
개념
-
linked data structures
-
노드(node)라고 하는 여러 개의 메모리 청크에 데이터를 저장
-
서로 다른 메모리 위치에 데이터가 저장됨
-
연결 리스트(linked list)의 기본 구조에서 각각의 노드는 저장할 데이터(data)와 다음 노드를 가리키는 포인터(next)를 가진다.
-
맨 마지막 노드에서는 다음 노드의 포인터 대신 자료 구조의 끝을 나타내는 NULL을 가진다.
-
연결 리스트에서 특정 원소에 접근하려면 리스트의 시작 부분, 즉 헤드(head) 부분부터 시작하여 원하는 원소에 도달할 때까지 next 포인터를 따라 이동해야 함.
-
그러므로 i번째 원소에 접근하려면 연결 리스트 내부를 i번 이동해야 함
-
원소 접근 시간은 노드 개수에 비례하여, 시간 복잡도는 O(n)
-
배열과 달리 연결 리스트는 포인터를 이용하여 원소 삽입/삭제를 매우 빠르게 수행 *추가/제거 위치의 주소를 알고 있을 경우 시간 복잡도가 O(1)
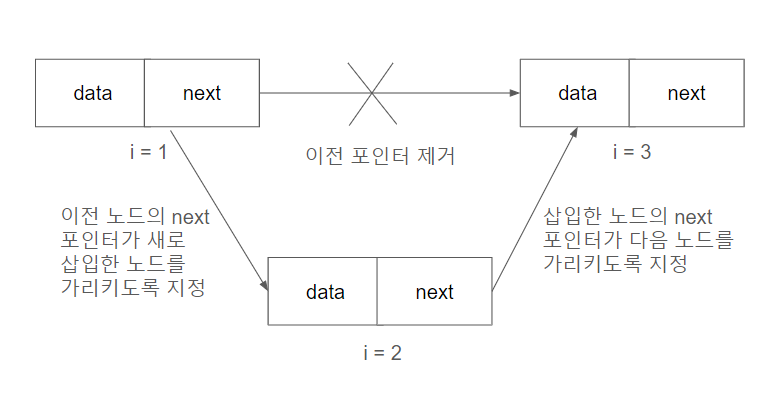
-
원소가 메모리에 연속적으로 저장되지 않기 때문에 캐시 지역성은 기대할 수 없다.
-
즉, 현재 노드가 가리키는 다음 노드에 직접 방문하지 않고 다음 원소를 캐시로 가져올 수 없다.
-
따라서 배열과 연결 리스트에서 모든 원소를 차례대로 방문하는 작업은 이론적으로 같은 시간 복잡도를 가지지만, 실제로는 연결 리스트의 성능이 조금 떨어진다.
-
c++ STL에서
list= doubly linked list(이중 연결 리스트)forward_list= singly linked list -> list보다 적은 메모리 공간 차지
백준 5397번
#include <iostream>
#include <list>
using namespace std;
int main(){
// 변수 선언
int N; // 테스트 케이스의 개수
string s; // 각 테스트 케이스에서 처리할 문자열
// 테스트 케이스의 개수 입력
cin >> N;
// 이터레이터와 비밀번호를 저장할 리스트 선언
list<char>::iterator it;
list<char> password;
// 각 테스트 케이스에 대해 반복
for(int i = 0 ; i < N ; ++i){
// 입력 문자열 읽기
cin >> s;
// 비밀번호 리스트 초기화하고 이터레이터를 시작 위치로 설정
password.clear();
it = password.begin();
// 입력 문자열의 각 문자에 대해 반복
for(int j = 0 ; j < s.length(); ++j){
// '<'를 만나면 이터레이터를 왼쪽으로 이동
if(s[j] == '<') {
if(it != password.begin()) it--;
}
// '>'를 만나면 이터레이터를 오른쪽으로 이동
else if(s[j] == '>'){
if(it != password.end()) it++;
}
// '-'를 만나면 이터레이터 왼쪽의 문자를 삭제
else if(s[j] == '-'){
if(it != password.begin()) it = password.erase(--it);
}
// 그 외의 경우 현재 이터레이터 위치에 문자를 삽입
else{
it = password.insert(it, s[j]);
it++;
}
}
// 각 테스트 케이스 처리 후 최종 비밀번호 출력
for(char x : password) cout << x;
cout << endl;
}
return 0;
}
- 전위 연산자(prefix)와 후위 연산자(postfix)의 사용
- 전위 연산자: 변수의 값을 먼저 증감시킴, lvalue
x = 10 a = ++x; // a = 11, x = 11 ++xx = x; // x = 12 - 후위 연산자: 표현식 수행 후에 변수의 값을 증감시킴, rvalue
x = 10 a = x++; // a = 10, x = 11 x++ = x; // compile error
- 전위 연산자: 변수의 값을 먼저 증감시킴, lvalue
