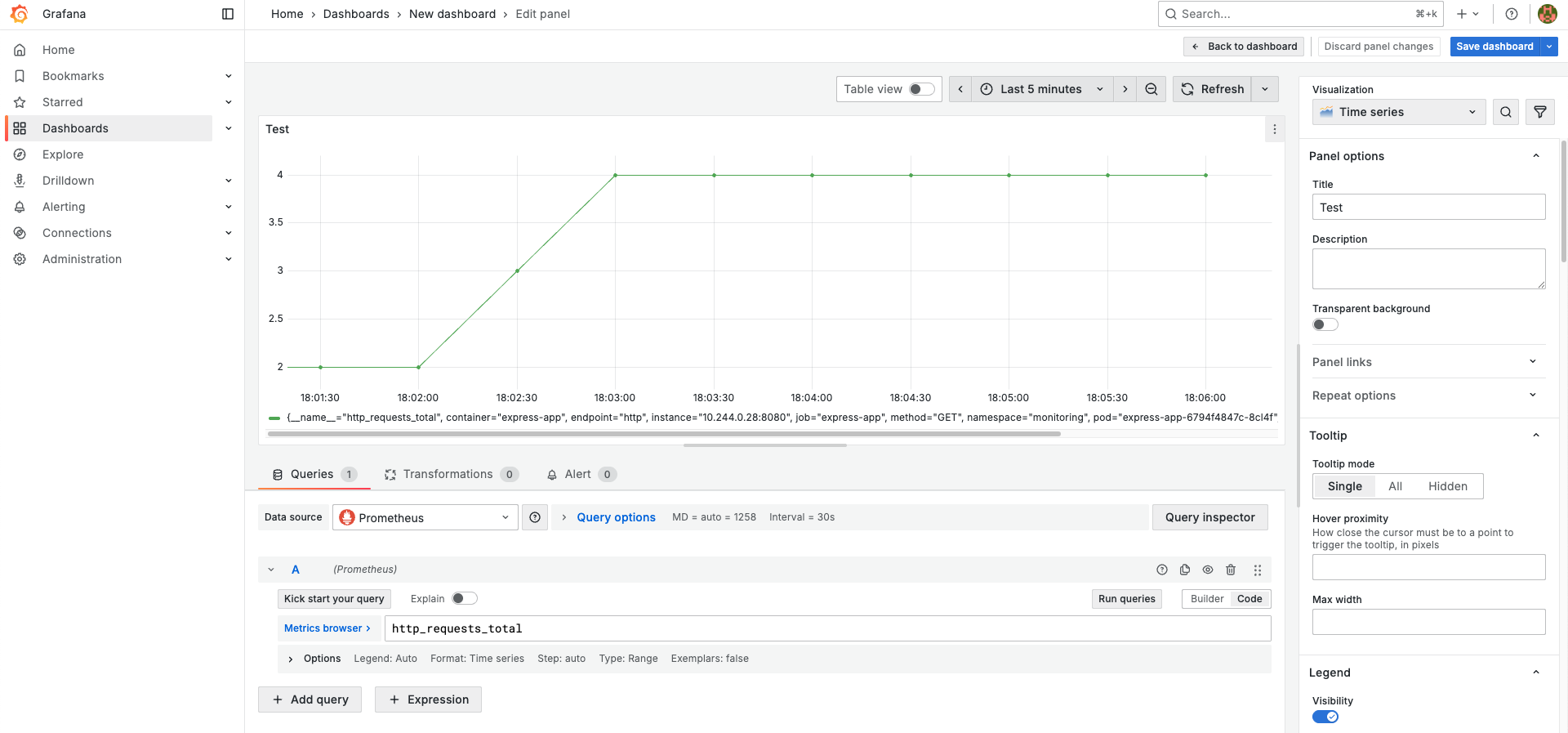
http_requests_total{method="GET",route="/",status_code="200"} 4그리고 Prometheus Web UI에서 쿼리를 확인해보자.

그럼 사진과 같이 커스텀한 http_requests_total가 잘 표시되는 것을 확인할 수 있다. 마찬가지로 Grafana 대시보드에서도 패널을 추가하여 확인해볼 수 있다.