단어를 입력받아서 단어를 이루는 크로아티아 알파벳의 갯수를 카운트하는 문제이다.
주의해야할 점은
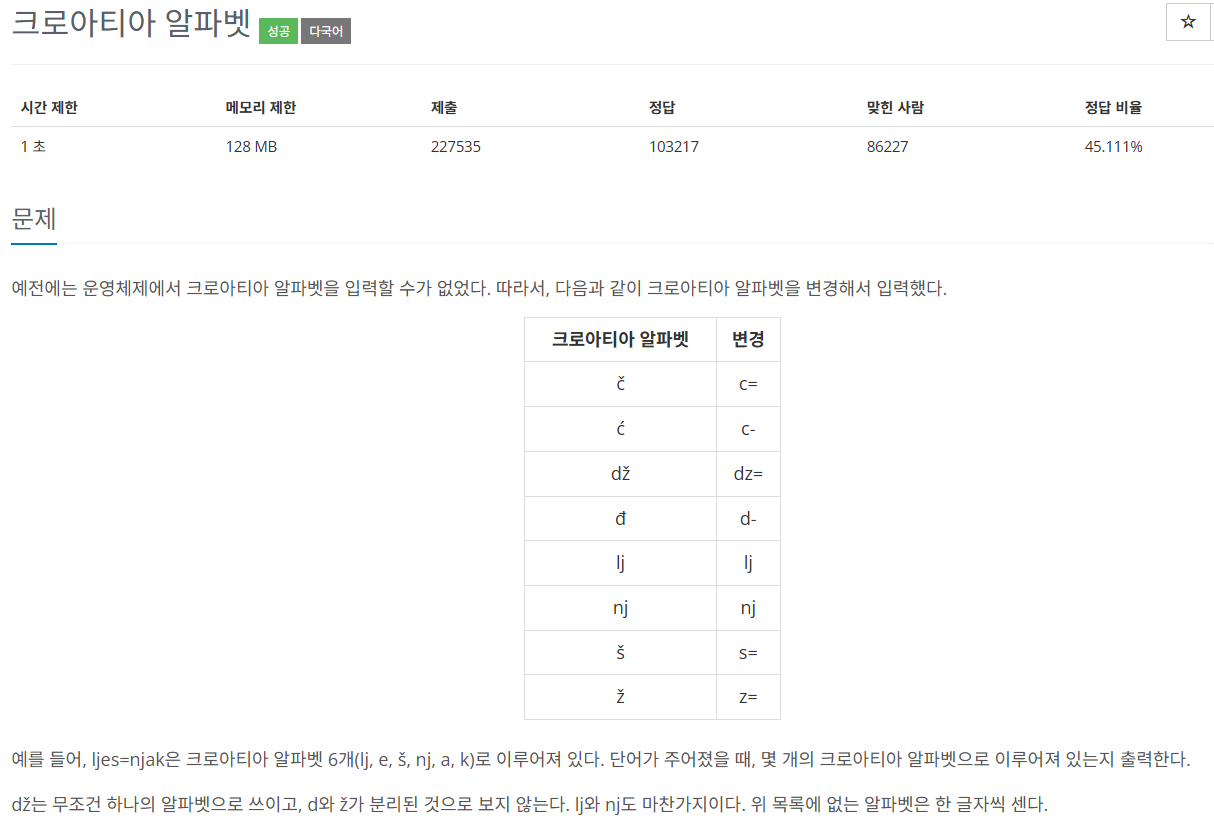
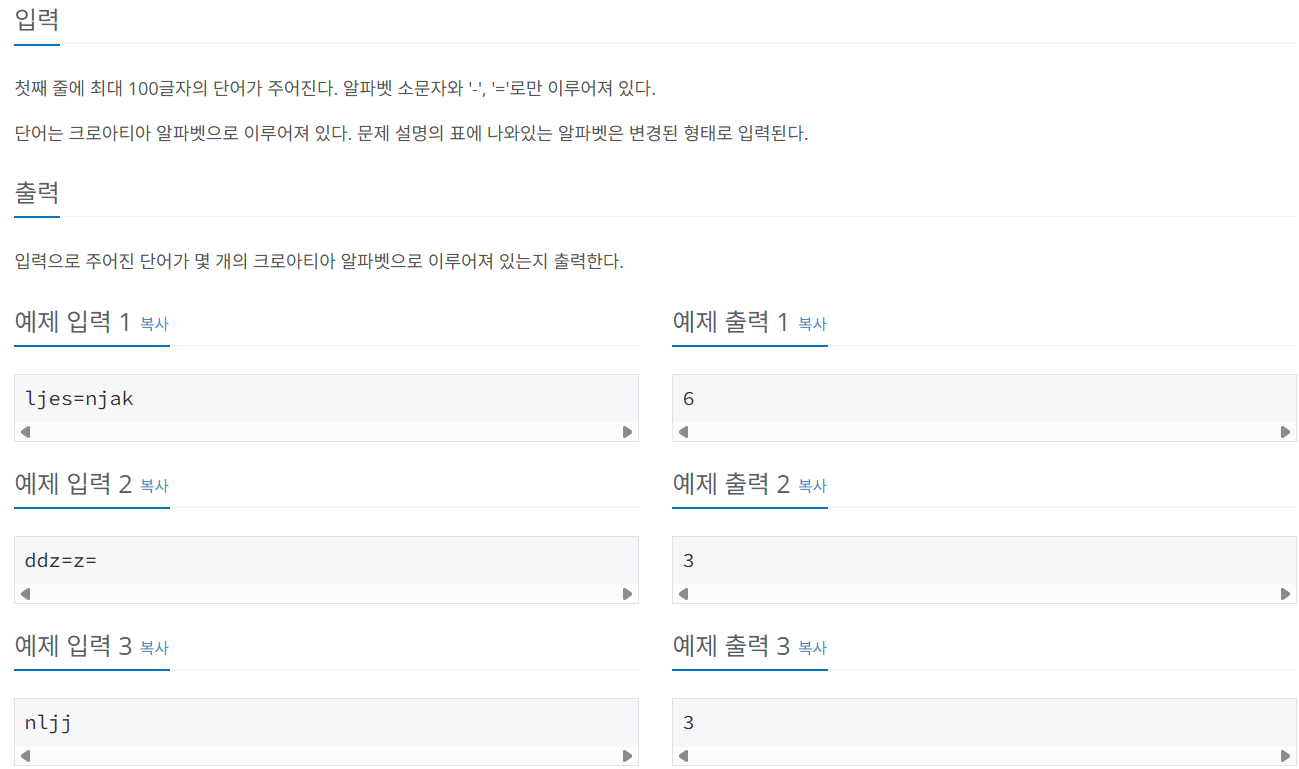
(1) 크로아티아 알파벳이 중복으로 있을 수 있다.
는 것이다.
1. 나의 풀이
#include <iostream>
#include <string>
using namespace std;
string arr[8]={"c=", "c-", "dz=", "d-", "lj", "nj", "s=", "z="};
int main() {
ios_base::sync_with_stdio(false);
cin.tie(0);
string s;
cin >> s;
for(int i=0;i<8;i++) {
if(s.find(arr[i])!=string::npos) {
s.replace(s.find(arr[i]), arr[i].size(), "0");
i--;
}
}
cout << s.size();
return 0;
}우선 크로아티아 알파벳으로 인식되는 문자열을 배열에 저장해둔다.
이후, 입력값을 받아서 s.find(s1)으로 배열에 있는 문자열이 입력 받은 문자열에 존재하는지 확인한다.
만약 존재한다면 -> s.replace(pos,len,s1) 을 사용해 문자열 하나로 치환시켜버린다.
이때 중요한것이, 입력받은 문자열에는 동일한 크로아티아 알파벳이 2개이상 존재할 수 있다. 따라서 i--를 통해 방금 확인한 문자열이 입력받은 문자열에 또 존재하는지 확인해줘야한다.
(s.find(s1)이 string::npos를 반환할때까지 반복)
이렇게 크로아티안 알파벳을 이루는 문자가 2개,3개인 아이들에 대한 처리가 끝나면 , 현재 입력 문자열에 남아있는 문자들은 전부 1개가 하나의 크로아티안 문자이다.
따라서 입력받은 문자열을 카운트하면 정답이다.
2. 다른 풀이
#include <iostream>
using namespace std;
int main() {
string s;
cin >> s;
int ans = 0, i = 0;
while (i < s.length()) {
if (s[i] == 'c') {
if (s[i + 1] == '=')
i++;
else if (s[i + 1] == '-')
i++;
}
else if (s[i] == 'd') {
if (s[i + 1] == '-')
i++;
else if (s[i + 1] == 'z' && s[i + 2] == '=')
i += 2;
}
else if (s[i] == 'l') {
if (s[i + 1] == 'j')
i++;
}
else if (s[i] == 'n') {
if (s[i + 1] == 'j')
i++;
}
else if (s[i] == 's') {
if (s[i + 1] == '=')
i++;
}
else if (s[i] == 'z') {
if (s[i + 1] == '=')
i++;
}
ans++;
i++;
}
cout << ans;
}위와 같이 모든 경우의수에 대해서 전부 분기처리하는 방법도 존재한다.
사실 이 방법이 가장 직관적인 방법인듯하다.
다음에 비슷한 문제가 출제되었을때, 해법이 잘 떠오르지않으면 마지막에 이렇게 푸는 방법도 고려해봐야겠다.
3. 헷갈렸던 것
(1) char -> string 의 암시적 형 변환
string arr[8]={"c=", "c-", "dz=", "d-", "lj", "nj", "s=", "z="};나는 이 코드를 작성하며,
"어, 근데
"~"리터럴은char[]인데std::string배열에 넣어도될까?"
- 참고로, 우리가 쓰는
string은std::string인데 우리가using namespace std;를 통해 이때까지 줄여서 써온 것이다.
하는 의문이 들었지만, 일단 이렇게 작성했다..운좋게 맞은 것 같다.
이에대해 알아보니, string 배열에 char[]를 넣으면, char[]->std::string으로 암시적 형 변환 이 일어난다고한다.
다음부터는 이런 문법적 근거를 확실히 가지고 문제를 풀어나갈 수 있도록 해야겠다.
(2) s.find(s1)의 반환값 : string::npos
s.find(s1)은 s에 s1이 없을 경우, string::npos를 반환한다.
근데 어디선가, 다른 사람의 코드중에서 s에 s1이 없을 경우 -1과 비교해서 이를 처리하는 것을 본 기억이 떠올랐다.
그래서 나도 처음에는 (int)s.find(s1)!=-1 이런식으로 비교를 했었다.
이렇게 해도 정답은 맞게 나왔지만, 코드의 가시성을 위하여 다음부터는 string::npos 를 활용해야겟다. (위에 올려둔 나의 풀이는 이를 반영하여 수정한 버전이다)
또한, 대부분의 사람들이 string::npos를 쓰던데, 다들 그렇게 쓰는 이유가 있지 않을까싶다.
4. 느낀 점
이렇게 특이 케이스에 대해 배열에 저장해두고 순회하며 검사하는 문제들을 앞에서 봤던 기억이 있다.
이렇게 문제를 풀고 인상적인 문제들에 대하여 블로그에 정리하니까 확실히 기억에 더욱 잘 남는것같다.
블로그 기록을 계속해서 습관화해야겠다.
아! 그리고 처음 풀어본 백준의 실버 문제이다. 뿌듯 ㅎ.ㅎ
