< 웹크롤링 실전 연습 >
기본 환경 설정이 끝난 후에 가장 간단한 방법으로 웹크롤링을 직접 해보도록 하겠습니다.
1. 가상 브라우저 열기
# 버전 업데이트 필요없이 항상 최신 버전의 구글 드라이브를 사용할 수 있도록 함
driver = webdriver.Chrome(ChromeDriverManager().install())
# 드라이브 열리는 동안 기다림
driver.implicitly_wait(3)2. 가상 브라우저에서 크롤링하고자 하는 페이지로 이동
Ex) 네이버 웹툰(일상) 페이지 선택
# 위 코드 실행하고, 창을 닫지 않아야함
# 접근할 주소, 예시로 네이버 웹툰 장르별 페이지
page_address='https://comic.naver.com/webtoon/genre'
# 암묵적으로 모든 자원이 로드될 때까지 기다리게 하는 시간
driver.implicitly_wait(3)
# # 크롤링할 사이트 호출, url에 접근하는 메소드
driver.get(page_address)3. Copy full Xpath로 태그 추출
F12 버튼(개발자 도구)을 통해 크롤링하고자 하는 태그를 마우스로 가리키고, 해당 부분의 태그를 Copy full Xpath 실행하면서 추출할 부분의 규칙을 파악(실행 X)
# 웹툰 제목
/html/body/div/div[3]/div[1]/div[3]/ul/li[1]/dl/dt/a
/html/body/div/div[3]/div[1]/div[3]/ul/li[75]/dl/dt/a # 마지막 이미지
# 웹툰 작가
/html/body/div/div[3]/div[1]/div[3]/ul/li[1]/dl/dd[1]/a
/html/body/div/div[3]/div[1]/div[3]/ul/li[2]/dl/dd[1]/a
# 웹툰 평점
/html/body/div/div[3]/div[1]/div[3]/ul/li[1]/dl/dd[3]/div/strong
/html/body/div/div[3]/div[1]/div[3]/ul/li[2]/dl/dd[3]/div/strong
# 웹툰 이미지 css selector, 총 75개 존재, 항상 아래와 같은 위치에 존재, 불규칙적인 full xpath가 존재하므로 대체
#content > div.comicinfo > div.thumb > a > img
#content > div.comicinfo > div.thumb > a > img
# 웹툰 내용, 총 75개 존재, 항상 아래와 같은 위치에 존재
/html/body/div/div[3]/div[1]/div[1]/div[2]/p[1]
/html/body/div/div[3]/div[1]/div[1]/div[2]/p[1]
/html/body/div/div[3]/div[1]/div[2]/div[2]/p[1]
#content > div.comicinfo > div.detail > p:nth-child(2)
#content > div.comicinfo > div.detail > p:nth-child(2)
# 웹툰 세부 장르
/html/body/div/div[3]/div[1]/div[1]/div[2]/p[2]/span[1]
/html/body/div/div[3]/div[1]/div[1]/div[2]/p[2]/span[1]
#content > div.comicinfo > div.detail > p.detail_info > span.genre
#content > div.comicinfo > div.detail > p.detail_info > span.genre
# 웹툰 연령 기준
/html/body/div/div[3]/div[1]/div[1]/div[2]/p[2]/span[2]
/html/body/div/div[3]/div[1]/div[1]/div[2]/p[2]/span[2]
#content > div.comicinfo > div.detail > p.detail_info > span.age
#content > div.comicinfo > div.detail > p.detail_info > span.age4. 주요 사용 함수
해당 부분도 실행 X
# 버튼 선택
driver.find_element(By.XPATH,'').click()
# 텍스트 추출
driver.find_element(By.XPATH,'').text
# CSS_SELECTOR를 활용한 추출
driver.find_element(By.CSS_SELECTOR,'')
# 브라우저 로드 2초 기다림, 초는 자유롭게 변경
time.sleep(2)
# 브라우저 뒤로 가기
driver.back()5. 데이터프레임 생성
크롤링한 데이터를 담을 데이터프레임을 생성하고, 컬럼명을 지정
col1='genre' # 장르
col2='title' # 제목
col3='writer' # 작가
col4='grade' # 평점
col5='image' # 이미지
col6='content' # 내용
col7='genreDetails' # 세부 장르
col8='ageCriteria' # 연령 기준
# 데이터 베이스 컬럼명 설정
col_list=[col1, col2, col3, col4, col5, col6, col7, col8]
# 해당 컬럼을 가진 빈 데이터프레임 생성
df_ta=pd.DataFrame(columns=col_list)6. 개별 데이터 추출 및 로직 구성 초안 설계
어떤 데이터를 추출할 것이고, 겹치지 않는 주소를 파악
# 웹툰 제목 추출
title=driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li[1]/dl/dt/a').text
# 웹툰 작가 추출
writer=driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li[1]/dl/dd[1]/a').text
# 웹툰 평점 추출
grade=driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li[1]/dl/dd[3]/div/strong').text
# 웹툰 세부 내용 페이지로 이동
driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li[1]/dl/dt/a').click()
# 이미지 url 추출
imgUrl = driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.thumb > a > img').get_attribute("src")
# 파일을 저장할 주소
address=str('C:\\Users\\shinyumi\\Desktop\\Image')
# 해당 주소에 웹툰 제목으로 파일을 저장
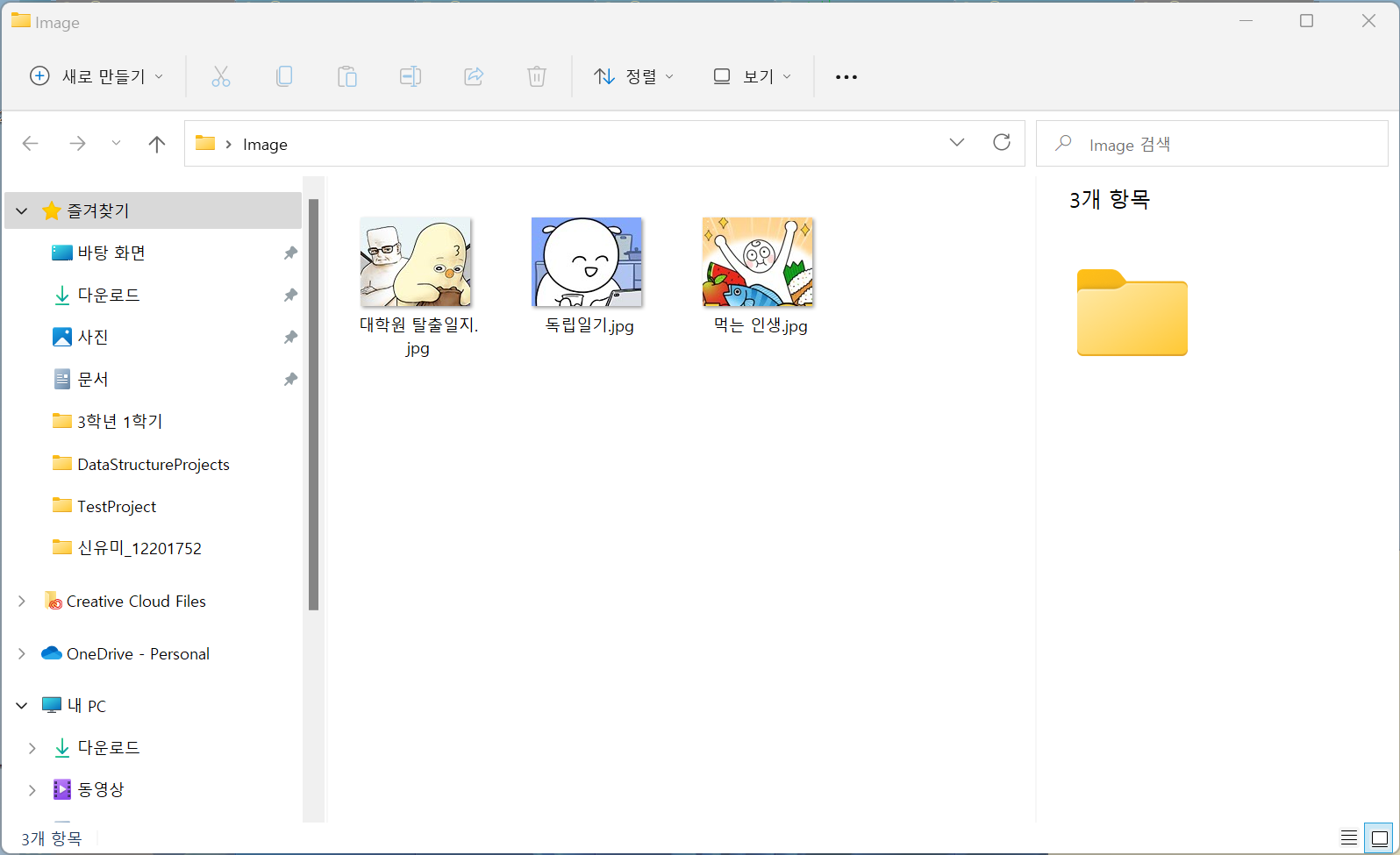
urllib.request.urlretrieve(imgUrl,address+"/"+str(title)+".jpg")
# 웹툰 소개글 추출
content=driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.detail > p:nth-child(2)').text
# 세부 장르 내용 추출
genreDetails=driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.detail > p.detail_info > span.genre').text
# 연령 기준 추출
ageCriteria=driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.detail > p.detail_info > span.age').text7. 로직 완성 및 추출 진행
로직을 완성하여 코드를 구성하고, 동작을 통해 추출을 진행(제목, 작가, 평점 추출 → 상세 페이지 이동 → 썸네일 저장, 소개글, 장르, 연령 기준 추출)
# 파일을 저장할 주소
address=str('C:\\Users\\shinyumi\\Desktop\\Image')
# 웹툰 정보 확보, 예시로 3개만 추출
for i in range(0, 3):
# 웹툰 제목 추출
title=driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li['+str(i+1)+']/dl/dt/a').text
# 웹툰 작가 추출
writer=driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li['+str(i+1)+']/dl/dd[1]/a').text
# 웹툰 평점 추출
grade=driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li['+str(i+1)+']/dl/dd[3]/div/strong').text
# 웹툰 세부 내용 페이지로 이동
driver.find_element(By.XPATH,'/html/body/div/div[3]/div[1]/div[3]/ul/li['+str(i+1)+']/dl/dt/a').click()
# 이동하면서 웹페이지 로드되는 동안 기다림
time.sleep(2)
# 이미지 url 추출
imgUrl = driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.thumb > a > img').get_attribute("src")
# 해당 주소에 웹툰 제목으로 파일을 저장
urllib.request.urlretrieve(imgUrl,address+"/"+str(title)+".jpg")
# 웹툰 소개글 추출
content=driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.detail > p:nth-child(2)').text
# 세부 장르 내용 추출
genreDetails=driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.detail > p.detail_info > span.genre').text
# 연령 기준 추출
ageCriteria=driver.find_element(By.CSS_SELECTOR,'#content > div.comicinfo > div.detail > p.detail_info > span.age').text
# 웹툰 정보에 따른 단일 배열 설정
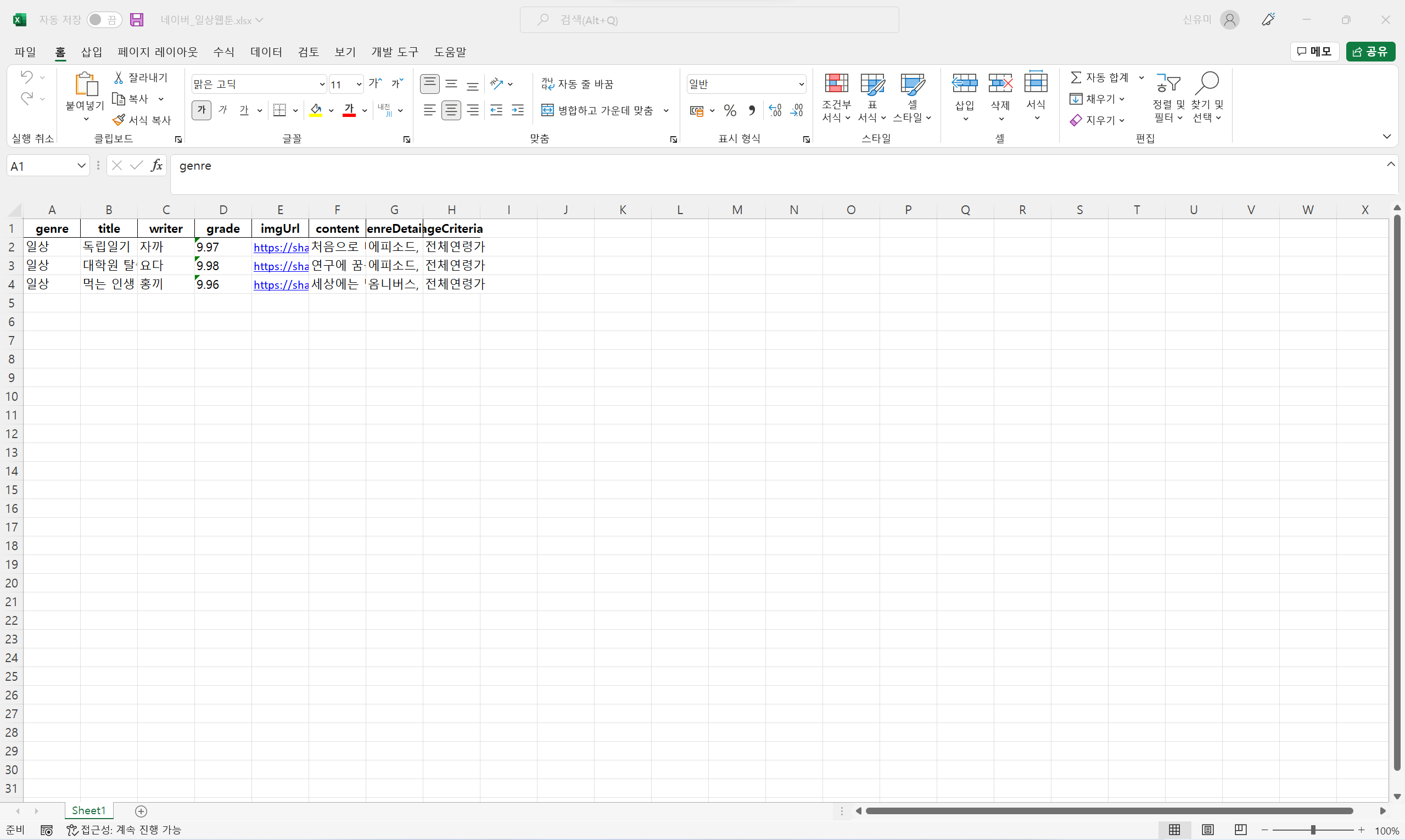
df_tem={col1:'일상', col2:title, col3:writer, col4:grade, col5:imgUrl, col6:content, col7:genreDetails, col8:ageCriteria}
# 최종 데이터 프레임에 삽입
df_ta=df_ta.append(df_tem, ignore_index=True)
# 로그 기록
print(str(title)+' 추출')
# 뒤로 가기
driver.back()
time.sleep(2)
# 최종 데이터 프레임 출력
df_ta8. 엑셀 파일에 저장
# 저장할 엑셀의 경로
excel_path='C:\\Users\\shinyumi\\Desktop\\Excel\\네이버_일상웹툰.xlsx'
# 엑셀에 작성하기, 파일이름만 변경해서 저장
writer = pd.ExcelWriter(excel_path, engine='xlsxwriter')
df_ta.to_excel(writer, index=False)
writer.save()9. 결과