1. 그래프 구현과 탐색 1
(1) 그래프 개념
그래프는 무방향 그래프, 방향 그래프로 나뉜다.
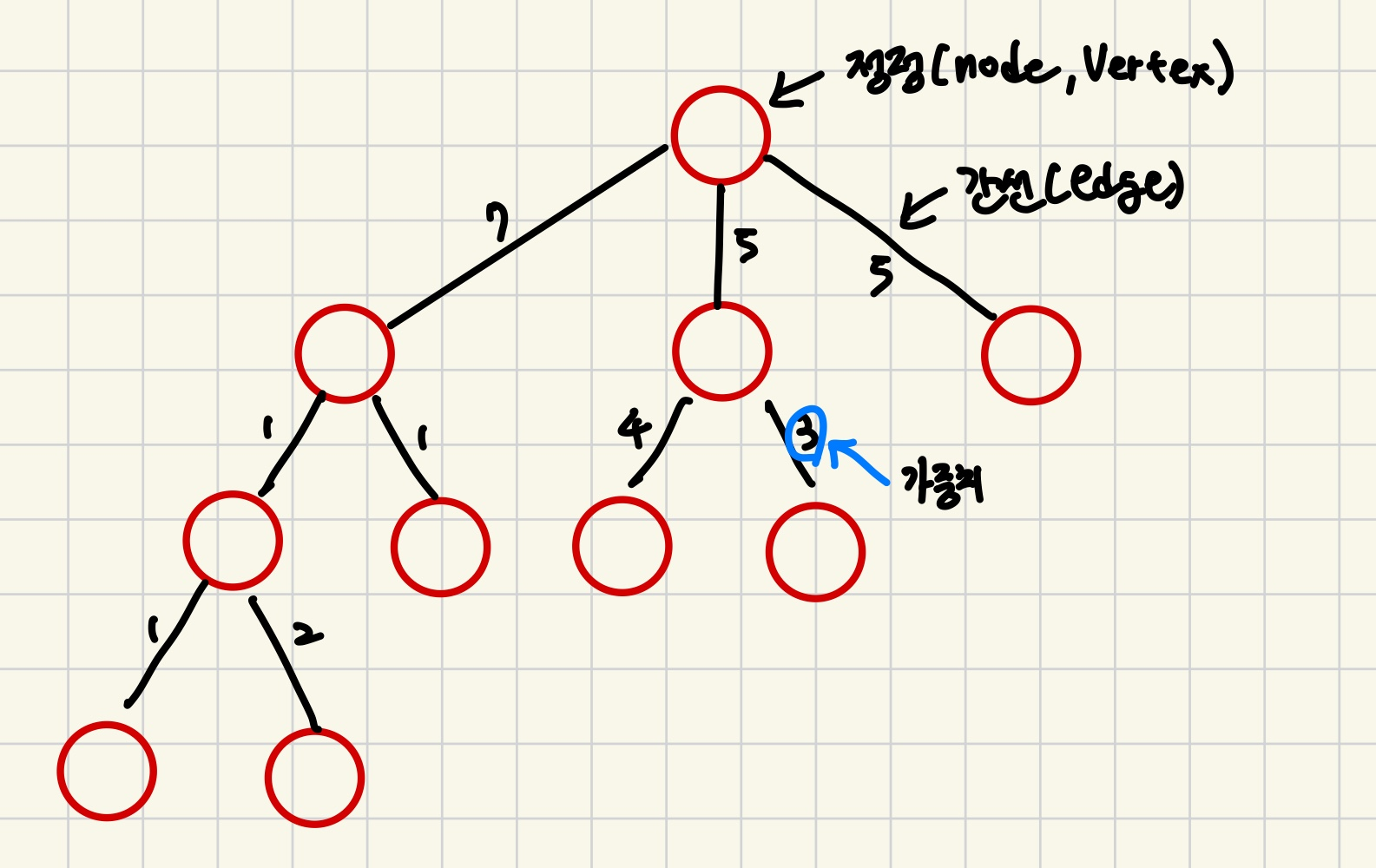
위는 무방향 그래프이다.
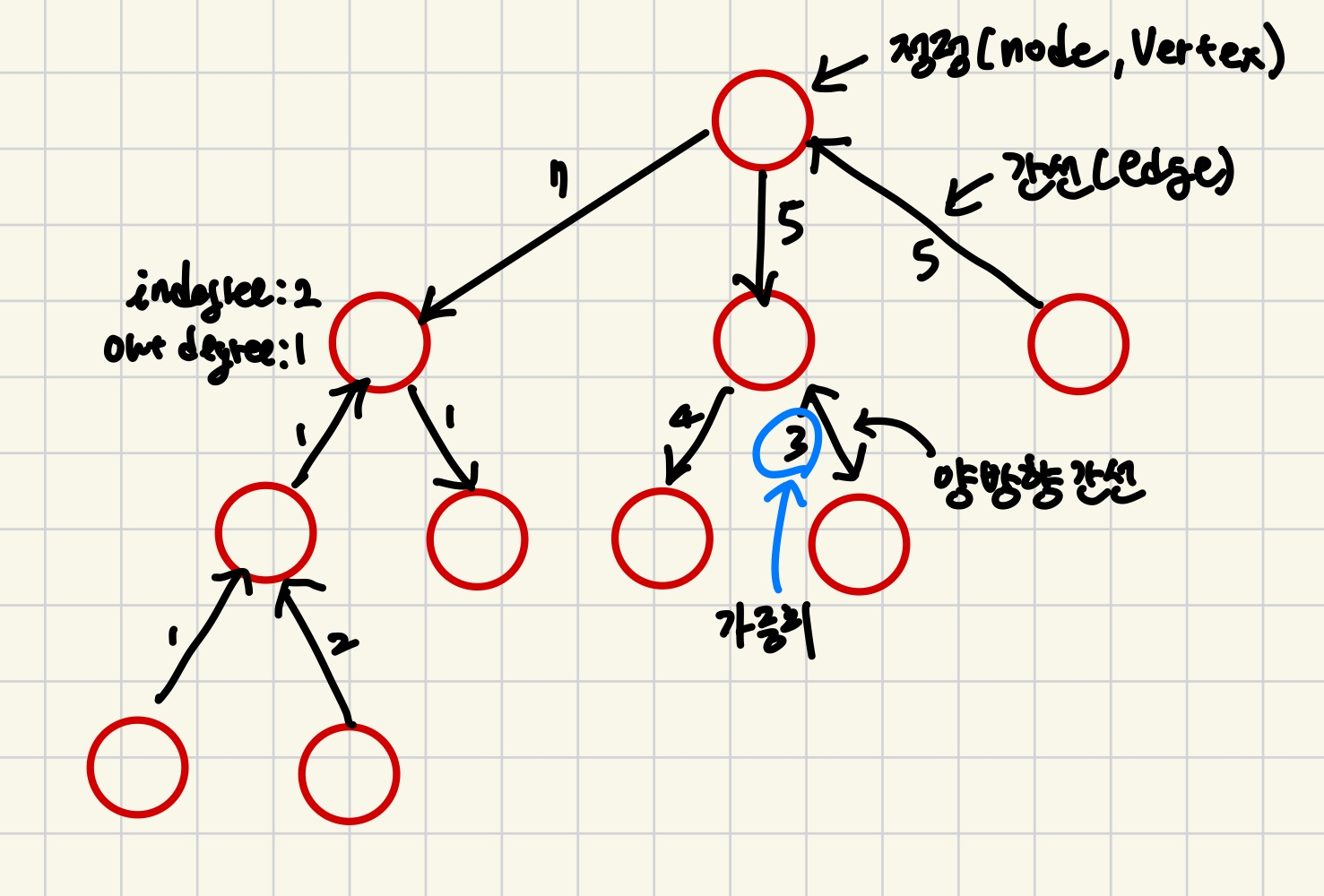
위는 방향 그래프이다.
- indegree : 들어오는 간선의 수
- out degree : 나가는 간선의 수
- 양 방향으로 연결된 간선을
양방향 간선이라고 부른다.
(2) 그래프 구현
그래프는
인접행렬또는인접리스트로 구현할 수 있다.
(맵의 경우는2차원 배열로 구현한다)
🌟 인접 행렬 <--- 2차원 배열로 구현
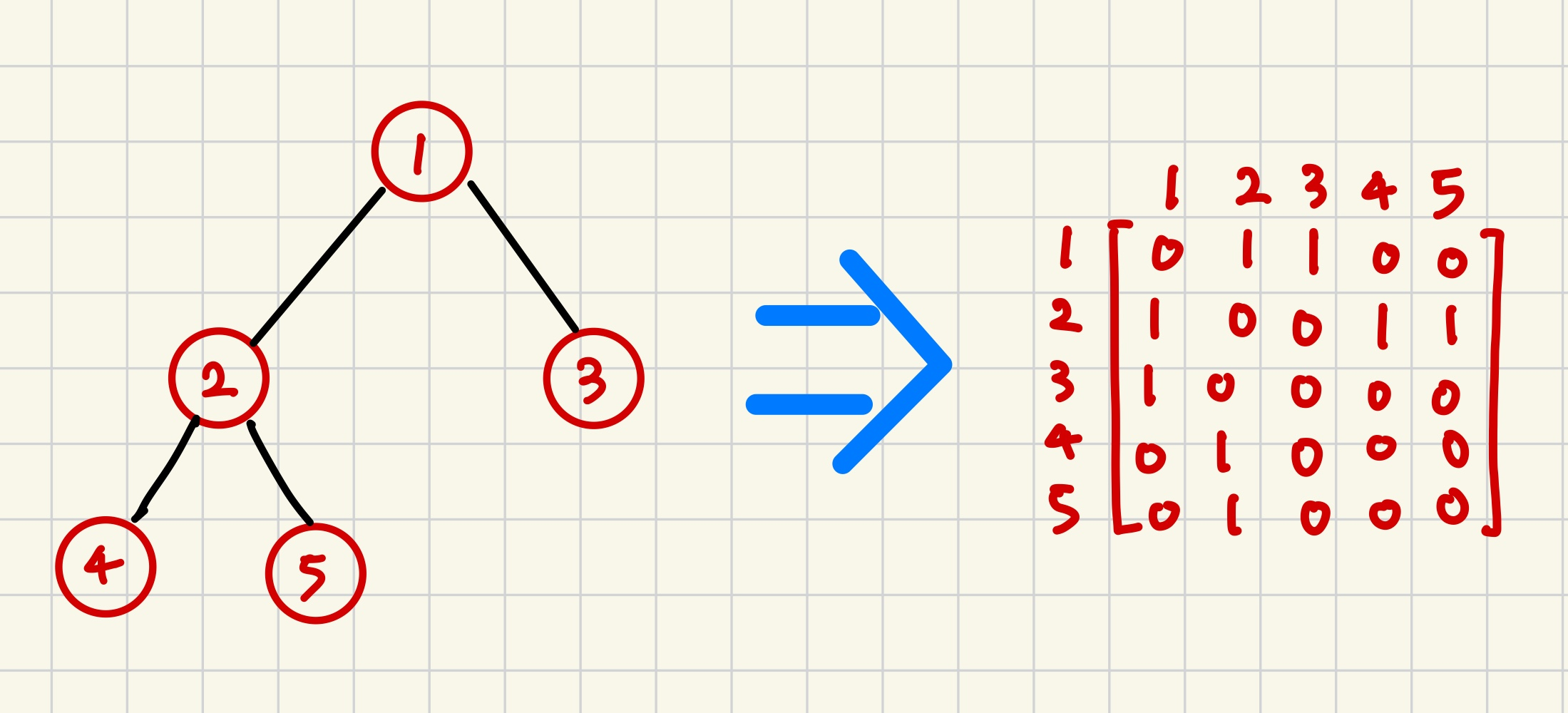
위와같이 2차원 배열 bool a[V][V] 를 만들고, 정점간에 연결 되어있으면 1, 연결 되어있지 않으면 0을 저장해서 그래프를 표현한다.
- 시간복잡도 : 모든 간선 찾기
- V^2 크기의 인접 행렬을 순회하며 값이 1인 애들을 전부 찾아야함
O(V^2)
- 시간복잡도 : a 와 b 사이 간선 한개를 찾을 때
O(1)
- 공간복잡도
- 그래프의 노드가 V개 -> bool a[V][V] 만들어야함 ->
O(V^2)
- 그래프의 노드가 V개 -> bool a[V][V] 만들어야함 ->
🌟 인접 리스트 <--- 1차원 배열에 벡터 넣어서 구현
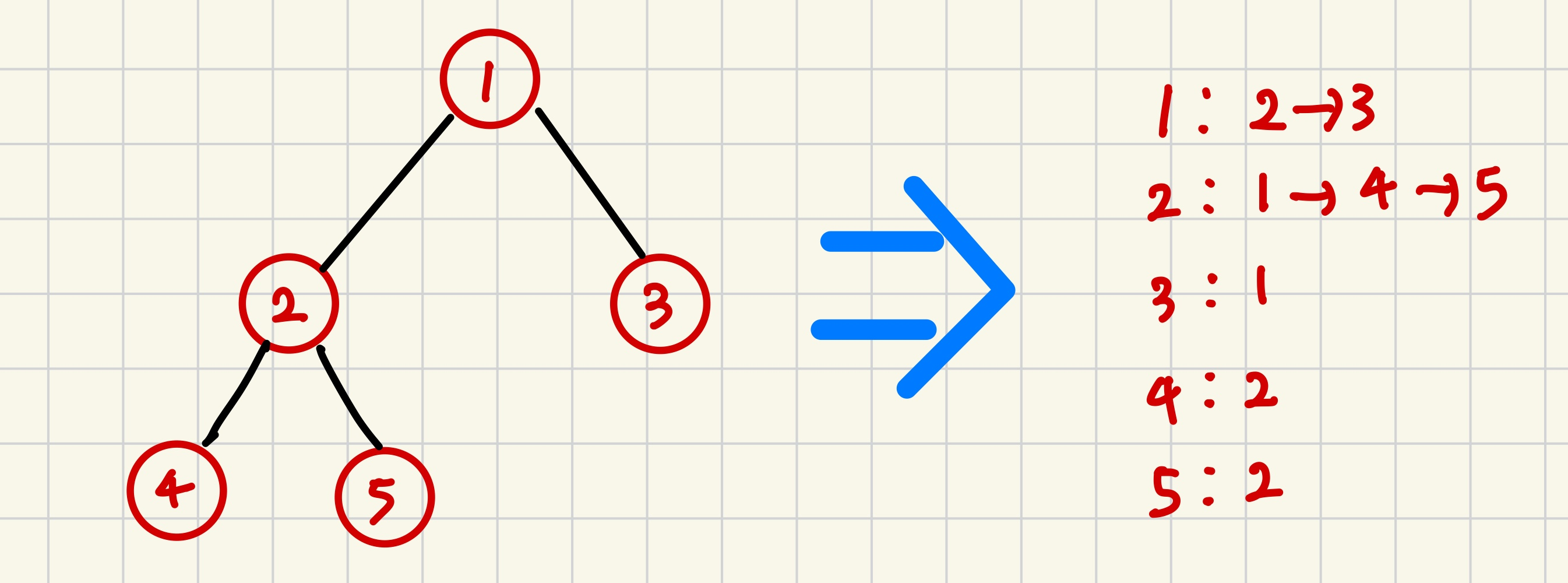
위와 같이 vector<int> a[V] 를 만들고, 연결된 정점들을 벡터의 요소로 저장한다
위의 경우, 1은 2,3과 연결되있으니 첫 번째 벡터는 {2,3}이고,
2는 1,4,5와 연결되있으니 두 번째 벡터는 {1,4,5} 이다.
list a[V] 로 구현해도 상관없으나, vector의 특정 요소 접근의 시간 복잡도가 O(1)로 더 빨라서 보통 vector로 인접 리스트를 구현하는게 효율적이다.
- 시간복잡도 : 모든 간선 찾기
- 인접 리스트를 전부 순회해야함
O(V+E)
- 시간복잡도 : a 와 b 사이 간선 한개를 찾을 때
O(V)
- 공간복잡도
- 그래프의 노드가
V개 ->vector<int> a[V]만들어야함 ->O(V+E)
- 그래프의 노드가
🌟 방문 기록 or 비용 저장 배열
그래프 사용시, 보통
int visited[]배열을 만들어서 방문 여부를 기록하거나 비용을 저장한다.
🌟 그래서 둘 중 뭘 써야하는데??
문제에서 그래프가 sparse한 경우, 인접 리스트를 쓰는 것이 공간복잡도 측면에서 이득이다. 대부분의 문제에서 sparse한 그래프가 나오므로 -> 앵간하면 인접 리스트로 풀되, 문제에서 인접 행렬로 주어지면 인접 행렬로 풀자 (둘 다 할줄알아야한다)
(3) 그래프 탐색
그래프의 특정 지점에서 시작해서 그래프를 돌아다니는 것
방문 처리 -> 인접 행렬 or 인접 리스트 순회하며 재귀 호출 로 구현한다.
인접 행렬 기반 탐색
void go(int from) {
visited[from]=1;
cout << "visited: " << from;
for(int i = 0; i < V; i++) {
if(visited[from][i]) continue;
if(a[from]==1) go(i); //값이 1인 노드는 방문
}
return;
}인접 리스트 기반 탐색
void go(int idx){
cout << idx << '\n';
visited[idx] = 1; //방문 처리
for(int there : adj[idx]){ //인접 리스트의 벡터의 내부 요소를 순회
if(visited[there]) continue;
go(there);
}
return;
}2. 그래프 구현과 탐색 2 : 맵(지도)과 방향벡터
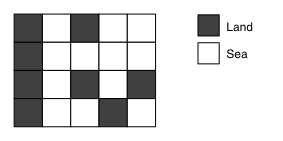
위와 같이 지도가 주어지고, 이를 탐색하는 문제에서는
- 지도(그래프)를
2차원 배열로 구현하고1: 갈 수 있는 지역0: 갈 수 없는 지역
- 가능한
이동 유형에 따른방향 벡터를 정의
해야한다.
(1) 4방향 탐색
상,우,하,좌로 움직일 수 있는 경우
int dy[4] = {1,0,-1,0};
int dx[4] = {0,1,0,-1};
.
.
.
for (int i=0;i<4;i++) {
int ny = y + dy[i];
int nx = x + dx[i];
//...로직
} (2) 8방향 탐색
상,우,하,좌+대각선 4방향으로 움직일 수 있는 경우
(3) ny,nx가 맵의 범위를 벗어나는지 검사
if(ny < 0 || ny >= n || nx < 0 || nx >= n) continue;Runtime Error를 피하기위해 ny,nx가 맵의 범위를 벗어나는지 검사를 해주는 코드를 꼭 넣어줘야한다.
(4) 연결된 컴포넌트
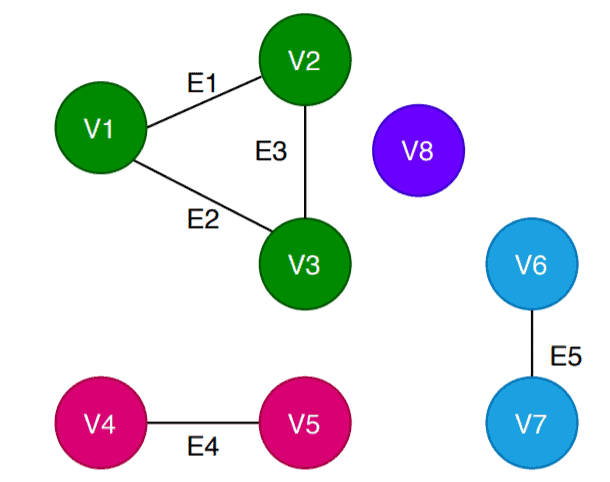
그래프에서
연결된 하나의 덩어리를 의미한다.
(연결된 컴포넌트는 속해있는 모든 정점들을 연결하는 경로가 존재한다)
3. DFS(깊이 우선 탐색, Depth First Search)
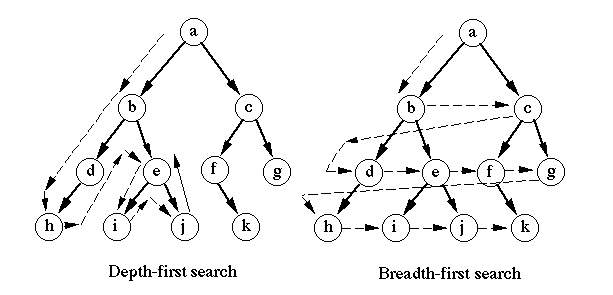
어떤 정점에서 시작해 깊이 우선으로 인접한 정점을 탐색 (한 번 방문한 정점은 재방문 x)
(1) 특징
- 문제에서
"퍼져나간다","탐색한다"이 2글자가 있으면 반드시DFS, BFS떠올려야한다 DFS 한 번 호출시연결된 컴포넌트를 1개 순회한다- 🌟🌟🌟🌟🌟DFS 는
재귀 함수로 구현한다.🌟🌟🌟🌟🌟
(2) DFS 수도 코드
DFS(u, adj)
u.visited = true //방문 처리
for each v ∈ adj[u] //u의 인접 리스트 순회
if v.visited == false //이미 방문됐으면 continue
DFS(v, adj) //DFS 재귀 호출(3) DFS 구현
< 방법 1 >
void DFS(int here){
visited[here] = 1; //방문 처리
for(int there : adj[here]){ //here와 연결된 노드에 접근
if(visited[there]) continue; //이미 방문됐으면 continue
DFS(there); //DFS 재귀 호출
}
}< 방법 2 >
void DFS(int here){
if(visited[here]) return; //이미 방문됐으면 return
visited[here] = 1; //방문 처리
for(int there : adj[here]){ //here의 인접 리스트 순회
DFS(there); //DFS 재귀 호출
}
}4. BFS(넓이 우선 탐색, Breadth First Search)
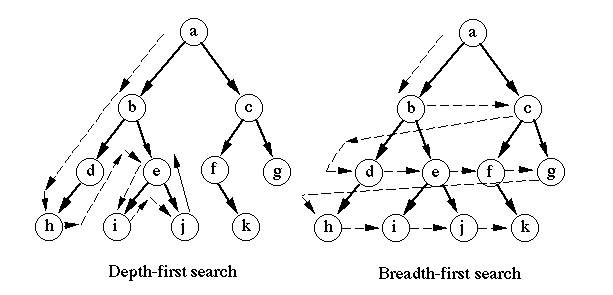
어떤 정점에서 시작해 넓이 우선으로 인접한 정점을 탐색 (한 번 방문한 정점은 재방문X)
(1) 특징
- 문제에서
"퍼져나간다","탐색한다"이 2글자가 있으면 반드시 DFS, BFS 떠올려야한다 - 레벨 i 탐색 완료전까지 레벨 (i+1)로 넘어가지 않는다
BFS 한 번 호출시연결된 컴포넌트를 1개 순회한다가중치가 전부 동일한 그래프에서최단 경로를 찾을 수 있다- 🌟🌟🌟🌟🌟BFS 는
반복문과Queue로 구현한다.🌟🌟🌟🌟🌟
(2) BFS 수도 코드
<방법 1 - 방문처리만 수행하는 경우>
BFS(G, u)
u.visited = true //방문 처리 (처음 1번만 실행)
q.push(u); //Queue에 push (처음 1번만 실행)
while(q.size()) //Queue가 비어있지 않은 동안
u = q.front() //Queue의 front에 접근
q.pop() // Queue를 pop()
for each v ∈ G.Adj[u] // 인자로 전달받은 노드 u의 인접리스트를 순회
if v.visited == false // 방문 되어있지 않으면
v.visited = true //방문 처리
q.push(v) //Queue에 저장<방법 2 - 비용 기반으로 최단거리 구해야하는 경우>
BFS(G, u)
u.visited = true //방문 처리 (처음 1번만 실행)
q.push(u); //Queue에 push (처음 1번만 실행)
while(q.size()) //Queue가 비어있지 않은 동안
u = q.front() //Queue의 front에 접근
q.pop() // Queue의 front를 삭제
for each v ∈ G.Adj[u] // 인자로 전달받은 노드의 인접리스트를 순회
if v.visited == false // 방문 되어있지 않으면
v.visited = u.visited+1 //비용(거리) 저장
q.push(v) //Queue에 저장 (3) BFS 구현 (비용 기반으로 최단거리 구해야하는 경우)
void BFS(int here){
queue<int> q;
visited[here] = 1; //방문 처리
q.push(here); //큐에 삽입
while(q.size()){ //Queue가 비어있지 않은 동안
int here = q.front(); q.pop(); //Queue의 front에 접근 및 삭제
for(int there : adj[here]){ //// 인자로 전달받은 노드의 인접리스트를 순회
if(visited[there]) continue; // 방문 되어있으면 continue
visited[there] = visited[here] + 1; //비용(거리) 업데이트
q.push(there); //Queue에 저장
}
}
}5. DFS와 BFS <--- 사실 상 동일함. 둘 다 그래프 탐색 방법일 뿐임.
- DFS : 메모리 덜 쓰고, 절단점 구할 수 있음. 완전 탐색에서 매우 많이 씀. 코드가 짧음
- 절단점이 뭐지??? <-------------업데이트 필요
- 절단점이 뭐지??? <-------------업데이트 필요
- BFS : 메모리 많이 쓰고 가중치 같은 그래프에서 최단 경로 구할 수 있음. 코드가 김.
퍼져나간다,탐색한다나오면DFS나BFS로 풀이 가능. 앵간하면DFS써라 (코드가 짧다)- 가중치 동일한 그래프에서 최단 경로 구해야하는 경우 ->
BFS사용
6. 트리
(1) 개념
특징
- 자식 노드와 부모 노드로 이루어진 계층적인 구조 (위에 있으면 부모, 아래에 있으면 자식 노드)
- 무방향그래프
- 사이클이 존재하지 않는다
- V - 1 = E (V:정점의 수, E: 간선의 수)
- 임의의 두 노드 사이의 경로가 유일하게 1개 존재함
용어
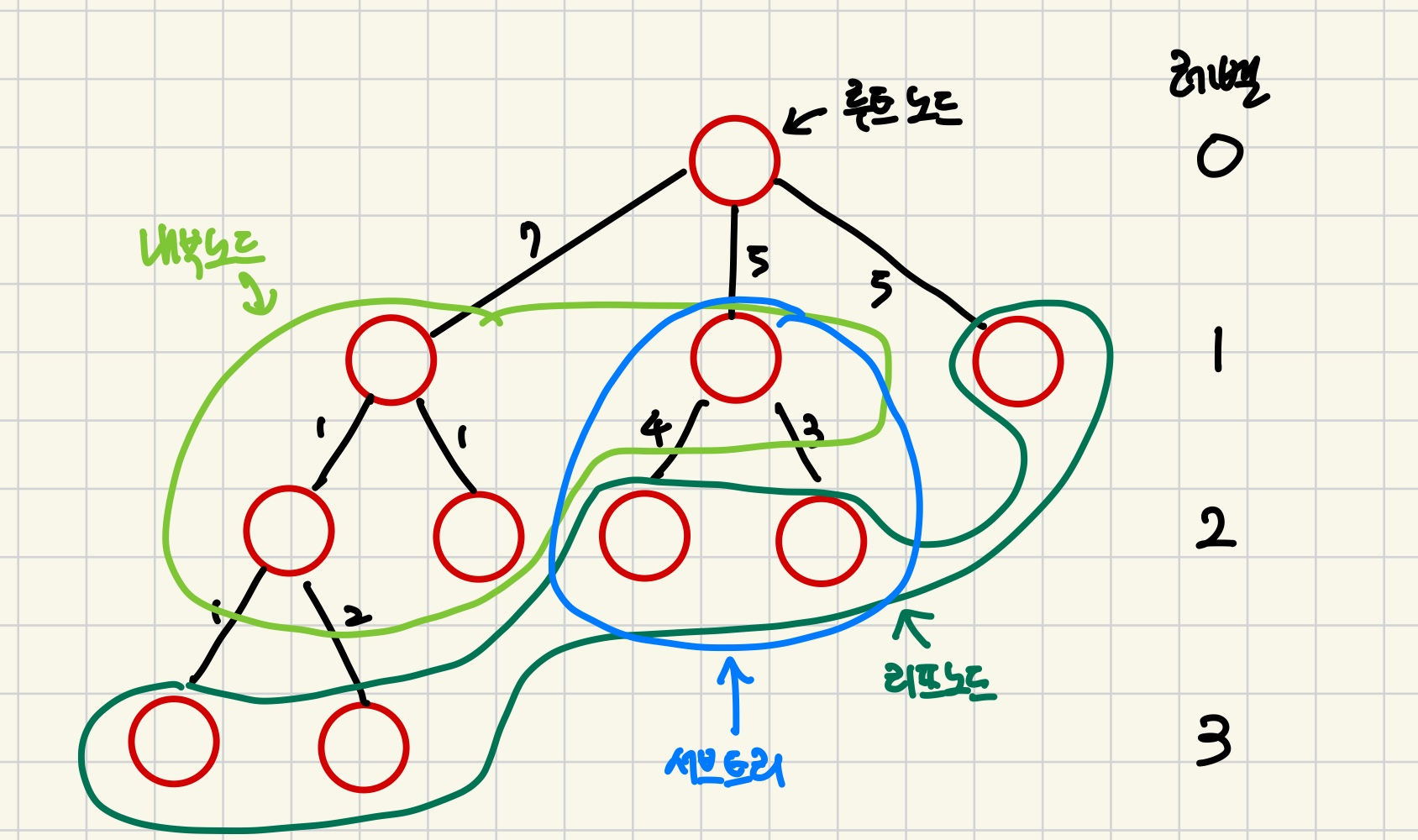
- 루트 노드 : 최상위 노드
- 내부노드 : 루트 노드와 리프 노드 사이의 노드
- 리프 노드 : 자식 노드가 없는 노드
- 깊이 : 루트 노드에서 특정 노드까지 최단거리
- 높이 : 루트 노드부터 리프 노드까지의 거리 중 최장거리
- 서브트리 : 트리내의 부분 집합
(2) 이진 트리
자식 노드의 개수가 최대 2개인 트리
✍ 다양한 이진 트리
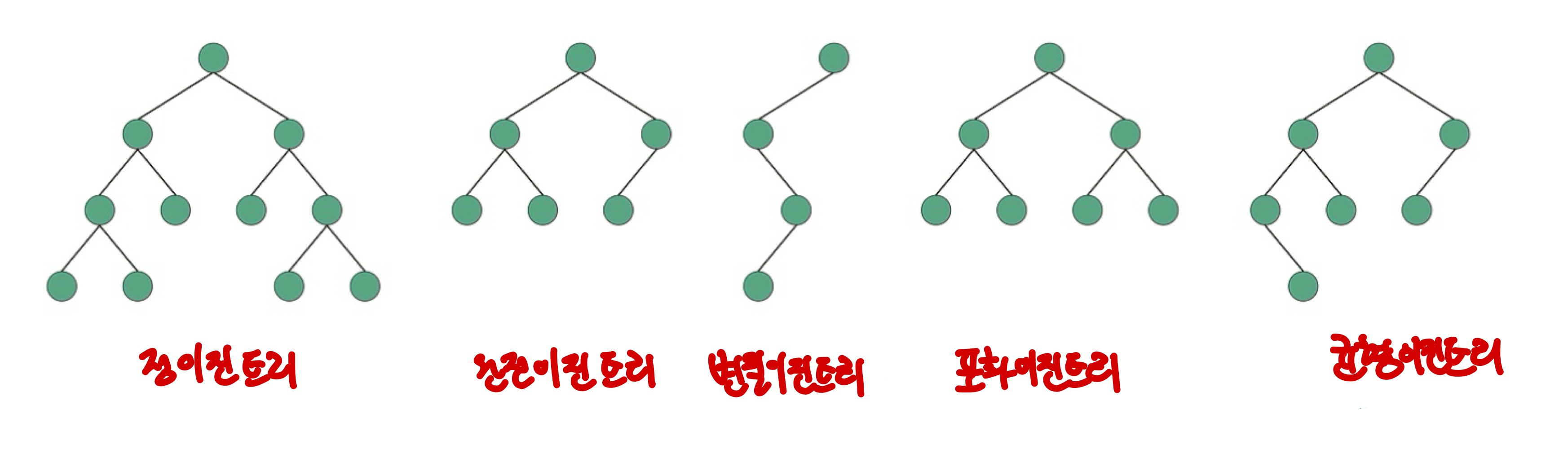
- 정 이진 트리 : 자식 노드의 개수가 0개 아니면 2개인 이진 트리
- 완전 이진 트리 : 왼쪽에서부터 채워져있는 이진 트리 (마지막 레벨 제외하고 모든 레벨이 포화이다)
- 변질 이진 트리 : 리프 노드를 제외하고 모두 자식 노드의 개수가 1개인 이진 트리
- 포화 이진 트리 : 모든 레벨이 꽉 차 있는 이진 트리
- 균형 이진 트리 : 트리의 모든 노드에대해, 왼쪽 서브 트리와 오른쪽 서브 트리의 높이 차이가 1 이하인 이진트리
std::map과std::set이 내부적으로 균형 이진 트리로 구현되어있다.
- 이진 탐색 트리 : 오른쪽 서브 트리에는 노드보다 큰 값이, 왼쪽 서브트리에는 노드보다 작은 값이 들어있다.
✍ 이진 탐색 트리 (BST, Binary Search Tree)
오른쪽 서브 트리에는 노드보다 큰 값이, 왼쪽 서브트리에는 노드보다 작은 값이 들어있다.
- 이미 오른쪽에 더 큰 값이, 왼쪽에 더 작은 값이 있다고 정해져있기에
검색 의 연산량을 줄일 수 있다.
(1) 트리가 균형잡히게 분표된경우 - 탐색, 삽입, 삭제, 수정 모두 O(logN) 이다
만약 트리가 균형잡히게 분표된경우 대략 n = 2^(h+1) 이다.
-> h=log(n) -1 + 최악의 경우 h번 탐색해야 검색한 값을 찾을 수 있음 -> O(h)=O(log(n))
(2) 트리가 선형적으로 분표된경우 - 탐색, 삽입, 삭제, 수정 모두 O(N) 이다
만약 트리가 선형적으로 분표된경우 대략 n = h이다. 이다.
-> 최악의 경우 h번 탐색해야 검색한 값을 찾을 수 있음 -> O(h)=O(n)
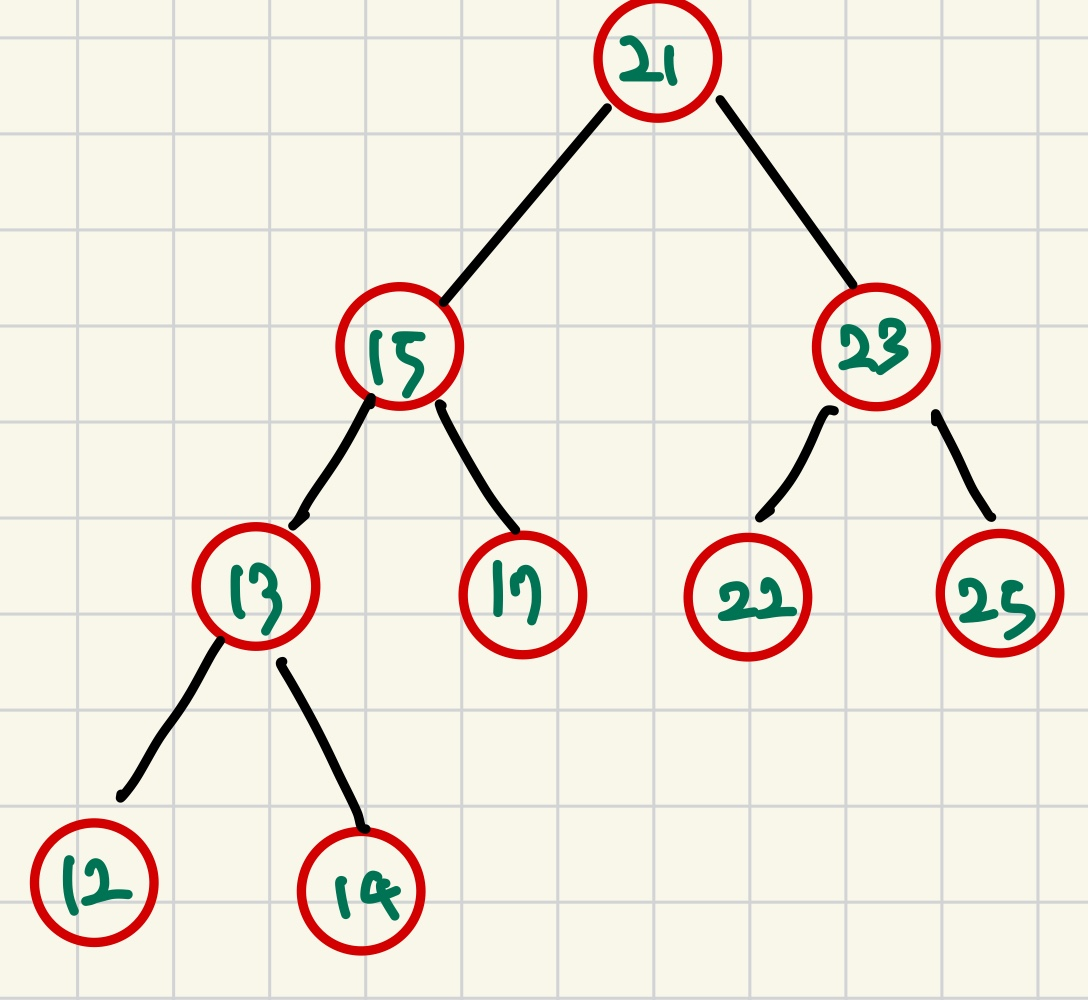
✍ AVL 트리, 레드 블랙 트리
AVL 트리, 레드 블랙 트리는 이진탐색트리에서 발전된 트리로, 탐색, 삽입, 삭제, 수정 모두 O(logN) 이다.
std::map이 레드 블랙 트리로 구현되어있다.
(3) 트리 순회
트리의 각 노드를 한 번씩 방문하는 과정
L,V,R 순서에따라 전위순회(VLR), 중위순회(LVR), 후위순회(LRV)로 나뉜다.
✍ 후위순회(postOrder)
L->R->V순서로 방문하는 것
postorder( node )
if (node.visited == false) //방문 안됐으면
postorder( node->left )
postorder( node->right )
node.visited = true ✍ 전위순회(preOrder)
V->L->R순서로 방문하는 것
preorder( node )
if (node.visited == false) //방문 안됐으면
node.visited = true
preorder( node->left )
preorder( node->right ) ✍ 중위순회(inOrder)
L->V->R순서로 방문하는 것
inorder( node )
if (node.visited == false) //방문 안됐으면
inorder( node->left )
node.visited = true
inorder( node->right ) 7. 실전 암기
(1) BFS로 최단 거리 탐색하는 유형
using namespace std;
int a[104][104], visited[104][104];
int dy[4]={-1,0,1,0};
int dx[4]={0,1,0,-1};
int m,n,ny,nx; //n=행의 수, m = 열의 수
queue<pair<int,int>> q;
void bfs(int y,int x) {
visited[y][x]=1;
q.push({y,x});
while(q.size()) {
tie(y,x)=q.front();
q.pop();
for(int i=0;i<4;i++) {
int ny = y + dy[i];
int nx = x + dx[i];
if(ny >= n || nx >= m || ny < 0 || nx < 0) continue;
if(visited[ny][nx] || !a[ny][nx]) continue;
visited[ny][nx] = visited[y][x] + 1;
q.push({ny,nx});
}
}
}
int main() { //O(2nm)=O(nm)=O(10000)
cin >> n >> m;
for(int i=0;i<n;i++) {
string s;
cin >> s;
for(int j=0;j<m;j++) {
a[i][j]=s[j]-'0';
}
}
bfs(0,0);
cout << visited[n-1][m-1];
return 0;
}위의 코드를 통으로 외워야한다.
- 항상 [0][0] 부터 [n-1][m-1] 을 쓴다
- BFS는 중복 방문 금지하므로 1회 수행시 시간 복잡도는 O(N*M)이다
- BFS(y,x) 1회 수행시 (y,x)가 속한 연결 컴포넌트에 속한 모든 노드를 방문한다.
