
1. 배열
(1) 1차원 배열
// 선언과 초기화
int arr[5]; // 쓰레기값 (지역 변수)
int arr2[5] = {1, 2, 3, 4, 5}; // 직접 초기화
int arr3[5] = {1, 2}; // → {1, 2, 0, 0, 0} 나머지 0
int arr4[5] = {}; // → {0, 0, 0, 0, 0} 전부 0
int arr5[] = {1, 2, 3}; // 크기 자동 결정 (3)
// 접근과 순회
arr2[0]; // 1 (0부터 시작!)
arr2[4]; // 5
for (int i = 0; i < 5; i++) {
cout << arr2[i] << " ";
}
-
전역 변수는 초기화 X시 자동으로 0이 들어간다.
-
지역 변수는 초기화 X시 쓰레기 값이 들어간다.
배열의 중요한 특징은 : 한 번 선언되면 배열의 크기는 변할 수 없다
는 것이다.
(2) 2차원 배열
// 선언
int grid[3][4]; // 3행 4열
int grid2[3][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
// 입력 받기 (코테 기본 패턴)
int n, m;
cin >> n >> m;
int arr[105][105]; // 넉넉하게 잡기! (N ≤ 100이면 105 정도)
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> arr[i][j];
}
}
// 출력
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cout << arr[i][j] << " ";
}
cout << "\n";
}(3) 배열 초기화 - 1차원 배열
#include <cstring> // memset을 쓰기 위해 필요한 헤더
#include <algorithm> // fill을 쓰기 위해 필요한 헤더
// 방법 1: 0으로 초기화
int arr[100] = {}; // 선언 시 0 초기화
memset(arr, 0, sizeof(arr)); // 언제든 0으로 리셋
// 방법 2: -1로 초기화 (DP에서 자주 씀)
memset(arr, -1, sizeof(arr)); // 모든 바이트를 0xFF → int에선 -1이 됨
// 방법 3: 특정 값으로 초기화
fill(arr, arr + 100, 7); // 모든 원소를 7로 (가장 범용적)
// 2차원 배열 초기화
int grid[105][105];
memset(grid, 0, sizeof(grid));
// 또는
fill(&grid[0][0], &grid[0][0] + 105 * 105, 0);위와같이 memset()이나 fill()을 통해 배열을 초기화할 수 있다.
memset(배열이름, 채울값, 바이트수);
- memset의 경우 채울 값으로
0또는-1만 사용 가능하다.fill(시작주소, 끝주소, 채울값);
- 중요한 것은 끝주소의 경우 초기화 대상이 아니다. 그래서 arr의 크기가 100이라면 ->
fill(arr,arr+100, 5)이런식으로 해줘야 배열의 모든 요소가 5로 초기화된다.
⚠️ memset 주의: 0과 -1만 안전하게 동작. 다른 값(예: 1, INF)으로 초기화하려면 fill()을 사용해야한다.
(3) 배열 초기화 - 2차원 배열
#include <cstring> //memset() 쓰기 위해 필요
#include <algorithm> //fill() 쓰기 위해 필요
// 고정 크기
int arr[100][100];
int arr[100][100] = {0}; // 2차원 배열 전체 0 초기화 (전역이면 자동 0)
// 0으로 초기화
memset(arr, 0, sizeof(arr));
// fill로 특정 값 초기화
for(int i = 0; i < N; i++)
fill(arr[i], arr[i] + M, 값);(4) 2차원 배열의 특징
(1) 2차원 배열 arr[m][n] 에서 arr[m] 은 1차원 배열의 이름 이다.
int arr[m][n] 은 int [n] 배열이 m개 모인 배열이다.
또한,arr[i]은 2차원 배열 내부 배열의 이름이다.
그래서 1차원 배열과 마찬가지로 배열의 이름인 arr[i]은 해당 1차원 배열의 주소를 반환한다.
2. 문자열 (C++ 스타일의 문자열 - string)
아래는 전부 C++ 스타일의 문자열인 string에 대한 설명이다.
참고로, C++ Style의 문자열인 string은 length라는 멤버로 문자열의 길이를 관리하므로
, C Style의 문자열인 char []와 다르게 \0이 필요하지않다.
(1) #include <string>
C++ 스타일 string을 사용하려면
#include <string>
using namespace std; // <---이건 선택<string> 헤더가 필요하다.
(2) 문자열 관련 주요 함수

string도 배열처럼 s[i]로 접근 가능하다.
또한 이때 char& 타입 (참조 타입) 으로 반환하므로
s[i] = "abcd~~"와 같이 문자열 원본을 수정하는 것도 가능하다.


string s = "hello world";
if (s.find("world") != string::npos) {
cout << "찾았다!" << endl; // ✅ 출력됨
}
// 몇 번째에 있는지
int pos = s.find("world"); // pos = 6
string s = "2025-02-14";
string year = s.substr(0, 4); // "2025"
string month = s.substr(5, 2); // "02"
string day = s.substr(8, 2); // "14"
💡 <, > 비교는 사전순(알파벳순) 비교! 코테 정렬에 자주 쓰임
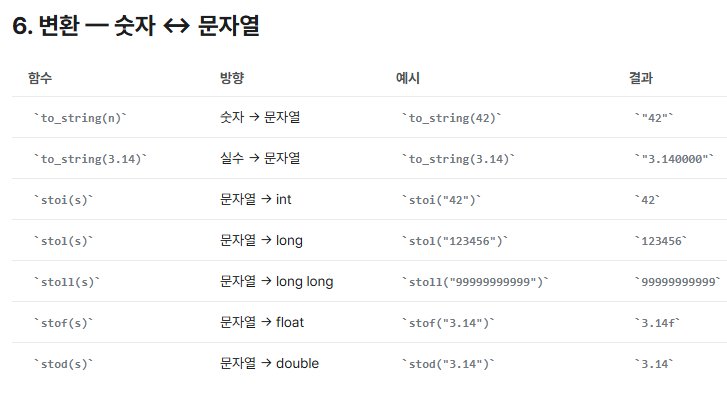
int n = 12345;
string s = to_string(n); // "12345"
int back = stoi(s); // 12345
// 코테 활용: 각 자릿수 순회
for (char c : to_string(n)) {
int digit = c - '0'; // 1, 2, 3, 4, 5
}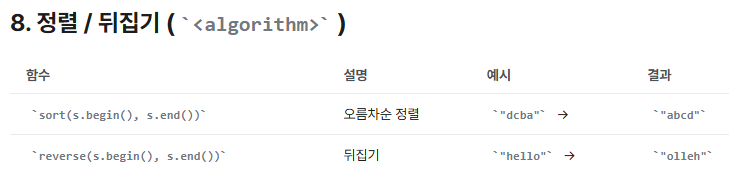
#include <algorithm>
// 팰린드롬(회문) 체크
string s = "racecar";
string rev = s;
reverse(rev.begin(), rev.end());
if (s == rev)
cout << "회문이다!"; // ✅(3) 문자 판별 함수 : <cctype> 활용
#include <cctype> // bits/stdc++.h에 포함
char ch = 'A';
isalpha(ch); // true — 알파벳인가?
isdigit(ch); // false — 숫자인가?
isalnum(ch); // true — 알파벳 또는 숫자?
isupper(ch); // true — 대문자?
islower(ch); // false — 소문자?
isspace(ch); // false — 공백/탭/줄바꿈?(4) 문자 변환 함수
toupper('a'); // 'A'
tolower('A'); // 'a'
// 문자열 전체를 대문자로
string s = "Hello World";
for (int i = 0; i < s.size(); i++) {
s[i] = toupper(s[i]);
}
// s = "HELLO WORLD"
// 더 깔끔한 방법
for (char &c : s) { // 참조로 받아야 원본 수정!
c = tolower(c);
}
// s = "hello world"(5) ASCII 활용
// 문자 → 숫자
'A' → 65 'a' → 97 '0' → 48
// 알파벳 인덱싱 (0~25)
char ch = 'C';
int idx = ch - 'A'; // 2
// 알파벳 등장 횟수 카운팅 (배열 이용)
int alpha[26] = {};
string s = "banana";
for (char c : s) {
alpha[c - 'a']++;
}
// alpha[0]=2(a), alpha[1]=1(b), alpha[13]=2(n) ...
// 숫자 문자 → 실제 숫자 (복습)
char ch2 = '7';
int num = ch2 - '0'; // 7(6) istringstream
문자열을 cin처럼 읽을 수 있게 해주는 도구
//기본 구조
istringstream iss(line); //line이라는 변수를 버퍼에 넣게된다.
│ │ │
│ │ └── 생성자에 문자열 전달 (이걸 버퍼에 넣음)
│ └─────── 변수 이름 (꼭 iss일 필요 없이 아무거나 가능)
└────────────────────── 타입 (input + string + stream)istringstream을 사용하면 문자열을 버퍼에 넣게되고 cin을 사용할때와 동일한 방법으로 읽을 수 있게된다.
// 키보드에서 읽기
int n;
cin >> n; // 키보드 입력 대기
// 문자열에서 읽기
string line = "42 hello";
istringstream iss(line); // "42 hello"를 버퍼에 넣음
int n;
string s;
iss >> n; // n = 42
iss >> s; // s = "hello"위와 같이 공백을 기준으로 끊어서 버퍼의 값을 변수에 저장한다. (cin과 동작이 동일하다)
또다른 예시를 살펴보자.
string line = "hello world foo bar";
istringstream iss(line);
string token;
while (iss >> token) {
cout << token << "\n";
}앞서 말했듯이, iss >> token도 cin >> 처럼 공백을 자동 스킵한다.
cin은 더 이상 읽을 게 없으면 대기하지만, iss는 더 이상 읽을 게 없으면 false를 반환해서 while이 종료된다.
(7) 사용 빈도별 함수 정리
| 사용빈도 | 기능 | 이름(형태) | 예시 호출 | 헤더 |
|---|---|---|---|---|
| 1 | \n 전까지 읽어서 문자열 타입 변수에 저장(한 줄 입력) | getline(cin, s) / getline(입력스트림, 문자열, 구분자문자) | getline(cin, s); | <iostream>, <string> |
| 2 | string s를 입력 스트림에 넣음. 토큰화에 주로 사용 (공백 기준 토큰화) | istringstream iss(s) | istringstream iss(s); string t; while (iss >> t) {} | <sstream>, <string> |
| 3 | 문자열→정수로 변환해서 반환 | stoi / stol / stoll | int x = stoi("123"); | <string> |
| 4 | 정수,실수→문자열로 변환해서 반환 | to_string(n) | string s = to_string(123); | <string> |
| 5 | 부분문자열 찾기(인덱스 반환) | s.find(s1) / s.find(pos, s1) | auto p = s.find("abc"); / s.find('a'); | <string> |
| 6 | 뒤에서 찾기(인덱스 반환) | s.rfind(s1) | auto p = s.rfind("abc"); | <string> |
| 7 | 부분문자열 추출(부분 문자열 반환) | s.substr(pos, len) | string t = s.substr(2, 3); | <string> |
| 8 | 맨 뒤에 문자열 붙이기 | s += t / s.append(s1) | s += "x"; / s.append("x"); | <string> |
| 9 | 맨 뒤에 한 글자 추가/삭제 | s.push_back(c) / s.pop_back() | s.push_back('a'); s.pop_back(); | <string> |
| 10 | 삭제 | s.erase(pos, len) / s.erase(it) | s.erase(3, 2); / s.erase(s.begin()+3); | <string> |
| 11 | 삽입 | s.insert(pos, s1) | s.insert(2, "ZZ"); | <string> |
| 12 | 치환 | s.replace(pos, len, s1) | s.replace(1, 3, "abc"); | <string> |
| 13 | 뒤집기(원본 수정) | reverse(s.begin(), s.end()) | reverse(s.begin(), s.end()); | <algorithm> |
| 14 | 정렬(아스키 코드 순서로 오름차순, 원본 수정) | sort(s.begin(), s.end()) | sort(s.begin(), s.end()); | <algorithm> |
| 15 | 다음 순열 | next_permutation(s.begin(), s.end()) | next_permutation(s.begin(), s.end()); | <algorithm> |
| 16 | 문자 판별 | isdigit(c) / isalpha(c) / isspace(c) | isdigit('7') / isalpha('d') / isspace(' ') | <cctype> |
| 17 | 대/소문자 변환한거 반환 | tolower(c) / toupper(c) | char c2 = tolower('D'); | <cctype> |
| 18 | 비었는지/길이 | s.empty() / s.size() / s.length() | if (s.empty()) ...; int n = s.size(); | <string> |
참고로, getline(입력스트림, 문자열, 구분자문자) 으로 구분자 문자를 수동 지정할 수도 있다.
예를들어
std::getline(iss, s1, ","); 하면 \n이 아니라 ,를 기준으로 끊어서 s1에 저장한다.
(8) 흔한 문자열 처리 패턴
// 패턴 1: 팰린드롬 체크
bool isPalindrome(string s) {
int l = 0, r = s.size() - 1;
while (l < r) {
if (s[l] != s[r]) return false;
l++; r--;
}
return true;
}
// 패턴 2: 문자열 내 숫자만 추출
string s = "a1b2c3";
string nums = "";
for (char c : s) {
if (isdigit(c)) nums += c;
}
// nums = "123"
// 패턴 3: 문자열 토큰 분리 (공백 기준)
string line = "hello world foo bar";
istringstream iss(line); // #include <sstream>
string token;
while (iss >> token) {
cout << token << "\n"; // hello / world / foo / bar
}
// 패턴 4: 특정 구분자로 분리
string csv = "apple,banana,cherry";
istringstream iss2(csv);
string item;
while (getline(iss2, item, ',')) {
cout << item << "\n"; // apple / banana / cherry
}
3. 참조 (Reference)
참조는 변수의 별명이다.
// 참조 = 변수의 별명
int a = 10;
int &ref = a; // ref는 a의 별명
ref = 20;
cout << a << "\n"; // 20 (a가 바뀜!)4. 포인터 (Pointer)
int a = 10;
int *p = &a; // p는 a의 주소를 저장
cout << p << "\n"; // 0x7fff... (주소)
cout << *p << "\n"; // 10 (역참조: 주소가 가리키는 값)
*p = 20;
cout << a << "\n"; // 20
// 널 포인터
int *q = nullptr; // 아무것도 가리키지 않음