Torch.utils.data
Pytorch를 이용해서 딥러닝 모델을 학습시키기 위해서는 데이터 로딩과 전처리를 담당하는 Dataset 클래스 및 Dataloader 클래스를 이용해서 딥러닝 모델 학습에 필요한 데이터를 준비함
DataLoader 클래스에 포함되는 함수
from torch.utils.data import DataLoader일반적으로 Dataloader를 구성하기 위해 사용됨
-
num_workers
: 데이터 로딩·전처리를 수행하는 CPU 서브프로세스 수
: I/O(Input/Output) 연산에 사용되는 코어를 적절하게 조절하여 병목을 완화
: num_workers=0 으로 설정하게 되면 main process 에서만 data를 loading 하도록 설정되고, num_worker>0으로 설정하면 비동기식으로 데이터를 loading하여 데이터를 더 효율적으로 주고받을 수 있음
-> 일반적으로 GPU x 4를 사용하는게 좋다는 보고가 있으나 이는 CPU성능과 GPU 성능을 고려해서, 각자 실험환경에서 맞추어서 구성해야함 ( 저는 GPU utilization에 따라서 구성하였습니다 ) -
pin_memory
: pin_memory=False를 기본값으로 설정 돼 있음
: DataLoader가 CPU의 페이지-고정 메모리(pinned memory)로 텐서를 만들어 반환
: 일반적으로 GPU를 위한 CUDA 사용 시 True를 일반적으로 사용함
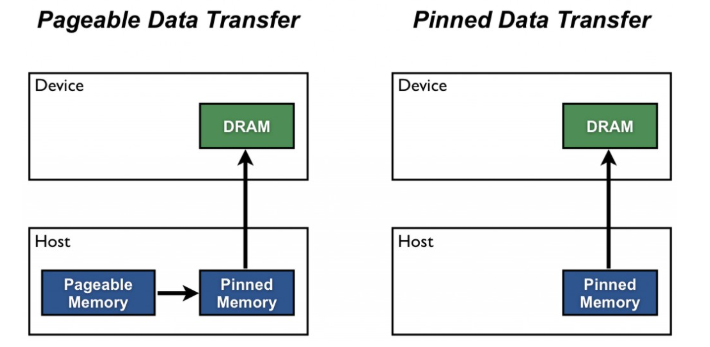
참조 : https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
: 그림에서 보이는 Device는 GPU, Host 는 CPU에서 이루어지는 작업이라고 생각하면 됨
: Device에서는 연산을 빠르게 처리할 수 있고
: 일반적으로 data를 페이징 기법을 이용해서 전송하는데 이를 생략해서 더 효율적으로 데이터를 전송하는 방식임
- non_blocking
: tensor 및 데이터를 비동기식으로 처리할 수 있는 option이라고 보면 됨
: tensor.to(device, non_blocking=True) 또는 .cuda(non_blocking=True)에서 복사를 비동기화 처리하기 위해 사용됨
: 데이터가 pinned memory여야 실제로 비동기 전송이 됨.
이를 위해서는 dataloader에서 pin_memory=True로 설정해야함
이는 Dataloder 옵션은 아니고 복사 호출 옵션
for batch in loader:
inputs = batch['img'].to(device, non_blocking=True)
targets = batch['targets'].to(device, non_blocking=True)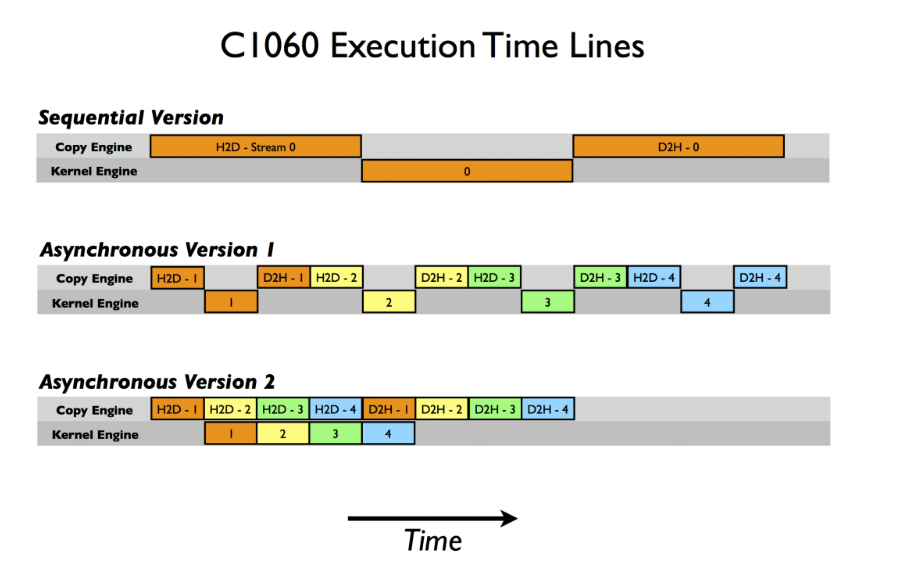
참조 : https://developer.nvidia.com/blog/how-overlap-data-transfers-cuda-cc/
: 위 그림의 첫번째가 동기식(synchronous) 방식이고 두번째, 세번째가 비동기식(asynchronous)방식입니다. 동기식 방식의 경우 CPU → GPU로 데이터 전달이 끝이나야 그 다음 연산이 진행되는 반면에 비동기식 방식에서는 데이터 전송과 GPU 연산이 동시에 발생할 수 있습니다.
Dataset 클래스에 포함되는 함수
-
init
-
len(): 데이터셋의 전체 샘플 개수를 반환하는 메서드로, 정수 값을 반환
-
getitem(idx): 인덱스 idx에 해당하는 샘플을 가져오는 메서드로, 인덱스에 따라 샘플 데이터와 레이블(label) 등을 반환하며 transpose 및 augmentation 관련된 부분이 정의됨
# torchvision.transforms 를 사용해서 이미지 전처리
import torchvision.transforms as T
img_T = T.Compose([
transforms.Resize((256, 256)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])torchvision.transforms 이미지 전처리 함수
-
Resize: 이미지의 크기를 조절
transform = transforms.Resize((256, 256)) -
RandomResizedCrop: 이미지를 무작위로 자르고 크기를 조절
transforms.RandomResizedCrop(size, scale, ratio)
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)) -
RandomHorizontalFlip: 이미지를 무작위로 수평 전환
transforms.RandomHorizontalFlip(p=0.5)
: 50% 확률로 수평으로 뒤집음 -
RandomVerticalFlip: 이미지를 무작위로 수직 전환
transforms.RandomVerticalFlip(p=0.5) -
ToTensor: 이미지를 텐서로 변환
transforms.ToTensor() -
Normalize: 이미지를 정규화
transforms.Normalize(mean, std)
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
: rgb 3개 채널에 대한 평균과 표준편차를 이용해서 이미지를 정규화 -
ColorJitter: 밝기, 대비, 채도를 무작위로 조정
transforms.ColorJitter(brightness, contrast, saturation, hue)
transforms.ColorJitter(brightness=0.2, contrast=0.3) -
RandomRotation: 이미지를 무작위로 회전
transforms.RandomRotation(degrees)
transforms.RandomRotation(degrees=30)
: -30도 ~ 30도 사이로 회전 -
RandomCrop: 이미지를 무작위로 자름
transforms.RandomCrop(size)
transforms.RandomCrop(128)
: (128, 128)로 자르기 -
Grayscale: 이미지를 흑백으로 변환
transforms.Grayscale(num_output_channels=1) -
RandomSizedCrop: 이미지를 무작위로 자르고 크기를 조절 > 최신 버전에서는 제거됨
torchvision.utils.save_image 텐서를 파일로 저장하는 함수
torchvision.utils.save_image(tensor, filename, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0)- tensor : (Tensor) - 저장할 이미지 텐서. shape는 (batch_size, channels, height, width) 이어야 합니다.
- filename : (str) - 저장할 파일의 경로와 이름입니다.
- nrow : (int, optional) - 저장할 이미지들을 한 줄에 몇 개씩 보여줄 것인지 결정하는 인자입니다. 기본값은 8입니다.
- padding : (int, optional) - 이미지들 사이의 간격을 몇 개의 픽셀로 할 것인지 결정하는 인자입니다. 기본값은 2입니다.
- normalize : (bool, optional) - 이미지의 값을 [0, 1]로 정규화할 것인지 결정하는 인자입니다. 기본값은 True입니다.
- range : (tuple, optional) - 이미지를 정규화할 때 사용할 범위를 결정하는 인자입니다. 기본값은 None으로, 입력된 텐서의 값 범위를 그대로 사용합니다.
- scale_each : (bool, optional) - 이미지를 정규화할 때 각 이미지마다 다른 범위를 사용할지 여부를 결정하는 인자입니다. 기본값은 False입니다.
- pad_value : (float, optional) - 이미지의 테두리를 채우는 값입니다. 기본값은 0입니다.
Problem ❓
객체 탐지 데이터셋의 경우 이미지의 숫자와 label에 해당하는 데이터가 일치하지 않아서 dataloading시에 적절하게 batch가 이루어지지 않으므로, collate_fn 함수를 사용해야함
Solution ⭕
Future Work & Check
Future Work & Check 🔍
