
💡 양자화란?
양자화는 모델의 가중치와 활성화를 고정밀도 데이터 표현(F32)에서 저정밀도 데이터 표현으로 변환하는 모델 압축 기술
쉽게 말해 복잡한 정보를 저장할 수 있는 데이터 유형에서 더 적은 정보를 저장하는 데이터 유형으로 변환하는 것을 의미합니다.
양자화 과정은 기본적으로 고정밀도 값을 저장하는 가중치를 낮은 정밀도 데이터 유형으로 매핑하는 것입니다. 예를 들어 FP32 값 범위의 [최소, 최대]를 INT4 공간으로 매핑한다고 생각해보죠. 이를 위해 FP32 값 범위의 [최소, 최대]를 찾아야 하는데, 이 과정에서 작은 보정 데이터 집합을 사용하여 모델을 보정하게 됩니다. 그런 다음 가장 작은 값과 가장 큰 값으로 설정하여 범위를 결정하고 해당 범위를 벗어나는 모든 값은 "클립"됩니다.
그러나 이런 방식은 이상치가 스케일링에 과도한 영향을 미칠 수 있다는 문제로 이어집니다. 이 문제를 해결하기 위해 가중치는 값에 따라 그룹으로 나누어지고 각 그룹은 개별적으로 양자화됩니다. 이렇게하면 이상치의 영향을 줄이고 정밀도를 높일 수 있습니다.
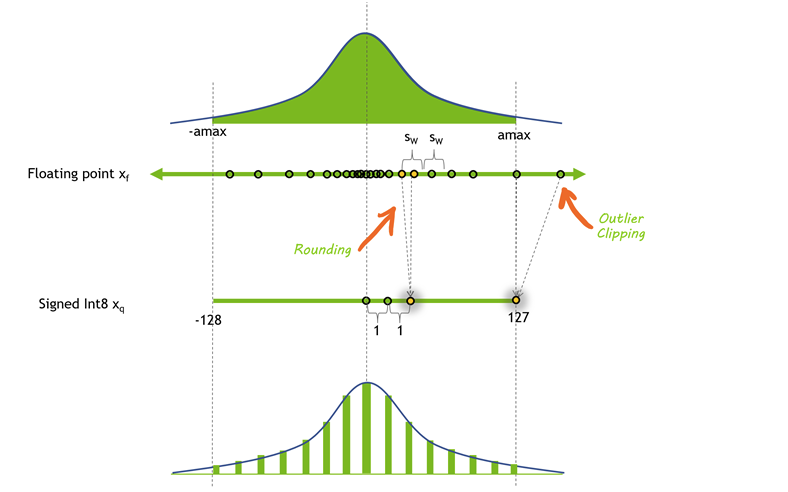
그림으로 이해가 잘 안 가신다면 제가 참고한 유튜브 영상을 추천드립니다. 이 외로도 그냥 llm quantization이라고 치면 많이 나옵니다.
양자화는 머신러닝에서 중요한 과정입니다. 모델의 가중치에 필요한 비트 수를 줄이면 모델의 전체 크기가 상당히 감소합니다. 결과적으로 양자화된 모델은 더 적은 메모리를 사용하고 더 적은 저장 공간이 필요하며, 더 에너지 효율적이며 빠른 추론이 가능해집니다. 이로써 LLM을 더 다양한 장치에서 실행할 수 있게 됩니다.
양자화의 개념에 관한 더 자세한 정보는 [엔비디아] LLM 기술 마스터하기: 인퍼런스 최적화 (2023년 11월 27일)을 확인하세요!
✌🏻 양자화의 두 가지 유형: PTQ, QAT
양자화 기술에는 여러 가지 있지만 일반적으로 LLM 양자화는 두 가지 범주로 나눌 수 있습니다.
1. 훈련 후 양자화(PTQ)
이미 훈련된 LLM을 양자화하는 기술을 의미합니다. PTQ는 QAT보다 구현하기 쉽지만, 가중치 값의 정밀도 손실로 인해 모델 정확도가 감소할 수 있습니다.
2. 양자화 관련 훈련(QAT)
양자화를 고려하여 데이터를 사용하여 모델을 세밀하게 조정하는 방법입니다. QAT는 보통 PTQ 기술보다 우수한 모델 성능을 제공하지만, 더 많은 계산이 필요합니다.
양자화의 장단점
✅ 장점
- 모델 크기의 감소
- 스케일 가능성의 증가
- 더 빠른 추론
❎ 단점
- 정확도 손실: 정밀도 손실이 발생할 수 있으며, 양자화가 더 "적극적"일수록(예: 4비트, 3비트 등) 정확도 손실이 커집니다.
💚 최근까지 소개된 양자화 방식
제가 느끼기로는 메타에서 LLaMA를 오픈소스로 공개한 뒤, 이 양자화 관련 연구들이 매우 활발해진 듯 합니다.
이런 방법론은 시간이 지남에 따라 더 많은 것이 나오기 마련이니, 'LLM quantization survey'라고 검색해 나오는 논문을 참고하시는 등의 방법으로 항상 최신의 방식을 트래킹해보시길 바랍니다.
23년에 나온 A Survey on Model Compression for Large Language Models은 이렇게나 다양한 방법을 소개합니다. 그중 우리가 관심 있는 것은 딱 Quantization 파트인 거고, 그 외로도 모델 압축에서 관심 있는 부분을 서치해보시기 좋은 시작점이 될 듯 합니다. 또 각 방법에 대해서 이론적으로 빠르게 훑을 수 있어 좋았습니다.
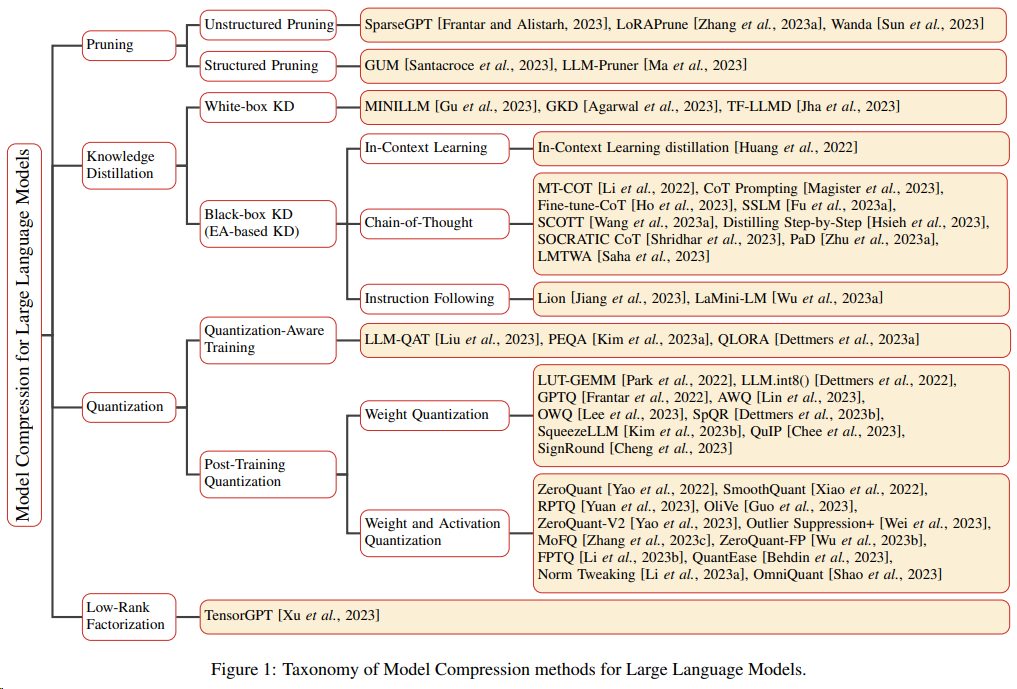
양자화와 관련해서는 이런 툴들을 소개하고 있습니다.
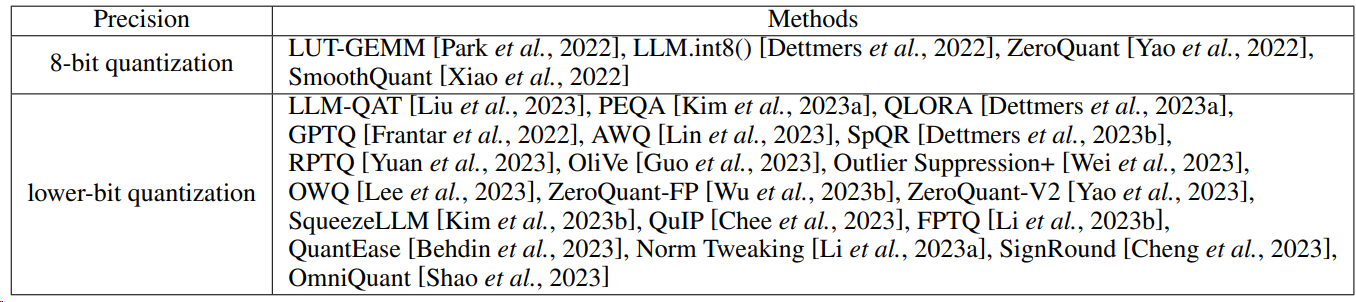
그러나 아시다시피, 논문에서 소개하는 최신 기술, SOTA가 늘 실전에서도 유용한 건 아닙니다. 밴치마크라는 게 그리 믿을만하지 못하더군요..
아래에 소개드리는 방법들은 자주! 사용되는 방법들입니다.
LoRA
양자화에 대해 알아보셨다면 가장 많이 접해보셨을 건 바로 'LoRA'입니다. LoRA(Low-Rank Adaptation)는 가중치를 동결하고, 어댑터라고 하는 추가 가중치의 작은 세트를 미세 조정하여 기본 LLM을 추가로 훈련하는 메모리 요구 사항을 줄이는 PEFT(Parameter-Efficient Fine-Tuning) 기법입니다. 아래 그림을 정말 많이 보셨을 텐데요. 이론에 대한 설명은 이 페이지에서 정말 잘 설명해주셨습니다. 논문과 함께 보시면 이해가 더 잘 될 듯 합니다.
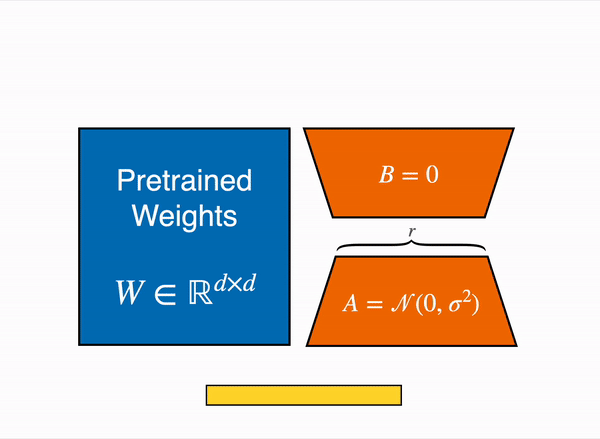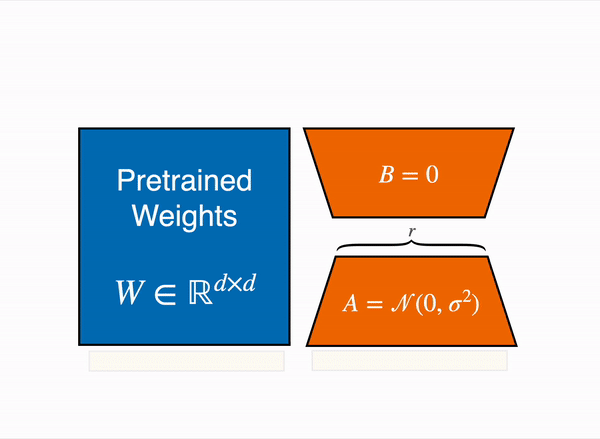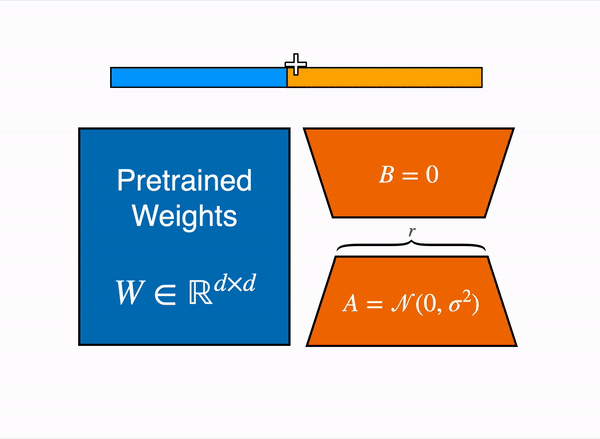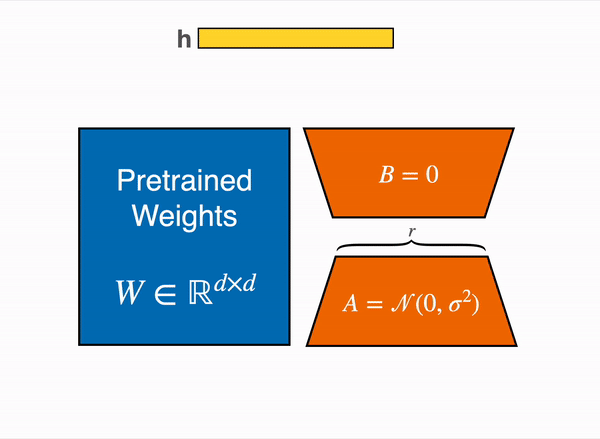
위에 소개드린 페이지를 읽고 궁금하실만한 점은, A와 B를 왜 저걸로 초기화시키는가? 일지도 모릅니다. 일단 0이 가장 적은 메모리를 차지하며 간단하니까 B를 0으로 설정하고, A도 0이면 가중치 업데이트가 안 될 테니 간단한 정규분포를 따르게 했다고 저는 생각했습니다. 다른 생각이 있으신 분은 댓글 부탁드립니다.
QLoRA
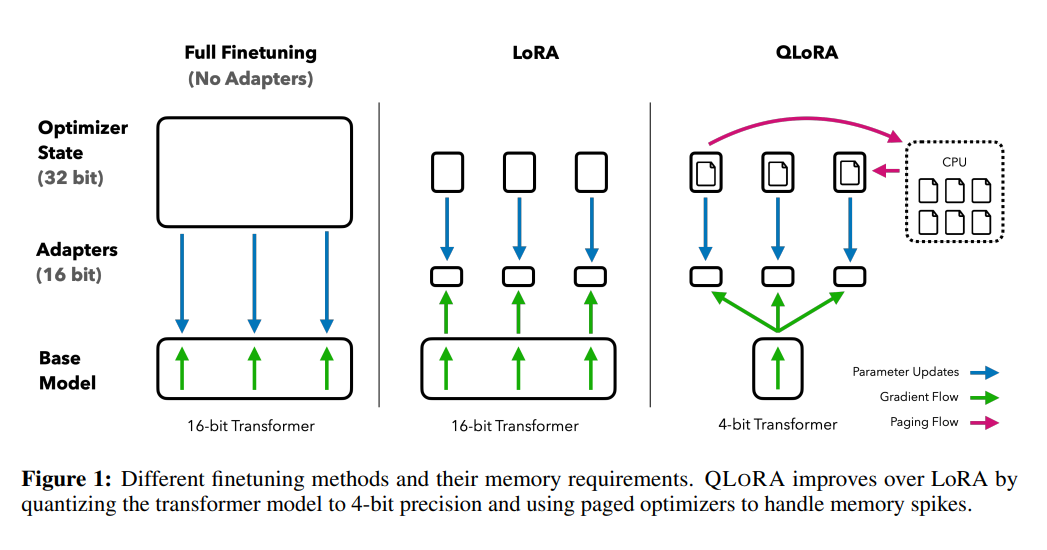
QLoRA(양자화된 저순위 적응)는 기본 LLM 내의 원래 가중치를 4비트로 양자화하여 LLM의 메모리 요구 사항을 줄여 단일 GPU에서 실행할 수 있도록 함으로써 한 단계 더 발전했습니다.
QLoRA는 4비트 NF4(NormalFloat) 데이터 유형과 이중 양자화라는 두 가지 핵심 메커니즘을 통해 양자화를 수행합니다.
1. NF4
기계 학습에 사용되는 4비트 데이터 유형으로, 기존의 4비트 부동소수점에 비해 낮은 정밀도의 가중치 값을 더 정확하게 표현하기 위해 각 가중치를 -1과 1 사이의 값으로 정규화합니다. 그러나 NF4가 양자화된 가중치를 저장하는 데 사용되는 반면 QLORA는 또한 기계 학습 목적으로 특별히 설계된 추가 데이터 유형인 Bfloat16(Brainfloat16)을 사용하여 순전파와 역전파 계산을 수행합니다.
2. DQ(Double Quantization)
추가적인 메모리 절약을 위해 양자화 상수를 양자화하는 과정입니다. QLoRA는 가중치를 64개 블록으로 양자화하고, 이를 통해 정확한 4비트 양자화를 용이하게 하지만 각 블록의 스케일링 인자도 고려해야 합니다.
DQ는 각 블록의 스케일링 인자에 대해 두 번째 양자화를 수행함으로써 이 문제를 해결합니다. 32비트 스케일링 인자는 256개 블록으로 컴파일되고 8비트로 양자화됩니다. 따라서 이전에 각 블록의 32비트 스케일링 인자가 가중치당 0.5비트를 추가했다면 DQ는 이 값을 0.127비트로 낮춥니다. 예를 들어 65B LLM에서 결합하면 3GB의 메모리가 절약됩니다.
PRILoRA
프루닝 및 순위 상승 저순위 적응(Pruned and Rank-Increasing Low-Rank Adaptation: PRILoRA)은 24년 1월 제안된 파인튜닝 기법으로, rank들의 선형 분포와 지속적인 중요도 기반 A 가중치 프루닝이라는 두 가지 추가 메커니즘을 도입하여 LoRA 효율성을 높이는 것을 목표로 합니다.
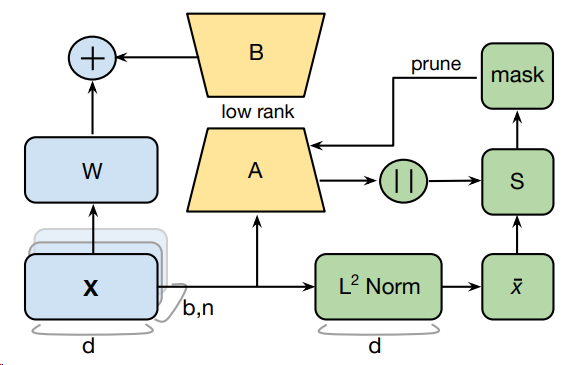
1. low-rank decomposition
LoRA의 파인튜닝을 복기해봅시다. 모델의 전체 가중치를 포함하는 W와 추가 가중치, 즉 어댑터를 훈련하여 모델에 대한 모든 변경 사항을 나타내는 AB의 두 행렬을 결합합니다. AB 행렬은 낮은 랭크의 두 개의 작은 행렬인 A와 B로 분해될 수 있으므로 low-rank decomposition라는 용어가 있습니다. 그러나 낮은 랭크 r은 LoRA의 모든 LLM 계층에서 동일하지만 PRILoRA는 각 계층에 대해 선형적으로 랭크를 증가시킵니다. 예를 들어, PRILoRA를 개발한 연구원은 로 시작하여 최종 계층에 대해 까지 랭크를 늘려 모든 계층에서 평균 8의 랭크를 생성했습니다.
2. pruning on the A matrix
PRILoRA는 A 행렬에 대해 가지치기를 수행하여 파인튜닝 프로세스 전반에 걸쳐 40단계마다 가장 낮은 가중치, 즉 가장 낮은 가중치를 제거합니다.
가장 낮은 가중치는 가중치의 일시적 크기와 각 계층의 입력과 관련된 수집된 통계를 모두 저장하는 중요도 행렬을 사용하여 결정됩니다. 이러한 방식으로 A 행렬을 가지치기하면 처리해야 하는 가중치의 수가 줄어들어 LLM을 미세 조정하는 데 필요한 시간과 파인튜닝된 모델의 메모리 요구 사항이 모두 줄어듭니다.
GPTQ
GPTQ(General Pre-Trained Transformer Quantization)는 모델의 크기를 줄여 단일 GPU에서 실행할 수 있도록 설계된 양자화 기법입니다. GPTQ는 출력 오류를 최소화하는 양자화된 가중치(MSE(평균 제곱 오차)를 발견하는 것을 목표로 한 번에 모델을 한 층씩 양자화하는 접근 방식인 레이어별 양자화를 통해 작동합니다
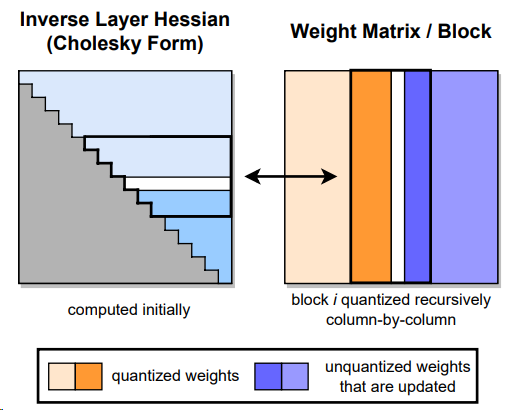
먼저 모델의 모든 가중치는 행렬로 변환되며, 이는 레이지 배치 업데이트(lazy batch update)라는 프로세스를 통해 한 번에 128개 열의 배치로 작업됩니다. 여기에는 배치로 가중치를 양자화하고 MSE를 계산하며 가중치를 감소시키는 값으로 업데이트하는 작업이 포함됩니다. 보정 배치를 처리한 후 행렬의 나머지 모든 가중치는 초기 배치의 MSE에 따라 업데이트되며, 그런 다음 모든 개별 레이어를 다시 결합하여 양자화된 모델을 생성합니다.
GPTQ는 가중치를 양자화하기 위해 4비트 정수를 사용하고 활성화는 더 높은 정밀도의 float16 데이터 유형에 유지되는 혼합 INT4/FP16 양자화 방법을 사용합니다. 이어서 추론하는 동안 모델의 가중치는 실시간으로 역양자화되므로 계산은 float16에서 수행됩니다.
GGML/GGUF
GGML
GGML(Georgi Gerganov Machine Learning, GPT-Generated Model Language의 약자)은 CPU에서 실행할 수 있도록 라마 모델의 양자화를 위해 설계된 C 기반 기계 학습 라이브러리입니다. 더 구체적으로, 라이브러리를 사용하면 양자화된 모델을 GGML 이진 형식으로 저장할 수 있으며, 이는 더 넓은 범위의 하드웨어에서 실행할 수 있습니다.
GGML은 k-quant 시스템이라는 프로세스를 통해 모델을 양자화하며, 이는 선택한 퀀트 방식에 따라 서로 다른 비트 폭의 값 표현을 사용합니다. 먼저 모델의 가중치는 32개의 블록으로 나뉘는데, 각 블록은 가장 큰 가중치 값, 즉 가장 높은 그래디언트 크기를 기반으로 스케일링 팩터를 갖습니다.
선택한 퀀트 방식에 따라 가장 중요한 가중치는 고정밀한 데이터 형태로 양자화되고 나머지는 고정밀한 형태로 할당됩니다. 예를 들어 q2_k 퀀트 방식은 가장 큰 가중치를 4비트 정수로 변환하고 나머지 가중치는 2비트 정수로 변환합니다. 그러나 q5_0과 q8_0 퀀트 방식은 모든 가중치를 각각 5비트 정수와 8비트 정수로 변환합니다. 이 코드 레포에 있는 모델 카드를 보면 GGML의 모든 범위의 퀀트 방식을 볼 수 있습니다.
GGUF
GGUF(GPT-Generated Unified Format)는 GGML의 후속 제품으로, 특히 비 라마 모델의 양자화를 가능하게 하는 등 한계를 해결하기 위해 설계되었습니다. GGUF는 또한 확장 가능합니다. 새로운 기능을 통합하는 동시에 이전 LLM과의 호환성을 유지할 수 있습니다.
그러나 GGML 또는 GGUF 모델을 실행하려면 lama.cpp라는 C/C++ 라이브러리를 사용해야 합니다. lama.cpp는 .GGML 또는 .GUF 형식으로 저장된 모델을 읽을 수 있으며 GPU가 필요한 것과 달리 CPU 장치에서 실행할 수 있습니다.
정말 빠르고, CPU에서 LLM을 구동할 수 있다는 점이 매력적이지만 이런 힙 오버플로우에 약하다고 하니 참고하시기 바랍니다.
굳이 구현할 필요 없이, 허깅페이스에 원하는 모델과 gguf를 함께 검색해서 미리 양자화된 모델을 다운받을 수도 있습니다. 영어 모델의 경우 웬만하면 TheBloke라는 분이 양자화를 해두었더군요. 800자~1000자의 인풋에 대해 5초~10초 내로 추론을 하는 무시무시한 속도를 볼 수 있습니다. 스트리밍도 가능하구요.
AWQ
일반적으로 모델의 가중치는 추론 중에 처리하는 데이터와 관계없이 양자화됩니다. 이와 대조적으로 활성화 인식 가중치 양자화(Activation-aware Weight Quantization: AWQ)는 모델의 활성화, 즉 입력 데이터의 가장 중요한 특징과 추론 중에 분포되는 방식을 설명합니다. 모델 가중치의 정밀도를 입력의 특정 특성에 맞게 조정하면 양자화로 인한 정확도 손실을 최소화할 수 있습니다.
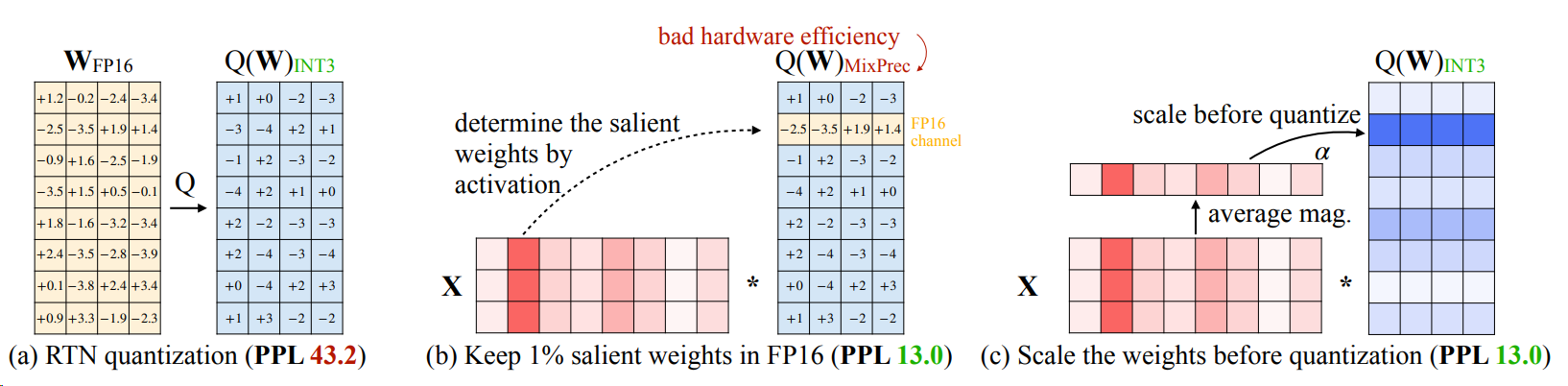
AWQ의 첫 번째 단계는 교정 데이터 하위 집합을 사용하여 모델에서 활성화 통계를 수집하는 것입니다. 이는 일반적으로 총 가중치의 1% 미만을 구성하는 현저한 가중치로 알려져 있습니다. 현저한 가중치는 정확도를 높이기 위해 양자화를 위해 건너뛰고 FP16 데이터 유형으로 남아 있습니다. 한편, 나머지 가중치는 나머지 LLM에서 메모리 요구 사항을 줄이기 위해 INT3 또는 INT4로 양자화됩니다.
결론
양자화는 LLM 환경에서 필수적인 부분입니다. 언어 모델의 크기를 압축함으로써, QLoRA 및 GTPQ와 같은 양자화 기술은 LLM의 채택을 증가시키는 데 도움이 됩니다. 이 모든 기술들을 능수능란하게 사용하게 되면 정말 빠르겠다-!를 체감하게 해준 건 GPT4all이었습니다. GPT4all은 다운 받고, 모델을 고르면 CPU 환경 내에서 LLM을 실행할 수 있는 멋진 프로그램입니다. GPU도 필요 없고, 와이파이 표시를 꺼버리면 자기 데이터도 private하게 유지할 수 있습니다. 그럼 도움이 되셨길 바랍니다~
