1. 해설
뮤탈이 SCV를 공격해서 전부 죽이는데 걸리는 최소 시간을 찾는 문제이다.
시도 1 - 반복문, 재귀 기반 완전 탐색
최악의 경우 몇 번의 공격이 필요할까?
재귀로 구현하는 경우 -> O(6^k) 의 시간 복잡도이다. k는 최악의 경우 21 정도로 예상된다.
-> 무조건 시간 초과
시도 2 - 우선순위 큐
priority_queue 로 풀이해보려했는데 테케로 시뮬레이션 해보니 반례가 존재했다
정답 - BFS
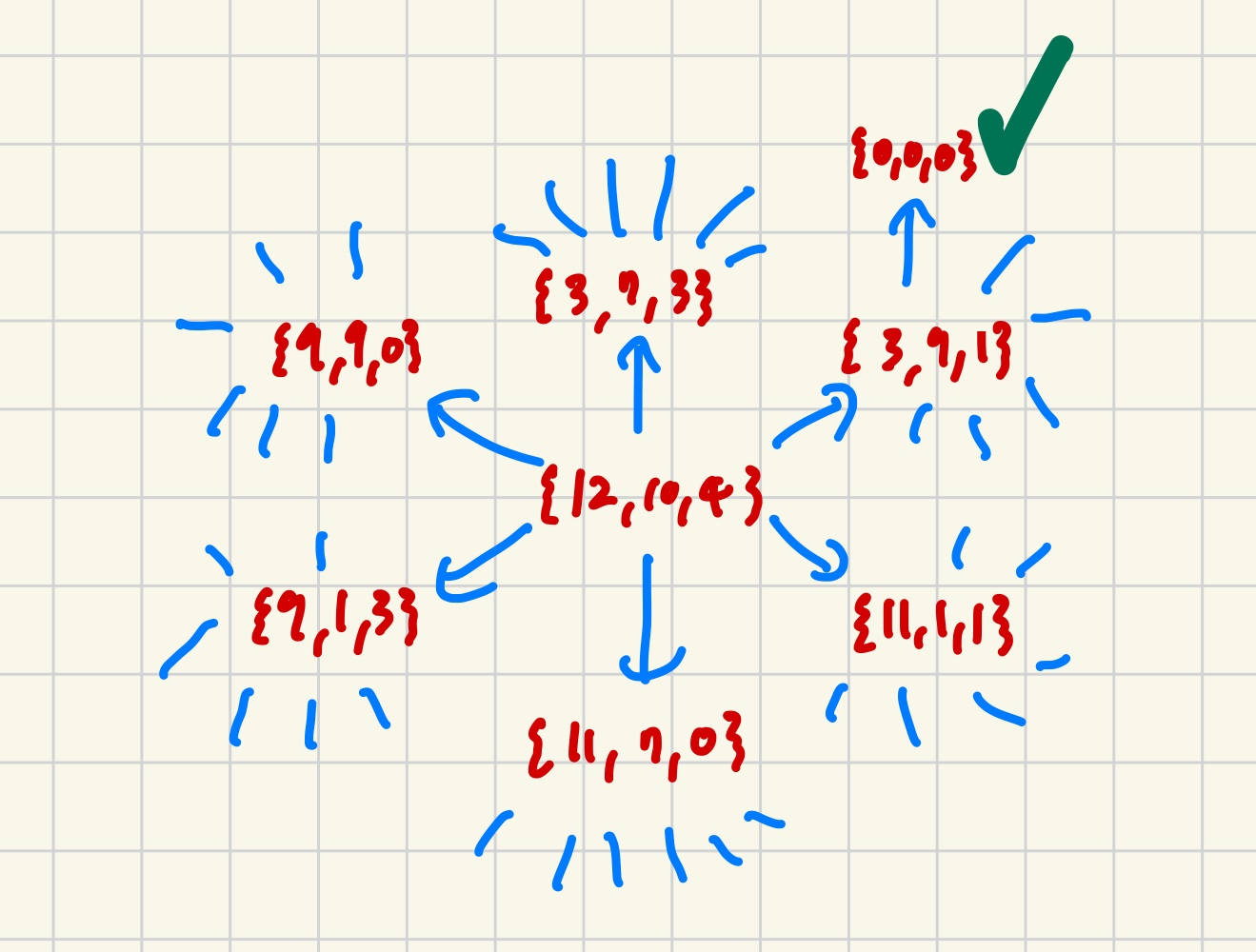
결론적으로 위와같이 BFS로 최단 경로 찾기를 활용해서 가능한 모든 경우의 수를 탐색해야한다.
int visited[64][64][64]; // 3차원 배열의 인덱스를 SCV1,2,3의 체력으로 생각한다.
//9,3,1 을 CSV1,2,3의 체력에서 빼는 경우의 수 총 6개 <--BFS에서 dy, dx에 해당한다고 생각하면된다
int diff[6][3] = {
{9,3,1},
{9,1,3},
{3,9,1},
{3,1,9},
{1,3,9},
{1,9,3}
};
struct A {
int a,b,c;
}; //SCV의 체력을 저장할 구조체로, Queue에 이 구조체를 넣어줄 것이다.
queue<A> q; // bfs 사용할 Queue
int bfs(int a, int b, int c) {
visited[a][b][c]=1;
q.push({a,b,c});
while(q.size()) {
int a1 = q.front().a;
int b1 = q.front().b;
int c1 = q.front().c;
q.pop();
for(int i=0;i<6;i++) {
int na = max(0, a1-diff[i][0]); //na,nb,nc는 인덱스로 사용되므로 0에서 클램핑 해준다
int nb = max(0, b1-diff[i][1]);
int nc = max(0, c1-diff[i][2]);
if(visited[na][nb][nc]) continue; //이미 방문된 지점이면 queue에 들어가있고 6개의 경우의수에대해 자동으로 확인될테니 continue로 무시한다
visited[na][nb][nc] = visited[a1][b1][c1] + 1; //비용업데이트
if(visited[0][0][0]) break; //만약 scv의 체력이 0,0,0 인 지점에 방문되었으면 bfs 종료!
q.push({na,nb,nc});
}
}
return visited[0][0][0]-1; //처음에 visited[a][b][c]를 1로 설정했으니 최종 return값에서는 1을 빼줘야함.
}
위의 방식으로 구현했을때 visited[][][] 로 인해 중복 방문이 제한되므로 시간복잡도는 O(64^3*6) 으로, 약 1570000 정도로 매우 안전하다.
2. 풀이
/*
bfs로 모든 경우의 수에 대해 탐색 수행하자.
그러다가, 0,0,0 도달하면 종료하고 비용 출력
*/
#include <bits/stdc++.h>
using namespace std;
int visited[64][64][64];
struct A {
int a,b,c;
};
int diff[6][3] = {
{9,3,1},
{9,1,3},
{3,9,1},
{3,1,9},
{1,3,9},
{1,9,3}
};
queue<A> q;
int bfs(int a, int b, int c) {
visited[a][b][c]=1;
q.push({a,b,c});
while(q.size()) {
int a1 = q.front().a;
int b1 = q.front().b;
int c1 = q.front().c;
q.pop();
for(int i=0;i<6;i++) {
int na = max(0, a1-diff[i][0]);
int nb = max(0, b1-diff[i][1]);
int nc = max(0, c1-diff[i][2]);
if(visited[na][nb][nc]) continue;
visited[na][nb][nc] = visited[a1][b1][c1] + 1;
if(visited[0][0][0]) break;
q.push({na,nb,nc});
}
}
return visited[0][0][0]-1;
}
int main() {
int n;
cin >> n;
int a[3] = {0,0,0};
for(int i=0;i<n;i++) {
cin >> a[i];
}
cout << bfs(a[0],a[1],a[2]);
return 0;
}3. 오답 노트
(1) BFS로 완전탐색할 수 있구나..!
BFS로 완전탐색을 수행하는 문제를 처음 풀어봤다.
어렴풋이 완전탐색해야할 것 같긴했는데 BFS로 하는건 떠올리지 못했다.
BFS를 활용해서 완전 탐색이 가능하다
(2) BFS 기반 완전 탐색 -> 시간복잡도 감소
BFS기반으로 완전 탐색하면 반복, 재귀 기반 완전 탐색과 달리 visited 배열이 존재해서 중복 방문이 없다.
시간 복잡도가 그래프(맵)의 크기로 제한되는 효과가 있다.
완탐이 시간복잡도 빡세면 bfs기반 완탐으로 접근해보자.
(3) 최소 비용, 최단 거리, 최소 시간 ---> BFS 기반 최소 비용 찾기 알고리즘
이 문제도 결국은 최소 비용(시간)을 찾는 문제이다.
따라서 BFS로 접근하는 것을 떠올려야한다

안녕하세요. 전자공학부 학부생의 공부 기록입니다.