🍃이 글은 inflearn에서 김영한의 스프링 부트와 JPA 실무 완전 정복 로드맵을 학습하고 작성한 것입니다.🍃
JPQL
-
JPQL은 객체지향 쿼리 언어다. 따라서 테이블을 대상으로 쿼리 하는 것이 아니라 엔티티 객체를 대상으로 쿼리한다.
-
JPQL은 SQL을 추상화하기 때문에 특정 데이터베이스 SQL에 의존하지 않는다.
-
JPQL은 결국 SQL로 변환된다.
JPQL 문법
-
select 문
- select 절 from 절 (where 절) (groupby 절) (having 절) (orderby 절)
-
update 문
- update 절 (where 절)
-
delete 문
- delete 절 (where 절)
-
ex) select m from Member m where m.age > 18
- 엔티티와 속성은 대소문자 구분한다.
- JPQL 키워드는 대소문자 구분하지 않는다. (select, from, where ...)
- 테이블 이름이 아닌 엔티티 이름을 사용한다.
- 별칭(m)은 필수이다.
-
집합 지원
select
COUNT(m), //회원 수
SUM(m.age), //나이 합
AVG(m.age), //평균 나이
MAX(m.age), //최대 나이
MIN(m.age) //최소 나이
from Member m-
정렬 지원
- GROUP BY, HAVING
- ORDER BY
TypeQuery, Query
- TypeQuery: 반환 타입이 명확할 때 사용
TypedQuery<Member> query =
em.createQuery("SELECT m FROM Member m", Member.class);- Query: 반환 타입이 명확하지 않을 때 사용
Query query =
em.createQuery("SELECT m.username, m.age from Member m");결과 조회
- query.getResultList(): 결과가 하나 이상일 때, 리스트 반환
- 결과가 없으면 빈 리스트 반환
-
query.getSingleResult(): 결과가 정확히 하나, 단일 객체 반환
-
결과가 없으면: javax.persistence.NoResultException
-
둘 이상이면: javax.persistence.NonUniqueResultException
-
Spring Data JPA는 이런 예외 대신 Optional을 반환한다.
-
파라미터 바인딩
em,createQuery("SELECT m FROM Member m where m.username = :username", Member.class)
.setParameter("username", usernameParam)
.getResultList();- 이름 기준으로 사용한다.
프로젝션
프로젝션이란 SELECT 절에 조회할 대상을 지정하는 것이다.
-
프로젝션 대상: 엔티티, 임베디드 타입, 스칼라 타입 (숫자, 문자 등 기본 데이터 타입)
-
"SELECT m FROM Member m", Member.class
- 엔티티 프로제션
-
"SELECT m.team FROM Member m", Team.class
- 엔티티 프로젝션
- 하지만 명확하고 구체적으로 쿼리를 작성해야 유지보수가 편하다.
- ex) "SELECT t from Member m join m.team t", Team.class
-
"SELECT m.address FROM Member m", Address.class
- 임베디드 타입 프로젝션
-
"SELECT m.username, m.age FROM Member m", ??? (타입 지정 불가)
- 스칼라 타입 프로젝션
-
DISTINCT로 중복 제거 가능하다.
-
데이터베이스에서 모든 컬럼값이 동일한 행 1차 중복 제거
-
조회한 엔티티 중에서 식별자(pk)가 같으면 2차 중복 제거
-
여러 값 조회
"SELECT m.username, m.age FROM Member m", ??? (타입 지정 불가)-
첫 번째 방법: new 명령어로 조회 가능하다.
- 타입을 지정해서 조회할 DTO 클래스 생성
public class MemberDTO { private String username; private int age; MemberDTO(String username, int age) { this.username = username; this.age = age; } }- 단순 값을 DTO로 바로 조회
"SELECT new 패키지명.UserDTO(m.username, m.age) FROM Member m", MemberDTO.class- 패키지 명을 포함한 전체 클래스 명 입력
- 파라미터 순서와 일치하는 생성자 필요
-
두 번째 방법: Object[] 타입으로 조회할 수 있다.
List<Objcet[]> resultList = em.createQuery("select m.username, m.age from Member m") .getResult(); Object[] result = resultList.get(0); System.out.println("username = ", result[0]); System.out.println("age = ", result[1]);-
반환 타입이 명확하지 않기 때문에 Object[]로 반환한다.
-
이 방법은 단순 값이 아닌, 여러 엔티티 값을 조회할 때 사용한다.
- 첫 번째 방법처럼 조회한 값을 DTO로 변환하기가 애매할 때 사용
-
페이징
//페이징 쿼리
String jpql = "select m from Member m order by m.name desc";
List<Member> resultList = em.createQuery(jpql, Member.class)
.setFirstResult(10)
.setMaxResults(20)
.getResultList();-
setFirstResult(int startPosition): 조회 시작 위치 (0부터 시작)
-
setMaxResults(int maxResult): 조회할 데이터 수
-
order by를 적용해서 페이징이 제대로 동작하는지 확인
조인
-
내부 조인
-
SELECT m FROM Member m JOIN m.team t
-
멤버는 있고, 팀이 없을 시 데이터 조회가 안 된다.
-
-
외부 조인
-
SELECT m FROM Member m LEFT JOIN m.team t
-
멤버는 있고, 팀이 없을 시 팀 데이터는 전부 null인 상태로 멤버가 조회된다.
-
-
세타 조인
-
SELECT m FROM Member m, Team t where m.username = t.name
-
CARTESIAN JOIN으로 멤버 테이블의 모든 행이 팀 테이블의 모든 행과 조인한다.
-
연관관계가 전혀 없는 것을 막 조인할 때 사용한다.
-
on 절
- 조인 대상 필터링
- ex) 회원과 팀을 조인하면서, 팀 이름이 A인 팀만 조인
SELECT m, t FROM Member m LEFT JOIN m.team t on t.name = 'A'
- 연관관계 없는 엔티티 외부 조인
- ex) 회원의 이름과 팀의 이름이 같은 대상 외부 조인
SELECT m, t FROM Member m LEFT JOIN Team t on m.username = t.name
서브 쿼리
-
ex 1) 나이가 평균보다 많은 회원
select m from Member m where m.age > (select avg(m2.age) from Member m2) -
ex 2) 한 건이라도 주문한 고객
select m from Member m where (select count(o) from Order o where m = o.member) > 0 -
예시 1번처럼 메인 쿼리의 Member를 굳이 사용할 필요가 없다면, 새 Member를 사용하는 것이 성능에 좋다.
서브 쿼리 지원 함수
- (NOT) EXISTS (서브 쿼리): 서브 쿼리에 결과가 존재하면 참(거짓)
select m from Member m where exists (select t from m.team t where t.name = ‘팀A') - ALL (서브 쿼리): 모두 만족하면 참
select o from Order o where o.orderAmount > ALL (select p.stockAmount from Product p) - ANY, SOME (서브 쿼리): 조건 하나라도 만족하면 참
select m from Member m where m.team = ANY (select t from Team t) - (NOT) IN (서브 쿼리): 서브 쿼리의 결과 중 하나라도 같은 것이 있으면 참
JPA 서브 쿼리 한계
-
JPA는 기본적으로 WHERE, HAVING 절에서만 서브 쿼리 사용 가능하다.
-
하이버네이트 6부터 SELECT, FROM 절에서도 사용 가능하다.
JPQL 타입 표현
-
문자: ‘HELLO’ , ‘She’’s’
-
숫자: 10L(Long), 10D(Double), 10F(Float)
-
Boolean: TRUE, FALSE
-
ENUM: jpabook.MemberType.Admin (패키지명 포함)
-
엔티티 타입: TYPE(m) = Member (상속 관계에서 사용)
SQL과 문법이 같은 식
- EXISTS, IN
- AND, OR, NOT
- =, <>, >, >=, <, <=
- BETWEEN, LIKE, IS NULL
조건식
- 기본 CASE 식
select
case when m.age <= 10 then '학생요금'
when m.age >= 60 then '경로요금'
else '일반요금'
end
from Member m- 단순 CASE 식
select
case t.name
when '팀A' then '인센티브110%'
when '팀B' then '인센티브120%'
else '인센티브105%'
end
from Team t- COALESCE: 하나씩 조회해서 null이 아니면 반환
select coalesce(m.username,'이름 없는 회원') from Member m- 사용자 이름이 없으면 이름 없는 회원을 반환
- NULLIF: 두 값이 같으면 null 반환, 다르면 첫 번째 값 반환
select NULLIF(m.username, '관리자') from Member m- m.username이 관리자면 null을 반환하고 아니면 m.username반환
JPQL 기본 함수
- CONCAT
- SUBSTRING
- TRIM
- LOWER, UPPER
- LENGTH
- LOCATE
- ABS, SQRT, MOD
- SIZE, INDEX(JPA 용도)
- 기본 함수로 해결이 안 되면 사용자 정의 함수를 호출한다.
경로 표현식
-
.(점)을 찍어 객체 그래프로 탐색한다.
-
상태 필드: 단순히 값을 저장하기 위한 필드
- m.username(username이 단순 값)
-
연관 필드: 연관관계를 위한 필드
- 단일 값 연관 필드
- @ManyToOne
- @OneToOne
- m.team(team이 엔티티)
- 컬렉션 값 연관 필드
- @OneToMany
- @ManyToMany
- m.orders(orders가 컬렉션)
- 단일 값 연관 필드
경로 표현식 특징
-
상태 필드: 경로 탐색의 끝, 탐색이 불가능하다.
- m.username.xxx가 불가능하다.
-
단일 값 연관 경로: 묵시적 내부 조인이 발생, 탐색이 가능하다.
- select m.team.name from Team t가 가능하다.
-
컬렉션값 연관 경로: 묵시적 내부 조인이 발생, 탐색이 불가능하다.
-
select t.members.username from Team t가 불가능하다.
- members가 컬렉션이기 때문에 어떤 member에서 이름을 가져올지 판단할 수가 없다.
-
대신 FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색이 가능하다.
- select m.username from Team t join t.members m이 가능하다.
-
결론
- 상태 필드는 jpql이 그대로 sql로 변환되기 때문에 그대로 사용하자.
- 묵시적 조인은 항상 내부 조인으로 동작하고, 유지보수에 어려움이 있다.
- join 키워드를 사용해서 sql과 비슷하게 명시적 조인을 하자.
- select m from Member m join m.team t
- 외부 조인은 어차피 명시적 조인으로밖에 동작을 안 한다.
- select m from Member m left join m.team t
- 일어나는 상황을 한눈에 파악하기 위해 그냥 명시적 조인만 사용하자.
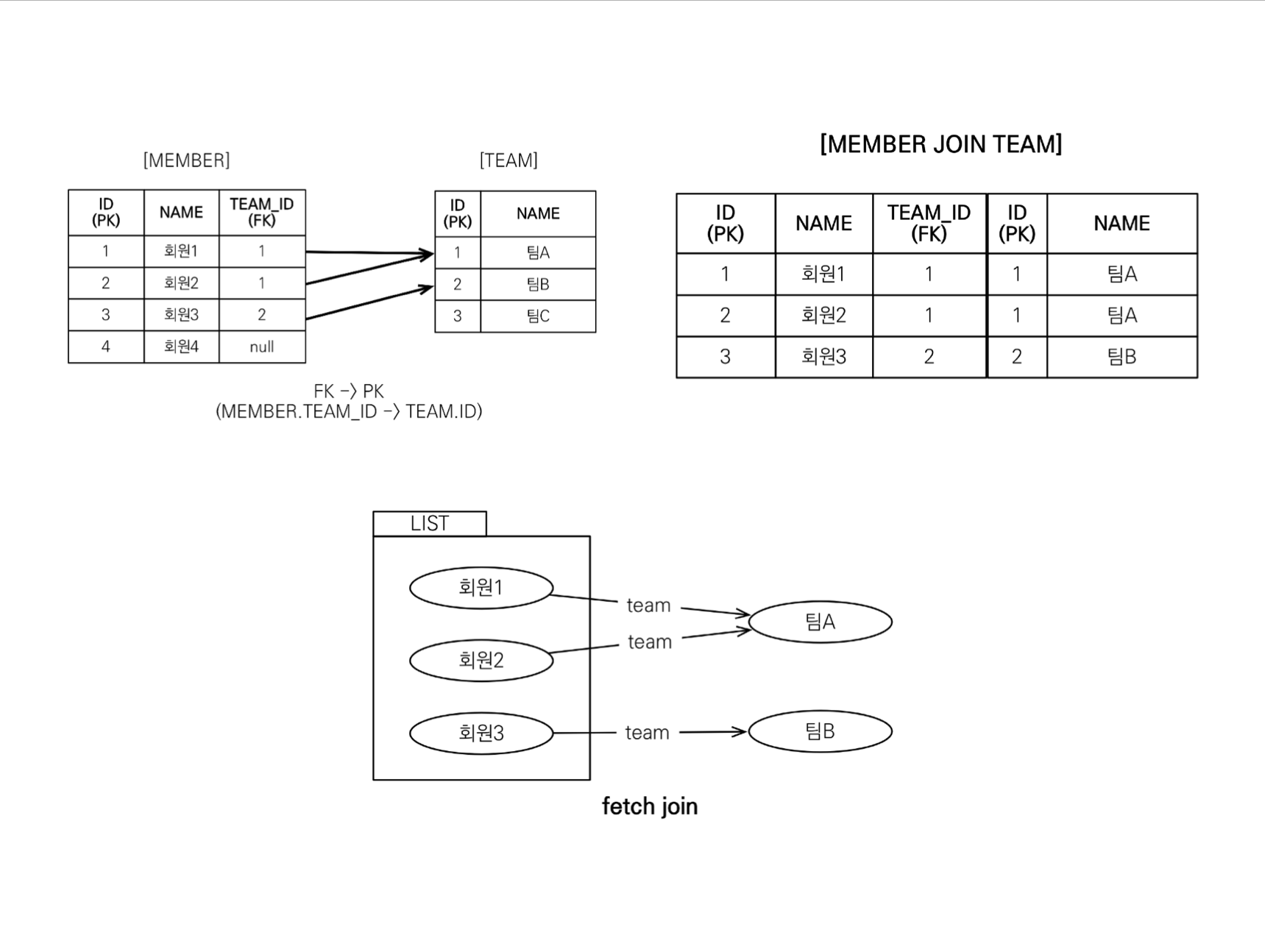
페치 조인(join fetch)
-
JQPL에서 연관된 엔티티나 컬렉션을 SQL 한 번에 조회 가능한 성능 최적화 기능이다.
-
join fetch 명령어 사용한다.
-
N + 1문제가 해결된다.
-
엔티티 페치 조인(일대일, 다대일)
- [JQPL]
- select m from Member m join fetch m.team
- [SQL]
- SELECT M.*, T.* FROM MEMBER M INNER JOIN TEAM T ON M.TEAM_ID = T.ID
- [JQPL]
-
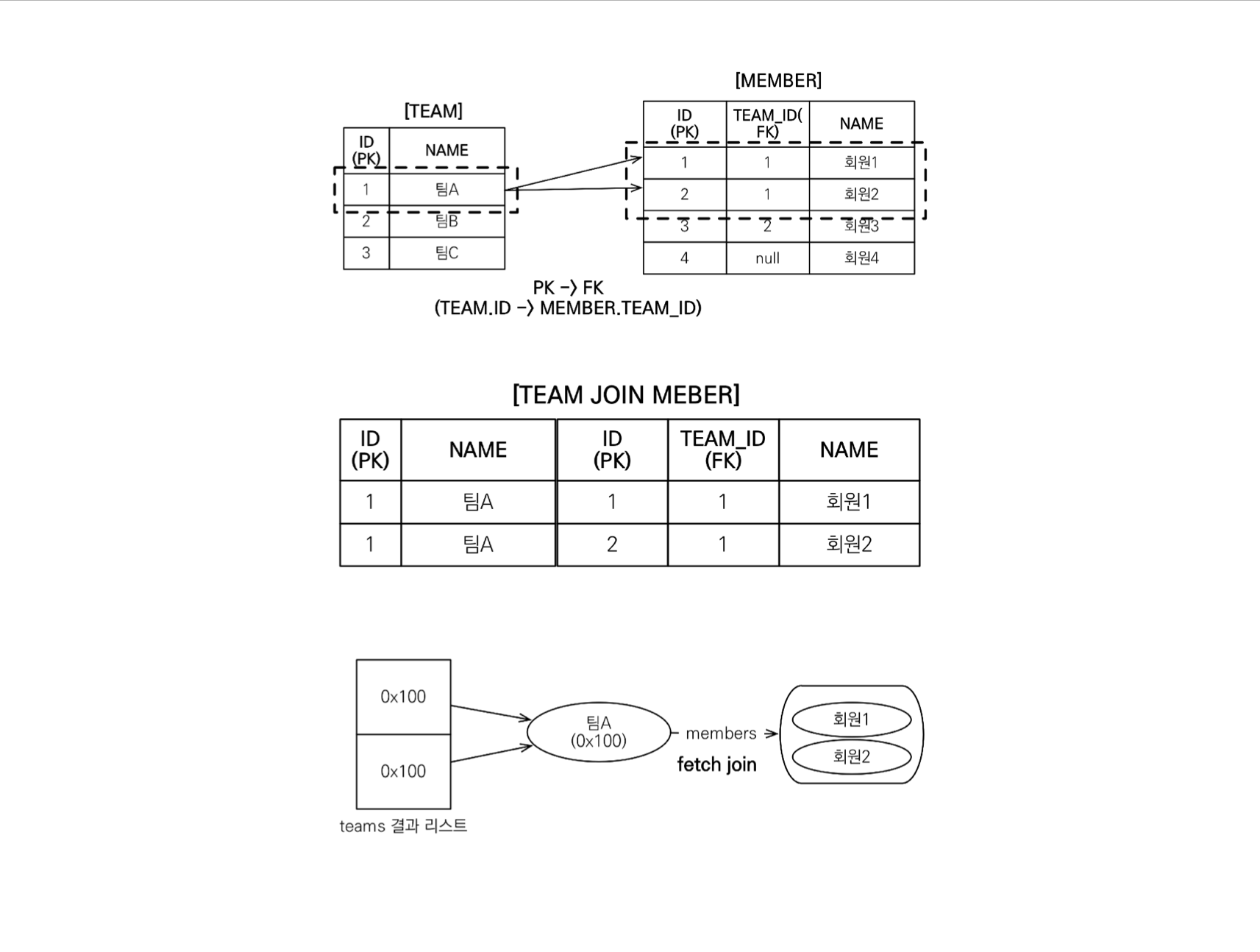
컬렉션 페치 조인(일대다, 다대다)
- [JQPL]
- select t from Team t join fetch t.members where t.name = ‘팀A'
- [SQL]
- SELECT T.*, M.* FROM TEAM T INNER JOIN MEMBER M ON T.ID=M.TEAM_ID WHERE T.NAME = '팀A'
- [JQPL]
페치 조인과 DISTINCT
-
위 컬렉션을 페치 조인할 때 그림을 보면 조인 특성상 row가 두 줄이 된다. (데이터 뻥튀기)
-
실제 객체 상태에서 보면 동일한 Team 객체가 두 개가 되는 것이다.
- 객체 그래프 탐색을 하면 하나의 팀에 두 멤버가 있는데, 이러한 Team 엔티티가 두 개 조회되기 때문이다.
-
JPQL의 DISTINCT
- SQL에 중복되는 행을 제거하는 DISTINCT 추가
- 애플리케이션에서 같은 pk 값을 가지는 엔티티 중복 제거
페치 조인과 일반 조인의 차이
-
일반 조인은 실행 시 연관된 엔티티를 함께 조회하지 않는다.
-
패치 조인은 실행 시 연관된 엔티티를 함께 조회한다.
- 페치 조인은 객체 그래프를 SQL 한 번에 조회한다.
페치 조인의 특징과 한계
-
페치 조인 대상에는 별칭을 주면 안 된다.
-
만약 별칭을 사용해서 원하는 데이터를 뽑는다면, JPA가 의도한 설계에 어긋난다.
-
기본적으로 데이터를 전부 조회하는 이유로 사용해야 한다.
-
정확성에 이슈가 생길 수 있다.
-
-
둘 이상의 컬렉션은 페치 조인을 할 수 없다.
- 페치 조인 컬렉션은 딱 하나의 컬렉션만 지정할 수 있다.
-
둘 이상의 컬렉션을 지정하면 정확성에 이슈가 생길 수 있다.
-
컬렉션을 페치 조인하면 페이징 API(setFirestResult, setMaxResults)를 사용할 수 없다.
- 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징이 가능하다.
- 일대다, 다대다 같은 컬렉션을 페치 조인하면 데이터 뻥튀기가 되면서 페이징할 때 정확성에 이슈가 생길 수 있다.
컬렉션 대상 페이징 해결 방법
-
일대다를 다대일로 뒤집어서 엔티티 페치 조인을 한다.
-
컬렉션 페치 조인을 하지않고, 일반적인 지연 로딩으로 해당 컬렉션에 접근해서 값을 가져온다. 이때 베치 사이즈를 1000 이하로 적절하게 설정한다.
-
개별적으로 컬렉션에 적용: @BatchSize(size = 1000)
-
글로벌하게 적용: spring.jpa.hibernate.default_batch_fetch_size = 1000
-
베치 사이즈를 설정하면 지연 로딩 시 설정한 베치 사이즈만큼 값들을 한 번에 가져온다.
-
N + 1문제가 해결된다.
-
페치 조인 정리
- 모든 것을 페치 조인으로 해결할 수는 없다.
- 페치 조인은 객체 그래프를 유지할 때 사용하면 효과적이다.
- 여러 테이블을 조인해서 엔티티가 가진 모양이 깨진다면 페치 조인보다는 일반 조인을 사용하고, 필요한 데이터들만 조회해서 DTO를 반환하자.
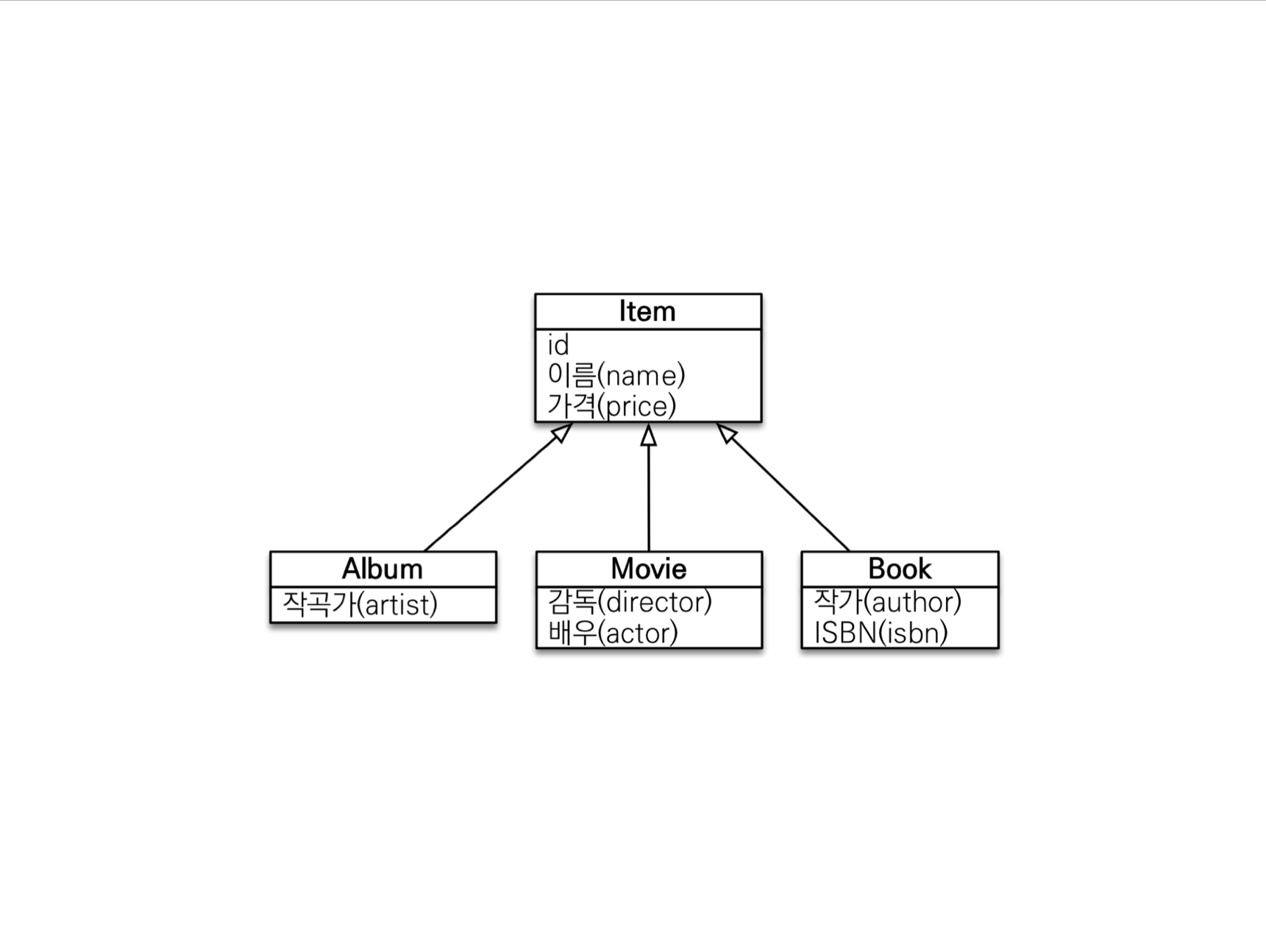
다형성 쿼리
-
type
-
조회 대상을 특정 자식으로 한정
-
Item 중에 Book, Movie를 조회해라
-
[JPQL]
- select i from Item i where type(i) IN (Book, Movie)
-
[SQL]
- select i from i where i.DTYPE in (‘B’, ‘M’)
-
자바의 타입 캐스팅과 유사
-
상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용
-
-
treat
-
자바의 타입 캐스팅과 유사
-
상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용
-
부모인 Item과 자식 Book이 있다.
-
[JPQL]
- select i from Item i where treat(i as Book).author = ‘kim’
-
[SQL]
- select i.* from Item i where i.DTYPE = ‘B’ and i.author = ‘kim’
-
엔티티 직접 사용
-
JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본키 값을 사용
-
[JPQL]
-
select count(m.id) from Member m
- 엔티티의 아이디를 사용
-
select count(m) from Member m
- 엔티티를 직접 사용
-
-
[SQL](JPQL 둘다 같은 다음 SQL 실행)
- select count(m.id) as cnt from Member m
Named 쿼리
-
미리 정의해서 이름을 부여하고 사용하는 JPQL
-
정적 쿼리, 동적 쿼리로 사용 불가
-
애플리케이션 로딩 시점에 초기화 후 재사용
-
애플리케이션 로딩 시점에 쿼리를 검증
- 컴파일 시점에 오류를 체크할 수 있는 장점
-
@Entity @NamedQuery( name = "Member.findByUsername", query="select m from Member m where m.username = :username") public class Member { ... } List<Member> resultList = em.createNamedQuery("Member.findByUsername", Member.class) .setParameter("username", "회원1") .getResultList(); -
실무에선 spring data jpa를 사용
@Query("select u from User u where u.emailAddress = ?1")
User findByEmailAddress(String emailAddress); - @NamedQuery보단 DAO 또는 Repository에서 @Query로 사용하자.
벌크 연산
-
pk값을 이용해서 한 건을 DELETE나 UPDATE할 때, 이런 식으로 변경된 데이터가 100건이라면 트랜잭션 커밋 시점에 변경 감지가 동작해서 100번의 쿼리가 실행된다.
-
쿼리 한 번으로 여러 테이블 값을 DELETE나 UPDATE해주는 것을 벌크 연산이라 한다.
-
int resultCount = em.createQuery("update ~").executeUpdate();를 실행해주면 된다.
- 결과는 영향받은 엔티티의 수를 반환해준다.
- 기본적으로 update와 delete를 지원한다.
-
spring data jpa의 @Modifying를 사용해서 벌크 연산을 수행할 수 있다.
- 자동으로 영속성 컨텍스트 초기화해주는 설정 등의 편의성을 제공
벌크 연산 주의
-
벌크 연산은 영속성 컨텍스트를 무시하고 바로 데이터베이스에 쿼리가 실행된다.
-
이때 쿼리가 실행되기 전에 플러쉬가 호출되므로 영속성 컨텍스트에 저장돼있던 쿼리들도 같이 실행된다.
-
문제는 이미 영속성 컨텍스트 1차 캐쉬에 있는 내용들이다. 벌크 연산이 반영된 실제 DB의 내용들과 다를 수 있다.
-
-
두 가지 해결 방법
- 벌크 연산을 먼저 실행한다.
- 벌크 연산 수행 후 영속성 컨텍스트를 초기화한다.
